




Optimizing Conversational AI at FARFETCH

15x
faster indexing time
5x
faster query time
Boosted conversion
through more relevant product recommendations
Multiple metric types
to support various use cases
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
About FARFETCH
FARFETCH, a leading force in online fashion retail, is pushing the boundaries of digital shopping with its latest innovation, iFetch. This conversational AI system is designed to bring the personalized, high-end service typically found in luxury physical stores into the digital realm. FARFETCH Chat R&D is developing a specialized conversational recommender system as part of this initiative. This chatbot, integrated into iFetch, allows users to interact with the FARFETCH product catalog through natural language and images. For instance, a user can upload a picture of a jacket they like, and the chatbot will respond with a curated selection of similar jackets. By seamlessly blending advanced AI technologies with a focus on user experience, FARFETCH aims to redefine what customers can expect from online shopping.
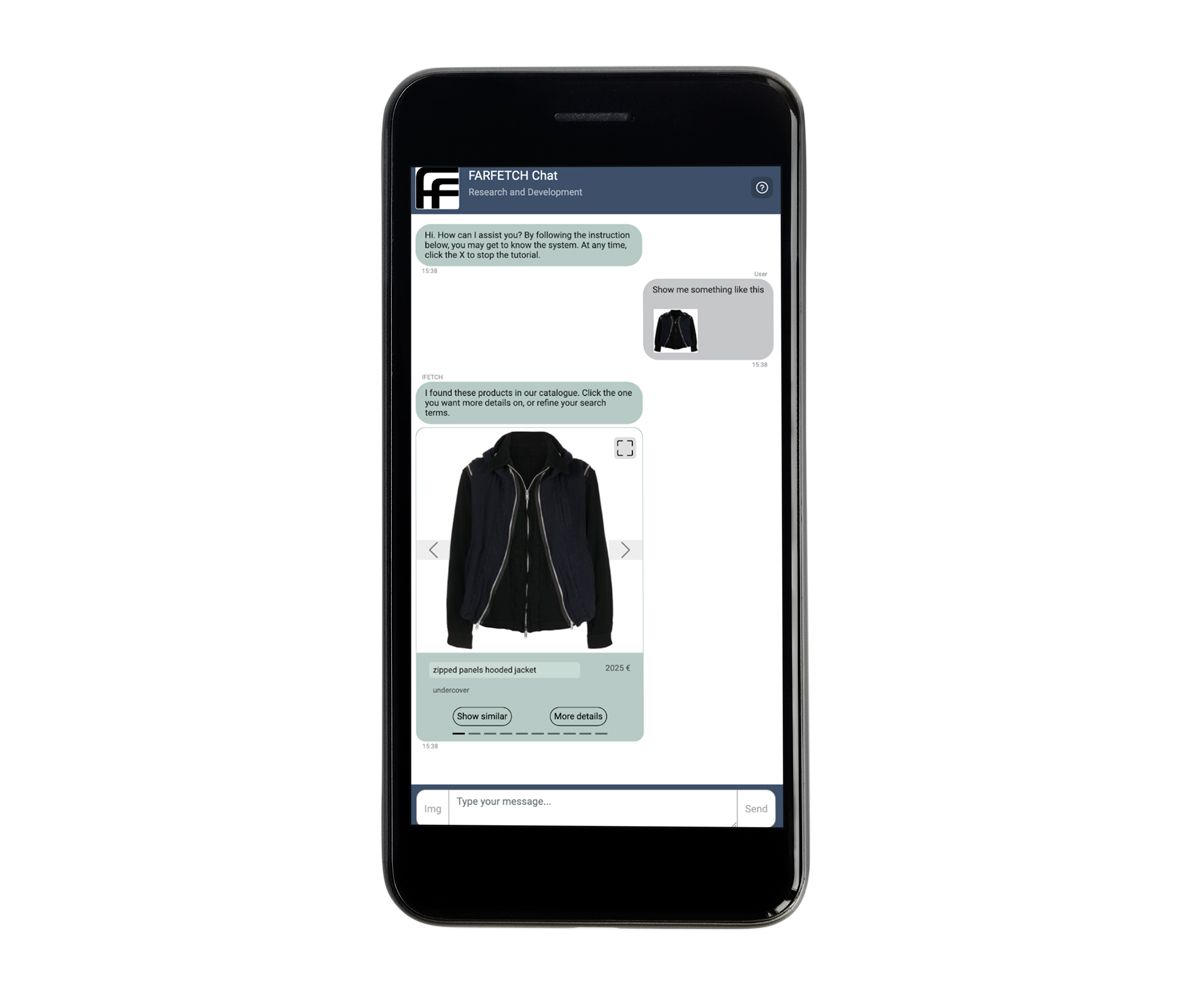 FARFETCH Chat shows a similar showcase
FARFETCH Chat shows a similar showcase
However, they encountered a significant challenge: with their limited metadata, traditional product catalogs struggled to capture their extensive range of products' intricate relationships and nuanced attributes. To tackle this, they employed machine learning algorithms to develop product embeddings—high-dimensional data points that serve as a robust language for their AI system. This enables the chatbot to understand and recommend products with unprecedented accuracy. Yet, storing and retrieving these embeddings in real-time presented another hurdle, requiring a specialized storage solution capable of efficiently handling high-dimensional data.
