




Vector Lakebaseとは何ですか?
TL;DR
- Vector Lakebase は、ベクトルデータベース級のサービング、オープンなレイクストレージ、再利用可能なレイクレベルのインデックス、共有セマンティックレイヤーを組み合わせた、AI のための統合されたレイクネイティブなデータアーキテクチャです。
- これにより、同じ非構造化データ がオンラインサービング(RAG、エージェント、セマンティック検索)とオフラインディスカバリー(クラスタリング、重複排除、再埋め込み、ガバナンス)を支えることができます — システム間でデータをコピーする必要はありません。
- Zilliz Vector Lakebase は、このアーキテクチャの実装です。マネージドベクトルデータベースから統合 AI データプラットフォームへと進化した Zilliz Cloud です。
Vector Lakebase とは?
Vector Lakebase は、AI のための統合されたレイクネイティブなデータアーキテクチャです。ベクトルデータベース級のサービング、オープンなレイクストレージ、再利用可能なレイクレベルのインデックス、共有セマンティックレイヤーを組み合わせることで、同じ非構造化データがオンライン AI アプリケーション、インタラクティブなディスカバリー、オフライン分析をサポートできるようにします — システム間でコピーする必要はありません。これは、検索だけとは異なる問いに答えるものです。本番環境の AI チームが、検索、ディスカバリー、分析、ガバナンス、フィードバック、継続的改善のために同じデータを必要とする場合、何が起こるのでしょうか?
これはベクトルデータベースの置き換えではなく、拡張として理解するのが最適です。ベクトル検索は低レイテンシのサービングパスであり続けます。Vector Lakebase は、そのパスを、周囲のデータを保存、インデックス化、ガバナンス、継続的に改善できる、より広範な基盤の中に配置します。
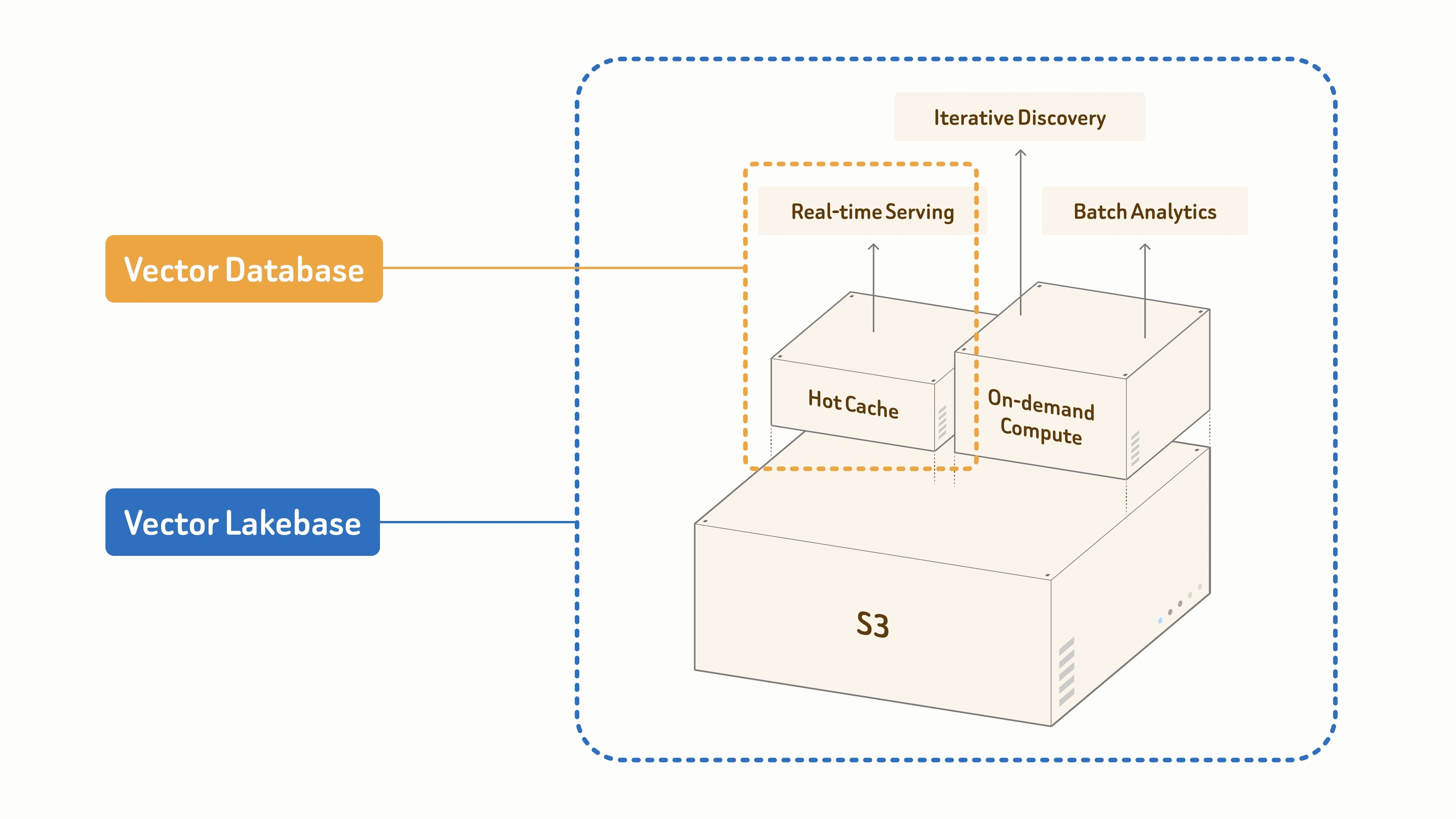
現代の AI ワークロードに Vector Lakebase が必要な理由
ベクトルデータベースは、現代 AI における最初のデータ課題を解決しました。それは、RAG、エージェント、セマンティック検索を支える、大規模で高速なセマンティック検索です。AI システムが広がるにつれて、その課題はこれまで以上に重要になっています。
しかし本番環境の AI チームは、同じデータからの検索以上のものをますます必要としています — トレーニングセットの重複排除とクラスタリング、異常およびドリフト検出、モデル変更時の再埋め込み、ガバナンスとリネージ、そして本番環境の挙動からのフィードバックです。
ほとんどのスタックは、これらのワークフローを別々のシステムとして扱います。生ファイル用のデータレイク、オンライン検索用のベクトルデータベース、前処理用のバッチパイプライン、埋め込みとインデックス用の個別ジョブです。データはそれらの間でコピーされ、インデックスは再構築され、オンラインサービングとオフラインディスカバリーは同期からずれていきます。
