




テキストからビジュアルへ:DALL-Eはいかにしてアイデアに命を吹き込むか?

テキストからビジュアルへ:DALL-Eはいかにしてアイデアに命を吹き込むか?
ダル-Eとは?
DALL-Eは、OpenAIによって開発された、テキストプロンプトから画像を作成するマルチモーダルモデルです。DALL-Eは、"スーパーヒーローのマントを着た猫が、夕暮れの街のスカイラインを飛んでいる "といったシンプルなプロンプトを、ユニークで視覚的にクリエイティブな画像に変換します。DALL-Eは、高度なディープラーニング技術を使って、言葉の背後にある意味を理解し、想像力や抽象的なアイデアに対しても、それにマッチしたビジュアルを作成する。
図- DALL-Eによる架空のイメージ.png](https://assets.zilliz.com/Figure_A_fictional_imagery_by_Dall_E_8b9bec6452.png)
図: Dall-Eによる架空のイメージ
Dall-E の仕組み
DALL-Eはディープラーニング(DL)と自然言語処理(NLP)(https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)を組み合わせ、テキスト記述から画像を生成します。人間のようなテキストを理解し生成するために設計されたGPT-3と同様の大規模言語モデル(LLM)モデル上に構築されています。GPT-3が1,750億のパラメータを使用するのに対し、DALL-Eは120億のパラメータを使用し、特にテキストではなく画像を生成するために最適化されています。これらのパラメータにより、テキスト入力を理解し、対応するビジュアルを生成することができます。
DALL-Eのアーキテクチャの中核は、トランスフォーマーのニューラルネットワークであり、テキストに記述された様々な概念を結びつけています。例えば、"タキシードを着た象 "というようなプロンプトが与えられると、ダーリーはニューラルネットワークを使ってこれらの概念を解釈し、首尾一貫したイメージに統合します。これはゼロショット・テキスト・トゥ・イメージ・ジェネレーションとして知られる技術によって達成され、モデルは特定の例を必要とせずに、事前知識に基づいて新しいイメージを生成する。ユーザーがプロンプトを提供すると、DALL-Eは単語を処理してその意味と関係を理解します。この情報は画像生成システムに渡され、画像生成システムは拡散モデルとして知られるAIの一種を使用して、説明を反映した画像を作成します。
DALL-E バージョン
DALL-E は、その誕生以来、画質、精度、全体的な機能性など、バージョンアップのたびに大きな進化を遂げてきました。
DALL-E 1
DALL-E 1 は、OpenAI が 2021 年にリリースしたオリジナルバージョンで、離散変分オートエンコーダ(dVAE) を用いてテキストプロンプトから画像を生成するというコンセプトを導入した先駆的なモデルです。DALL-E 1はGPT-3モデルの縮小版をベースに構築され、120億個のパラメータを使用した。無関係な要素(「宇宙服を着たキリン」のような)を組み合わせる能力は印象的でしたが、生成された画像はしばしばシャープネスとフォトリアリズムに欠けていました。DALL-E 1は、AIがテキストから画像への生成のような創造的なタスクを処理できることを示す概念実証であったが、その結果はまだ比較的基本的なものであった。
DALL-E 2
DALL-E 2 は 2022 年にリリースされ、画質とリアリズムの両面で大きな性能を発揮した。DALL-E 2 の重要な革新のひとつは、dVAE アプローチに代わる拡散モデル の使用である。この変更により、DALL-E 2 はコヒーレンスを改善した、より詳細で高解像度の画像を作成できるようになりました。また、前作よりもはるかに鮮明なフォトリアリスティックな画像を生成できるようになりました。もう一つの大きな改良点は、CLIP モデル(Contrastive Language-Image Pre-training)を統合したことです。CLIP モデルでは、視覚表現と言語表現の関係を理解することで、DALL-E 2 が画像とテキストの説明をより適切に整合させることができるようになりました。
