




Amazon S3 Vectorsはベクトルデータベースを葬るのか、それとも救うのか?
つい最近、AWS は新しいものを発表しました。S3 Vectors です。これは同社初のベクトルストレージソリューションへの取り組みで、セマンティック検索のためのベクトル埋め込みを Amazon S3 内で直接保存・クエリできるようにするものです。
一見すると、低コストのオブジェクトストレージ上で動作する軽量なベクトルデータベースのように見えます。その価格帯は、多くの専用ベクトルデータベースソリューションと比べて明らかに魅力的です。
 amazon s3 vectors.png
amazon s3 vectors.png
当然ながら、これは多くの熱い議論を呼びました。ソーシャルメディアやエンジニアリング界隈では、これが Milvus、Pinecone、Qdrant などを含む、専用ベクトルデータベースの終わりになるかもしれない、と言う人たちを見かけました。大胆な主張ですよね?
Milvus のエンジニアリングアーキテクトとして、そしてベクトル検索について夜更けまで考えすぎてきた者として、私はこう認めざるを得ません。S3 Vectors は、特にコストと AWS エコシステム内での統合という点で、興味深いものをもたらしています。しかし、ベクトルデータベースを「殺す」のではなく、私はこれがエコシステムの中で補完的なピースとして収まると見ています。実際、その本当の未来は、プロフェッショナルなベクトルデータベースを置き換えることではなく、それらと共に機能することにあるでしょう。
この記事では、なぜ私がそう考えるのかを、技術そのもの、それができること・できないこと、そして市場にとって何を意味するのかという3つの観点から説明します。
意外な事実:ベクトルストレージは LLM 呼び出しより高くつくことがある
ベクトル検索は強力ですが、重大な落とし穴があります。高価なのです。 計算需要は、典型的な NoSQL データベースで見られるものよりも、しばしば1桁から2桁高くなります。その差は理論上の話だけではなく、実際の請求額に表れます。
最近、人気のある AI ノートアプリの CTO と話したところ、驚くべきことを教えてくれました。彼らは OpenAI API 呼び出しにかける費用の 2倍 もの金額 をベクトル検索に費やしているのです。少し考えてみてください。検索レイヤーを動かすコストが、LLM そのものに支払うコストを上回っているのです。これは、通常の前提を根底から覆します。
2022年の ChatGPT ブームは、この状況をさらに明白にしました。突然、埋め込みは至るところで使われるようになり、ベクトルデータはパブリッククラウド上で最も急成長するデータ型になりました。Retrieval-Augmented Generation (RAG) がその原動力であり、それに伴って Milvus のようなベクトルデータベースが対応すべき3つの課題が生まれました。
大規模なデータ爆発: ワークロードは、ほぼ一夜にして数千万ベクトルから数百億ベクトルへと跳ね上がりました。これは線形の成長ではなく、量子的な飛躍であり、従来のデータ処理方法を破綻させました。
レイテンシ許容度の変化: LLM はそもそも応答生成に時間がかかるため、ユーザーは多少遅い検索に対してより寛容になりました。「何が何でもサブ10msのリコール」という考え方は、突然それほど重要ではなくなりました。
コスト感度の急上昇: データ量が2倍、3倍になることは、単なるストレージ問題ではありませんでした。従来のコンピュート重視の設計でスケールしようとすれば、財務上の危機になったのです。
要するに、ベクトルデータベースは急速に進化する必要がありました。それは技術が機能しなかったからではなく、検索の経済性が突然、最重要課題として前面に出てきたからです。
ベクトルストレージの進化:メモリからディスクへ、そして今やオブジェクトストレージへ