Vector Lakebase は、サービングとディスカバリーのための単一の論理的データ基盤を提供することで、この断片化を取り除きます。ベクトルデータベースが目的として構築された低レイテンシの検索パスを維持しつつ、データ、ベクトル、インデックス、メタデータ、セマンティックコンテキストを長期にわたって保存、ガバナンス、バージョン管理、再利用、改善できるレイクネイティブな基盤に接続します。目的は、ベクトルデータベースをレイクで置き換えることではありません。ベクトル検索、セマンティックコンテキスト、非構造化データ処理を単一のアーキテクチャに統合することです。(この変化の業界背景とエンジニアリングについては、Why We Built Vector Lakebase を参照してください。)
Vector Lakebase の中核設計原則:One Data、One Index、One Semantic Layer
Vector Lakebase アーキテクチャは、One Data、One Index、One Semantic Layer という 3 つの原則に基づいています。これらは、記録システムがどこに存在するか、インデックスがどのように管理されるか、意味がどのように整理されるかを示します。

One Data:共有データ基盤としてのレイク
One Data とは、オープンなレイクストレージが非構造化 AI データの共有基盤になることを意味します。生ファイル、クレンジング済みデータ、ベクトル、スカラー項目、メタデータ、インデックス成果物、セマンティックラベル、リネージ、オフライン処理結果がすべて、単一の論理的データ基盤内に存在します。
このアーキテクチャでは、ベクトルデータベースは新たなデータサイロではありません。低レイテンシのサービングパスの一部になります。権威あるデータはレイクネイティブのままであり、オンラインシステムは必要に応じてホットデータとインデックスをキャッシュします。これにより、重複ストレージ、ガバナンス、システム間移行が削減され、同じデータでオンラインアプリケーション、オフライン処理、モデル学習、評価、ガバナンスを支援できるようになります。
たとえば、RAG システムで使用されるドキュメントは、オフラインクラスタリングジョブ、学習データ探索ワークフロー、コンプライアンスレビュー、将来の再埋め込みプロセスの一部にもなり得ます。断片化されたアーキテクチャでは、各ワークフローが独自のコピーまたは派生表現を作成します。Vector Lakebase では、これらのワークフローは同じ論理的なデータ基盤上で動作します。
One Index: インデックスはレイクレベルの資産になる
One Index とは、インデックスが単一のオンラインサービングエンジンの内部に閉じ込められないことを意味します。インデックスは、構築、バージョン管理、再利用、そして異なるコンピュートモードにわたって提供できるデータ資産になります。これは重要です。なぜなら、インデックスは高コストで運用上も重要だからです — インデックスは、システムがデータをどのように検索し整理するかをエンコードします。すべてのワークフローが独自のインデックスを構築しなければならない場合、チームはコンピュートを浪費し、検索動作の不整合を生み、ガバナンスをより難しくします。
Vector Lakebase では、論理インデックスはアクセスパターンとコストに基づいて異なるサービング形態にマッピングできます。ホットインデックスはミリ秒レベルのオンライン検索を支え、ウォームデータはキャッシュまたは階層型ストレージを通じて提供され、コールドデータは探索、ガバナンス、オフライン分析のためにレイク内に残ります。同じインデックスのリネージは、RAG サービング、セマンティック検索、エージェントメモリ、データ探索、バッチ処理を支えることができ、チームはデータモデルを壊すことなく、適切なレイテンシとコストのプロファイルを選択できます。
