




ミルヴァス・アーキテクチャーの紹介
1,200人以上のユーザーを対象としたアンケートで、私たちは1つの重要な繰り返し課題となる「スケーラビリティ」を発見しました。ベクトル演算をどのようにスケーリングできるのか?この疑問が、分散システムとしてのMilvusの開発につながる。ベクターデータベースは、従来のデータベースとは異なり、利用要件が異なります。3つの主な違いが、クラウドネイティブなベクトルデータベースをゼロから構築する動機となった。
第一に、ベクトルデータは複雑なトランザクションを必要としない。
第二に、ユースケースの多様性により、パフォーマンスと一貫性のトレードオフを調整する必要がある。
第三に、一部のベクトルデータ操作は計算コストが高く、弾力的なリソース割り当てが必要である。
Milvusは、意図的に分散システムとして設計することにより、水平スケーリングを実現している。シングルインスタンスデータベースは、ある時点まではスケールアップできるが、すぐにハードウェアの制約を受けるようになる。Milvusの水平スケーリング機能はこの問題を克服し、データベースを複数のインスタンスに拡張することを可能にします。データベースの水平スケーリングには、機能をデータベースに直接組み込む方法と、スケーリングプロセスを手動で実装する方法があります。
Milvusでは、スケーリング機能がシステムに組み込まれています。スケーリングを自分で処理することもできますが、ミッションクリティカルな業務でデータベースのスケーリングが必要な場合を除き、理想的なソリューションではありません。Milvusのスケーラビリティを実現する3つのアーキテクチャと2つの検索設計の選択について見ていきましょう。
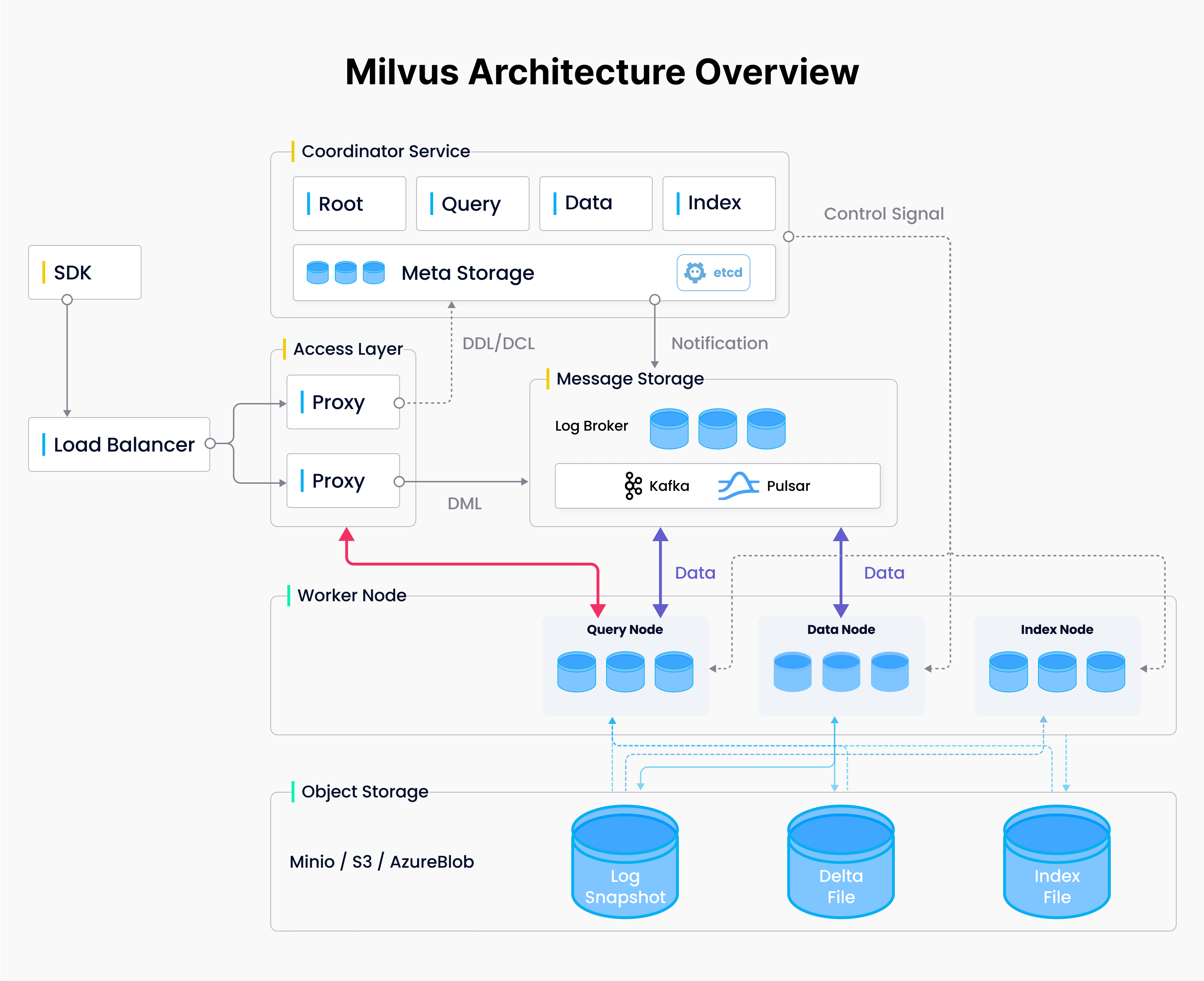
クラウドネイティブシステムアーキテクチャ
ほとんどのソフトウェア・チームは、もはやサーバールームのサーバーにデプロイしない。なぜか?利用可能なパブリッククラウド(AWS、Azure、GCPなど)により、ソフトウェアチームはより迅速に動けるようになりました。Milvusは、クラウド上での作業がもたらす柔軟性を活用するために構築されています。
Milvusには、アクセス、コーディネーション、ワーカー、ストレージの4つのレイヤーがあります。ステートレスアクセスノードはシステムへのアクセスを提供する。ワーカーとコーディネーターはサーバーレスパターンで設計されている。ステートフルなコーディネータは、必要に応じてステートレスワーカーをスピンアップ/ダウンさせる。ストレージレイヤーは、ベクトルデータとシステムが機能するために必要なすべての情報を格納する。
関心の分離