コストとスケールをめぐる圧力は、ひとつの結論を強制しました。ベクトルデータベースは、永遠にメモリ専用のままではいられなかったのです。まずディスクへ、そして今では S3 のようなオブジェクトストレージへと進化する必要がありました。これは選択ではなく、業界として避けられない流れでした。そしてこの分野を追ってきたなら、ここ数年で私と同じ傾向に気づいているはずです。
私は、ベクトルデータベースが3つの明確な段階を経てきたのを見てきました。
フェーズ I(2018~2022年):純粋メモリの時代: Milvus の初期には、HNSW や IVF のようなメモリインデックスに依存していました。性能とリコールは素晴らしかったのですが、コストは過酷でした。メモリは安価にはスケールせず、クラウド料金を支払っていた誰もがそれを知っていました。
フェーズ II(2022~2024年):ディスクインデックス革命: メモリのボトルネックを打破するため、私たちは DiskANN と、独自の Cardinal インデックス(マネージド Milvus である Zilliz Cloud 限定)を使用したディスクベースのアプローチを先駆けて導入しました。非同期 I/O(AIO)や io_uring のような工夫により、ディスクから実用的な性能を引き出すことに成功しました。その結果は? コストを 3~5 倍削減できました。容量最適化コンピュートユニット(CU)は、Zilliz Cloud ですぐにベストセラーになりました。
フェーズ III(2024年~):階層型ストレージの時代: 次のステップは明らかでした。ベクトルインデックスを安価なオブジェクトストレージへ押し出すことです。TurboPuffer のような新しいプレイヤーは S3 に全面的に賭け、ストレージコストを月額約 ~$0.33/GB まで引き下げました—10 倍の削減です。しかし、そのトレードオフも同じく明確でした。コールドクエリのレイテンシは 500ms~1s の範囲になり、リコール精度も低下します。
Zilliz では、以前から階層型ストレージに取り組んできましたが、コールドクエリ性能を制御できるようになるまでリリースを控えていました。来月、Zilliz Cloud で真のホット/コールド分離を備えたアップグレード版の拡張容量 CU を展開する予定です。つまり、500ms 未満の安定したコールドクエリレイテンシと、ホットクエリ向けの超高 QPS を両立します。言い換えれば、両方の長所を兼ね備えたものです。
Amazon S3 Vectors が絶好のタイミングで登場
階層型ストレージがすでにその有効性を証明している中、AWS が S3 Vectors で参入したのは驚くことではありません。実際、このリリースは業界全体ですでに起きていた流れの自然な延長のように感じられます。Amazon は S3 Tables のような機能で S3 の役割を拡張し、「単なるオブジェクトストレージ」からマルチモーダルなコールドストレージ基盤へと進化させてきました。ベクトルは、その進化における次のモダリティにすぎません—そして、おそらくそこで止まることはないでしょう。グラフ、キー値、時系列データもすべて同じ道をたどる可能性があります。
そして Amazon は、三つの否定しがたい利点をもたらします。
低コスト:業界でも最も低い水準のストレージ価格。
大規模スケール:AWS のマシンプールは、ほぼあらゆるクエリ負荷を吸収できます。
マイクロサービスネイティブなアーキテクチャ:ベクトルインデックスの書き込み–ビルド–クエリのワークフローと完全に一致します。
これらを組み合わせることで、S3 Vectors はベクトル向けの超低コストで高度にスケーラブルなコールドストレージソリューションとなる素地を備えています。
S3 Vectors は真の価格破壊者だが、明確な限界がある