DALL-E 3
DALL-E 3 は 2023 年に導入され、プロンプトの解釈と画質の両方を強化することで、さらに進化を遂げました。DALL-E 3 は、複雑でニュアンスの異なるプロンプトを理解する能力に優れ、ユーザーの意図により近い画像を生成します。このバージョンでは、複雑なシーンやオブジェクトの処理、複数の要素や詳細な背景を持つ画像の生成方法も改善されています。もう一つの重要なアップグレードは、より洗練された言語処理を提供するOpenAIのGPT-4とのより深い統合です。出力品質の面では、DALL-E 3は高解像度であるだけでなく、フォトリアリズム、イラストレーション、抽象芸術など、ユーザーの入力とスタイルが一致した画像を生成することで、リアリズムの限界を押し広げ続けています。
DALL-E の使い方
テキストプロンプトから画像を生成するDALL-Eにアクセスし使用するには、以下の手順に従ってください:
1.ChatGPT を開く: まず、ChatGPT インターフェイスを使用していることを確認します。左上隅で、モデルバージョンを選択します。ChatGPT 4.0** に設定されていることを確認してください。
2.左のパネルで、Explore GPTs**ボタンをクリックしてください。これにより、インターフェイス内で利用可能な様々なGPTとカスタム機能を発見することができます。
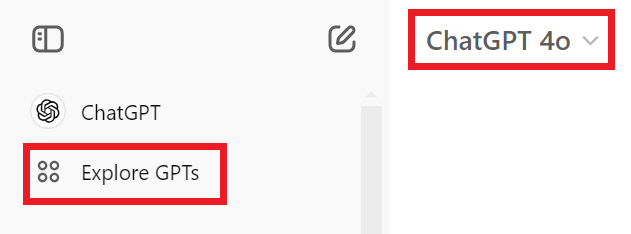 図- ステップ1- GPTの探索.png
図- ステップ1- GPTの探索.png
図:ステップ1:GPTの探索
3.DALL-E を検索する: GPT の探索セクションに入ったら、検索バーを使って "DALL-E" と入力してください。検索結果の下にDALL-Eが表示されます。
4.**DALL-Eを選択します。"Let me turn your imagination into imagery "と書かれたDALL-Eオプションをクリックします。これで DALL-E が起動し、希望するテキストプロンプトを入力して画像の生成を開始することができます。
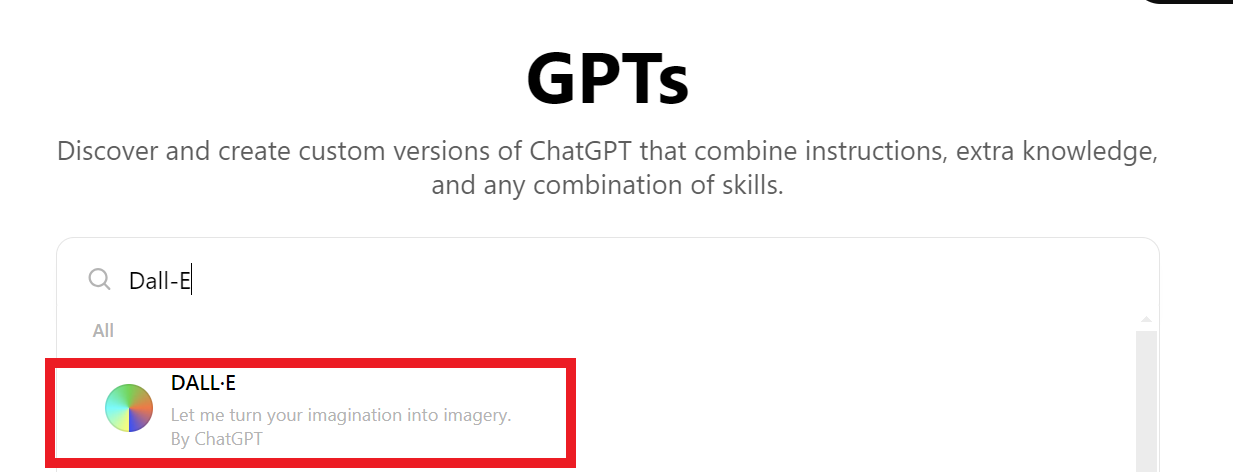 図- ステップ 2- Dall-E を選択.png
図- ステップ 2- Dall-E を選択.png
図: ステップ 2: Dall-E の選択
これでDall-Eとチャットする準備ができました。チャット開始 "**ボタンをクリックしてください。
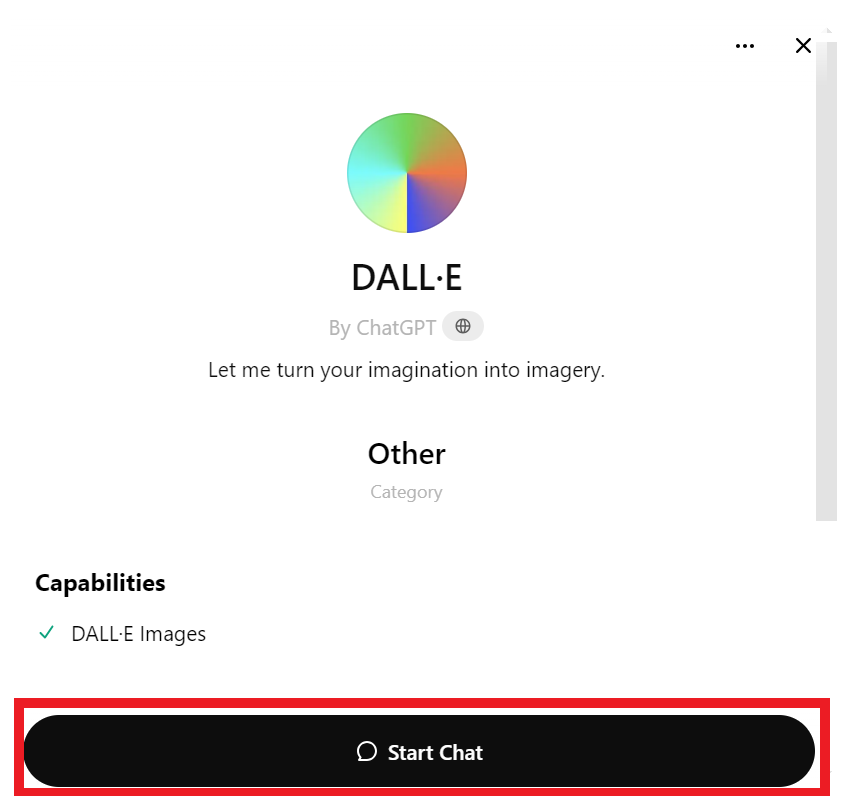 図- ステップ 3- Dall-E とチャットを始める.png
図- ステップ 3- Dall-E とチャットを始める.png
図: ステップ 3: Dall-E とのチャット開始
様々なプロンプトに対してDall-eをテストしてみましょう。
簡単なプロンプト
白い皿の上に赤いリンゴが乗っている」_応答:。
図-簡単なプロンプトに対するDall-Eのテスト.png](https://assets.zilliz.com/Figure_Testing_Dall_E_against_a_simple_prompt_632ea05a27.png)
図: 簡単なプロンプトに対する Dall-E のテスト
これは簡単で、シンプルな背景で基本的なフォトリアリスティックなオブジェクトを生成する DALL-E の能力をテストします。出力は、一般的なアイテムに焦点を当てた、きれいでリアルなものです。
マーケティングプロンプト
湯気が立ち上るコーヒーカップを木製のテーブルの上に置き、居心地の良いカフェを背景にしたソーシャルメディア広告。
**回答
 図-マーケティング・プロンプトに対するDall-Eのテスト.png
図-マーケティング・プロンプトに対するDall-Eのテスト.png
