




データフローの効率化:ZillizがUpsert、Kafka Connector、Airbyte統合を発表
今日のデータドリブンな状況において、効率的なデータ取り込みと堅牢なデータパイプラインは、強力なデータベースシステムのバックボーンを形成します。Zillizでは、これらの分野における最近の機能強化、特にUpsert、Kafka Connector、Airbyte統合の導入は、パフォーマンス、汎用性、統合の容易さに優れたベクトルデータベースを開発者に提供するという当社のコミットメントを裏付けるものです。これらの新機能は、データハンドリングを合理化し、シームレスな統合とデータフローの制御を強化することで、開発者が複雑なデータ取り込みプロセスの管理に煩わされることなく、革新的なアプリケーションの作成に集中できるように設計されています。
Upsert によるデータ更新の合理化
旧バージョンのMilvusでは、多くのユーザーシナリオにおいてデータの更新は、削除→挿入という2段階のプロセスを必要としていました。この方法は機能的ではあるものの、データの原子性や操作の利便性を確保できないという欠点がありました。これらの課題を認識し、私たちはUpsert in Milvus 2.3を導入し、データ更新の処理方法を根本的に変更しました。現在、UpsertはZilliz Cloudでパブリックプレビュー中です。
Upsertは更新プロセスを簡素化します。データがシステムに存在しない場合は挿入し、存在する場合は更新します。このアプローチは、重要なアトミティティの概念に基づいて構築されており、Upsert操作は、挿入か削除かに関係なく、外部からは単一のアクションとして認識されます。
内部的には、この方法は型破りですが、非常に効果的です。この順序は、特に挿入と削除が異なるセグメントで処理されるMilvusのようなシステムにおいて、操作中のデータの可視性を維持するための鍵となる。
さらに、Upsertは主キーの変更を慎重に扱うように特別に設計されている。これは、Milvusが主キーのハッシュに基づいてシャード間でデータを管理する方法と一致している。この制約により、クロスシャード操作の複雑さや潜在的な不整合を回避することができます。
Upsertの使用は簡単で、多くの点でInsert操作を反映しています。開発者は、最小限の調整でUpsertを既存のワークフローに簡単に統合できる。例えば、PymilvusのようなSDKでは、UpsertコマンドはInsertと同様に呼び出すことができ、プラットフォームに慣れ親しんだ人々にシームレスなエクスペリエンスを提供する。
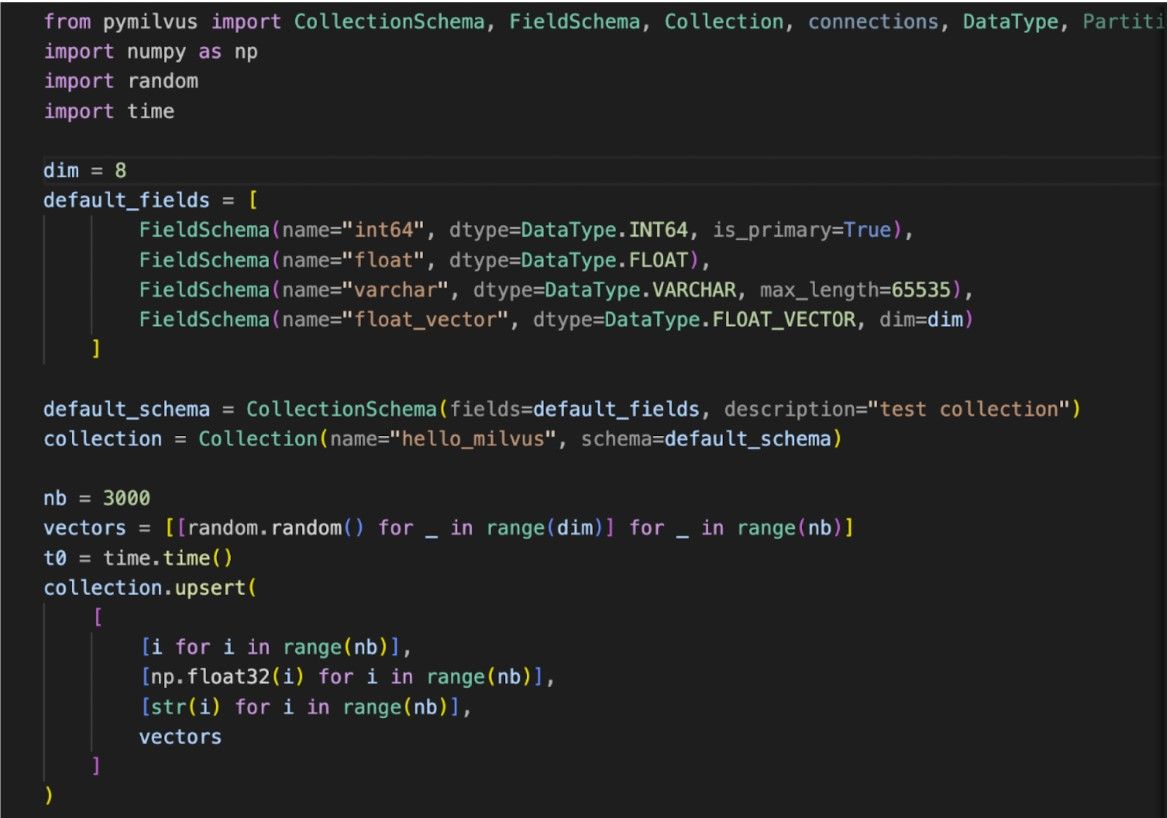
実行されると、Upsertは操作の成功と影響された行数に関するフィードバックを提供し、開発者の使いやすさを向上させます。このシンプルな使用法と操作の堅牢性が相まって、Upsertはデータ管理における貴重なツールとなっています。詳細については、Upsert ドキュメントを参照してください。
しかし、Upsertに関する特定の考慮事項を認識しておくことは重要である。
AutoIDの制約:** Upsertには、AutoIDがfalseに設定されている必要がある。コレクションのスキーマにAutoIDがtrueに設定されている場合、Upsert操作は実行できません。更新操作であるUpsertは、対応するデータのバッチを更新するためにプライマリ・キーの提出を必要とするため、この制限が存在します。ユーザーが提供した主キーとAutoIDが割り当てられた主キーが衝突し、データが上書きされる可能性があります。したがって、AutoIDを有効にしたコレクションは、今のところUpserをサポートできません。しかし、将来の反復では、この制限が削除されるかもしれません。
