




ベクターデータベースを使ったホワイトハウス演説の検索
米大統領選の選挙戦シーズンが近づいてきた。バイデン政権が就任してからの2年間に行った演説を振り返る良い機会だ。演説原稿を検索して、これまでの特定のトピックに関するホワイトハウスのメッセージングについてもっと知ることができたら素晴らしいと思いませんか?
スピーチの内容を検索したいとしよう。どうすればいいだろうか?セマンティック検索](https://zilliz.com/glossary/semantic-search)を使えばいい。セマンティック検索は今、人工知能(AI)で最もホットなトピックの一つだ。ChatGPTのような自然言語処理(NLP)アプリケーションの人気が高まるにつれ、その重要性は増している。経済的にも環境的にも高価なGPTに何度もpingを打つ代わりに、ベクトル・データベースを使って結果をキャッシュすることができます(GPTCacheなど)。
このチュートリアルでは、2021年から2022年までのBidenのスピーチを内容別に検索できるように、ローカルでベクトル・データベースをスピンアップする。使用するデータセットは "The White House (Speeches and Remarks) 12/10/2022 "データセットで、Kaggleで見つけ、この例ではGoogle Drive経由でダウンロードできるようにしました。このチュートリアルのウォークスルー・ノートブックはGitHubにあります。
コードに入る前に、必要なものをダウンロードしておいてください。4つのライブラリが必要です:PyMilvus, Milvus, Sentence-Transformers, gdownです。pip3 install pymilvus==2.2.5 sentence-transformers gdown milvus`を実行することでPyPiから必要なライブラリを入手できます。
ホワイトハウススピーチデータセットの準備
実世界のデータセットに基づくAI/MLプロジェクトと同様に、まずデータを準備する必要がある。gdownでデータセットをダウンロードし、zipfile`でローカルフォルダに展開する。以下のコードを実行すると、"white_house_2021_2022 "というタイトルのフォルダに "The white house speeches.csv "というタイトルのファイルができる。
インポート gdown
url = 'https://drive.google.com/uc?id=10_sVL0UmEog7mczLedK5s1pnlDOz3Ukf'
出力 = './white_house_2021_2022.zip'
gdown.download(url, output)
インポート zipfile
with zipfile.ZipFile("./white_house_2021_2022.zip", "r") as zip_ref:
zip_ref.extractall("./white_house_2021_2022")
pandas`を使用してCSVデータをロードし、検査する。
pandas を pd としてインポートする。
df = pd.read_csv("./white_house_2021_2022/The white house speeches.csv")
