




Milvusのメタデータフィルタリング:MilvusにおけるJSONとメタデータのフィルタリング
JSON(JavaScript Object Notation)は、保存と転送のための柔軟なデータフォーマットである。キーと値のペアを適応的に使用するため、NoSQLデータベースやAPIの結果に最適です。その柔軟性から、一般的なデータ形式となっている。検索パラメータは、使用されるベクトルフィールド、クエリベクトル、返される結果の数の制限など、各検索リクエストの仕様を定義するために重要である。
Milvusのデモの多くは、.txt、.pdf、.csvなどの生のテキストデータから始まります。しかし、Milvusで生のJSONをアップロードして扱うことができることをご存知でしょうか?詳しくはJSON ドキュメント ページをご覧ください。
Milvus ClientはMilvusコレクションオブジェクトのラッパーであり、柔軟なJSON "key":valueフォーマットを使用し、スキーマレスなデータ定義を可能にします。詳細はMilvus Client documentationを参照してください。
スキーマレスのMilvusクライアントとZillizのfree tier cloudはMilvusを素早く利用するための素晴らしい方法です!Milvusクライアントは、フルスキーマを前もって定義するのとほぼ同等のスピードで、よりエラーの少ないコーディングが可能です。enable_dynamic_field](https://milvus.io/docs/v2.2.x/dynamic_schema.md)」と比較すると、Milvusクライアントははるかに高速で、スキーマの定義が少なくて済むため、よりスムーズなアプローチを提供します。スキーマレスのスキーマは以下の通りです:
- id** (str):主キーフィールドの名前。
- vector**(str):ベクトル・フィールドの名前。
