




TokopediaがMilvusを使って10倍スマートな検索体験を実現した方法
10倍賢くなる
サーチ・エクスペリエンス
改善された
ユーザーエクスペリエンス
強化された
スケーラビリティと信頼性
Our search system has been much more intelligent, stable, and reliable using Milvus.
Rahul Yadav
♪トコペディアについて
Tokopediaはインドネシア最大のEコマース・プラットフォームで、月間アクティブユーザー数9,000万人という驚異的な数字と、860万ものマーチャント・ネットワークを誇っています。インドネシアの行政区域の 98% をカバーし、Tokopedia はインドネシアのオンラインショッピングの主要な目的地となっています。
Tokopediaは、その豊富な商品カタログの価値を、購入者が自分の好みに合った商品を簡単に発見できることにあると認識しています。検索結果の関連性を高めるための揺るぎないコミットメントとして、同社はTokopediaに類似検索を導入しました。
ユーザーがモバイルデバイスで検索結果ページに移動すると、控えめな「...」ボタンが表示されます。このボタンをクリックすることで、ユーザーはメニューにアクセスすることができ、ユーザーが見ている商品と密接に一致する商品を探索するエキサイティングな機会を提供する。
キーワード検索の課題
以前、Tokopedia Searchは商品検索とランキングの主要エンジンとしてElasticsearchを利用していました。各検索リクエストはElasticsearchへのクエリーを開始し、ユーザーの検索キーワードに基づいて商品をランク付けしていました。Elasticsearchはキーワードを数値のシーケンスとして保存し、個々の文字をASCIIまたはUTFコードで表現します。ユーザーのクエリに含まれる単語を含むドキュメントを素早く特定するために転置インデックスを構築し、その後、様々なスコアリング・アルゴリズムを用いてベストマッチを決定します。