S3 Vectors が発表されるとすぐに、私たちのチームは包括的なテストを実施しました。その結果は目を見張るものでした—単にどれほど安いかという点だけでなく、どこからほころびが見え始めるかという点でもです。
S3 Vectors は真の価格破壊者
これは否定できません。S3 Vectors は非常にコスト効率に優れています。
ストレージはわずか $0.06/GB で、ほとんどのサーバーレスベクトルソリューションよりおよそ 5 倍安価です。代表的なワークロード—たとえば 4 億ベクトルと月間 1,000 万クエリ—では、請求額は約 $1,217/月になります。これは従来のベクトルデータベースと比較して 10 倍以上の削減です。低 QPS でレイテンシに寛容なワークロードにとっては、ほぼ無敵です。
しかし性能には現実的な制約がある
コレクションサイズの制限: 各 S3 テーブルは最大 5,000 万ベクトルまでで、作成できるテーブル数は最大 10,000 個です。
コールドクエリ: レイテンシは 100 万ベクトルで約 500ms、1,000 万ベクトルで約 700ms です。
ホットクエリ: レイテンシは 200 QPS で 200ms 未満に収まりますが、その 200 QPS の上限を超えて押し上げるのは困難です。
書き込み性能: 2MB/s 未満に制限されています。これは Milvus(GB/s を処理可能)より桁違いに低いものの、評価すべき点として、書き込みがクエリ性能を劣化させることはありません。つまり、大規模で頻繁に変化するデータセットを扱うシナリオ向けには設計されていないということです。
精度と機能性のトレードオフ
精度の話は、厄介なところです。Recall は 85〜90% 程度で推移し、それをさらに高めるための調整ノブはありません。フィルターを重ねると、Recall は 50% 未満に落ちることがあります。データの 50% を削除したあるテストでは、TopK クエリが 20 件の結果を要求したにもかかわらず、15 件しか返せませんでした。
機能性もまた絞り込まれています。TopK クエリの上限は 30 です。レコードあたりのメタデータには厳格なサイズ制限があります。そして、ハイブリッド検索、マルチテナンシー、高度なフィルタリングといった機能は見当たりません。これらはいずれも、多くの本番アプリケーションにとって必須の機能です。
S3 Vectors を解剖する: 想定されるアーキテクチャ
テストを実施し、それを馴染みのある AWS の設計パターンと照らし合わせた結果、S3 Vectors が内部でどのように動作しているかについて、かなり有力な仮説が形成されました。Amazon は詳細を完全には公開していませんが、その性能特性は 5 つの中核技術を示唆しています。
SPFresh Dynamic Indexing: 各書き込みの後にインデックス全体を再構築するのではなく、S3 Vectors は影響を受ける部分だけを更新しているように見えます。この設計により書き込みコストは低く、可用性は高く保たれますが、代償もあります。更新後に Recall 率が数パーセントポイント低下するのです。
Deep Quantization (4-bit PQ): S3 の I/O オーバーヘッドを削減するため、埋め込みは 4-bit product quantization を使って圧縮されている可能性が高いです。
利点: ストレージが安価で、クエリも高速に保たれます。
欠点: Recall は約 85% 前後で頭打ちになり、開発者がそれ以上に調整するためのノブはありません。
Post-Filter Mechanism: フィルタリングは粗い検索の後に適用されているように見えます。これによりインデックスは統一されシンプルに保たれますが、複雑な条件には苦戦します。私たちのテストでは、データの 50% を削除した際、20 件の結果を要求する TopK クエリが 15 件しか返しませんでした。これは post-filter パイプラインの典型的な兆候です。また、Amazon がゼロから独自のものを構築するのではなく、既存のオープンソースのインデックス設計に大きく依存したことも示唆しています。