One Semantic Layer: 意味が共有システムレイヤーになる
One Semantic Layer とは、システムが埋め込み以上のものを管理することを意味します。埋め込みは、基礎となる資産の 1 つの表現にすぎません。有用な AI データ基盤には、エンティティ、ラベル、要約、トピック、コンテキスト断片、ソース情報、モデルバージョン、アクセスポリシー、リネージ、フィードバックシグナルも必要です。このセマンティックレイヤーにより、チームはファイルパス、テーブル、バケット、コレクションだけではなく、意味に基づいて非構造化データを整理できます。
RAG システムは、セマンティックレイヤーから信頼できるコンテキストを検索できます。AI エージェントは、過去のタスク、メモリ、ツール呼び出し結果を理解できます。学習データワークフローは、カバレッジギャップ、重複、外れ値、バイアスを発見できます。ガバナンスシステムは、回答、特徴量、サンプルを、それを生成したソースデータとモデルバージョンまで追跡できます。
セマンティックレイヤーは、データフライホイールの中心でもあります。オンラインアプリケーションはクエリ、クリック、引用、修正、フィードバックを生成し、オフライン発見はそれらのシグナルをより良いメタデータ、よりクリーンなデータセット、改善されたインデックス、より強力なコンテキストへと変換し、その改善がサービングへ戻っていきます。そのループこそが、Vector Lakebase をストレージと検索以上のものにする場所です。
Vector Lakebase の仕組み: CS/CD フライホイール、4 つの段階
Vector Lakebase は、サービングと発見の間の継続的なループとして動作します — 私たちはこれを CS/CD (Continuous Serving and Continuous Discovery) と呼びます。 サービングはフィードバックと新しいデータを生成し、発見はそれをよりクリーンなデータとより良いインデックスに変換し、その改善がサービングへ戻っていきます。
運用上、同じループはデータ取り込み、ベクトル化とエンリッチメント、クエリサービング、オフライン処理という 4 つの段階を通じて実行されます。
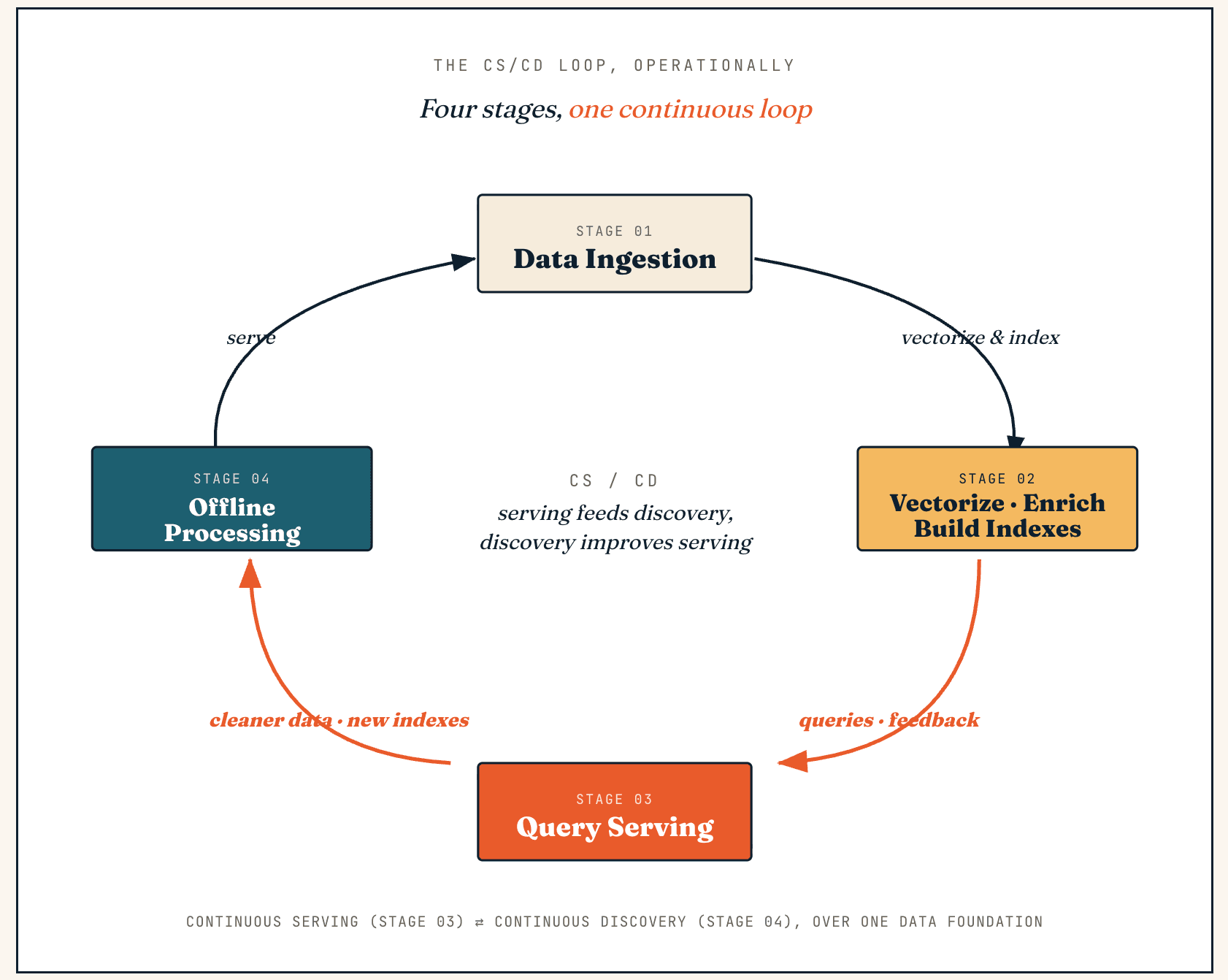
データ取り込み
データは、ベクトルデータベース API、ドキュメントパイプライン、オブジェクトストレージ、または既存のオープンレイクフォーマットを通じてシステムに入ることができます。データには、ドキュメント、ベクトル、スカラー項目、ビジネスメタデータ、画像、音声、動画、コード、ログ、会話、サポートチケット、エージェントトレースが含まれる場合があります。
非構造化データが増大するにつれ、取り込みはクリーニング、正規化、アクセス制御、ソース追跡、リネージにも対応する必要があります。システムは、データが何であるかだけでなく、それがどこから来たのか、どのモデルが処理したのか、誰がアクセスできるのか、どのように使用できるのかを把握する必要があります。これはエンタープライズAIにとって特に重要です。RAGシステムやエージェントは、取得したすべてのデータを同等に信頼できるものとして扱うことはできません。コンテキストには、ソースの認識、権限の認識、鮮度、そして場合によってはビジネス固有のガバナンスルールが必要です。