The Importance of Vector Databases
Vector databases, also known as Vector Similarity Engines (VSE), are specialized databases engineered to handle complex, high-dimensional data called vector embeddings. These databases employ Approximated Nearest Neighbors (ANN) algorithms, which are indispensable for quick and accurate data retrieval. This feature is particularly vital for iFetch, which demands real-time customer interactions to provide instant product recommendations and answer their queries. The choice of a vector database is not a mere technicality; it's a strategic decision that directly impacts the performance, robustness, and efficiency of iFetch. They conducted a comprehensive benchmarking study to ensure they selected the most suitable VSE. This benchmark involved evaluating various databases, including Vespa, Milvus, Qdrant, Weaviate, Vald, and Pinecone, on diverse criteria such as indexing speed, query speed, and scalability. The benchmarking also included stress tests to evaluate how each VSE would perform under peak loads and failover and recovery scenarios to assess resilience.
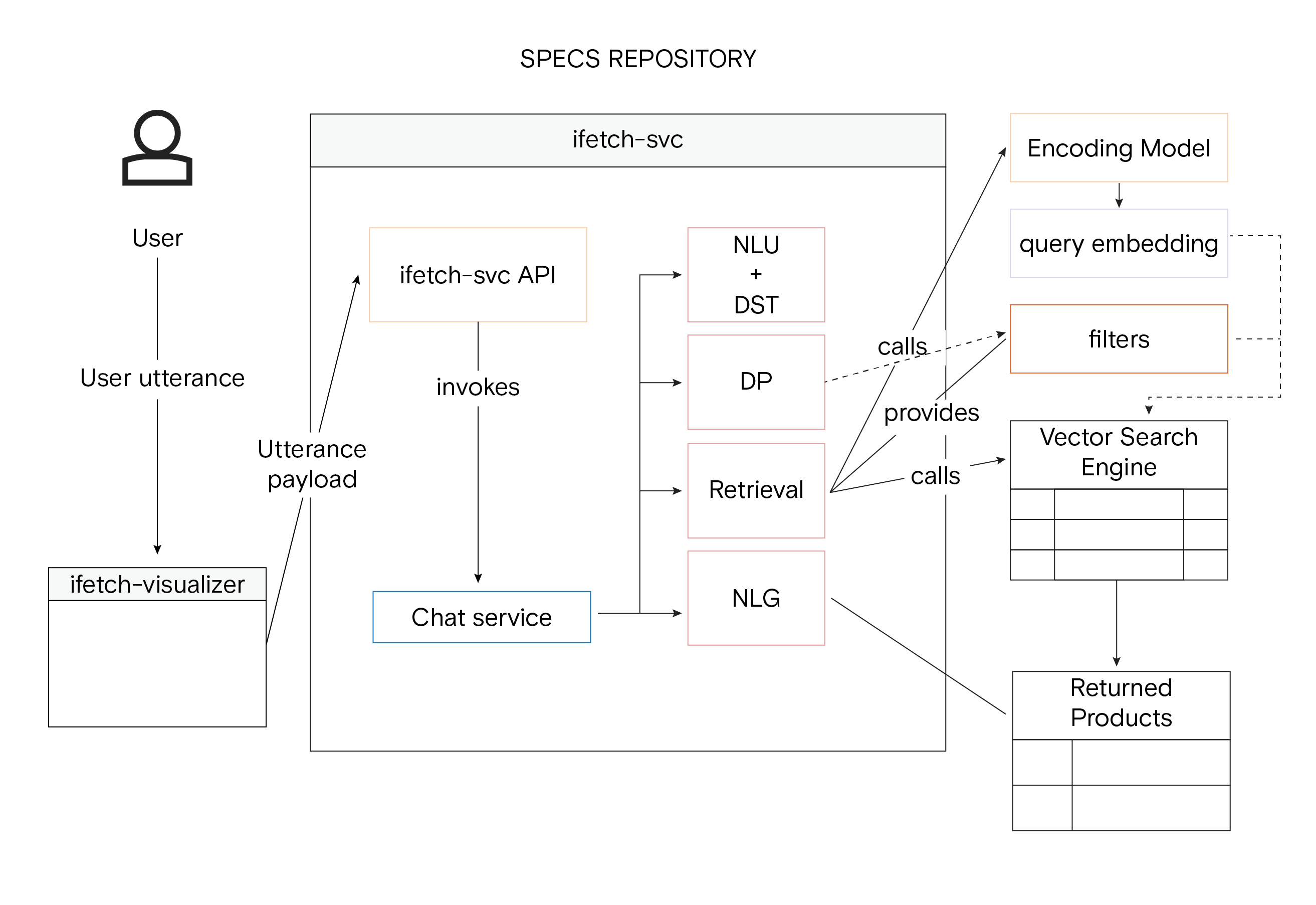 Holistic representation of the iFetch system architecture with Vector Similarity Searc
Holistic representation of the iFetch system architecture with Vector Similarity Searc
Benchmark Criteria and Selection
The benchmarking process conducted by the Farfetch team was exhaustive and methodical, covering a wide range of factors crucial for the long-term success of iFetch. These included the diversity of index types, metric types, model serving capabilities, and community adoption. They also considered the quality of documentation and the availability of support, as these factors would impact the ease of implementation and ongoing maintenance.
| Feature | Qdrant | Milvus | Weaviate | Vespa | Vald | Pinecone |
