




知っておくべきDeepSeekの素晴らしい統合の長いリスト
シリコンバレーのビッグテックの陰で、DeepSeek-中国発の600万ドルのオープンソースプロジェクトがAIの世界を席巻している。そのツールや統合のエコシステムは、OpenAIやMetaのような伝統的な技術プレーヤーから市場シェアを奪っている。この記事では、シリコンバレーがあなたが無視することを望んでいる最もゲームチェンジャー的な統合のいくつかをクローズアップし、あなたのビジネスが見逃すわけにはいかない理由を説明する。
DeepSeekの概要
DeepSeekは、中国のスタートアップDeepSeek AIによって開発された一連の大規模言語モデル(LLMs)である。データの検索と取得を強化するために設計されたDeepSeekは、機械学習(ML)、自然言語処理(NLP)、ディープニューラルネットワークを活用し、人間のようなテキストを処理・生成します。その中核となるDeepSeekは、Deepseek-7B、Deepseek-67B、およびDeepSeek-Coderのような特殊なバリエーションを含むモデルファミリーを通じて、卓越したパフォーマンスを提供します。従来のAIモデルとは異なり、フラッグシップモデルであるDeepSeek-V3はMoE(Mixture of Experts)アーキテクチャを採用しており、クエリごとに6710億個のパラメータのうち必要なブロック、すなわち370億個のみをアクティブにすることで、GPT-4やGeminiと比較して計算コストを90%削減する。主な特徴は以下の通り:
Multi-Head Latent Attention (MLA):より高速な推論を実現。
グループ相対政策最適化(GRPO):**自律的推論のため
MITライセンスによるオープンライト:**自由な商用利用のため
シリコンバレーが注目する理由
DeepSeekの設計とアーキテクチャは、拡張性とアクセス性を両立させている。OpenAIやMetaのような企業がリソース集約型モデルに多額の投資を行っているのに対し、ディープシークは、通常必要とされる数億ドルの予算を大幅に下回る約600万ドルのトレーニング費用で競争力のある結果を達成したと主張している。この数字は、高性能AIがシリコンバレーの予算を必要としないことを示唆している。そのモデルは現在、リートコードの精度82%(GPT-4の68%)、数学のGSM8Kスコア92.1%といった印象的な指標を誇っており、シリコンバレー規模の予算の必要性に挑戦している。さらに、DeepSearcherのようなツールに見られる強固なプライバシー機能により、企業は機密情報を公開することなく、安全に内部データを活用することができます。
長いDeepSeek統合リスト
以下は、DeepSeekの柔軟性と様々な業界における実際の適用可能性を示す、素晴らしいDeepSeek統合の厳選されたリストです。
1.### DeepSearcher**(ディープサーチャー