ベクトル化、エンリッチメント、インデックス構築
取り込み後、システムは埋め込みモデルとデータ処理ジョブを使用してベクトル表現を生成します。また、エンティティ、ラベル、要約、トピック、ソース情報、権限、タイムスタンプ、モデルバージョンといったメタデータでデータをエンリッチします。その後、レイクデータ上にクエリ構造を構築します。ベクトルインデックス、キーワードインデックス、全文インデックス、JSONインデックス、スカラーインデックス、そしてハイブリッド検索に必要なその他の構造です。
アーキテクチャ上、これが重要なポイントです。インデックスは特定のサービングエンジンに結び付けられていません。インデックスはバージョン管理、公開、再利用が可能で、構築元のデータスナップショットまで追跡できます。これにより、インデックスのライフサイクル管理は、1つのアプリケーション内に埋もれた実装の詳細ではなく、データ基盤の一部になります。
クエリサービング
Vector Lakebaseは、RAG、エージェント型検索、セマンティック検索、マルチモーダル検索、AIメモリ、レコメンデーション、その他のAIアプリケーションワークロードのための検索経路を提供します。クエリ経路では、低レイテンシが必要なホットデータにはベクトルデータベースまたはキャッシュレイヤーを使用し、よりコールドな、または頻度の低いワークロードにはレイクネイティブなデータとインデックスにアクセスできます。
クエリは、ベクトル検索、キーワード検索、全文検索、メタデータフィルタリング、スカラー述語、権限、ハイブリッドランキングを組み合わせることがあります。なぜなら、本番環境のAI検索がベクトル類似度だけに基づくことはほとんどないからです。優れた結果は多くの場合、意味的関連性、鮮度、アクセス権、ソース品質、ビジネスメタデータ、ユーザー意図に依存します。
オフライン処理
オフライン処理には、クラスタリング、重複排除、異常検知、データ品質分析、トレーニングデータ探索、スキーマ進化、再埋め込み、評価、インデックス再構築が含まれます。これらのワークフローは大規模なデータバッチ上で実行され、常にミリ秒単位のレイテンシを必要とするわけではありませんが、オンラインアプリケーションで使用される同じベクトル、メタデータ、インデックス、セマンティックコンテキストにアクセスする必要があります。
その出力は、よりクリーンなデータセット、より優れたラベル、改善されたコンテキスト断片、新しいインデックスバージョン、または更新されたフィードバックシグナルとして、レイク、インデックスシステム、セマンティックレイヤーに書き戻され、本番環境が構築途中のインデックスを読み取らないようにアトミックなスナップショットとして公開されます。これが中核となる運用ループです。サービングがフィードバックを生成し、ディスカバリーがデータを改善し、改善されたデータがサービングに戻ります。
Vector Lakebaseの3つのワークロード形態
AIデータワークロードは1つの形態ではありません。終日ミリ秒レベルのサービングを必要とするものもあります。短時間の分析セッションのためのインタラクティブ検索を必要とするものもあります。実行して結果を公開し、終了する大規模なオフライン処理ジョブを必要とするものもあります。単一の常時稼働オンラインストレージモデルでは、これらすべてを効率的にカバーすることはできません。