|---|---|---|---|---|---|---|
| Consistency Model | N/A | Strong Consistency | Eventual Consistency | Eventual Consistency | N/A | Eventual Consistency |
| Support for GraphQL | N/A | N/A | Yes | N/A | N/A | N/A |
| Sharding | No (To be addressed date unknown) | Yes | Yes | Yes | N/A | N/A |
| Pagination | N/A | No (Expected in version 2.2 in 2022.3) | Yes | Yes | N/A | N/A |
| Metric Types | Inner Product Cosine similarity Euclidean (L2) | L2 Inner Product Hamming Jaccard Tanimoto Superstructure Substructure | Cosine | Euclidean Angular Innter Product Geo degrees Hamming | L1 L2 Angle Hamming Cosine Normailized Angle Normalized Cosine Jaccard | Euclidean Cosine Inner Product |
| Max vector dim | N/A | N/A | 32 768 | N/A | max.MaxInt64 | N/A |
| Max index size | N/A | N/A | Unlimited | N/A | N/A | N/A |
| Index Types | HNSW | ANNOY HNSW IVF_PQ IVF_SQ8 IVF_FLAT FLAT IVF_SQ8_H RNSG | NHSW | HNSW BM25 | N/A | Proprietary |
| Model Serving | N/A | N/A | text2vec-contextionary Weaviate’s own language vectorizer; Weighted Mean of Word Embeddings (WMOWE) vectorizer module which works with popular models such as fastText and GloVe. The most recent text2vec - contextionary is trained using fastText on Wiki and CommonCrawl data. text2vec- transformers Transfomer models differ from the Contextionary as they allow you to plug in a pretrained NLP module specific to your use case. This means models like BERT, DilstBERT, RoBERTa, DilstilROBERTa, etc. can be used out-of-the box with Weaviate. Custom models | N/A | N/A | N/A |
After a rigorous analysis, two VSEs—Milvus and Weaviate—were selected for in-depth benchmarking. These platforms aligned closely with their stringent robustness, efficiency, and scalability requirements. The platforms' roadmaps also influenced the final selection, as they needed a solution that would continue to evolve and adapt to their growing needs.