DeepSearcherは、ZillizによるPythonベースのツールで、DeepSeek、OpenAIなどの複数のLLMとベクトルデータベース機能(例えば、Milvus)を組み合わせたものである。データをベクトル埋め込みに変換し、ベクトルデータベースを介して保存されたデータと照合することで、PDFや社内文書などの大規模で構造化されていないデータセットに対して、セキュアでセマンティックなデータ検索を実行する。この統合は、Q&Aシステムの構築に理想的であり、企業が機密データを損なうことなく内部文書にアクセスすることを可能にする。
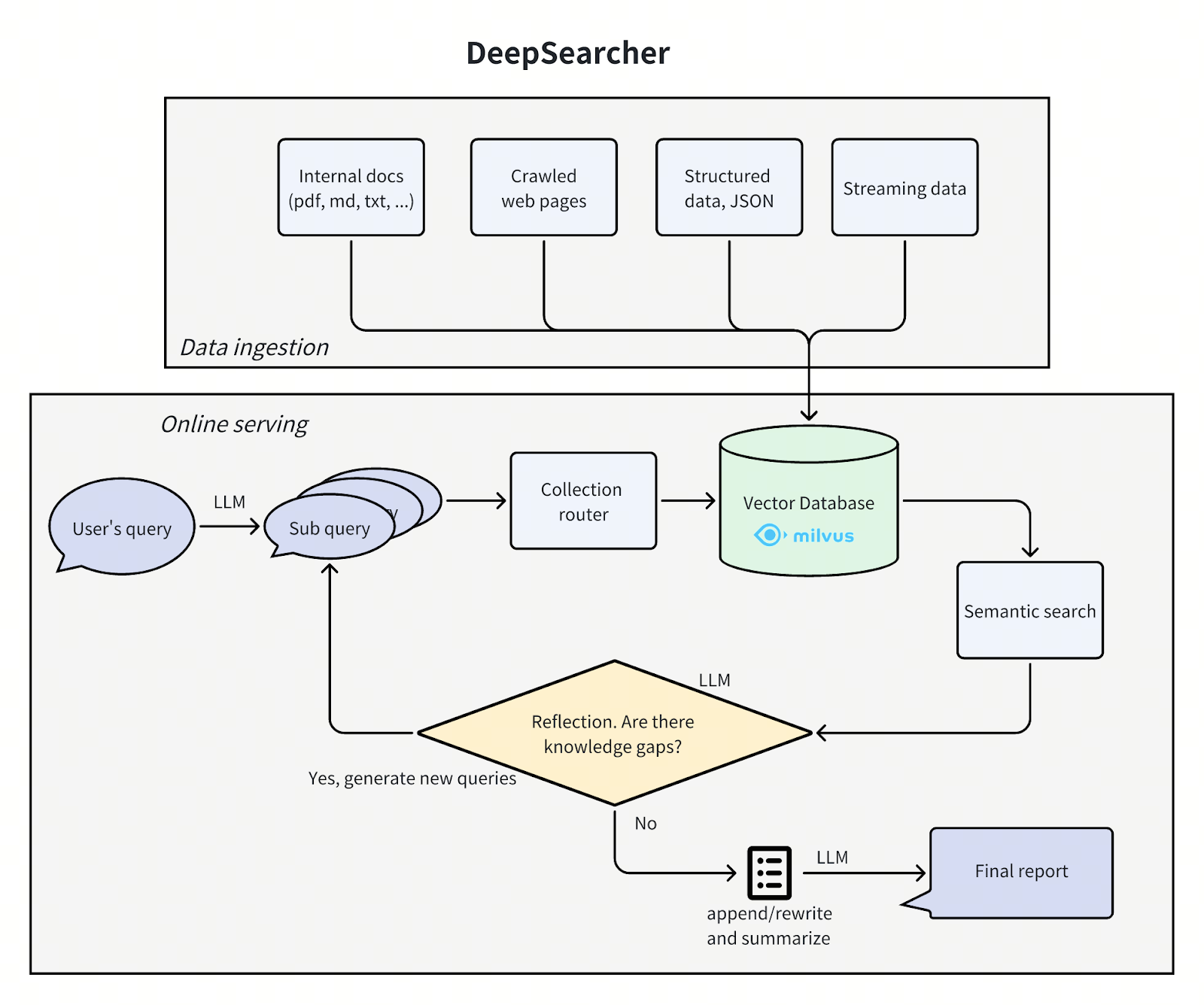
**図:DeepSearcherアーキテクチャ
パイソン
例:例: DeepSeekおよびMilvusを使用したDeepSearcherの構成と使用
from deepsearcher.configuration import Configuration, init_config
from deepsearcher.offline_loading import load_from_local_files
from deepsearcher.online_query import query
LLM として DeepSeek を初期化します。
config = 構成()
config.set_provider_config("llm", "DeepSeek", {"model": "deepseek-chat"})
config.set_provider_config("vector_db", "Milvus", {"uri": "./milvus.db"}) config.set_provider_config("embedding", "MilvusEmbedding", {"model": "BAAI/bge-base-en-v1.5"})
init_config(config)
ローカル文書(PDF、テキストファイル)を読み込みます load_from_local_files(paths_or_directory="/path/to/enterprise_docs")
安全なセマンティック検索
result = query("Milvusにおけるベクトルの類似性を説明する")
print(result[0].text)
2.### **RAGFlow**
[RAGFlow](https://github.com/infiniflow/ragflow)は、DeepSeekのドキュメントを処理し理解する能力を利用した、RAG(Retrieval-Augmented Generation)のためのオープンソースエンジンである。ドキュメントをチャンクに分割し、埋め込みを生成し、ベクトルデータベースに格納する。クエリが実行されると、RAGFlowは最も関連性の高いセグメントを取得し、引用を含むコンテキストリッチな回答を生成します。RAGFlowは、PDF、画像、テーブルのレイアウト解析に対応しており、スケーラブルなQ&Aシステムやコンテンツジェネレータの導入を検討している企業に適しています。
パイソン
from ragflow import RAGPipeline