従来のベクトルデータベースは、主に最初のワークロード形態に最適化されています。Vector Lakebaseは、1つの論理データセット上で3つすべてに対応するように設計されています。
Zilliz Vector Lakebaseでは、これらのワークロードは3つのコンピュートモードに対応します — 長時間実行(常駐型、ミリ秒単位のサービング)、オンデマンド(インタラクティブ、分単位課金、サービングとディスカバリーの橋渡し)、オフラインバッチ(完了時にコンピュートを解放する大規模ジョブ)です。
| ワークロードの種類 | 典型的な例 | コンピュートパターン |
|---|---|---|
| リアルタイムサービング | 本番 RAG、エージェントメモリ、セマンティック検索、レコメンデーション、パーソナライゼーション、AI 検索 | ホットなインデックス、ウォームキャッシュ、予測可能なレイテンシを備えた長時間稼働のサービングクラスタ |
| インタラクティブな探索 | フィードバック分析、エージェントトレースの検査、異常検索、コールドデータ検索、セマンティック探索 | 必要なときに起動し、セッション終了時にリソースを解放するオンデマンドコンピュート |
| バッチ分析 | コーパスの重複排除、クラスタリング、全面的な再埋め込み、トレーニングデータ準備、インデックス再構築 | 実行され、結果を公開し、消える大規模ジョブ向けのバッチコンピュート |
Vector Lakebase の一般的なユースケース
Vector Lakebase は単一の基盤上でサービングと探索を統合するため、そのユースケースは2つのグループに分かれます。
 图片12
图片12
検索ユースケース(ベクトルデータベースと共通し、現在はガバナンスされた基盤上で実現):
- RAG — ドキュメント、ナレッジベース、コード、ログを検索可能なコンテキストとして扱い、常に最新に保ち、権限管理し、モデルの変化に応じて再インデックス化可能にします。
- AI エージェントメモリとツール利用 — エージェントメモリを保存・検索し、その後オフラインで分析して、得られた知見をフィードバックします。
- エージェント型およびマルチモーダル検索 — テキスト、画像、音声、動画、エンティティを横断した、ベクトル、キーワード、全文、メタデータ検索。
- レコメンデーションシステムなど。
データライフサイクルのユースケース(ベクトルデータベース単体でカバーできる範囲を超えるもの):
- 特徴量およびコンテキストエンジニアリング — エンティティ、要約、トピック、ラベル、クラスタを導出し、それらの元データの近くに保存します。
- トレーニングデータ探索 — サンプルをクラスタリングし、近重複を見つけ、外れ値を検査し、例をソースまで追跡します。
- 非構造化データの前処理 — 重複排除、異常検知、エンリッチメント、品質フィルタリングを行い、結果をレイクに書き戻します。
Vector Lakebase とベクトルデータベースおよび Lakebase との関係
Vector Lakebase は、ベクトルデータベースと Lakebase という2つのアーキテクチャに関連しています。どちらの代替でもありません。下の表は簡単な概要であり、続くセクションでそれぞれの関係を説明します。
| ベクトルデータベース | Vector Lakebase | Lakebase | |
|---|---|---|---|