以上である! 残りのフィールドはデータをMilvusに挿入する際に柔軟に決定することができる。
具体的にMilvusクライアントの使い方を説明します。 全コードは私のBootcamp github repoにあります。
コード例 - 生のJSONデータをMilvusに直接アップロードする
生データはJSON形式である。 例えば、MongoDBのようなNoSQLデータベースからデータを取得する場合に便利です。 以下のJSONデータはKaggleのIMDB映画ジャンル分類です。
# !pip install numpy pandas json pprint pymilvus torch sentence-transformers
# 一般的なライブラリをインポートする。
import pandas as pd
json をインポート
# JSON データを読み込む。
df = pd.read_json('data/tiny_parsed_data.json')
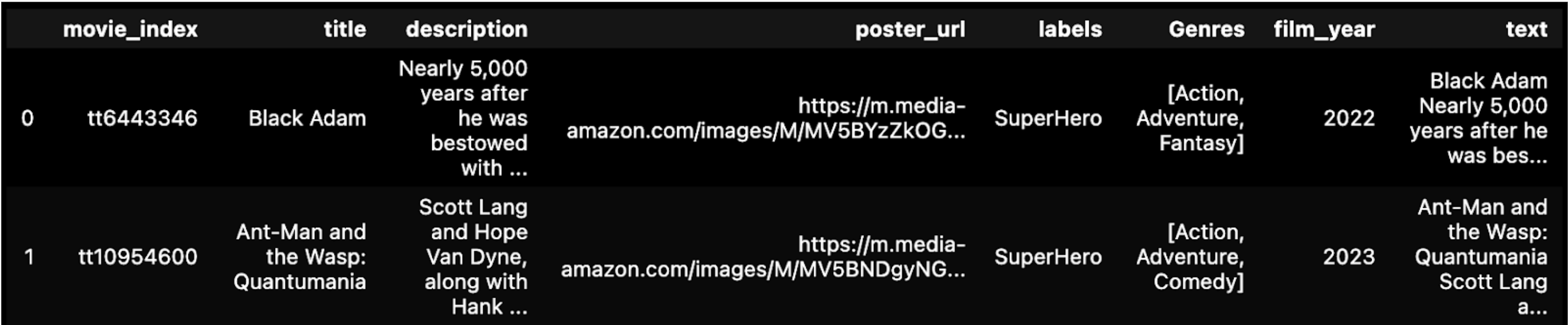
# タイトルと説明を'text'カラムに連結する。
df['text'] = df['title'] + ' + df['description'] # タイトルと説明を'text'カラムに連結する。
display(df.head(2))
Zillizクラウド無料トライアルサーバーを立ち上げる](https://cloud.zilliz.com/login) 一度に100万ベクトルまでのコレクションを2つまで無料トライアルできます。このノートブックのコードはfully-manを使用しています。
- プロビジョニング時にデフォルトの "Starter "オプションを選択 > コレクションを作成 > 名前を付ける > クラスタとコレクションを作成。
- クラスタのメインページで、