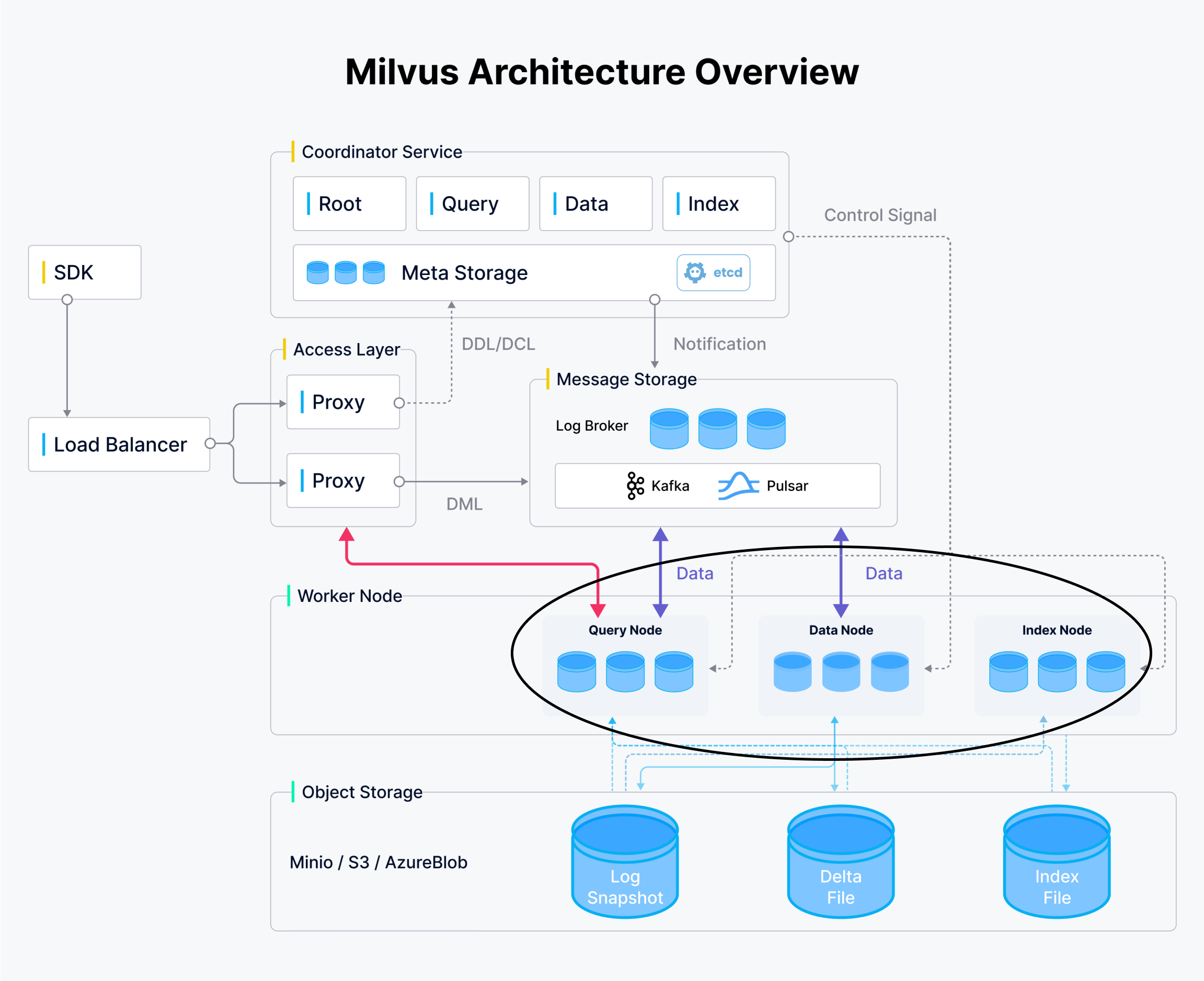
ベクターデータベースを扱う場合、3つの主要な関心事項がある。これら3つの機能は、常に異なるタイミングで異なる量だけスケールします。Milvusは3つの異なるタイプのノードを提供し、それぞれ独立してスケールさせることができます。
クエリノードはクエリ機能を扱うため、複数のセグメントのインメモリインデックスを保持するのに十分なメモリを持つ必要があります。セグメントとは、Milvusが効率性とスケーラビリティのために使用する、あらかじめ定義されたサイズのデータブロックである。クエリノードはまた、そのコンピューティングとメモリの一部を使用して、複数のセグメントからの検索結果を委任、集約、処理することで、検索の並列化を支援します。
データが入ってくると、クエリノードとデータノードの両方に入ります。これらのノードは、まだサイズの上限に達していない、成長するセグメントのデータを保持します。セグメントが容量に達すると、クエリノードはそのデータを解放し、生成されたインデックスに置き換えます。
データノードはデータの取り込みを処理する。データノードでセグメントがサイズ上限に達すると、そのセグメントは "封印 "される。封印されたセグメントは、データノードとクエリノードからパーマネントストレージにフラッシュされる。データがストレージレイヤーにフラッシュされると、コーディネータはインデックスノードに通知する。
インデックスノードはインデックスを構築する。インデックスノードは通知を受けると、ストレージレイヤーからデータセグメントを読み込む。このセットアップにより、インデックスを作成する際に、より少ないデータで作業できるようになります。インデックスノードはストレージからデータを読み込むので、インデックスを作成するのに必要な属性だけを読み込むことができます。
大規模書き込み一貫性
スケーリングを行う上で、一貫性の問題に遭遇することは当然のことです。Milvusや他のデータベースシステムの2つ目のレプリカやインスタンスをスピンアップすると、即座にデータの一貫性の問題に遭遇します。データの一貫性についてシステム全体で合意する必要があります。
Milvusにはデータの一貫性を調整するための多くのオプションがシステムに組み込まれています。Milvusはパブ/サブシステムです。メッセージ・ストレージ・ブロックはパブリッシング・システムとして機能し、送られてくるデータそれぞれにタイムスタンプを付与します。そして、クエリーノードとデータノードはサブスクライバーとしてこのパブリッシングログを読みます。
書き込みのスケーリングには、書き込み側として機能するシャードの数をスケーリングすることが含まれる。データが入力されると、そのIDがハッシュ化され、ハッシュによってどのシャードがそのデータを書き込むかが決定される。
