




非構造化データの移行と変換を効率化するDatabricks Connectorをご紹介します。
AIや機械学習(AI/ML)技術の急速な進化に伴い、vector embeddingsは、非構造化データをインデックス化し、意味検索を行うための手法として選択されるようになった。
AI駆動型検索は通常、オフラインのデータ索引付けとオンラインのクエリ提供という2つの異なるフェーズから構成され、異なる技術スタックの利用が必要となる。しかし、オフライン処理スタックからオンラインサービングスタックへデータをシームレスに効率的に移行することは困難である。Zilliz Cloudの最新リリースでは、Apache Spark/DatabricksとMilvus/Zilliz Cloudを統合することで、このプロセスを効率化するためのDatabricks Connectorを導入している。
この投稿では、この統合を紹介し、実際のシナリオでの使い方を探り、使い方を説明します。
Databricks Connectorの仕組みと使用例
Sparkは、大規模データを処理する能力と機械学習に長けていることで有名だ。一方、Milvusは、機械学習モデルによって生成されたベクトル埋め込みを効率的に処理・検索することに優れています。この2つの強力な技術を組み合わせることで、ジェネレーティブAI、レコメンデーションシステム、画像・動画検索などの分野における最先端のアプリケーション開発が容易になります。
SparkからMilvusへのデータ転送は、AIを活用した検索を構築する上で一般的なタスクだが、検索システムのバックエンドに複雑なグルーコードが含まれることが多い。Spark-Milvusコネクターはこのプロセスを簡素化し、Sparkプログラム内の単一の関数呼び出しに凝縮する。
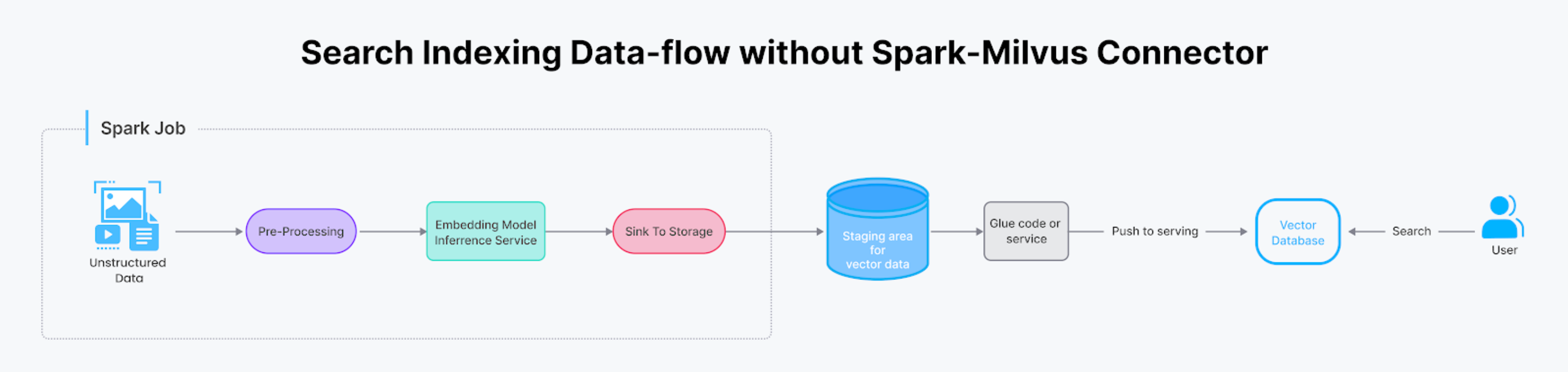
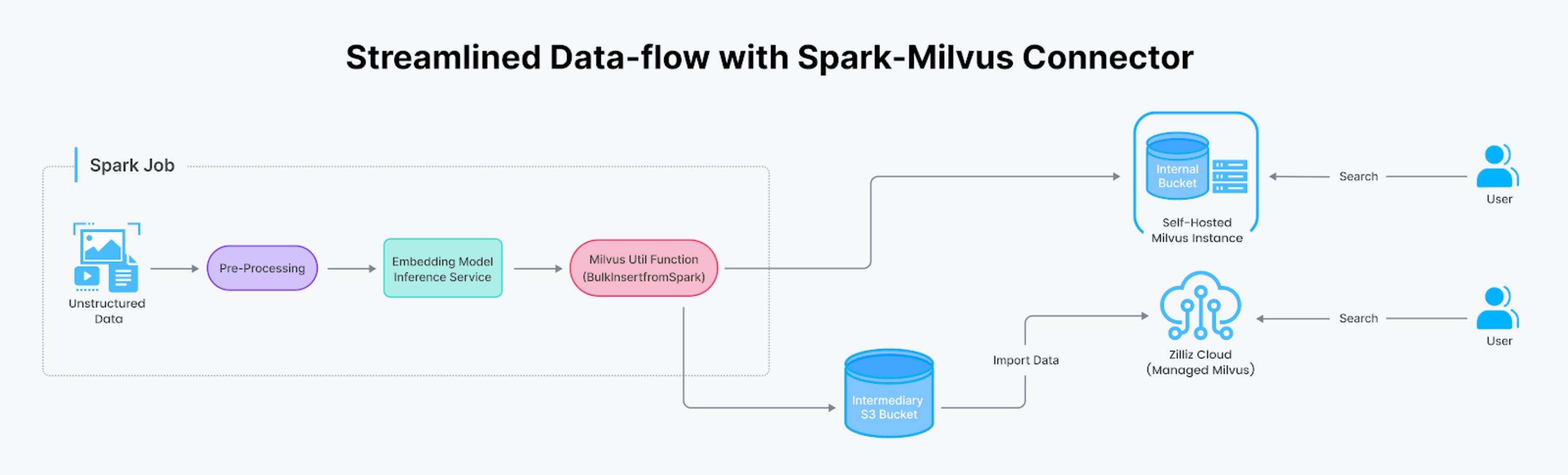
このコネクターは様々な場面で役に立つ。
バッチ・データ・インポート
機械学習の専門知識を持つチームは、最新の研究成果を取り入れるためにエンベッディングモデルを更新することがよくあります。エンベッディングモデルをアップグレードするたびに、データコーパス全体がSparkジョブによって再処理され、新しいベクトルセットが生成される必要があるため、チームは多くの場合、これらの新しいベクトルをサービングスタックに統合するために、カスタム「グルーコード」、専用サービス、または別のSparkジョブが必要になります。しかし、Databricks Connectorを使用すると、このタスクはMilvusのS3バケット(またはZilliz Cloudを使用する場合はエフェメラルバケット)への書き込み権限をジョブに与えるだけでよくなります。この合理化されたプロセスにより、ベクトルを生成するSparkジョブは、簡単なユーティリティ関数の呼び出しによってMilvusインスタンスに直接データをロードすることができます。
反復挿入
大規模な処理を行わないユーザーは、Spark-Milvusコネクタを使用してSpark DataFrameレコードをMilvusに直接挿入することもできます。このアプローチでは、接続を確立するコードやAPIコールを書く手間が省け、統合プロセスがよりスムーズになります。
Databricks コネクタの使用方法
このセクションでは、Databricks Connector を使用してデータの移行と変換を効率化する方法を示します。