Multi-Tier Caching: ホットクエリははるかに高速に動作しますが、これはおそらく S3 の前段に SSD/NVMe キャッシュが置かれているためです。しかし、クエリがキャッシュミスすると、レイテンシは大きく跳ね上がります。このパターンは、オブジェクトストレージに内在する遅さを覆い隠すために構築された多層キャッシュ階層と一致します。
Large-Scale Distributed Scheduling: AWS にはマシンプールが豊富にあります。S3 Vectors はワークロードをマイクロサービス全体に分散し、read → decompress → search の流れをパイプライン化しているようです。その結果、テストで観測したように、高負荷下でも驚くほど安定したレイテンシ分布が得られています。
S3 Vectors が適する場所: 特定の用途に適したツール
S3 Vectors を徹底的に試した結果、得意なシナリオと不得意なシナリオがあることは明らかです。ほとんどのインフラツールと同様に、万能の解決策ではありません。適切な仕事に対して適切なツールなのです。
うまく機能する場面
コールドデータのアーカイブ: めったにアクセスされない履歴データセットの保存に最適です。500ms 以上のクエリ時間を許容できるなら、コスト削減効果は圧倒的です。
低 QPS の RAG クエリ: 1 日に数十件のクエリしか実行せず、100 QPS 未満に収まる小規模な社内ツールやチャットボットを想像してください。こうしたユースケースでは、レイテンシは致命的な問題ではありません。
低コストのプロトタイピング: インフラに多額を費やさずにアイデアを検証することが目的の proof-of-concept プロジェクトに最適です。
苦戦する場面
高性能な検索とレコメンデーション: アプリケーションが50ms未満のレイテンシを必要とする場合、S3 Vectorsはそのために作られているわけではありません。
大量の書き込みまたは頻繁な更新: 高い変更頻度の下ではパフォーマンスが急速に低下し、再現率の精度も目に見えて落ちます。
複雑なクエリワークロード: ハイブリッド検索、集計、その他の高度なクエリ機能はサポートされていません。
マルチテナントの本番アプリ: 10,000バケットという厳格な上限があるため、大規模なマルチテナントデプロイ向けには設計されていません。
言い換えれば、S3 Vectorsはコールドで安価、低QPSのシナリオには優れていますが、レコメンデーションシステム、リアルタイム検索アプリ、あるいは大規模な本番システムを支えるエンジンとして望ましいものではありません。
未来は階層型ベクトルストレージ
S3 Vectorsはベクトルデータベースの終わりを意味するものではありません。むしろ、多くの人がしばらく前から目にしてきたことを裏付けています。未来は階層型ストレージなのです。すべてのベクトルを高価なメモリや高速ディスクに保持するのではなく、ワークロードはアクセス頻度やアプリケーションが許容できるレイテンシの種類に応じて、ホット、ウォーム、コールドの各層に自然に分散していきます。
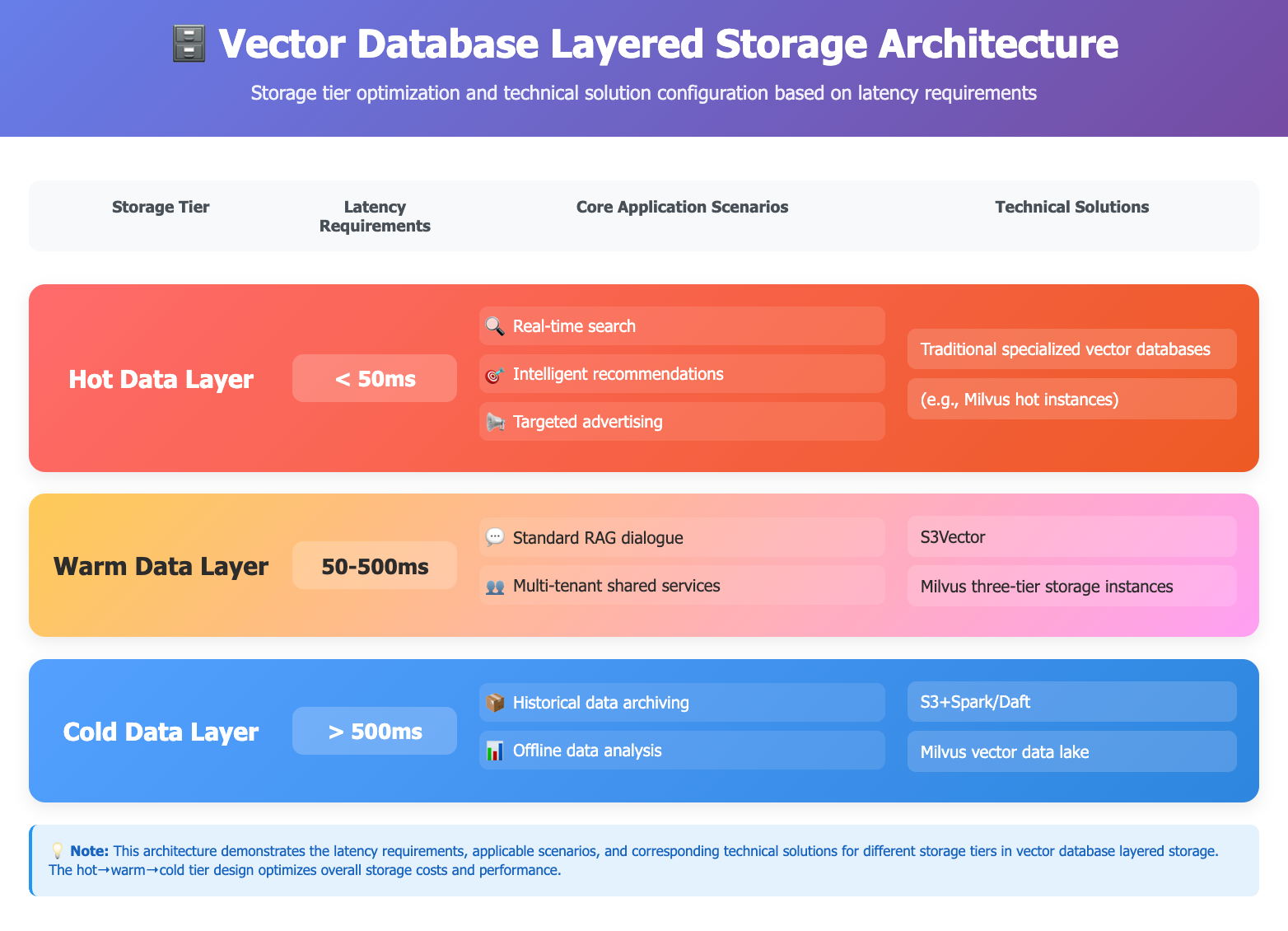
実際には次のようになります。
ホットデータ層(<50ms) – ここにはリアルタイム検索、レコメンデーション、ターゲティング広告が含まれます。レイテンシは50ms未満である必要があり、つまり専用のベクトルデータベースが依然として最適な選択肢です。それらは圧倒的な速度と高いクエリスループットの両方に最適化されています。