df.head()
データの head を見てみると、何に気づくだろうか?まず、このデータにはタイトル、日付、時間、場所、スピーチの4つのカラムがあることに気づく。次に、ヌル値があることです。ヌル値はいつも問題になるわけではありませんが、私たちのデータでは問題になります。

データセットのクリーニング
実体のないスピーチ("Speech "列のnull値)は、まったく役に立たない。ヌル値を削除してデータを再調査してみよう。
df = df.dropna()
df
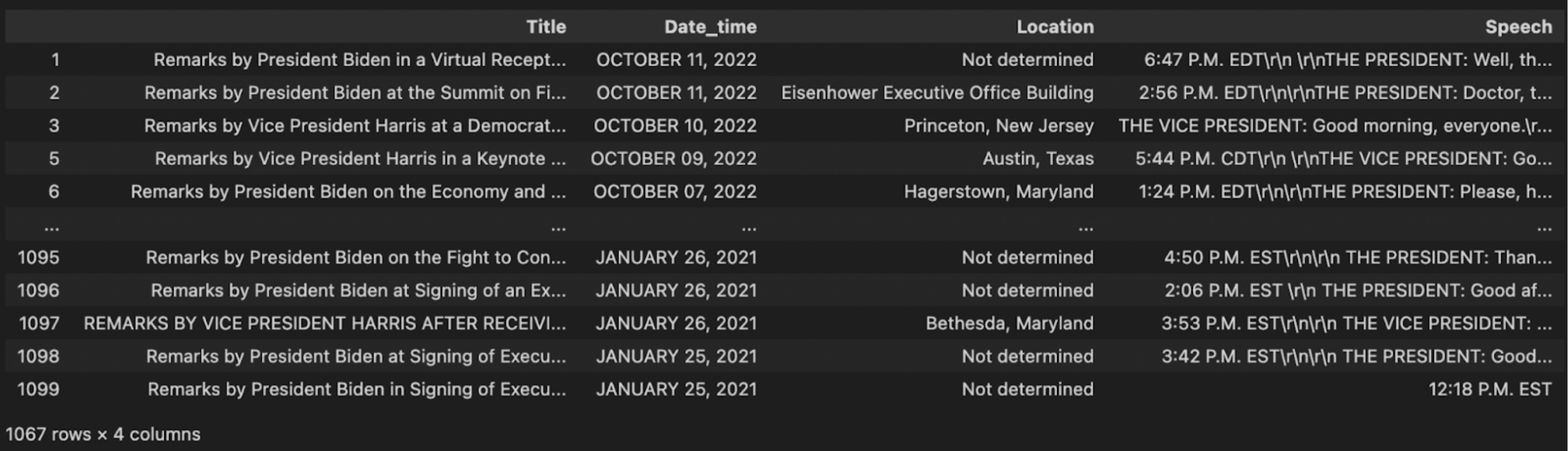
さて、データの先頭だけを見ただけではすぐにはわからなかった2つ目の問題があることがわかった。最後のエントリーを見ると、このエントリーは単なる時間であることがわかる。「12:18 P.M. EST」はスピーチとは言い難い。このエントリーを保存しても意味がない。ベクトルの埋め込みを保存しても、何の価値も得られません。
ある長さ以下のスピーチはすべて削除しましょう。この例では、私は50を選んだ。私はいろいろな数字を調べて50を選びました。20文字から50文字の間のスピーチ原稿を探すと、その多くが場所や時間であり、そこにいくつかのランダムな文章が混じっていることがわかります。
cleaned_df = df.loc[(df["Speech"].str.len() > 50)]cleaned_df
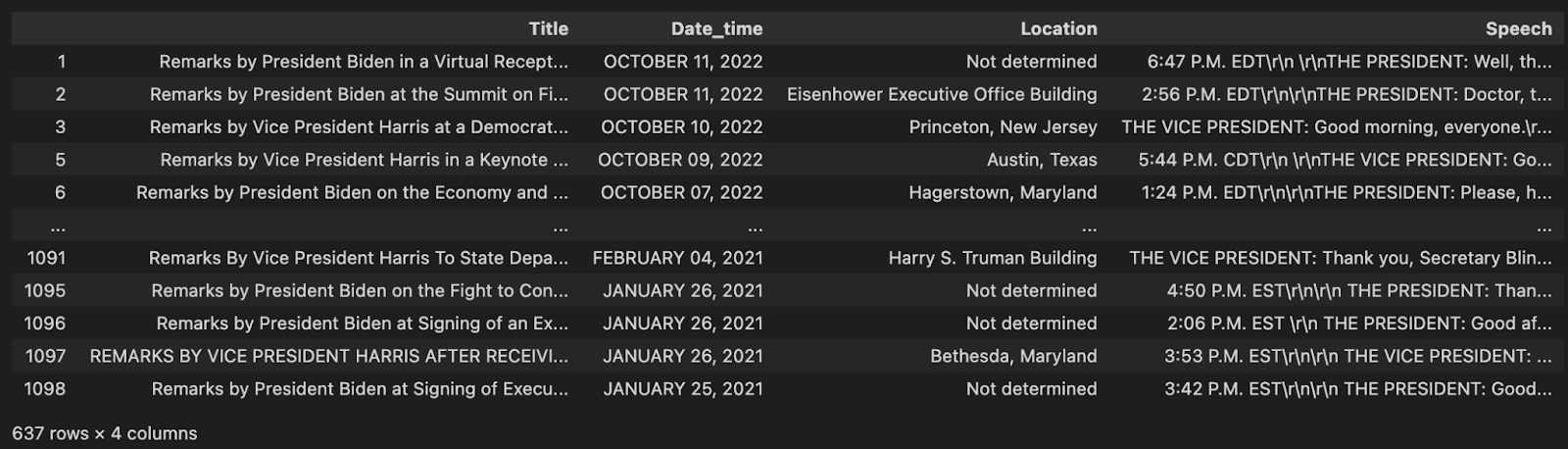
短い、実体のないスピーチは片付いたので、もう一度データを見てみると、もう一つ問題がある。スピーチの多くに改行とリターンの rrn 値が含まれている。これらの文字は書式設定に使われるが、意味的な価値はない。データクリーニングの次のステップは、これらを取り除くことである。
cleaned_df["Speech"] = cleaned_df["Speech"].str.replace("\rn", "")
cleaned_df

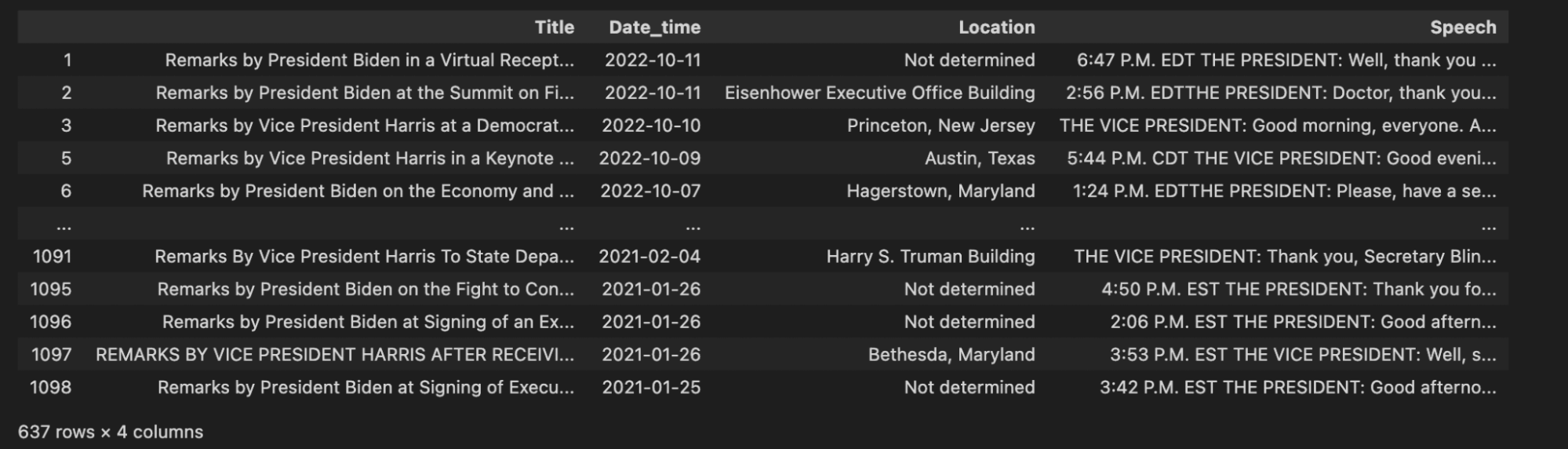
だいぶ良くなった。最後のステップは、"Date_time "カラムをベクターデータベースに格納し、他のdatetimeと比較できるように、より良いフォーマットに変換することです。ここでは、datetimeライブラリを使用して、単純にこの日時フォーマットを世界共通のYYYY-MM-DDフォーマットに変換する。
インポートdatetime
# 'date'カラムをdatetimeオブジェクトに変換する
cleaned_df["Date_time"] = pd.to_datetime(cleaned_df["Date_time"], format="%B %d, %Y")
cleaned_df
意味検索のためのベクターデータベースのセットアップ
これでデータはきれいになり、使えるようになった。次のステップは、実際にスピーチの内容から検索するためのベクターデータベースを立ち上げることです。この例では、Milvus Liteを使用します。これはDockerやKubernetes、YAMLファイルを扱うことなく実行できるMilvusのライトバージョンです。