しかし、これらのスコアリング・アルゴリズムは通常、検索されたキーワードのセマンティクスを考慮しない。その代わりに、単語が文書に出現する頻度や、単語同士の近さ、その他の統計的情報といった要素に注目する。人間は単語のASCII表現の背後にある意味を理解することができますが、コンピュータはASCIIエンコードされた単語のセマンティクスを比較するために信頼性の高いアルゴリズムを必要とします。
ベクター表現
Tokopediaチームが見つけた問題解決のひとつは、キーワードを表現する新しい方法を作り出すことだった。例えば、よく使われる単語を検索キーワードと一緒にエンコードすることで、可能性の高い文脈を提供することができる。そこから、似たような文脈は似たような概念を示していると仮定し、数学的手法を使って比較することができる。意味に基づいて文章全体を符号化することも可能である。
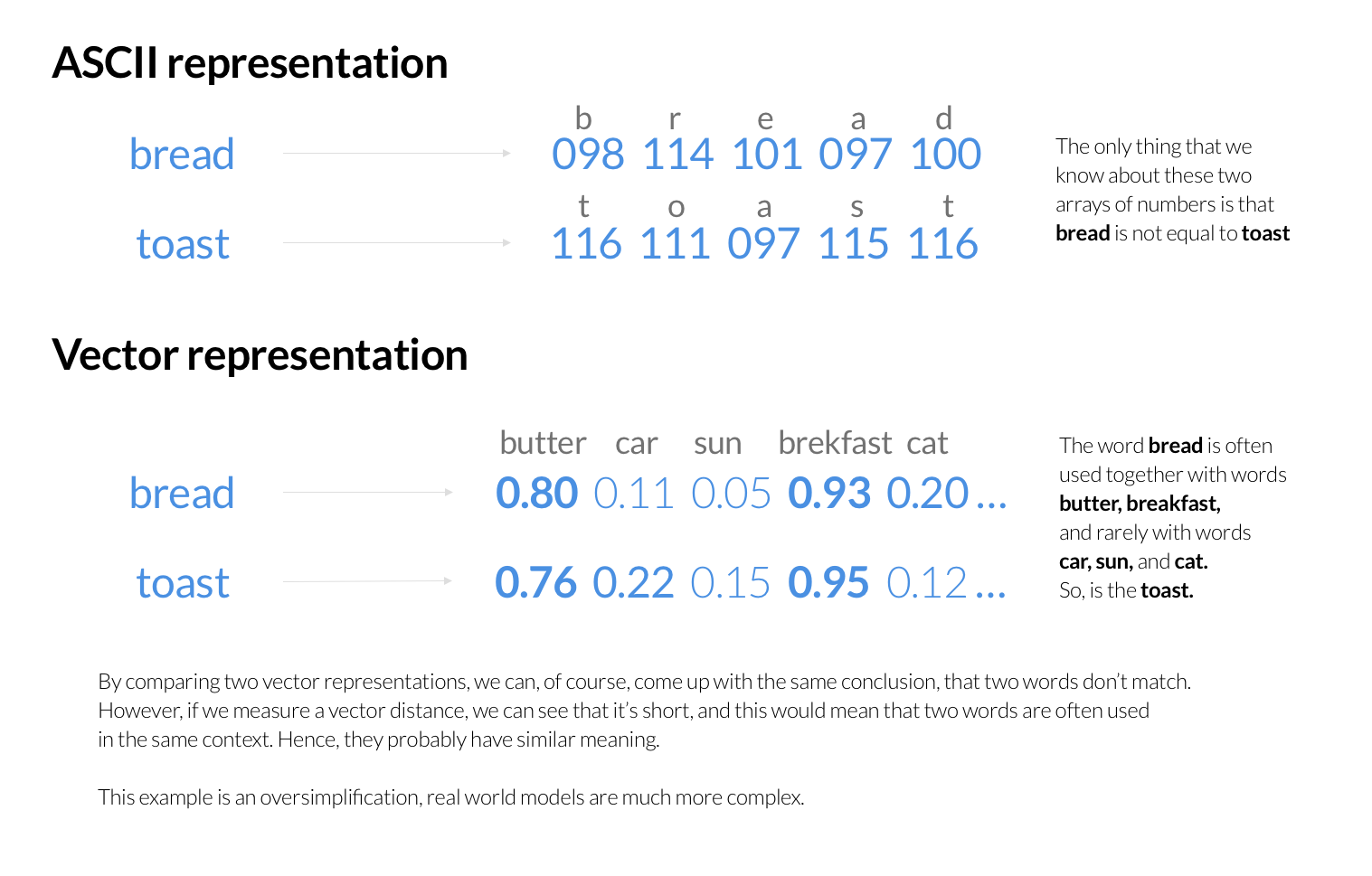
ベクトル類似検索エンジンとしてMilvusを選択する
Tokopediaが特徴ベクトルを持つようになった今、残された課題は、膨大なデータセットからターゲットベクトルと密接に一致するベクトルを効率的に検索することにある。ベクトル検索エンジンを検討するにあたり、FAISS、Vearch、Milvusなど、GitHubで公開されているいくつかのベクトル検索スタックで概念実証(POC)評価を行った。
我々の負荷テストの結果では、Milvusに軍配が上がった。Milvusと比較すると、FAISSはより基礎的なライブラリとして動作しており、結果としてユーザーフレンドリーではありません。Milvusを深く掘り下げるにつれ、以下の理由からMilvusを採用しました:
- Milvusは非常にユーザーフレンドリーである。Milvusは驚くほどユーザーフレンドリーであることがわかった。