図: マーケティングプロンプトに対するDall-Eのテスト
これはコーヒーブランドのマーケティングに最適なユースケースです。消費者の心に響く、温かく魅力的なシーンを作り出すことに焦点を当てているからです。
ブログ記事用グラフィック
ブログ記事用にRAGチャットボットの最小限のイラストを作成してください。
レスポンス:
 図-グラフィックス生成プロンプトに対する Dall-E のテスト.png
図-グラフィックス生成プロンプトに対する Dall-E のテスト.png
図:グラフィックス生成プロンプトに対する Dall-E のテスト
このプロンプトは、教育的なビジュアルを生成するのに便利です。しかし、単純なリクエストでは、ロボットや吹き出しのある一般的なチャットボッ ト画像が生成される可能性が高く、洗練された現代的なスタイルには見えません。この画像は、RAG(Retrieval-Augmented Generation:検索拡張世代)のコンセプトを捉えていない可能性があります。画像は、RAGベースのシステムの性質や情報検索との関係を具体的に伝える特徴的な特徴を欠いている可能性があります。
このようなシナリオは、プロンプトエンジニアリング技術によって改善することができる。
Dall-Eとプロンプトエンジニアリング
DALL-E の使い方は簡単ですが、プロンプトをいかにうまく作るかにかかっています。DALL-E に生成させたい画像をテキストで記述するだけです。このプロセスはプロンプトエンジニアリングと呼ばれる。ゼロショット](https://zilliz.com/learn/what-is-zero-shot-learning)、思考連鎖、プロンプト連鎖 などの様々なプロンプトエンジニアリングのテクニックは、プロンプトの出力に直接影響します。
プロンプトエンジニアリングを使って DALL-E の結果を向上させるには、以下の手順で入力を改良し、より精度を高めてください。
洗練されたプロンプト
RAG (Retrieval-Augmented Generation)チャットボットのモダンで洗練されたイラストを作成してください。チャットボットは、光り輝くインターフェイスを持つ、フレンドリーで未来的なAIアシスタントのように見えるはずです。ナレッジベースや外部ソースからチャットボットに流れ込むデータやテキストの流れを表示し、情報検索を視覚的に表現する。チャットボットは、ホログラフィックスクリーンを介してユーザーと対話し、取得した情報を使用して応答を生成する能力を紹介する必要があります。ハイテクでインテリジェントな雰囲気を呼び起こすために、クールな青と紫のカラーパレットを使用し、アクティブな思考や処理を示すためにチャットボットの頭の周りに微妙なハイライトを入れます。
**応答:
プロンプトエンジニアリングによる Dall-E のレスポンスの改善.png](https://assets.zilliz.com/Figure_Improving_Dall_E_s_response_through_prompt_engineering_76c83e8e86.png)
図:プロンプトエンジニアリングによるDall-Eの反応改善
洗練されたプロンプトは、RAGチャットボットのより視覚的な魅力と情報量の多いイメージ、そしてAIシステムに関連する洗練された未来的なデザインにつながります。
プロンプトエンジニアリングの主なテクニック
1.概念の明確化:
RAG (Retrieval-Augmented Generation)」チャットボットであることを指定することで、モデルが典型的なチャットボットのイメージ以上のものを生成する必要があることを理解し、RAGメカニズムにフォーカスすることを確実にします。
2.検索の視覚的表現:
RAGシステムの本質的な側面である情報検索を表す、チャットボットに入ってくる「データまたはテキスト断片の流れ」を明示的に求めています。
3.ユーザーインタラクションと機能性:
チャットボットがユーザーと対話する「ホログラフィック・スクリーン」のようなディテールを含めることで、その先進的で未来的な性質を強調することができます。これにより、ビジュアルストーリーテリングが強化され、チャットボットの機能的な側面が伝わります。