API Keyをコピーし、.env変数'ZILLIZ_API_KEY'にローカルに保存します。 - 同じくクラスタのメインページで
Public Endpoint URIをコピーします。
import os
from pymilvus import connections, utility
TOKEN = os.getenv("ZILLIZ_API_KEY")
# エンドポイント URI と API キー TOKEN を使って Zilliz クラウドに接続する。
cluster_endpoint="https://in03-xxxx.api.gcp-us-west1.zillizcloud.com:443"
connections.connect(
alias='default'、
token=TOKEN、
uri=CLUSTER_ENDPOINT,)
# サーバーが準備できているかチェックし、コレクション名を取得する。
print(f "Type of server:{utility.get_server_version()}")

埋め込みモデルを選びます。 以下、HuggingFaceのものを選んでみた。 ラップトップで動かしているので、DEVICE=cpuにしている。
インポートトーチ
from sentence_transformers import SentenceTransformer
# トーチの設定を初期化する
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# huggingface model hubからモデルをロードする。
モデル名 = "WhereIsAI/UAE-Large-V1"
エンコーダ = SentenceTransformer(model_name, device=DEVICE)
# モデルパラメータを取得し、後のために保存する。
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# モデルのパラメータを見る
print(f "model_name: {model_name}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH}")

MilvusClientをインポートし、コレクションを作成します。 スキーマを指定する必要がないことに注意してください! また、AUTOINDEXと呼ばれるデフォルトのインデックスを使用することもできます。 オープンソースと無料版のデフォルトはHNSWです。 有料のZillizクラウドでは、AUTOINDEXは独自のインデックスを使用してさらに最適化されます。
from pymilvus import MilvusClient
インポート pprint
# Milvusコレクション名を設定する。
COLLECTION_NAME = "imdb_metadata"
# スキーマなしのMilvusクライアントを使用する。
mc = MilvusClient(
uri=CLUSTER_ENDPOINT、
token=TOKEN)
# コレクションが既に存在するかどうかをチェックします。
has = utility.has_collection(COLLECTION_NAME)
if has:
drop_result = utility.drop_collection(COLLECTION_NAME)
print(f "Successfully dropped collection: `{COLLECTION_NAME}`")
# コレクションを作成します。
mc.create_collection(COLLECTION_NAME、
EMBEDDING_DIM、
consistency_level="Eventually"、
auto_id=True、
overwrite=True、