- Milvusはより幅広いインデックスをサポートしている**。FAISS、HSNW、DISK_ANN、ScaNNに加えて、11のインデックスから選択できる。
- Milvusは、ユーザーの実装を支援する包括的なドキュメントを提供します。
一言で言えば、Milvusはユーザーフレンドリーであり、明確なドキュメントと、問題が発生した場合の信頼できるコミュニティサポートがある。
稼働中のMilvus
機能ベクトル検索エンジンとしてMilvusを導入した後、同社は広告サービスにMilvusを活用し、成約率の低いキーワードと成約率の高いキーワードのマッチングを行った。開発(DEV)環境でスタンドアロンノードを構成し実行したところ、スムーズに動作し、クリックスルー率(CTR)とコンバージョン率(CVR)が10倍も向上しました。
しかし、潜在的な懸念が生じた。スタンドアロンノードがクラッシュすると、サービス全体がアクセス不能になってしまうのです。そこで、TokopediaチームはMilvusのHA実装に切り替えた。
Milvusは2つのツールを提供している:クラスタ・シャーディング・ミドルウェアのMishardsと、設定を合理化するMilvus-Helmである。Tokopediaでは、インフラストラクチャのセットアップにAnsible playbookを使用しており、インフラストラクチャをオーケストレーションするためのplaybookを作成するよう促している。下図はMishardsの仕組みを示している。
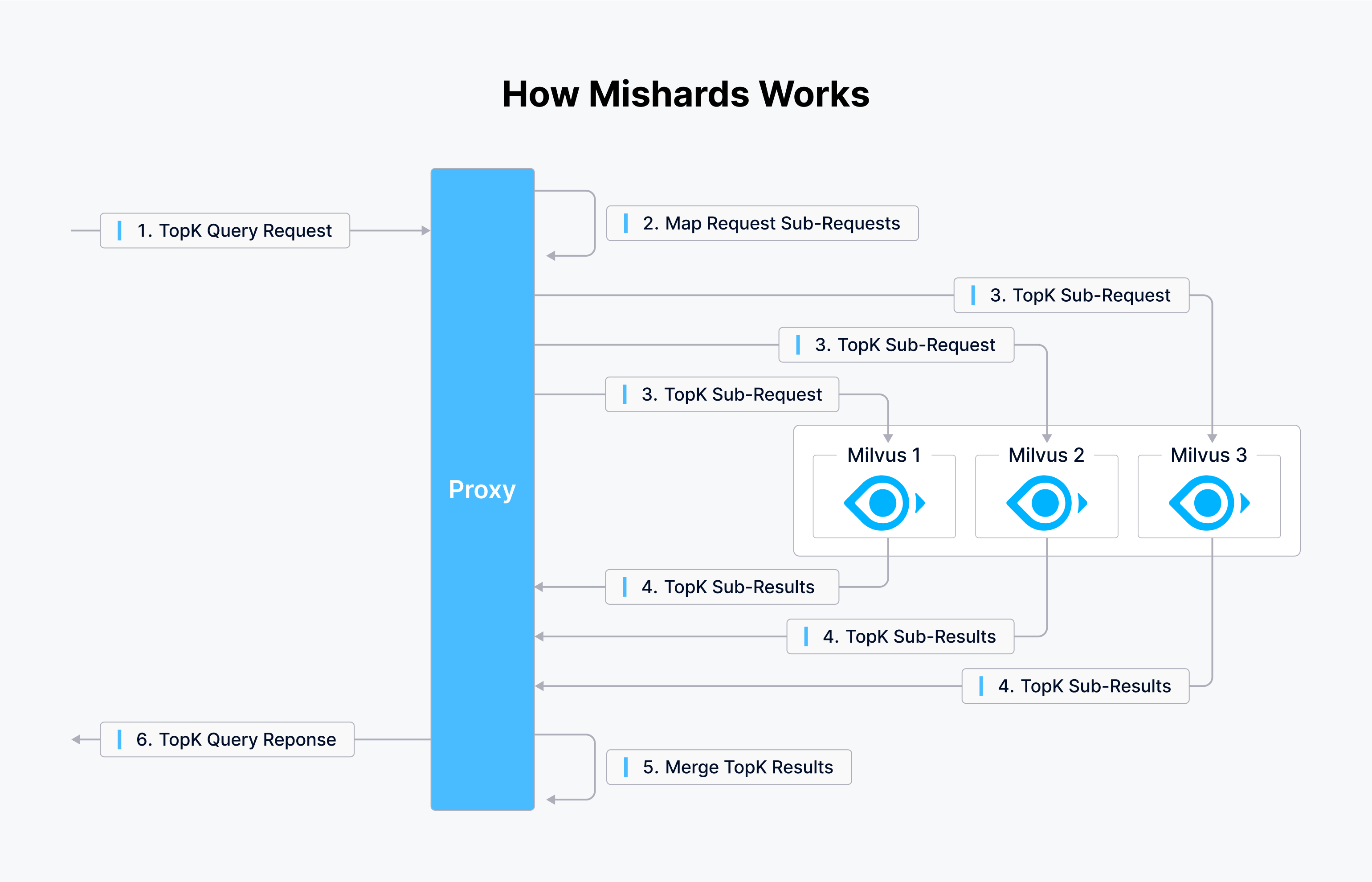
Mishardsは、上流から下流へのリクエストのシームレスな流れを促進し、上流のリクエストをサブモジュールに分割し、サブサービスから結果を収集し、その結果を上流のソースに送り返す。
Mishardsベースのクラスタソリューションのアーキテクチャを以下に示す。
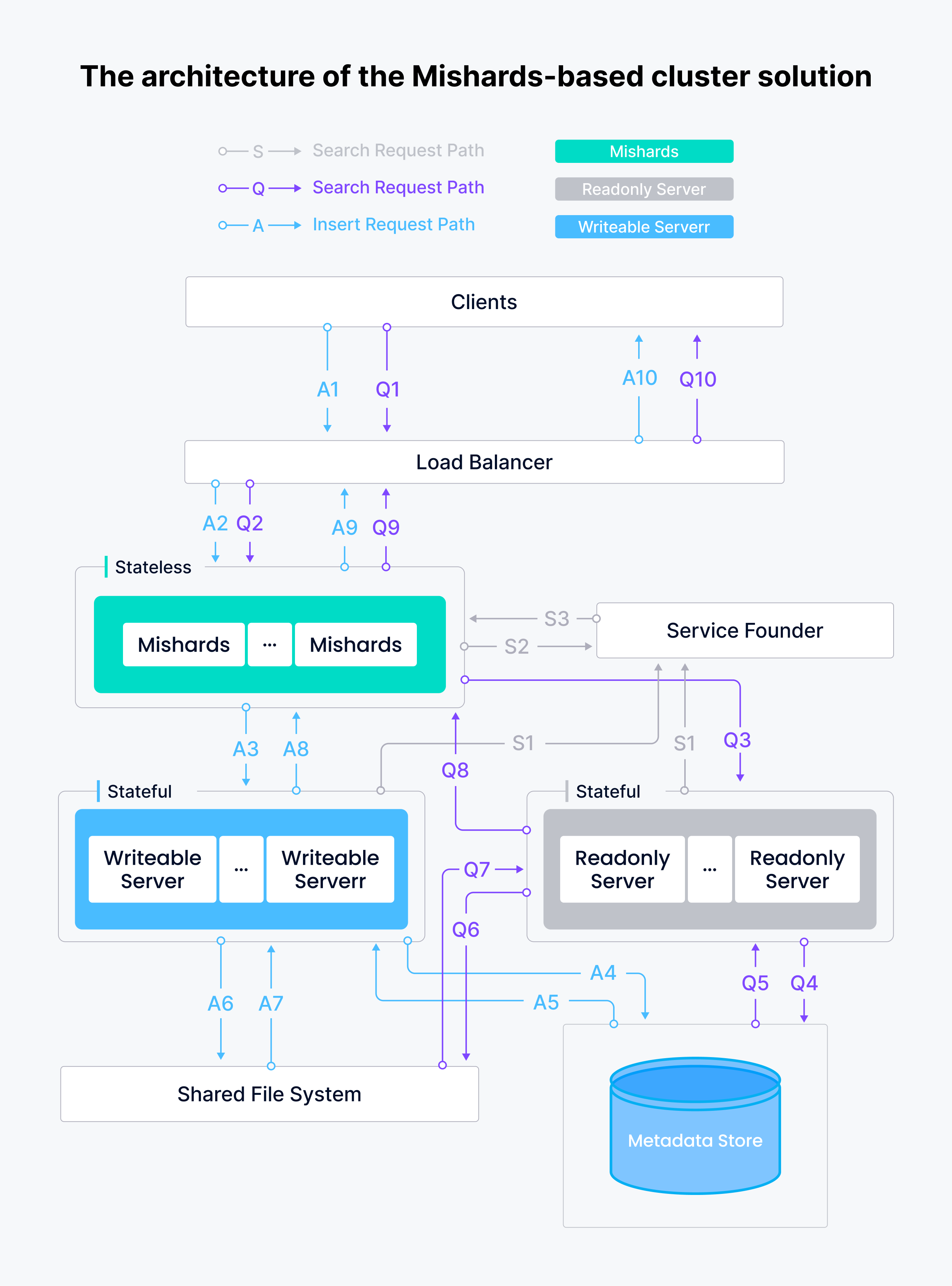