4.カラーパレットとスタイル:
カラーパレット(クールなブルーとパープル)を指定し、「未来的で洗練された」デザインを強調することで、AIとテクノロジーに関するブログにふさわしい、コンセプトが正確で視覚的に魅力的なイメージに仕上がっています。
5.処理/インテリジェンスの強調:
チャットボットの頭の周りに微妙なハイライト "のような要素を追加することは、アクティブな処理や思考を示し、これが能動的に情報を取得し生成するインテリジェントなシステムであることをさらに強調します。
Dall-E の実際の使用例
広告とマーケティング:** DALL-Eは、マーケティング担当者が広告キャンペーン用にユニークなビジュアルを作成したり、特定の商品説明やテーマに基づいてカスタム画像を生成したりするのに役立ちます。
グラフィックデザイン: **デザイナーは DALL-E を使ってコンセプト、イラスト、モックアップを素早く作成し、手作業によるデザイン作業に費やす時間を短縮します。
コンテンツ作成: **ブロガーやコンテンツ作成者は DALL-E を使って、文章に沿った人目を引くビジュアルを生成し、エンゲージメントを高めることができます。
エンターテイメントとメディア: **映画やゲームのスタジオは、DALL-E を使ってキャラクター、シーン、ポスターのビジュアルアイデアをブレインストーミングし、クリエイティブの可能性を広げます。
教育:*** 教育者は、抽象的な概念を説明するためのビジュアルを作成したり、生徒のための魅力的な教材を作成することができます。
建築とインテリアデザイン:** DALL-E は、詳細なテキスト記述に基づいて、建築デザインやインテリアレイアウトのビジュアル表現を作成することができます。
アートとイラストレーション:** アーティストは DALL-E を使って創造的なアイデアを探ったり、新しいスタイルを試したり、作品のインスピレーションを生み出すことができます。
E コマース:** E コマースプラットフォームは、DALL-E を使用して、まだ存在しないアイテムの製品イメージを作成したり、顧客の好みに基づいてカスタマイズされた製品を視覚化したりします。
DALL-E の利点
効率的な画像作成:** DALL-E を利用することで、ユーザーは簡単なテキスト説明を提供するだけで、 高品質な画像を素早く作成することができ、手作業によるデザインにかかる時間と労力を 節約することができます。
創造的な柔軟性:** DALL-E は、リアルなものから抽象的なものまで、幅広いビジュアルを作成することができ、アーティスト、デザイナー、マーケティング担当者に計り知れない創造的な自由を与えます。
費用対効果:** 画像作成を自動化することで、DALL-E はプロのデザイナーを雇ったり、ストック画像を購入したりする必要性を減らし、企業にとって費用対効果の高いソリューションとなります。
カスタマイズ:** DALL-E は、独自の芸術的スタイルや、パーソナライズされた結果を得るための特定の視覚的要素など、特定の要件に合わせて画像を調整することができます。
非アーティストのためのアクセシビリティ:** DALL-E は、アーティスティックなスキルを持たない人々にも、より多くの人々のためにプロ級のビジュアルを作成する力を与えます。
ラピッドプロトタイピング:**デザイナーやクリエイターは、様々なアイデアやコンセプトを素早く試すことができ、複数のビジュアルを素早く作成することができます。
スケーラビリティ:** DALL-E は、複数の画像を同時に生成できるため、製品カタログやマーケティングキャンペーンなど、大量のビジュアルを必要とするプロジェクトに適しています。
DALL-E の制限事項
DALL-E は印象的なビジュアルを生成する一方で、ユーザーが出力の特定のディテールをコント ロールできるとは限らないため、期待に沿えない結果となる可能性があります。