最初にすることは、いくつかの定数を定義することだ。コレクション名(ベクトルデータベース用)、埋め込みベクトルの次元数、バッチサイズ、検索時に返したい結果の数を定義する数値が必要です。この例では、MiniLM L6 v2センテンス・トランスフォームを使用しています。
COLLECTION_NAME = "white_house_2021_2022"
次元 = 384
バッチサイズ = 128
TOPK = 3
Milvusの default_server を使用する。そして、PyMilvus SDKを使用してローカルのMilvusサーバに接続します。ベクターデータベースに先ほど定義したコレクション名と同じ名前のコレクションがある場合は、そのコレクションを削除して白紙の状態から始めます。
from milvus import default_server
from pymilvus import connections, utility
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
他の多くのデータベースと同様に、Milvusベクトルデータベースにデータをロードするにはスキーマが必要です。まず、各オブジェクトに持たせたいデータフィールドを定義します。先にデータを見ておいてよかった。ここでは5つのデータフィールドを使用する。ただし、今回は実際のテキストではなく、音声のベクトル埋め込みを使用する。
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
# オブジェクトは (タイトル, 日付, 場所, スピーチ埋め込み) のフォーマットで挿入される。
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True)、
FieldSchema(name="タイトル", dtype=DataType.VARCHAR, max_length=500)、
FieldSchema(name="日付", dtype=DataType.VARCHAR, max_length=100)、
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=200)、
FieldSchema(name="embedding",dtype=DataType.FLOAT_VECTOR,dim=DIMENSION)。
]
schema = CollectionSchema(fields=fields)
コレクション = コレクション(name=COLLECTION_NAME, schema=schema)
ベクトルデータベースにデータをロードする前に、最後に定義する必要があるのはインデックスです。多くのベクトルインデックスとパターン](https://zilliz.com/learn/index-overview-part-2)がありますが、この例では128クラスタのIVF_FLATインデックスを使用します。大きなアプリケーションでは通常128以上のクラスタを使いますが、この例では600エントリを少し超える程度です。距離の測定にはL2ノルムを使用する。インデックスのパラメータを定義したら、コレクションにインデックスを作成し、使用するためにロードします。
index_params = {
"index_type":"IVF_FLAT"、