| 主要データ | ベクトル埋め込み + 関連する非構造化データ | 非構造化・マルチモーダルデータ、およびそれを取り巻くライフサイクル全体 | 構造化 / トランザクション型アプリケーションデータ |
| 中核的な役割 | 低レイテンシのセマンティック検索 | 単一の基盤上でオンラインサービングとオフライン探索を統合 | オープンなレイクストレージにデータベース(OLTP)機能をもたらす |
| インデックス | サービングエンジン内で構築・保持 | レイクレベルのアセット:構築、バージョン管理され、コンピュートモード間で再利用される | テーブル / SQL インデックス |
| コンピュート | 常時稼働のサービング | 長時間稼働 + オンデマンド + オフラインバッチ | トランザクション型 |
| 記録のストレージ | 多くの場合エンジンに結合 | オープンなレイクストレージ | オープンなレイクストレージ |
| 最適な用途 | オンラインアプリケーション向けの高速ベクトル検索 | 大規模な非構造化データのサービングと継続的な改善 | レイク上のトランザクション型アプリデータ |
| vector lakebase との関係 | Vector Lakebase 内のサービングエンジンになる | - | 同じレイクネイティブな考え方における構造化データ側の対応物 |
Vector Lakebase とベクトルデータベースの比較
Vector Lakebase はベクトルデータベースを置き換えるものではありません。 組織が単一のアプリケーション向けに低レイテンシのベクトル検索だけを必要としている場合、ベクトルデータベースで十分なことがあります。レイテンシ、スケール、フィルタリング、運用上の信頼性が重要な本番検索において、それは引き続き適切なシステムです。たとえば Milvus は、この種の本番向けベクトル検索のために構築されています。
組織が同じ非構造化データ、埋め込み、インデックス、セマンティックコンテキストを、多数のチーム、モデル、アプリケーション、処理ワークフローで再利用する必要がある場合、判断基準は変わります。
その世界では、ベクトルデータベースはデータとインデックスが存在する唯一の場所であるべきではありません。それは、より広範な非構造化データアーキテクチャの内部にあるサービングエンジンになります。その役割はより具体的で、より重要になります。つまり、AIアプリケーションが必要とするサービングパスを提供し、その一方でVector Lakebaseはそのパスを取り巻くより広範なデータ基盤を提供します。その結果は、ベクトル検索が少なくなることではありません。非構造化データのライフサイクル全体に接続されたベクトル検索になるのです。
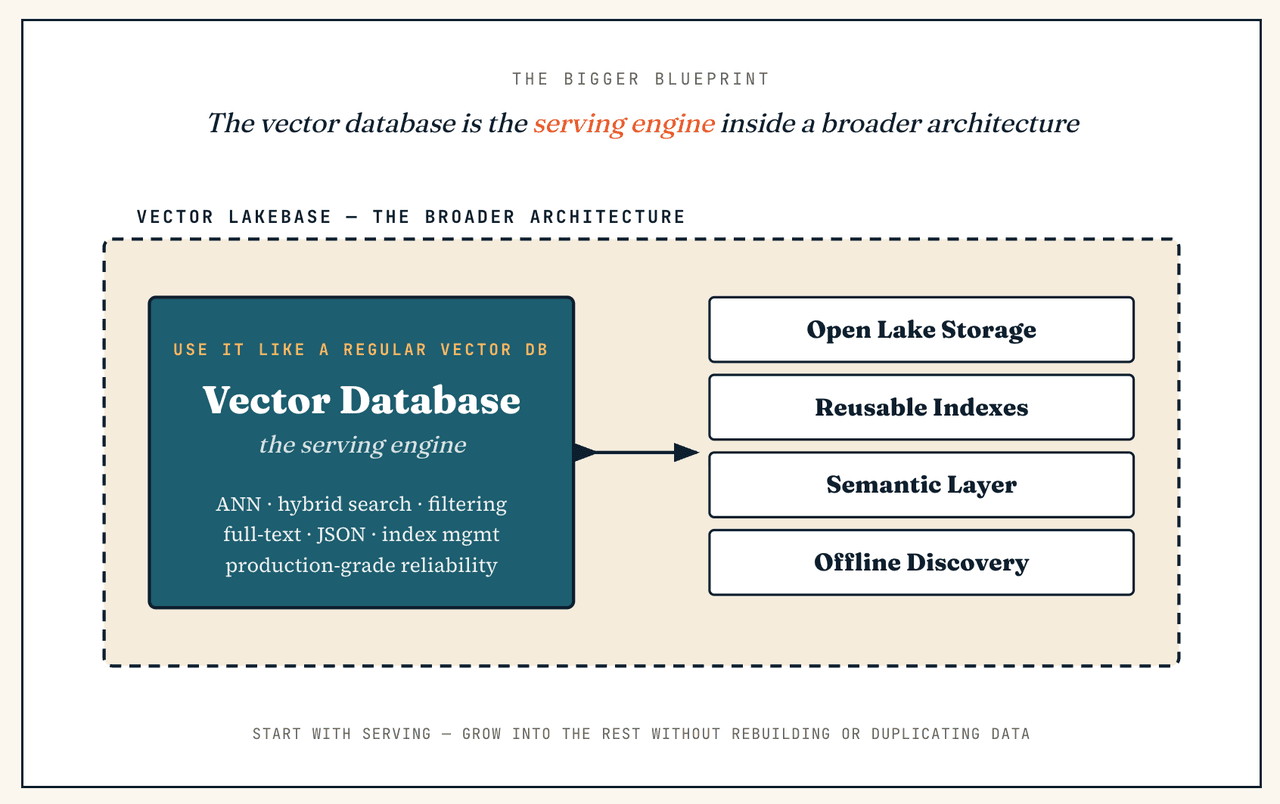
ベクトルデータベースだけが必要な場合でも、Vector Lakebaseは適していますか?
それはまったく妥当な出発点です。なぜなら、ベクトルデータベースはすでにVector Lakebaseの一部だからです。サービングクラスターレイヤーを、スタンドアロンのベクトルデータベースとまったく同じように使用できます(低レイテンシのANN検索、ハイブリッド検索、メタデータフィルタリング、全文検索、JSONフィルタリング、インデックス管理、本番環境での信頼性)。そして初日からインタラクティブな探索やバッチ分析に触れる必要はありません。違いは、検索専用アーキテクチャに閉じ込められないことです。後でワークロードがコールドデータ検索、大規模重複排除、再埋め込み、トレーニングデータ準備、またはセマンティックガバナンスへ拡張された場合でも、より広範なアーキテクチャはすでに整っています。再構築も、データの重複も不要です。