Spark データフレームの反復挿入
SparkとMilvusの接続により、SparkからMilvusへのデータストリーミングがかつてないほど簡単になりました。SparkのネイティブDataframe APIを使って、SparkからMilvusに直接データをプッシュできるようになりました。同じコードはDatabricksやZilliz(フルマネージドMilvus)でも動作します。この方法を示すコード・スニペットです:
// 対象となるMilvusインスタンスとベクトルデータ収集の指定
df.write.format("milvus")
.option(MILVUS_URI, "https://in01-xxxxxxxxx.aws-us-west-2.vectordb.zillizcloud.com:19535")
.option(MILVUS_TOKEN, dbutils.secrets.get(scope = "zillizcloud", key = "token"))
.option(MILVUS_COLLECTION_NAME, "text_embedding")
.option(MILVUS_COLLECTION_VECTOR_FIELD, "embedding")
.option(MILVUS_COLLECTION_VECTOR_DIM, "128")
.option(MILVUS_COLLECTION_PRIMARY_KEY, "id")
.mode(SaveMode.Append)
.save()
コレクションを一括ロードする
大量のデータを効率的に転送する必要がある場合は、¶MilvusUtils. bulkInsertFromSpark ()¶関数を使用することをお勧めします。この方法は、巨大なデータセットを扱うのに超効率的です。
Milvusのアプローチ
Milvusインスタンスの内部ストレージとしてS3またはMinIOバケットを利用する。SparkやDatabricksへのアクセスを許可することで、SparkジョブはMilvusコネクタを使用してバッチでバケットにデータを書き込み、その後コレクション全体を一括インサートして提供することができる。
// バッチでデータをMilvusバケットストレージに書き込む。
val outputPath = "s3a://milvus-bucket/result"
df.write
.mode("上書き")
.format("parquet")
.save(outputPath)
// Milvusのオプションを指定する。
val targetProperties = Map(
MilvusOptions.MILVUS_HOST -> host、
MilvusOptions.MILVUS_PORT -> port.toString、
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName、
MilvusOptions.MILVUS_BUCKET -> bucketName、
MilvusOptions.MILVUS_ROOTPATH -> rootPath、
MilvusOptions.MILVUS_FS -> fs、
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint、
MilvusOptions.MILVUS_STORAGE_USER -> minioAK、
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK、