# AUTOINDEXを使用する場合は、パラメータの設定をスキップする。
)
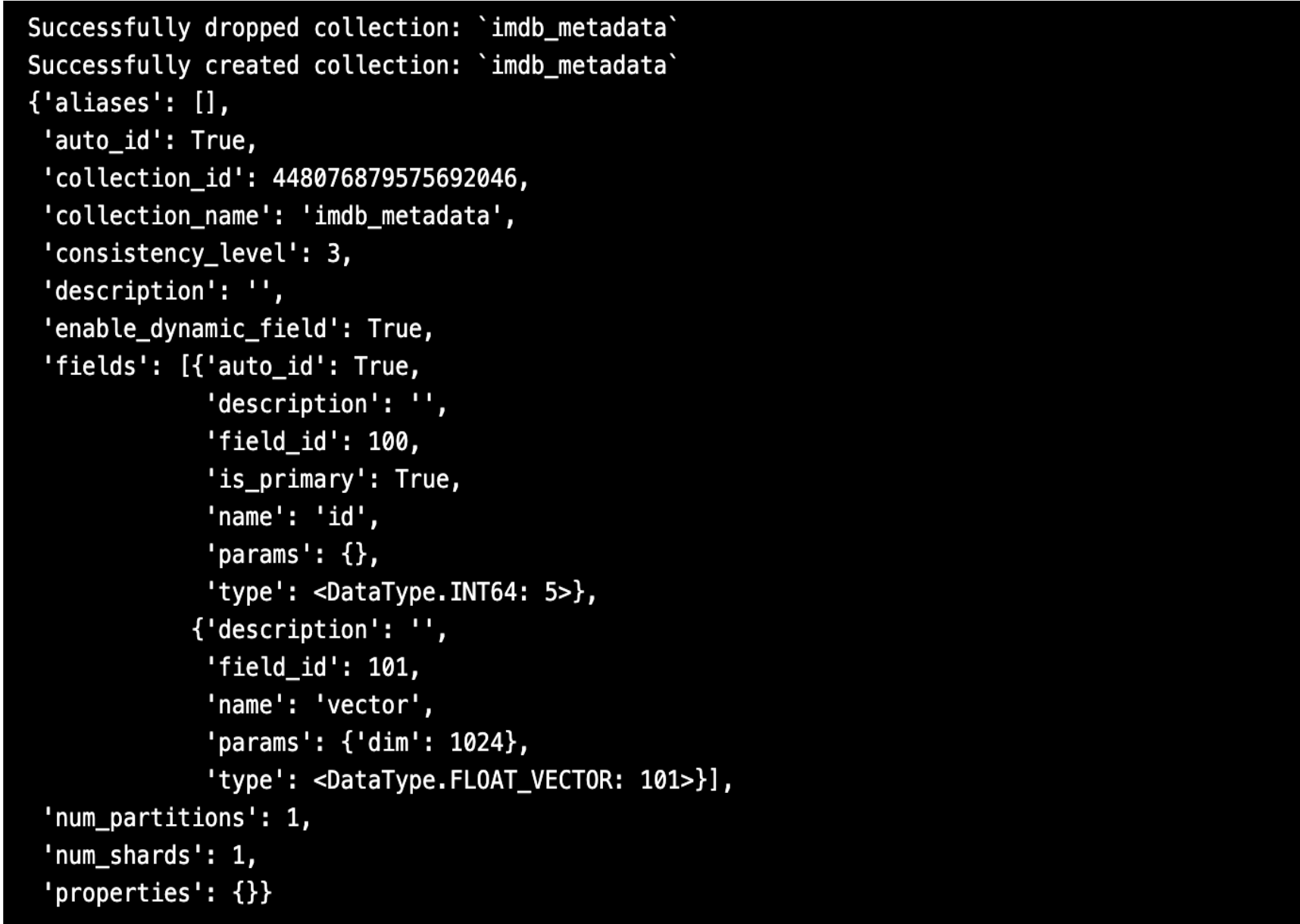
print(f "Successfully created collection: `{COLLECTION_NAME}`")
pprint.pprint(mc.describe_collection(COLLECTION_NAME))
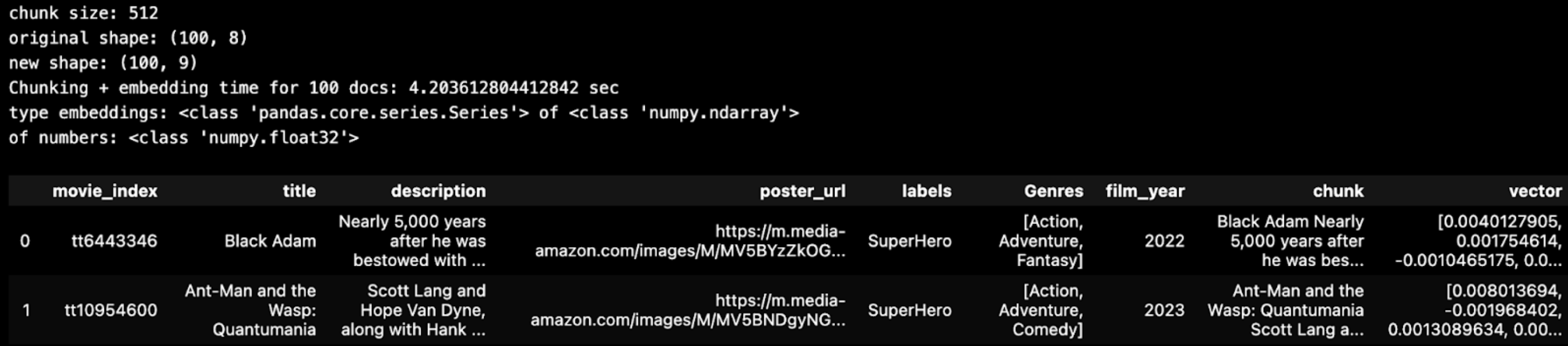
単純なチャンキング戦略は、'text'フィールドの長さが512文字を超えない限り、単一のチャンクとして保持することである。以下では、JSONデータのテキストフィールドがかなり短いことがわかる。 行を小さなチャンクに分割する必要はありませんでした。
# 埋め込みモデルのパラメータを使う。
チャンクサイズ = 512
chunk_overlap = np.round(chunk_size * 0.10, 0)
# pandas DataFrame からバッチデータをチャンクして検査する。
バッチサイズ = 100
バッチ = imdb_chunk_text(BATCH_SIZE, df, chunk_size)
表示(batch.head(2))
これで、テキストのチャンク、各チャンクのベクトル埋め込み、そしてオリジナルのメタデータが揃ったので、そのデータをMilvusのベクトルデータベースに挿入してみよう。
# DataFrameを辞書のリストに変換する。
chunk_list = batch.to_dict(orient='records')
# データをMilvusコレクションに挿入する。
start_time = time.time()
insert_result = mc.insert( COLLECTION_NAME, data=chunk_list, progress_bar=True )