複雑なプロンプトの理解:** DALL-E は、複雑すぎるプロンプトや曖昧なテキストプロンプトに苦戦することがあり、不正確 な画像や誤解された画像を生成することがあります。
画像内の不正確なテキスト:** DALL-E は、画像内の正確なテキスト生成、特にスペルや単語の明確さに苦戦すること がよくあります。このモデルは誤ったスペルや乱雑なテキストを生成する可能性があり、教育やマーケティングのような実用的な目的での画像の有効性を低下させる可能性があります。
DALL-E は既存のデータに基づいて学習されるため、そのデータに含まれるバイアスが反映され、 意図しない出力やステレオタイプな出力になることがあります。
DALL-E は様々なスタイルを再現することができますが、高度に専門的で複雑な芸術技法を完 全に模倣することはできません。
AIが生成する芸術は、独創性、著作権、そして人間のアーティストの居場所を奪うことについて疑問を投げかけ、クリエイティブ産業における議論を巻き起こしている。
結論
DALL-Eは、テキストを視覚的に魅力的な画像に変換する強力なAIツールであり、クリエイティブ産業における新たな可能性を開くものである。プロンプトエンジニアリングを使用することで、ユーザーは生成されるビジュアルの精度と品質を向上させることができ、DALL-Eはさらに多機能になる。DALL-Eには限界があるが、デザイン、マーケティング、教育などを変革する可能性は否定できない。
ダル・イーに関するFAQ
DALL-Eとは何ですか、そしてどのように機能するのですか?ディープラーニング(深層学習)技術を使い、単語間の関係を理解し、その記述に基づいてビジュアルを作成します。これは、テキストと画像の大規模なデータセットで訓練された自然言語処理と画像生成モデルの組み合わせを使用しています。
DALL-Eは、広告、グラフィックデザイン、コンテンツ制作、エンターテインメント、教育、eコマースなど、さまざまな分野で活用できます。ユニークなビジュアル、コンセプト、イラストを素早く作成し、手作業によるデザイン作業の必要性を減らし、業界を超えた創造性を刺激します。
DALL-E の限界は何ですか? DALL-E は強力ですが、その限界には、画像内の正確なテキスト生成、出力結果の潜在的な偏り、 画像生成プロセスの特定の側面に対する微調整の欠如が含まれます。さらに、効果的に動作させるためには多大な計算リソースが必要です。
プロンプトエンジニアリングは DALL-E の結果をどのように改善するのでしょうか?ユーザーは、画像の色、スタイル、ムード、要素などの詳細を指定することで、出力をよりよく制御することができ、意図したビジョンに近いビジュアルを実現することができます。
関連リソース
Milvusを使ったLLMによるテキストから画像へのプロンプト生成](https://zilliz.com/blog/llm-powered-text-to-image-prompt-generation-with-milvus)
GPT-4.0と大規模言語モデルの秘密を解き明かす](https://zilliz.com/learn/what-are-llms-unlock-secrets-of-gpt-4-and-llms)
画像類似度検索](https://zilliz.com/vector-database-use-cases/image-similarity-search)
画像検索のための画像埋め込み:徹底解説](https://zilliz.com/learn/image-embeddings-for-enhanced-image-search)
ハイブリッド検索:テキストと画像の組み合わせによる検索機能の強化](https://zilliz.com/learn/hybrid-search-combining-text-and-image)
プロンプト連鎖](https://zilliz.com/blog/prompting-langchain)
LangChainにおけるプロンプティング](https://zilliz.com/blog/prompting-langchain)