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// Sparkの出力ファイルをMilvusに一括挿入する。
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "parquet")
Zillizクラウドのためのアプローチ
Zilliz Cloud(マネージドMilvus)を使用している場合、その便利なData Import APIを活用することができます。Zilliz CloudはSparkを含む様々なデータソースからデータを効率的に移動するための包括的なツールとドキュメントを提供しています。S3バケットを仲介として設定し、Zilliz Cloudへのアクセスを許可することで、Data Import APIはS3バケットからベクターデータベースへシームレスにデータをロードします。
このインテグレーションを実行する前に、Databricks Clusterにjarファイルを追加してSparkランタイムをロードする必要があります。ライブラリをインストールする方法は様々です。以下のスクリーンショットは、ローカルからクラスタにjarをアップロードしています。
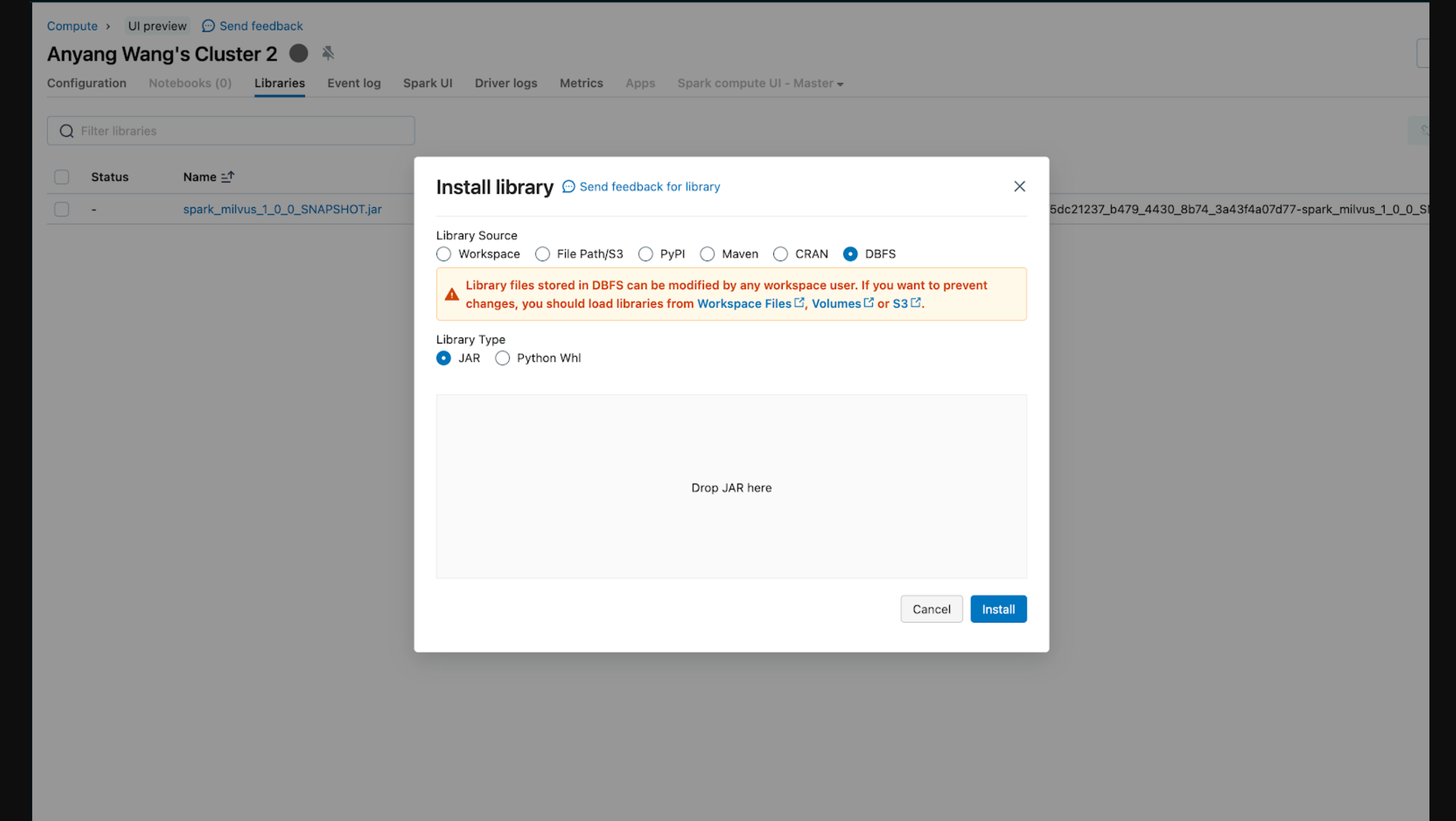
Databricksワークスペースへのライブラリのインストールについての詳細は、Databrickの公式ドキュメントを参照してください。
一括インサートでは、Zilliz Cloudが一括でインポートできるように、一時的なバケットにデータを保存する必要があります。S3バケットを作成し、Databricksの外部ロケーションとして設定することができます。詳細は本ドキュメントをご参照ください。Zilliz Cloudの認証情報のセキュリティリスクを軽減するために、Databricksの説明に従ってDatabricks上で安全に認証情報を管理することができます。
バッチデータマイグレーションプロセスを紹介するコードスニペットです。上記のMilvusの例と同様に、クレデンシャルとS3バケットアドレスを置き換えるだけです。
// バッチデータをMilvusのバケットストレージに書き込む。
val outputPath = "s3://my-temp-bucket/result"
df.write
.mode("上書き")
.format("mjson")
.save(outputPath)
// Milvusのオプションを指定する。
val targetProperties = Map(
MilvusOptions.MILVUS_URI -> zilliz_uri、
MilvusOptions.MILVUS_TOKEN -> zilliz_token、
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName、
MilvusOptions.MILVUS_BUCKET -> bucketName、
MilvusOptions.MILVUS_ROOTPATH -> rootPath、
MilvusOptions.MILVUS_FS -> fs、
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint、
MilvusOptions.MILVUS_STORAGE_USER -> minioAK、
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK、