"metric_type":"L2",
「params":params": {"nlist":128},
}
collection.create_index(field_name="embedding", index_params=index_params)
コレクション.load()
スピーチからベクトル埋め込みを取得する
これまで説明してきたことの多くは、ほとんどすべてのデータベースを扱うときに適用されます。いくつかのデータをクリーンアップし、データベースインスタンスを立ち上げ、データベースのスキーマを定義しました。インデックスを定義する以外に、特にベクトル・データベースで必要なことは、埋め込みデータを取得することです。
まず、前述のように文型変換モデルMiniLM L6 v2を取得します。そして、データに対して変換を行い、コレクションに挿入する関数を作成します。この関数は、データのバッチを受け取り、音声トランスクリプトの埋め込みを取得し、挿入するオブジェクトを作成し、コレクションに挿入します。
コンテキストのために、この関数はバッチ更新を実行します。この例では、一度に128エントリをバッチ挿入しています。挿入で行うデータ変換は、音声テキストを埋め込みに変換することだけです。
from sentence_transformers import SentenceTransformer
transformer = SentenceTransformer('all-MiniLM-L6-v2')
# (タイトル, 日付, 場所, 発言) のリストを期待する
def embed_insert(data: list):
embeddings = transformer.encode(data[3])
ins = [
data[0]、
data[1]、
data[2]、
[x for x in embeddings]
]
コレクション.insert(ins)
ベクターデータベースの投入
埋め込みと挿入のバッチを作成する関数が完成したので、データベースにデータを入れる準備ができました。この例では、データフレームの各行をループして、データのバッチ処理に使用するリストのリストに追加します。バッチサイズに達したら、 embed_insert 関数を呼び出してバッチをリセットします。
ループが終わった後、バッチ内にデータが残っていれば、残りのデータを埋め込んで挿入する。最後に、ベクターデータベースの入力を終了するために、flushを呼び出してデータベースの更新とインデックス付けを確実に行う。
data_batch = [[], [], [], []] とする。
for index, row in cleaned_df.iterrows():
data_batch[0].append(row["Title"])
data_batch[1].append(str(row["Date_time"]))
data_batch[2].append(row["Location"])
data_batch[3].append(row["Speech"])
if len(data_batch[0]) % BATCH_SIZE == 0:
embed_insert(data_batch)
data_batch = [[], [], [], []].