Experimental Setup
They used a standardized hardware and software setup to ensure a fair and comprehensive evaluation.
- Hardware: Intel Xeon E5-2690 v4 CPU, 112 GB RAM, 1024 GB HDD
- Software: Linux 16.04-LTS, Anaconda 4.8.3 with Python 3.8.12
- Dataset: The Farfetch team used a public dataset from startups-list.com, comprising 40,474 records. The dataset included precomputed embeddings for company descriptions.
Scenarios and Indexation Algorithm
They designed multiple test scenarios to evaluate the performance of these VSEs under different conditions. These scenarios varied the number of records and the number of encodings per entity. They used the Hierarchical Navigable Small World (HNSW) algorithm for indexation, known for its efficiency in high-dimensional data spaces.
The final list of scenarios is listed below.
| Scenario | Number of Entities | Number of Encodings per entity |
|---|---|---|
| Scenario #1 (S1) | 1.000 | 1 |
| Scenario #2 (S2) | 10.000 | 1 |
| Scenario #3 (S3) | 40.474 | 1 |
| Scenario #4 (S4) | 1.000 | 2 |
| Scenario #5 (S5) | 10.000 | 2 |
| Scenario #6 (S6) | 40.474 | 2 |
| Scenario #7 (S7) | 1.000 | 5 |
| Scenario #8 (S8) | 10.000 | 5 |
| Scenario #9 (S9) | 40.474 | 5 |
Performance Analysis
Indexing
Weaviate: Allows for explicit declaration of index parameters during class schema creation. However, it restricts class naming, such as not allowing numbers or special characters.
Milvus: Offers a broader range of indexing algorithms and metric types. It also allows for defining index file sizes, which can optimize batch operations.