from deepseek_rag import DeepSeekEmbedder
# DeepSeekエンベッディングとMilvusで初期化する
rag = RAGPipeline(
embedder=DeepSeekEmbedder(model="deepseek-r1")、
database="milvus", # カスタム設定が必要です。
api_key="<YOUR_KEY>"
)
rag.ingest("path/to/document.pdf")
3.### Milvus ベクターデータベース
DeepSeek と Milvus の統合は、強力な RAG パイプラインを形成する。DeepSeek は、テキストやその他のデータタイプ(テキスト、画像、音声など) の埋め込みを生成し、類似検索に最適化された拡張性の高いベクターデータベースである Milvus に格納・管理します。クエリが発行されると、Milvusは最も意味的に類似したベクトルを素早く見つけます。MilvusとDeepSeekでRAGを構築する](https://milvus.io/docs/build_RAG_with_milvus_and_deepseek.md)」のドキュメントで実証されているように、これらを組み合わせることで、迅速な検索とコンテキストに関連したレスポンスの生成が可能になります。この組み合わせにより、高次元ベクトルデータの効率的な保存、インデックス付け、検索が可能となり、類似検索、推薦システム、企業規模のQ&Aなどの大規模展開に最適です。
パイソン
from deepseek_api import generate_embeddings
from pymilvus import MilvusClient
DeepSeekを使用して埋め込みを生成する
text = "Milvusにはどのようにデータが格納されていますか?"
embedding = generate_embeddings(text, model="deepseek-v3")
Milvusに接続して挿入する
client = MilvusClient(uri="http://localhost:19530")
client.insert(collection_name="my_collection", data=[{"vector": embedding, "text": text}])
詳しくは[Zilliz Cloud](https://zilliz.com/cloud)でマネージドMilvusサービスを体験してください。
4.### カーソル
[Cursor](https://www.cursor.com/)は、DeepSeekを統合し、コード生成、エラーのデバッグ、自然言語プロンプトを使用したコンテキスト認識提案で開発者を支援するAI搭載コードエディタ(VS Code上に構築)です。複雑なコードベースのナビゲート、サジェストによる効率的なコードの記述、自然言語からコードへの翻訳、コードスニペットの理解を簡素化し、開発者にとって日常的なツールとなる。
例えば、Pythonのメモリリークを修正する:
Python
# ユーザー入力:"なぜこのループは8GB RAMを消費しているのか?"
for i in range(10**8):
data = np.zeros((1000, 1000)) # DeepSeek は、「ジェネレータまたはチャンク・データを使用する」ことを提案します。
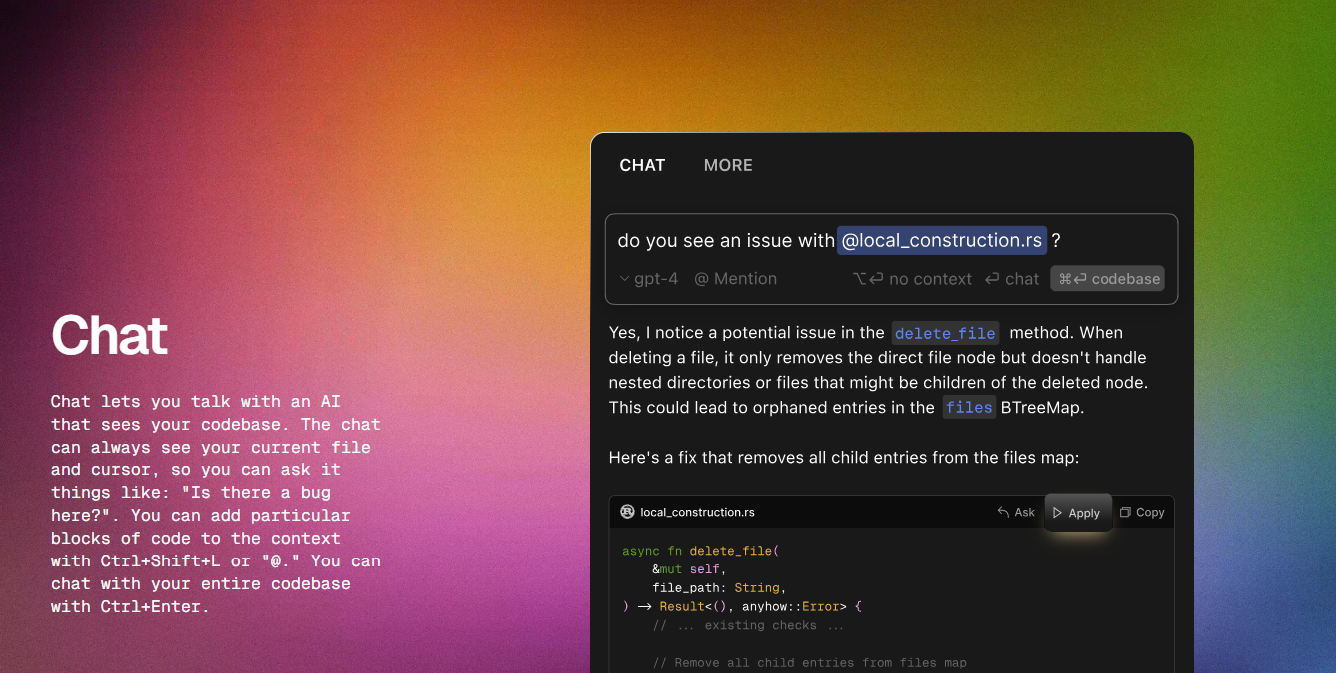
図:AIとのカーソルチャット_ Source.
5.### リューバイ
Liubaiは、DeepSeekをWeChat上の生産性アシスタントに変える。ユーザーは、自然言語コマンドを使用して、タスク、メモ、カレンダー、ToDoリストを管理することができます。この統合により、日常の個人的な整理がより効率的になり、日常的なタスクの管理が容易になる。例えば、ユーザーは次のように入力する:
"明日の午後3時にアレックスと会う予定"
“summarize https://arxiv.org/pdf/2401.06066”
6.### アップソニック
Upsonicは、AI主導のタスクを記述するためのエンタープライズ対応のフレームワークを提供する。DeepSeekを活用し、1つのシステム内で複数のAIモデルの呼び出しとエージェントの対話を処理する。例えば、CRMシステムからデータを取得し、正確な応答を生成し、企業全体のリソース割り当てを最適化することで、カスタマーサポートを自動化することができる。
パイソン
from upsonic import エージェント
support_agent = Agent(
task="Resolve billing disputes"、
models={"deepseek":「r1-8b"}、
max_cost="$0.02/query"
)
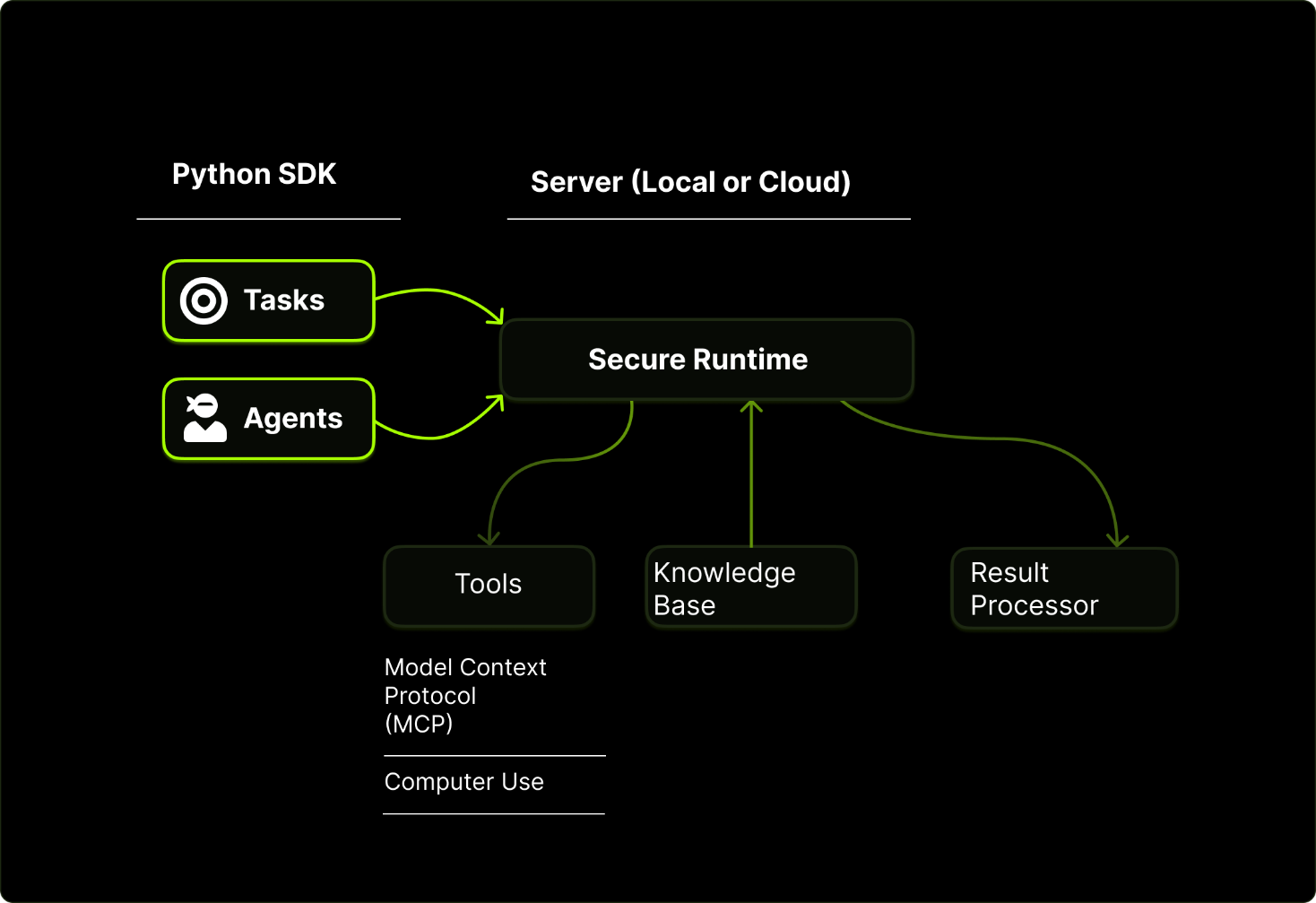
**図:アップソニックの仕組み._** [**_Source_**](https://docs.upsonic.ai/introduction#how-upsonic-works)**_._**
7.### 16x プロンプト