Tokopediaセマンティック検索サービスシステムには、書き込み可能なノード1台、読み取り専用ノード2台、Mishardsミドルウェアインスタンス1台が含まれ、これらはすべてMilvus Ansibleを使ってGCPにデプロイされている。このシステムはかなり賢く、安定し、信頼できる。
ベクターインデックスはどのように類似検索を加速するのか?
類似検索エンジンで大規模なベクトルデータセットを効率的にクエリするには、適切なインデクシングが必要です。このプロセスはデータを整理し、検索プロセスを高速化するため、数百万、数十億、あるいは数兆のベクトルを持つデータセットを扱うためには不可欠です。巨大なベクトルデータセットにインデックスを作成すれば、入力クエリと類似したベクトルを含む可能性が最も高いデータのクラスタやサブセットにクエリを誘導することができる。しかし、このアプローチは、大きなベクトルデータに対してより高速なクエリーを実現するために、精度を犠牲にする可能性がある。
よりよく理解するために、インデックス作成は辞書の単語をアルファベット順に並べるようなものだと考えてください。キーワードを調べるとき、同じ頭文字を持つ単語だけを含むセクションに素早く移動することができ、入力単語の定義の検索が劇的に速くなる。
要約
Tokopediaは優れた検索機能を追求した結果、セマンティック検索の常識を覆すMilvusにたどり着いた。Milvusによって、彼らはベクトル表現の力を解き放ち、ユーザー体験を劇的に向上させる10倍スマートな検索システムを構築した。同社の検索サービスは可用性も高く、シームレスな運用を保証している。このMilvusとの旅は、Tokopediaの検索を一変させ、パーソナライズされた意味のある検索結果の未来を約束した。Milvusと共に、Tokopediaはインドネシア、そして世界のEコマースに革命を起こそうとしている。
この投稿はTokopediaのソフトウェアエンジニア、Rahul Yadavによって書かれました。許可を得て編集し、ここに再掲載しています。