並列検索のためのデータセグメント
前述したように、Milvusは "セグメント "と呼ばれるあらかじめ定義されたデータ量に対して個別のインデックスを作成する。デフォルトでは、Milvusは512MBのデータに対してセグメントを作成しますが、必要に応じて調整することができます。
なぜこのようにセグメントを作成し、インデックスを構築するのか?柔軟性、拡張性、変異を容易にするためです。インデックスはデータにアクセスするための手段です。ある初期データセットにインデックスを作成したとします。実際のシナリオでは、データは時間とともに変化するので、データを追加し続けなければなりません。最初のインデックスは最初のデータに対して構築されただけなので、新しいデータに対しては役に立たない。
このインデックス作成問題に対する合理的な解決策は、(新しいデータが追加される量のように)あらかじめ定義された間隔で継続的に新しいインデックスを作成することでしょう。Milvusはこの解決策を複数のインスタンスとレプリカに渡って実装しています。
このセグメントセットアップにより、非効率なインデックス作成に対する効率的なソリューションが提供され、クエリのスケーラビリティが向上します。別々のデータセグメントに構築されたインデックスは互いに依存しないので、ハードウェアの制限のみで並列検索が可能です。
セグメントサイズを大きくすることで、各検索処理の効率が向上します。しかし、この選択は、コンパクションやインデックスの再構築に関連するコストの増加にもつながることに注意する必要があります。
プレフィルタリングメタデータ検索
メタデータのフィルタリングは多くの人にとって重要な機能です。この機能により、特定の日付、特定の作者、特定の属性値のベクターだけを検索することができます。ベクター検索アプリケーションを設計するとき、メタデータフィルタリングをベクター検索機能の前または後に置くことができます。
ベクトル検索を行う前に、Milvusはメタデータのビットマスクを生成します。この前処理は時間的にリニアです。Milvusはデータを一度見直し、メタデータが提供されたフィルター式に一致するかどうかをチェックします。メタデータを事前にフィルタリングすることで、ベクトル検索の対象となるデータ量が減少し、ベクトル検索がより効率的になります。
近日リリース予定のMilvus 2.4では、tantivyによる転置インデックスに対応し、プレフィルタ処理速度が飛躍的に向上する予定です。
まとめ