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// Sparkの出力ファイルをMilvusに一括挿入する。
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "mjson")
すべてをまとめる: 全体のプロセスを説明するノートブックの例
すぐに始められるように、MilvusとZilliz Cloudを使ったストリーミングとバッチデータ転送プロセスを説明するノートブックサンプルを用意しました。
結論
SparkとMilvusの統合は、AIを活用したアプリケーションにエキサイティングな可能性をもたらします。データポータビリティへの合理化されたアプローチにより、開発者はリアルタイムモードであれバッチモードであれ、Spark/DatabricksからMilvus/Zilliz Cloudへ簡単にデータを転送することができます。この統合により、効率的でスケーラブルなAIソリューションを構築し、これらの強力なテクノロジーの可能性を最大限に引き出すことができます。
AIの旅に出る準備はできていますか?今すぐZilliz Cloudで無料でスタートしましょう。インストールの手間もなく、クレジットカードも必要ありません。
 Jiang Chen
Jiang ChenJiang is currently Head of Ecosystem and Developer Relations at Zilliz. He has years of experience in data infrastructures and cloud security. Before joining Zilliz, he had previously served as a tech lead and product manager at Google, where he led the development of web-scale semantic understanding and search indexing that powers innovative search products such as short video search. He has extensive industry experience handling massive unstructured data and multimedia content retrieval. He has also worked on cloud authorization systems and research on data privacy technologies. Jiang holds a Master's degree in Computer Science from the University of Michigan.
読み続けて

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Knowledge Injection in LLMs: Fine-Tuning and RAG
Explore knowledge injection techniques like fine-tuning and RAG. Compare their effectiveness in improving accuracy, knowledge retention, and task performance.