ウォームデータ層(50〜500ms) – 多くのRAGベースのアプリケーションやマルチテナントの共有サービスがここに当てはまります。これらのワークロードは超低レイテンシを必要としませんが、低コストで予測可能なパフォーマンスを必要とします。S3 VectorsとMilvusの階層型ストレージインスタンスは、この中間領域に適合します。
コールドデータ層(>500ms) – 履歴アーカイブやオフライン分析はリアルタイム応答を必要としないため、数百ミリ秒のレイテンシでも許容できます。ここで重要なのは、大規模スケールでのコスト効率です。S3 + Spark/DaftやMilvusベクトルデータレイクのようなソリューションが力を発揮する領域です。
ホット・ウォーム・コールドの分割は、単一のストレージ層だけではカバーできない形で、レイテンシ、コスト、スケールのバランスを取ります。これはリレーショナルデータベース、データウェアハウス、さらにはCDNでも以前に見られたパターンであり、ベクトルストレージも今、同じ軌跡をたどっています。この3層アーキテクチャは、MilvusとZilliz Cloudのために私たちが構築してきたロードマップとも密接に一致しています。
1. 統合されたオンライン + オフライン処理アーキテクチャ
AIアプリケーションは、「オンライン」と「オフライン」という別々の世界にきれいに収まるものではありません。実際には、データはその2つの間を常に移動しています。だからこそ、今後のMilvus 3.0では、同じデータセットからリアルタイム検索とオフライン処理の両方をサポートするように設計されたベクトルデータレイクを導入します。
実際には、これは1つのデータセットでライブRAGや検索クエリを支えつつ、Sparkベースのオフライン分析にも供給できることを意味します。たとえば、LLM向けのトレーニングデータのキュレーションです。重複も、2つの異なるパイプラインのやりくりも不要です。
また、ベクトルデータレイク向けにStorageV2 formatも展開します。これにより、経済性がさらに別のレベルへ引き上げられます。
コールドデータストレージで最大100倍安価。
ホットデータに対するブルートフォースのSparkクエリより最大100倍高速。
その結果、冗長性を最小限に抑え、コストを管理し、ベクトルデータの扱いをはるかに楽にする統合システムが実現します。
2. AI開発者が本当に必要とする機能を構築する
過去2年間で、AIアプリケーションは急速に進化してきました。そして、その背後にあるインフラへの要件も同じように急速に変化しています。Zillizでは、こうしたニーズに歩調を合わせてMilvusを前進させ、BM25 + vector hybrid search、multi-tenant分離、hot–cold tiered storage、MinHash重複排除といった機能に加え、開発者向けの改善を数多く提供してきました。
私たちの考え方はシンプルです。ビジネスユースケースへの深い理解と最新テクノロジーを組み合わせることで、まったく新しいインフラの可能性が開かれるというものです。これこそが、Milvus 3.0を形作るマインドセットであり、現実世界のアプリケーションに直接対応するよう設計された、AIネイティブな新機能の波をもたらします。その一部を紹介します。
検索におけるキーワード重み付け – “red phone” のようなクエリで、red を適切に優先できるようにします。
ジオロケーション対応 – 位置情報を考慮したベクトルを保存・クエリし、“find nearby coffee shops.” のようなプロンプトに対応します。
RAG向けマルチベクトル対応 – 各テキストに複数の埋め込みを付与し、複雑な検索タスクにおける再現率と精度を向上させます。
柔軟なUDF処理 – よりリッチでカスタマイズ可能なデータ処理のためのユーザー定義関数。
ビジュアル分析ツール – 大規模な、より深いオフラインマイニングとデータ探索。