# 残りを埋め込んで挿入する
if len(data_batch[0]) != 0:
embed_insert(data_batch)
# フラッシュを呼び出して、未封入のセグメントをインデックス化する。
collection.flush()
ホワイトハウスのスピーチを説明文に基づいて意味検索する
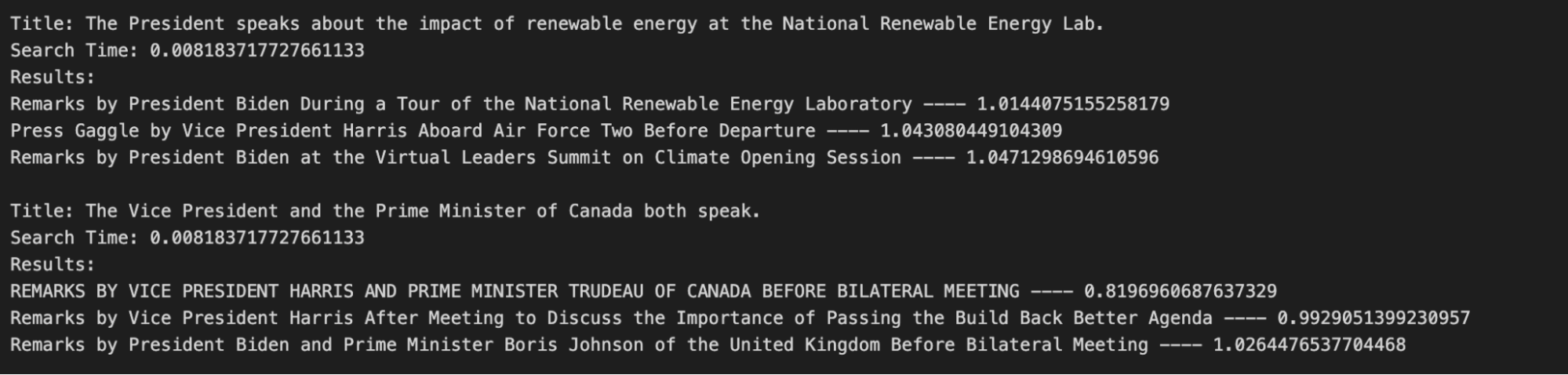
例えば、大統領が国立再生可能エネルギー研究所(NREL)で再生可能エネルギーの影響について演説したスピーチと、副大統領とカナダの首相が演説したスピーチを探したいとしよう。先ほど作成したベクトルデータベースを使えば、2021-2022年にホワイトハウスのメンバーが行った最も類似したスピーチのタイトルを見つけることができる。
ベクターデータベースを検索して、私たちの説明と最も類似したスピーチを探すことができる。あとは、スピーチの埋め込みを得るために使ったのと同じモデルを使って、説明をベクトルの埋め込みに変換し、ベクトルデータベースを検索すればよい。
説明をベクトル埋め込みに変換したら、コレクションに対して search 関数を使います。エンベッディングを検索データとして渡し、検索したいフィールドを渡し、検索方法のパラメータを追加し、検索結果の件数の制限と返したいフィールドを追加します。この例では、検索パラメータとして、メトリックの型(インデックスを作成するときに使用したものと同じ型(L2ノルム))と、検索するクラスタの数(nprobeを10に設定)を渡す必要があります。
import time
search_terms = ["The President speaks about the impact of renewable energy at the National Renewable Energy Lab.", "The Vice President and the Prime Minister of Canada both speak."] 検索したいクラスタを指定する。
# 入力テキストに基づいてデータベースを検索
def embed_search(data):
embeds = transformer.encode(data)
戻り値 [x for x in embeds]
search_data = embed_search(search_terms)
start = time.time()
res = collection.search(
data=search_data, # 埋め込み検索の値
anns_field="embedding", # エンベッディングを横断して検索する
param={"metric_type":"L2",
「params":{"nprobe":10}},
limit = TOPK, # 1回の検索結果をTOP_k件に制限する。
output_fields=["title"] # 結果にタイトルフィールドを含める
)
end = time.time()
for hits_i, hits in enumerate(res):
print("Title:", search_terms[hits_i])
print("検索時間:", end-start)
print("結果:")
for hit in hits:
print( hit.entity.get("title"), "----", hit.distance)
print()
この例で文章を検索すると、下の画像のような出力が期待される。タイトルが期待通りのものなので、これは検索に成功している。最初の説明文はバイデン大統領がNRELで行ったスピーチのタイトルを返し、2番目の説明文はハリス副大統領とトルドー首相のスピーチを反映したタイトルを返している。
要約
このチュートリアルでは、ベクトルデータベースを使って、2022年の中間選挙前にバイデン政権が行った演説を意味的に検索する方法を学んだ。セマンティック検索では、構文的に類似したテキストだけでなく、意味的に類似したテキストを探すことができます。これにより、特定の文章や引用に基づいてスピーチを検索する代わりに、スピーチの一般的な説明を検索することができる。ほとんどの人にとって、興味のあるスピーチを見つけるのが簡単になる。
 Yujian Tang
Yujian TangYujian Tang is a Developer Advocate at Zilliz. He has a background as a software engineer working on AutoML at Amazon. Yujian studied Computer Science, Statistics, and Neuroscience with research papers published to conferences including IEEE Big Data. He enjoys drinking bubble tea, spending time with family, and being near water.
読み続けて

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.