end_time = time.time()
print(f "Milvus Client insert time for {batch.shape[0]} vector:{end_time - start_time} 秒")

質問をして、ムービーデータから答えを取得してみよう。
SAMPLE_QUESTION = "ロボットが出てくるディストピアSF"
# 同じエンコーダーを使って質問を埋め込みます。
query_embeddings = _utils.embed_query(encoder, [SAMPLE_QUESTION])
TOP_K = 2
# クエリとベクトルデータベースを使用して、セマンティックベクトル検索を実行します。
start_time = time.time()
results = mc.search(
コレクション名、
data=query_embeddings、
output_fields=OUTPUT_FIELDS、
limit=TOP_K、
consistency_level="Eventually"、
filter='film_year >= 2019', )
elapsed_time = time.time() - start_time
print(f"{len(chunk_list)}ベクトルに対するMilvusクライアントの検索時間:{elapsed_time} 秒")
検索時間](https://assets.zilliz.com/search_time_2d507dec63.png)
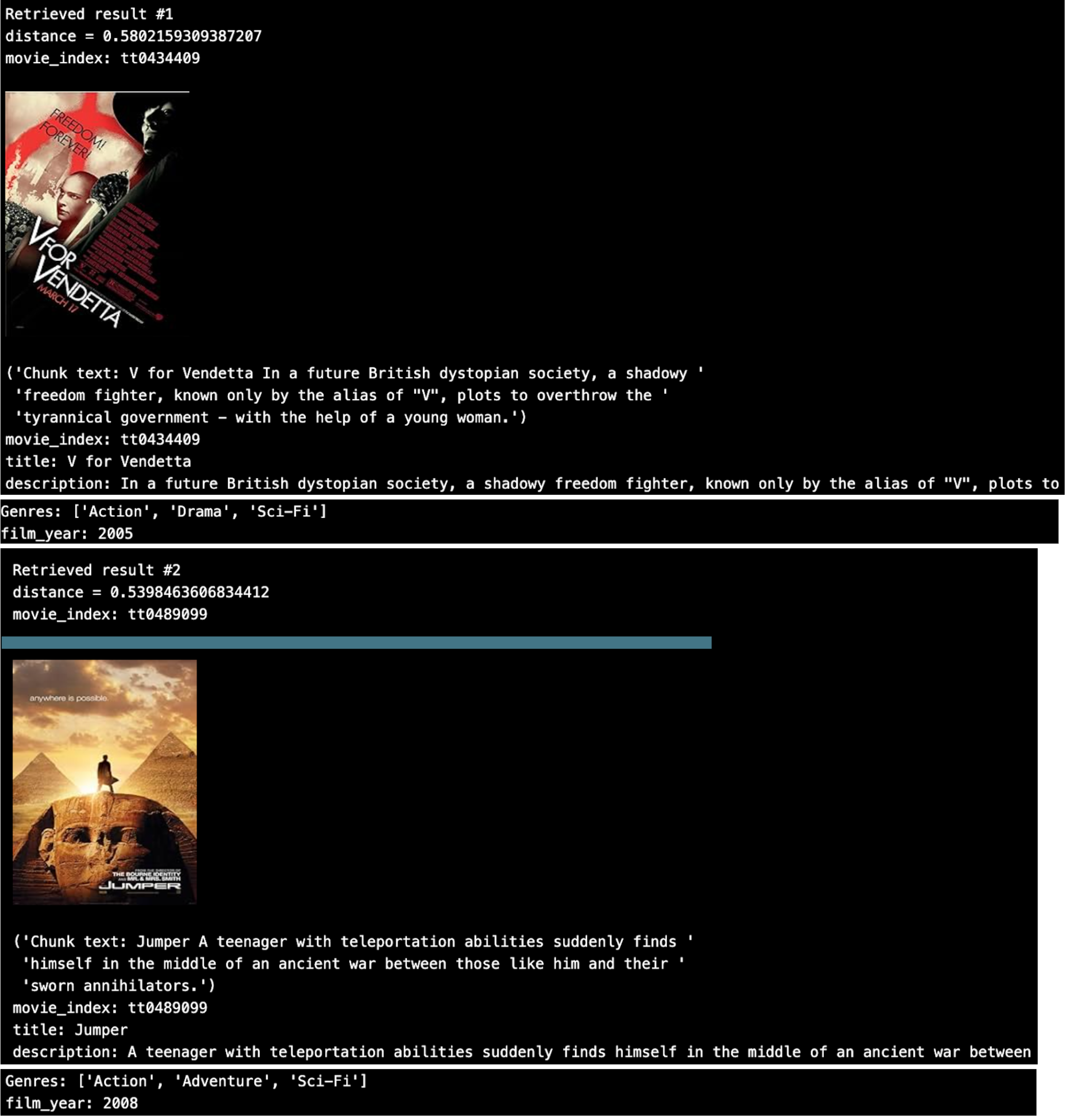
上位2つの結果をループすると、こうなる。
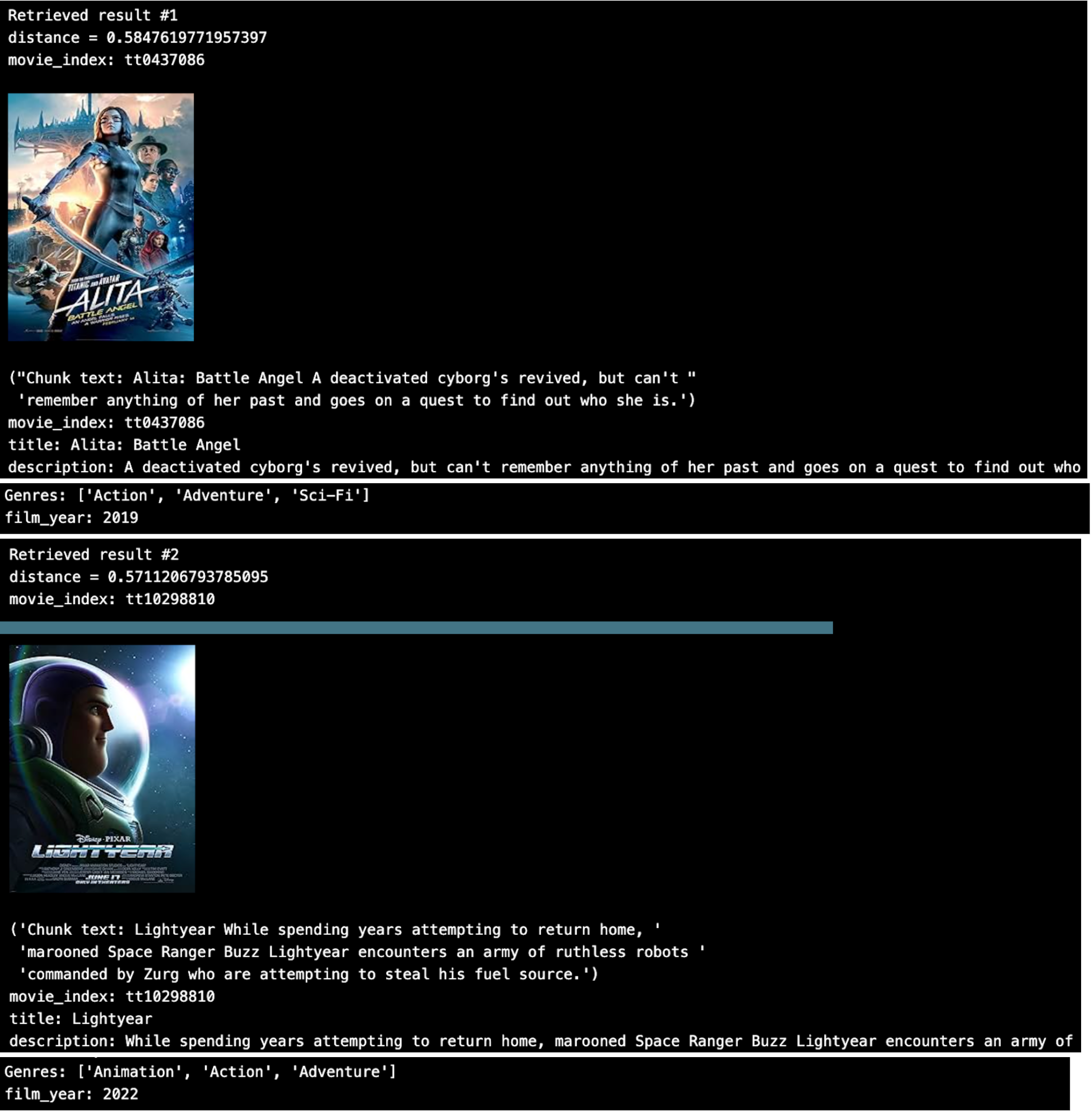
これはなかなか良さそうだ。 しかし、JSON配列の'Genres'に対してメタデータのフィルタリングを行いたい場合はどうすればいいでしょうか?