[16x Prompt](https://prompt.16x.engineer/)は、DeepSeekを使用してソースコードのコンテキストを管理し、API統合やバグ修正などのタスクに対して詳細なプロンプトを生成する開発者ツールです。プロンプトを自動生成し、コーディングセッション中に支援を提供することで、明確さを維持することが重要である大規模な複数ファイルのプロジェクトで特に役立ちます。このツールは、プロンプトの作成、テスト、コラボレーション、およびバージョン管理を簡素化し、開発者がプロンプトのパフォーマンスを最適化できるようにします。
8.### Siri_deepseek_shortcut
このカスタム iOS ショートカットは、DeepSeek を Siri と統合し、音声による AI 支援を可能にします。ユーザーは、「Hey Siri、会議のメモを箇条書きに要約して」と尋ねると、DeepSeek-R1 による応答を受け取ることができます。コードのデバッグや、多忙な専門家のための記事の要約などのタスクのための外出先でのインタラクションを可能にすることで、日常生活にハンズフリーの生産性をもたらします。
9.### Mem0
[Mem0](https://github.com/mem0ai/mem0)は、"_The Memory Layer for your AI Agents_"として知られ、インテリジェントなメモリレイヤーを追加することでDeepSeekを補強するパーソナルアシスタントである。この統合により、AIは以前の対話、ユーザーの好み(例えば「Pythonのコード例がいい」)、時間の経過に伴うコンテキストを記憶することができる。また、Mem0に保存されたメモ、文書、電子メール、その他の個人データの意味と文脈を理解することもできる。このような継続性は、カスタマー・サポート、パーソナル・アシスタント、会話の文脈を維持することが重要なあらゆるアプリケーションを強化する。さらに、メモの自動整理、ナレッジグラフの生成、スマートコンテンツリンク、個人ナレッジベースのセマンティック検索にも優れている。
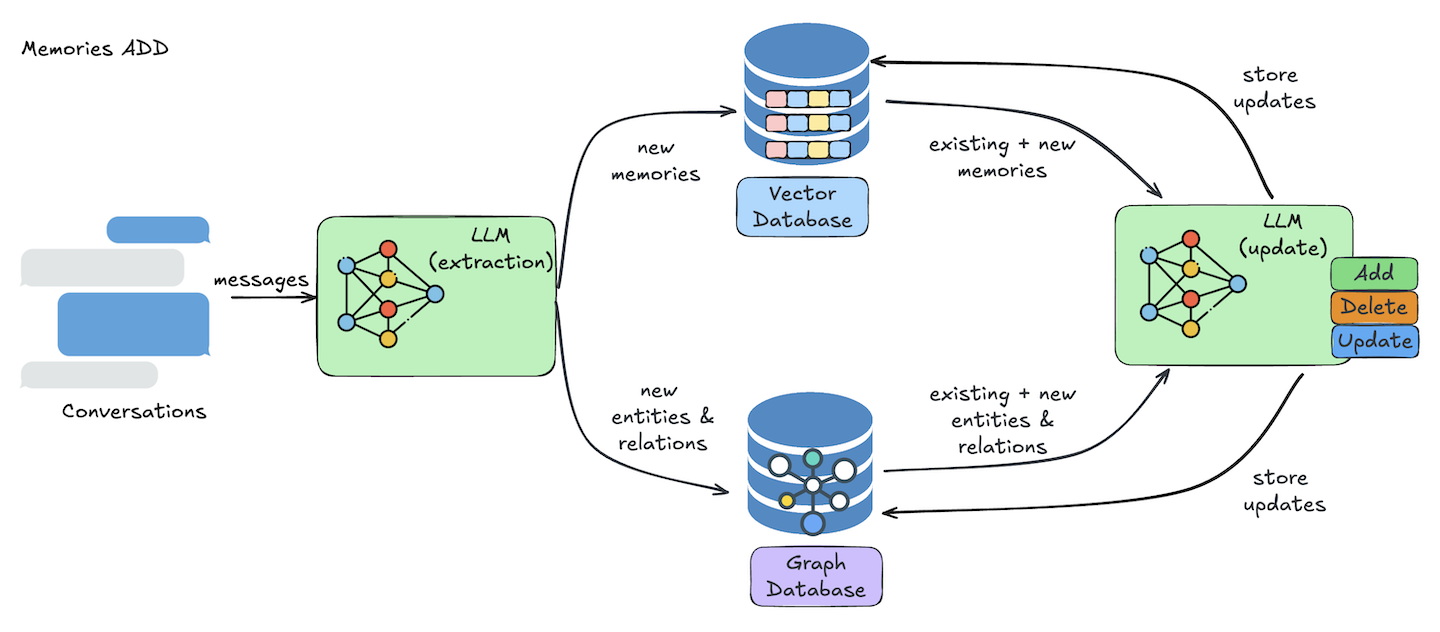
**図:記憶を追加するプロセスを示すアーキテクチャ図_** [**_Source_**](https://docs.mem0.ai/overview)**_._**
10.### ラングヒューズ