そして、これは始まりにすぎません。より重要なのは、Milvusが効率的でスケーラブルなだけでなく、中核からAIネイティブなシステムへと進化していることです。つまり、現代のアプリケーションが実際にどのように動くかに合わせて専用設計されているのです。
3. コストを抑えながらスケールするためのエンジニアリング
Zillizでは、10倍のコスト削減が、100倍のアプリケーションユースケースへの扉を開くと信じています。この原則は、Milvusにおけるすべての大きなマイルストーンを導いてきました。2022年以降、私たちはディスクベースのインデックス、GPUアクセラレーション、RabitQ quantizationを導入してきました。これらはいずれも、クエリ性能を桁違いに引き上げる一方で、コストを引き下げてきました。
今後、私たちの焦点は、スタックからさらに多くの効率を絞り出すことにあります。
より深いハードウェア最適化 – 生の計算能力とIOPS性能に合わせたチューニング。
よりスマートな圧縮と量子化 – 精度を犠牲にせず、ベクトルをより軽量にします。
インデックスクエリの早期終了 – 確信度の高い結果が得られた時点で、無駄な計算を打ち切ります。
洗練された階層型インデックス – コールドデータへのより高速なアクセスのために、キャッシュ利用を改善します。
最終目標は変わっていません。すぐに使えて、必要に応じてスケールし、高速かつ手頃な価格を維持するインフラを構築することです。
S3 Vectorsの登場がすべての人にとって朗報である理由
多くの人は、S3 Vectorsによって従来のベクトルデータベースが時代遅れになるのではないかと懸念しています。私の見方はその逆です。そのリリースは業界全体にとって朗報です。実際、私は3つの大きなメリットがあると考えています。
需要を証明しています。 ベクトルがもはや単なる流行だと主張できる人はいません。AWS がそれを中心にプロダクトを構築しているなら、それはベクトルストレージが「データベースに包まれたインデックス」にすぎないのではなく、現実の必需品であることの確かな証拠です。
市場を教育しています。 AWS のリーチにより、より多くの企業がベクトルデータベースを認識するようになり、構築できるアプリケーションの可能性が広がっています。
イノベーションを促進しています。 競争は、Milvus を含む私たち全員に、さらなる最適化、さらなるコスト削減、そして差別化された強みの発見を促します。
ポジショニングの観点から見ると、S3 Vectors は完全なベクトルデータベースというよりも、ベクトルストレージのコールドティアに近いものに見えます。その低コストは、これまでコスト面で手が届かなかったシナリオにおいて特に魅力的です。RAG アプリを構築する小規模チーム、実験を行う個人開発者、あるいは基本的な検索ニーズだけで大規模データセットをインデックス化する組織などです。これはエコシステムにとって本当に大きな解放です。
個人的には、AWS のエンジニアリングチームにも敬意を表したいと思います。彼らは Lambda のデバッグからコールドスタート性能に至るまで、プラットフォームを着実に改善してきました。そして S3 Vectors もまた、思慮深いプロダクトイノベーションの一例です。経済性がここまで有利になった今、開発者たちが何を作るのか、心から楽しみにしています。
つまり、ベクトルデータベース市場は破壊されているのではなく、さまざまなソリューションが異なる性能とコストのニーズに応える階層型エコシステムへと成熟しているのです。 それは企業にとっても、開発者にとっても、そして AI インフラスタック全体にとっても良いことです。
ベクトルデータベースの黄金時代は終わっていません。まさに始まったばかりです。

読み続けて

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.