JSON フィールドと JSON 配列にまたがるメタデータのフィルタリング
Milvus 2.3の新機能は、生のJSONメタデータをフィルタリングする機能です。 以下に、フィールドと配列を使ってメタデータフィルタリングを行う例を示します。
例えば、古いレトロな映画やSFジャンルの映画を見たいとします。
SAMPLE_QUESTION = "ロボットが出てくるディストピアSF"
# 同じエンコーダーを使って質問を埋め込みます。
query_embeddings = _utils.embed_query(encoder, [SAMPLE_QUESTION])
TOP_K = 2
# クエリとベクトルデータベースを使用して、セマンティックベクトル検索を実行します。
start_time = time.time()
results = mc.search(
コレクション名、
data=query_embeddings、
output_fields=OUTPUT_FIELDS、
limit=TOP_K、
consistency_level="Eventually"、
filter='json_contains(Genres, "Sci-Fi") and film_year < 2019'、
)
elapsed_time = time.time() - start_time
print(f"{len(chunk_list)}ベクトルのMilvusクライアント検索時間:{elapsed_time} 秒")
上位2つの検索結果をループすると、おすすめ映画がフィルターにマッチするように変わっている。
Milvusのデモの多くは、.txt、.pdf、.csvのような生のテキストデータから始まります。 今回はJSONデータをMilvusベクトルデータベースコレクションに直接ロードする方法を見ました。 また、JSONフィールドに対する便利なメタデータフィルタリングとJSON配列データ型に対するjson_contains()フィルタリングの使い方も紹介します。 このブログ記事の全コードは私のBootcamp GitHub repoにあります。
ハイブリッド検索入門
ハイブリッド検索はMilvusの強力な機能であり、複数のベクトルフィールドを1つの検索にまとめることができます。この機能は、実体が複数の多様なベクトルで表現されるような複雑な検索シナリオにおいて特に有用です。リランキング戦略を使って複数のベクトル検索結果を統合することにより、ハイブリッド検索はより高い精度と関連性の高い検索結果を実現します。
Milvusでは、ハイブリッド検索を使用して、テキスト、画像、音声などの異なるタイプのデータを単一の検索クエリに組み合わせることができる。これにより、ユーザーはより包括的な検索を行い、より関連性の高い結果を得ることができる。例えば、ハイブリッド検索では、テキスト埋め込みと画像埋め込みを組み合わせることで、テキストの説明と視覚的な例の両方に一致する商品を見つけることができます。
Milvusでハイブリッド検索を効果的に使うには、様々なベクトルフィールドとその組み合わせ方を理解することが重要です。ベクトルフィールドを注意深く選択し組み合わせることで、ユーザーは検索結果の精度と関連性を向上させることができる。さらに、リランキング戦略を使用することで、検索結果をさらに絞り込み、最も関連性の高い結果を確実に返すことができます。
メタデータによるデータ管理
メタデータはMilvusにおけるデータ管理において重要な役割を果たします。メタデータはデータの構造と構成を記述するために使用され、検索、フィルタリング、分析を容易にします。Milvusでは、コレクション名、ベクトルフィールド、インデックスタイプなどのデータに関する情報を含むデータファイルを管理するためにメタデータが使用されます。
メタデータを効果的に使用することで、ユーザーは検索のパフォーマンスと精度を向上させることができます。メタデータを使用することで、ユーザーは検索や分析が容易になるようにデータを整理することができます。例えば、メタデータを使用して関連キーワードでデータにタグ付けすることで、ユーザーは特定のデータポイントを素早くフィルタリングして検索することができます。
検索パフォーマンスを向上させるだけでなく、メタデータはデータの整合性と一貫性を確保するのにも役立ちます。メタデータを使用してデータの変更と更新を追跡することで、ユーザーはデータの正確性と最新性を確保できます。これは、データが常に更新・修正される大規模データ環境では特に重要です。
JSONとメタデータのフィルタリング
JSON(JavaScript Object Notation)は、NoSQLデータベースやAPI結果で広く使用されている柔軟なデータフォーマットです。Milvusは生のJSONデータのアップロードと作業をサポートし、他のシステムとの統合を容易にします。メタデータフィルタリングはMilvusの強力な機能で、特定の条件に基づいて生のJSONメタデータをフィルタリングすることができます。