[Langfuse](https://zilliz.com/product/integrations/Langfuse)は、DeepSeek と連携してモデルのパフォーマンスを監視、デバッグ、 分析する、オープンソースの観測可能性および分析プラットフォームです。レイテンシ、コスト、トークン使用量、出力品質などの主要パフォーマンス指標(KPI)を追跡し、チームがAI統合を微調整するのに役立ちます。Langfuseを使えば、開発者は各クエリのパフォーマンスを記録し、最適化すべき領域を特定できます。Langfuseには、モデルの出力を視覚化・分析して、パターンや偏り、改善すべき領域を特定するためのツールがあります。さらに、特定のタスクのパフォーマンスを最適化するために、さまざまなDeepSeekモデルの構成やプロンプトのA/Bテストを容易にします。
DeepSeek API の使用状況を監視します:
パイソン
from langfuse import Langfuse
langfuse = Langfuse()
def query_deepseek(prompt):
start = time.time()
response = deepseek.query(プロンプト)
langfuse.log(
input=prompt、
output=response、
latency=time.time() - start、
cost=calculate_cost(response)
)
レスポンスを返す
11.### ゲネプロAI
Geneplore AIは、DeepSeek v3やR1などの最新バージョンを含む、DeepSeekの高度なモデルをサポートする最大級のAI Discordボットです。Discordコミュニティ内でのインタラクティブなQ&Aセッション、コンテンツ生成、さらには科学研究の分析を可能にする。例えば、研究論文を分析したり、自然言語の記述からLaTeX方程式を生成したりすることができる。また、SDXLやFLUX.1のようなモデルを使用して、高品質の画像やビジュアルを生成することもできる。
12.### キュレーター
Curator は、DeepSeek モデルの学習後のデータセットのキュレーションを簡素化し、低品質なデータや冗長な データをフィルタリングするオープンソースのツールです。言語モデルの微調整、異常や予期しないパターンの自動検出、コンテンツの分類のために、高品質のデータセットを維持するのに役立ちます。この統合は、よりクリーンなトレーニングデータを通じてモデルのパフォーマンス向上を目指す研究開発チームに最適です。さらに、CuratorはDeepSeekのAI機能によってコンテンツ管理を簡素化し、自動コンテンツ分類、スマートタグ付け、コンテンツ推薦、エンゲージメント分析を提供します。例えば、データサイエンティストはCuratorを使用して、デモグラフィックを要約したり、異常な支出パターンを検出したりすることで、大規模な顧客データセットをクリーンにすることができます。