Vector Lakebase vs. Lakebase
Vector LakebaseはLakebaseに関連していますが、単なる「Lakebaseにベクトルを追加したもの」ではありません。

Lakebaseスタイルのアーキテクチャは、構造化されたアプリケーションデータのために、オープンなレイクストレージへデータベースのような機能をもたらします。つまり、構造化レコード、トランザクション、スキーマ、エラスティックコンピュート、統合ガバナンスであり、既知のフィールドと関係を通じてクエリされます。
Vector Lakebaseが対象とする重心は異なります。AIのための非構造化データとマルチモーダルデータです。問題は、アプリケーション状態をレイク上にどのように保存するかではありません。非構造化データに対して、セマンティック表現、ベクトルインデックス、メタデータ、コンテキスト、フィードバック、オフライン探索ワークフローをどのように管理するかです。そこでは、既知のフィールドに対するルックアップではなく、セマンティックな解釈、検索、改善、フィードバックが必要になります。これはLakebaseの代替ではなく、ベクトル、インデックス、セマンティックコンテキストの時代へLakebaseの考え方を拡張したものと表現するのが最も適切です。
| Dimension | Lakebase | Vector Lakebase |
|---|---|---|
| 主要データ | 構造化されたアプリケーションデータ、トランザクションレコード、アプリケーション状態 | ドキュメント、画像、音声、動画、ログ、コード、会話、ベクトル、メタデータ、セマンティックコンテキスト |
| 中核となる抽象概念 | テーブル、トランザクション、スキーマ、ブランチ、クローン | ベクトル、インデックス、チャンク、エンティティ、ラベル、要約、権限、フィードバック、セマンティックな関係 |
| 主なワークロード | アプリケーションの読み書き、トランザクション、リアルタイム分析 | RAG、エージェントメモリ、エージェント型検索、マルチモーダル検索、探索、コンテキストエンジニアリング、トレーニングデータワークフロー |
| クエリモデル | SQL、トランザクションクエリ、分析クエリ | ベクトル検索、ハイブリッド検索、全文検索、JSONフィルタリング、マルチモーダル検索、セマンティック探索 |
| セマンティックモデル | ビジネス上の意味は主にスキーマを通じて表現される | 意味は埋め込み、メタデータ、エンティティ、要約、モデルバージョン、リネージ、フィードバックを通じて表現される |
| AI価値 | オープンなレイクストレージにデータベースのような機能をもたらす | レイクネイティブな非構造化データに、AIコンテキスト、ベクトルインデックス、セマンティック検索、オフライン探索をもたらす |
Vector Lakebaseではないもの
Vector Lakebaseは新しいアーキテクチャパターンであるため、それが何ではないのかを明確にしておく価値があります。