Result: Milvus had the edge regarding average indexing times across all scenarios. It was notably faster in the most resource-intensive scenario, S9.
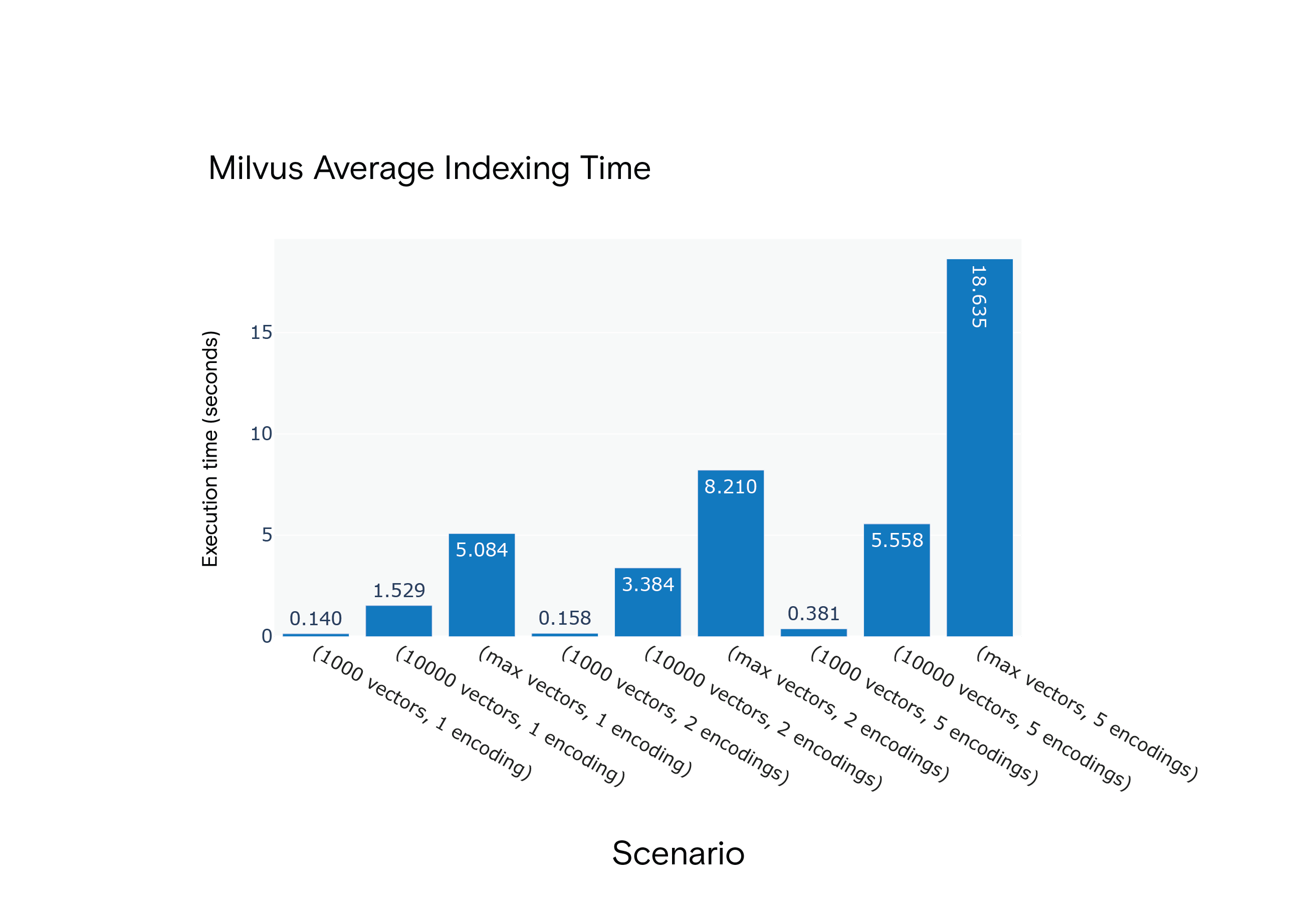 Milvus 1.1.1 Average Indexing Time for Scenarios S1 through S9
Milvus 1.1.1 Average Indexing Time for Scenarios S1 through S9
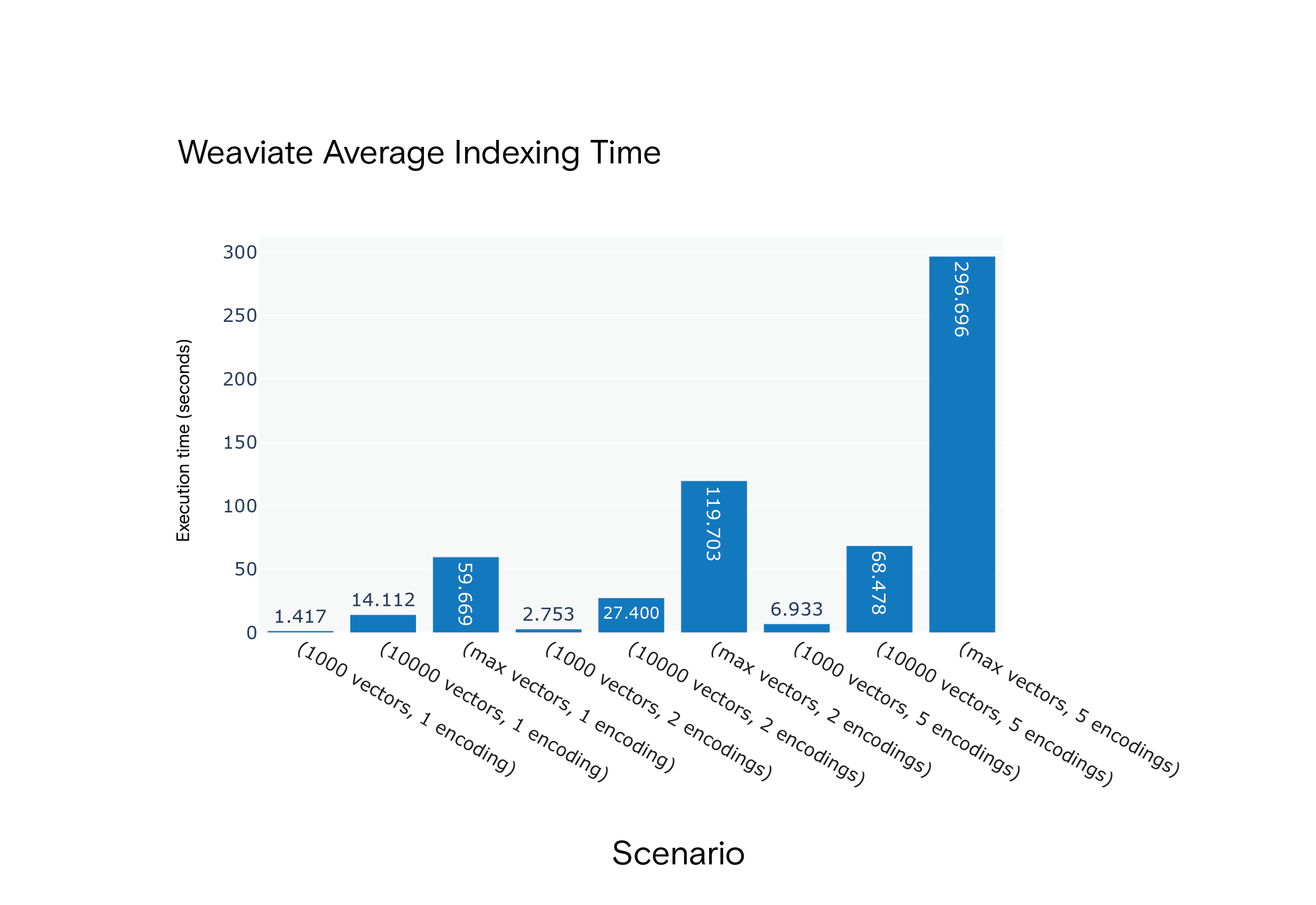 Weaviate Average Indexing Time for Scenarios S1 through S9
Weaviate Average Indexing Time for Scenarios S1 through S9
Querying
Weaviate: Its Python client supports vector search but only for a single vector at a time.
Milvus: Offers a more flexible search method that can handle a list of vectors, facilitating multi-vector querying.
Result: Milvus displayed shorter average querying times across all scenarios, even though it required a "warm-up" phase to reach optimal performance.