メタデータフィルタリングを使用することで、ユーザーは検索の精度を向上させ、無関係なデータの量を減らすことができます。例えば、映画のジャンルや公開年によるフィルタリングなど、特定のフィールドや値に基づいてJSONデータをフィルタリングすることができます。これにより、ユーザーはより的を絞った検索を実行し、より関連性の高い結果を取得することができます。
Milvusでは、メタデータフィルタリングをベクトル検索と組み合わせて使用することで、検索結果をさらに絞り込むことができます。ベクトル検索クエリにメタデータフィルターを適用することで、ユーザーは最も関連性の高いデータのみを確実に返すことができる。これにより、検索精度を向上させ、処理する必要のある無関係なデータの量を減らすことができます。
ベクトル検索のためのインデックスの構築と管理
インデックス構築は、Milvusにおけるベクトル検索のパフォーマンスを最適化する上で非常に重要なステップです。インデックスとは、データベースが特定のデータを素早く検索できるようにすることで、データ検索の速度を向上させるデータ構造です。Milvusでは、ベクトル検索のパフォーマンスを向上させるために、ベクトルフィールド上にインデックスを構築することができます。
Milvusで使用可能なインデックスには様々な種類があり、それぞれに利点と使用例があります。例えば、HNSW(Hierarchical Navigable Small World)インデックスは、その効率性と正確性から高次元ベクトル検索によく使用されます。IVF(Inverted File)やPQ(Product Quantization)などの他のインデックス・タイプは、検索速度と精度のトレードオフが異なります。
インデックスを効果的に構築し管理するためには、データの特性と特定の検索要件を理解することが重要である。適切なインデックスタイプを選択し、インデックスパラメータをチューニングすることで、ユーザーは検索のパフォーマンスを大幅に向上させることができる。さらに、インデックスを定期的に更新・保守することで、データが進化しても最適な検索パフォーマンスを維持することができます。
ハイブリッド検索パフォーマンスの最適化
ハイブリッド検索のパフォーマンスは、インデックスの構築、メタデータのフィルタリング、クエリの最適化など、様々なテクニックを使うことで最適化することができる。ベクトル](https://zilliz.com/learn/vector-index)フィールドにインデックスを作成することで、ベクトル検索のパフォーマンスを向上させることができます。インデックスにより、データベースは関連するデータを素早く見つけることができ、検索に必要な時間を短縮することができる。
メタデータのフィルタリングもハイブリッド検索のパフォーマンスを最適化するための重要なテクニックである。メタデータ・フィルターを使用することで、ユーザーは処理する必要のある無関係なデータの量を減らし、検索の精度と速度を向上させることができる。例えば、特定のフィールドや値に基づいてデータをフィルタリングすることで、検索結果を絞り込み、最も関連性の高いデータのみが返されるようにすることができます。
クエリの最適化もまた、ハイブリッド検索のパフォーマンスを向上させる上で極めて重要です。検索クエリの構造とパラメータを最適化することで、ユーザーは検索に必要な計算リソースを削減し、パフォーマンスを向上させることができる。これには、クエリのバッチ処理、効率的なデータ構造の使用、クエリ・パラメータのチューニングなどのテクニックが含まれる。
このセクションでは、Milvusにおけるハイブリッド検索のパフォーマンスを最適化するためのベストプラクティスについて説明した。インデックスの構築、メタデータのフィルタリング、クエリの最適化などのテクニックを使用することで、ユーザは検索の精度と速度を向上させ、最も関連性の高い結果を確実に取得することができます。
 Christy Bergman
Christy BergmanChristy Bergman is a passionate Developer Advocate at Zilliz. She previously worked in distributed computing at Anyscale and as a Specialist AI/ML Solutions Architect at AWS. Christy studied applied math, is a self-taught coder, and has published papers, including one with ACM Recsys. She enjoys hiking and bird watching.
読み続けて

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.