パフォーマンス・オーバーヘッド:** Upsertはパフォーマンス・コストが発生する可能性があります。MilvusはWrite-Ahead Logging (WAL)アーキテクチャを使用しており、過度の削除はパフォーマンス低下につながる可能性があります。これは、Milvusの削除オペレーションが直ちにデータを消去しないためです。その代わり、削除レコードでデータをマークします。このレコードは処理されるだけで、データは後のコンパクション処理で削除される。従って、頻繁な削除はデータの肥大化を招き、パフォーマンスに影響を与える可能性がある。最適なパフォーマンスを得るためには、アップサートを使いすぎたり、誤用したりしないことをお勧めします。
開発者が効率的かつ効果的なデータ処理に必要なツールを装備できるよう、データ管理機能を改良し、進化させるための継続的な取り組みとして、Upsertのような新機能がさらにリリースされる予定です。
Kafka Connectorによるリアルタイムデータソリューションの強化
当社は最近、オープンソースのMilvusおよびZilliz Cloudと共にKafka Sink Connectorを発表しました。この開発により、Confluent/ KafkaからMilvusまたはZillizベクトルデータベースへのベクトルデータのシームレスなリアルタイムストリーミングが可能になります。この統合は、非構造化データのパワーを活用し、特にOpenAIのGPT-4のような高度なモデルで、リアルタイムのジェネレーティブAIの能力を強化するために非常に重要である。
ZillizとConfluentのコラボレーションは、増え続ける非構造化データの管理と活用における大きな進歩を意味します。リアルタイムのベクトルデータストリーミングを可能にすることで、このデータを効率的に保存、処理し、簡単に検索できるようにする堅牢なソリューションを提供します。
このコネクターの使用例
ジェネレーティブAIの強化:** GenAIアプリケーションに最新のベクトルデータを提供することで、より正確でタイムリーな洞察が可能になります。これは、様々なデータソースからのストリーミングベクトル埋め込みが重要である金融やメディアなどの分野で特に有益です。
Eコマース推奨の最適化:** リアルタイムの在庫と顧客行動の更新により、Eコマース・プラットフォームは推奨商品を動的に調整し、ユーザー体験を向上させることができます。
この統合を始めるのは簡単です:
GitHub](https://github.com/zilliztech/kafka-connect-milvus#kafka-connect-milvus-connector) または Confluent Hub から Kafka Sink Connector をダウンロードする。
Confluent と Zilliz のアカウントを設定し、両方のプラットフォームでフィールド名が一致するようにする。
GitHub リポジトリの詳細な手順に従って、Connector をロードして設定します。
Connectorを起動し、KafkaからZillizへのリアルタイムデータストリーミングを体験する。
セットアップ、ユースケース、ステップバイステップの詳細なガイドについては、GitHub リポジトリ を参照し、Confluent インテグレーションページ をご覧ください。
Airbyte Integrationで効率的なデータ統合を促進する
我々は最近、Airbyteチームと協力してAirbyteをMilvusに統合し、大規模言語モデル(LLMs)とベクトルデータベースにおけるデータの取り込みと利用を変革した。この統合により、高次元のベクトルデータの保存、索引付け、検索が強化され、これは生成チャット応答や製品推奨のようなアプリケーションにとって極めて重要である。