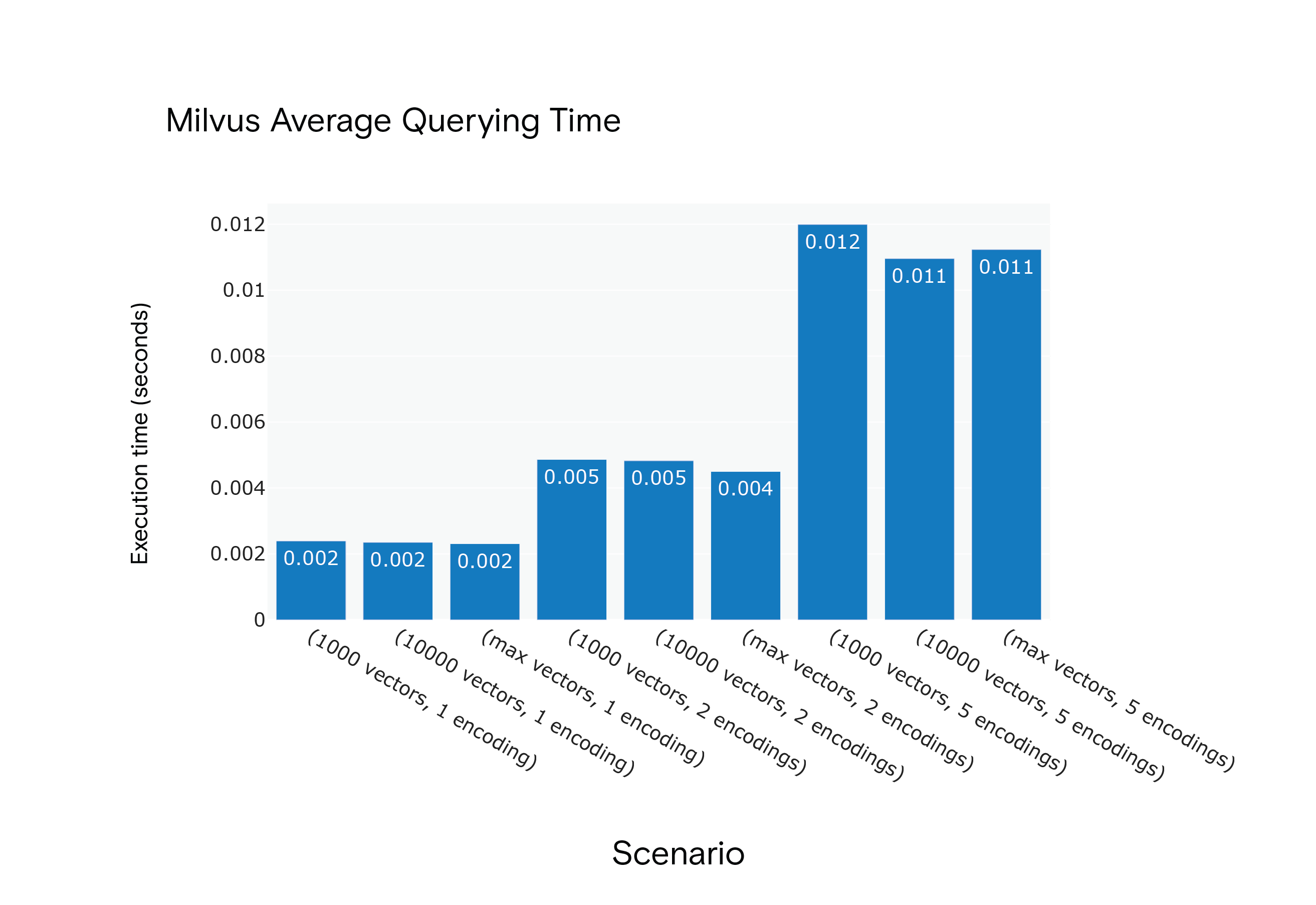 Milvus 1.1.1 Average Querying Time for Scenarios S1 through S9
Milvus 1.1.1 Average Querying Time for Scenarios S1 through S9
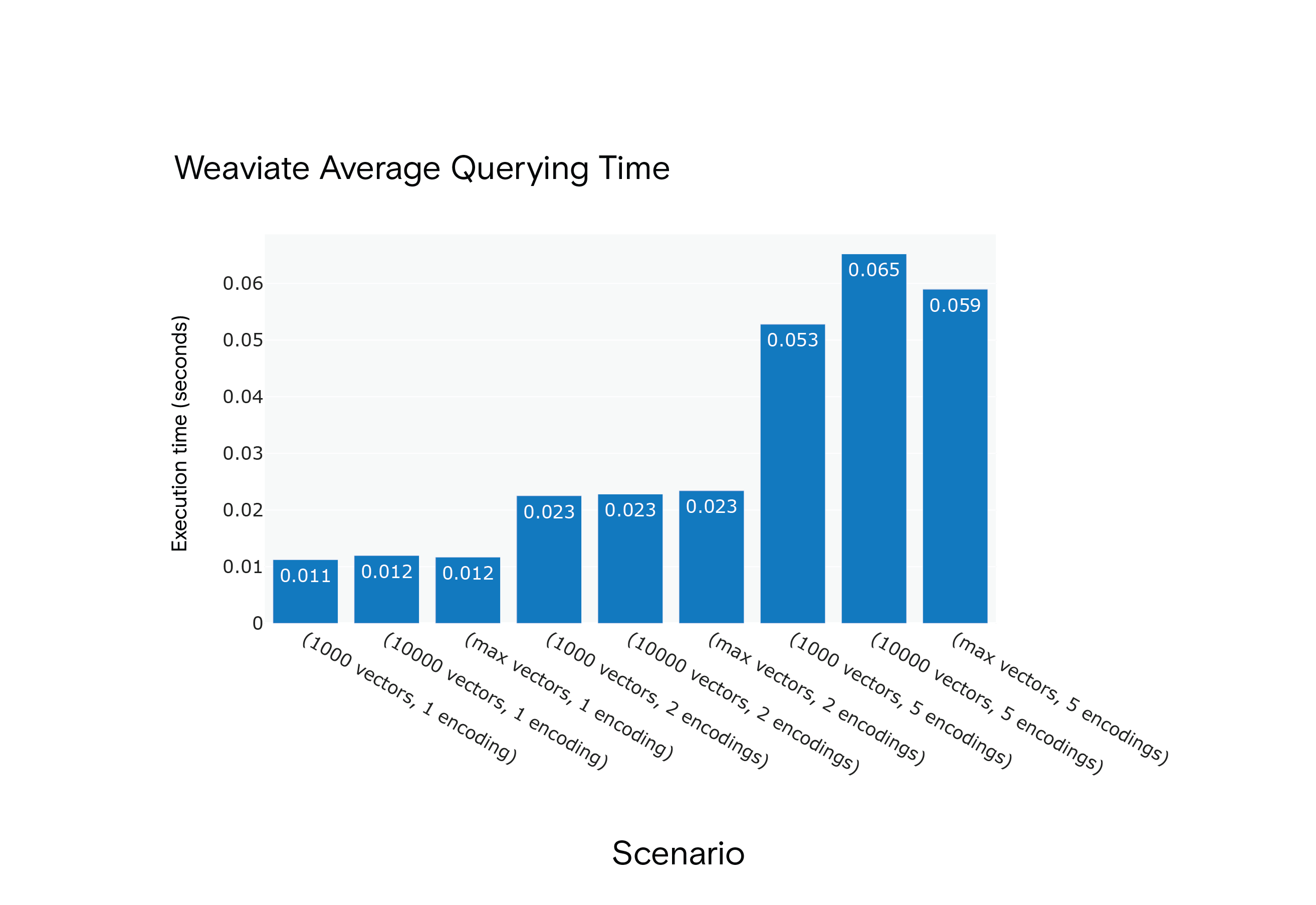 Weaviate Average Querying Time for Scenarios S1 through S9
Weaviate Average Querying Time for Scenarios S1 through S9
The Farfetch team felt that Milvus and Weaviate show promise but are still evolving. Features like horizontal scaling, sharding, and GPU support are on the roadmap. For FARFETCH, which aims to handle a product catalog ranging from 300k to 5 million products, the ideal VSE should offer:
- High-quality, accurate results
- Efficient indexing capabilities
- Fast query execution
- Scalability features like load balancing and data replication
Their experiments revealed that Milvus consistently outperformed Weaviate in indexing and querying times. However, it's worth noting that both platforms have certain limitations, such as the lack of support for multiple encodings. Their future work will closely monitor these platforms' development and potentially re-evaluate them as they introduce new features.
This case study is a condensed version of in-depth vector database benchmarking blogs originally published by PEDRO MOREIRA COSTA from Farfetch. For a more detailed analysis and insights, please refer to the original blog posts: POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART I and POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART II.