Milvusはアクセス、コーディネーション、ワーカー、ストレージの4層からなる分散システムアーキテクチャを採用している。ベクターデータベースの多様なユースケースを考慮すると、適応可能で進化するインフラストラクチャが不可欠である。Milvusはこの要件に沿ってデータ取り込みコンポーネントをpub/sub(パブリッシュ・サブスクライブ)システムとしてモデル化しています。
データ取り込みをpub/subサービスとしてモデル化することで、サービスパラダイムを切り離すことができ、データの一貫性を保つことができます。パブリッシュ "サービスは、一貫性機能の一部として、各データにタイムスタンプを付けます。
ベクトルデータベースにおける3つの関心事(クエリ、データ取り込み、インデックス作成)に関して言えば、Milvusはそれらをすべて分離している。3つの操作にはそれぞれ専用のノードがあります。Milvusは、データ量や使用パターンに応じてスケールすることができます。
データの一貫性を確保することは、データ量が増大するにつれて最も困難な課題のひとつとなります。Milvusは、"シャード "を使用することでこの課題に対処している。入ってきたデータはハッシュ化され、そのハッシュに基づいてシャードに分割される。Milvusの一貫性は4段階から選択可能で、検索の応答速度とデータベースの多数のインスタンス間でのデータの複製速度のトレードオフを行うことができる。
スケールの大きなデータの書き込みには複数のシャードが使用される。スケールの大きなデータの読み込みにはセグメントを使用します。インデックスは個々のセグメント上に構築される。クエリ時に各セグメントを並列検索できるようになり、大量データの検索時間が大幅に短縮される。
データを検索する際、何らかの方法でデータをフィルタリングしたいと思うことでしょう。Milvusはメタデータのフィルタリングをプリフィルタリングとして実装しています。そして、ベクトル検索時にデータセットにビットマスクを適用し、適合しないベクトルをスキップします。このアプローチにより、多くのベクトルがフィルタリングされた場合、検索時間を大幅に短縮することができる。
Milvusのユニークなアーキテクチャは、多くの利点、特に水平スケーリングを提供する。最適なパフォーマンスを維持しながら迅速に水平スケーリングできるよう、クラウドネイティブなベクターデータベースとして細心の注意を払って作られています。意図的に切り離されたアーキテクチャーの設計により、Milvusを長期的に進化させることが容易になり、柔軟性がもたらされる。この適応性は、ベクターデータベースが注目され、そのユースケースが拡大していることを考えると、非常に重要です。

読み続けて

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.