統合の主なハイライト
効率的なデータ転送:** Airbyteは様々なソースからMilvus/ Zillizにシームレスにデータを転送し、オンザフライでのベクトル埋め込み計算を可能にし、データ処理を合理化します。
検索機能の強化:** この統合により、ベクトルデータベース内のセマンティック検索機能が強化されます。埋め込みを利用することで、意味的類似性に基づいて密接に関連するコンテンツを自動的に識別して表示することができ、非構造化データからの効率的な検索を必要とするアプリケーションにとって非常に貴重です。
Milvusクラスタのセットアップとデータ同期のためのAirbyteの設定は、StreamlitとOpenAIエンベッディングAPIを使ったアプリケーションの構築と同様に簡単です。
この統合により、データ転送と処理が効率化され、リアルタイムのAI駆動型アプリケーションに新たな可能性が生まれます。例えば、カスタマーサポートシステムでは、このテクノロジーを統合することで、セマンティック検索を利用したインテリジェントなサポートフォームを作成することができる。これにより、システムはユーザーに即座に適切な情報を提供できるようになり、サポート・エージェントによる直接介入の必要性が減り、全体的なユーザー・エクスペリエンスが向上する。
Zendeskをデータソースとして使用するような、詳細な実用例については、私たちのリリースブログを参照してください。この例では、実際のシナリオで統合を適用し、サポートチケット管理とナレッジベースへのアクセシビリティを強化する方法を示しています。
AirbyteとMilvusの統合は、AIとデータ管理における大きな前進であり、ベクトルデータを管理するための効率的なソリューションを提供します。AirbyteとMilvusの統合は、AIとデータ管理における大きな前進であり、ベクトルデータを管理するための効率的なソリューションを提供します。
結論
Upsert、Kafka Connector、Airbyteのようなツールの継続的な開発とZillizのベクトルデータベースとの統合は、非構造化データ管理技術の進歩に対する当社のコミットメントを強調するものです。これらの機能強化は、検索パフォーマンスを向上させ、データパイプライン全体を合理化し、より効率的で開発者に優しいものにするために調整されている。
今後、データ取り込みとパイプラインの機能をさらに拡張する予定です。非構造化データのハンドリングとAI駆動型アプリケーションの進化するニーズに対応するツールを提供し、イノベーションを続けていきますので、これらのアップデートにご期待ください。
私たちは、開発者コミュニティからのフィードバックと洞察を深く尊重し、継続的な改善に専念しています。皆様からの経験やご提案は、これらのテクノロジーを進化させる私たちの旅において非常に重要です。皆様からのフィードバックをお待ちしております。GitHubコミュニティ](https://github.com/milvus-io/milvus)にご参加いただくか、チケットこちらから直接フィードバックをお寄せください。

読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Top 5 AI Search Engines to Know in 2025
Discover the top AI-powered search engines of 2025, including OpenAI, Google AI, Bing, Perplexity, and Arc Search. Compare features, strengths, and limitations.