- 列に保存された埋め込みを持つ単なるデータレイクではありません。 レイクテーブルに埋め込みを保存すればベクトルは保持されますが、本番AIシステムが必要とするインデックス作成、サービング、セマンティックメタデータ、ハイブリッド検索、フィードバックループ、低レイテンシの検索パスは何も提供されません。ベクトルが有用なのは、検索でき、ガバナンスされ、バージョン管理され、フィルタリングされ、ソースデータと接続され、時間とともに改善できる場合であり、単に保存されているだけではありません。
- object storageに接続された単なるベクトルデータベースではありません。ベクトルデータベースの背後にobject storageを置けばストレージコストは下がるかもしれませんが、インデックスの再利用、オフライン発見、ガバナンス、バージョン管理、処理済みデータと提供データの一貫性には対処できません。難しいのはバイトがどこに存在するかではなく、データ、インデックス、メタデータ、セマンティックシグナル、コンピュートモードが、1つの運用システムとしてどのように連携するかです。
- オフライン分析システムではありません。 オフライン発見はアーキテクチャの片側にすぎません。Vector Lakebaseは本番トラフィックにも対応し、ホット検索パスをサポートし、インデックスを管理し、アクセス制御を適用し、アプリケーションやエージェントに関連性の高いコンテキストを返します。目的はサービングと分析のどちらかを選ぶことではなく、それらを接続することです。
- ベクトルデータベースからの離脱ではありません。 これは、私たちが繰り返し述べてきた中で最も重要な点かもしれません。Vector Lakebaseはベクトルデータベースの重要性を低下させるものではありません。それらが動作するための、より広いアーキテクチャを提供するものです。
Zilliz Vector Lakebaseはパブリックプレビューで利用可能です
私たちはZilliz Vector Lakebaseのパブリックプレビューを開始しました。これは、Zilliz Cloudを純粋なマネージドベクトルデータベースから、低レイテンシのベクトルサービングと、データレイクのオープン性、スケーラビリティ、経済性を組み合わせた統合セマンティックデータプラットフォームへと進化させる大きな一歩です。
Zilliz Vector Lakebaseの主要機能:
- 階層型サービング さまざまなリアルタイム性能とコストのトレードオフに最適化
- オンデマンド検索 常時稼働のコンピュートなしで、大規模または探索的ワークロードに対応
- 外部データレイク検索 — 既存のレイクデータに対して直接インデックスを作成し検索
- フルスペクトラムAI検索 ベクトル、テキスト、JSON、地理空間データを対象に、ハイブリッド検索とリランキングを実行
- Vortex上に構築された統合レイクネイティブストレージ LanceやParquetよりも高速かつ低コストなランダム読み取りを実現するオープンフォーマット
現在のスタックでサービングと発見が別々のシステムに分かれているなら、Vector Lakebaseは検討する価値があるかもしれません。Zilliz Cloudでお試しください — 新規の仕事用メール登録で$100分の無料クレジットを提供しています — または、あなたのユースケースについてご相談ください。
Vector Lakebaseについてさらに学ぶ
読み続けて

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.