DeepSeekの微調整のためのトレーニングデータをクリーニングします:
パイソン
from curator import DataFilter
DeepSeek-R1 で DataFilter を初期化します。
filter = DataFilter(model="deepseek-r1")
低品質なテキストを最小信頼度閾値で除去する
clean_data = filter.remove_low_quality(texts, min_confidence=0.8)
13.### Dify
[Dify](https://zilliz.com/product/integrations/dify)は、企業がコードを書かずにAIアプリを構築・展開できるノーコード・プラットフォームである。DeepSeekのLLMリソースに加え、ビルド済みのコンポーネント、テンプレート、ワークフローを組み込むことで、チャットボット、ワークフロー自動化ツール、テキストジェネレータの作成を簡素化します。ユーザーフレンドリーなインターフェースと柔軟な設計により、非技術系ユーザーだけでなく、企業の開発者にも人気があります。
14.### その他
上記の統合以外にも、DeepSeek のエコシステムは以下のようないくつかのツールに広がっています:
- Zotero:学術研究を強化、共同作業、整理、引用するためのツール。
- SiYuan:**安全なオフライン・データ・ハンドリングのためのパーソナル知識管理システム。
- Raycast:**迅速なクエリのためのDeepSeek拡張機能を備えたmacOSの生産性ツール。
- Chatbox:**Windows、Mac、Linux、Androidで利用可能なデスクトップ・スマート・アシスタント。
- Bolna:**コールセンター向けに設計された音声AIエージェント。
- PHPクライアントとLaravelの統合:** これはウェブ開発におけるAPI統合のためのものです。
## 要約
DeepSeekの統合は、オープンソースのAIがシリコンバレーのクローズドシステムに匹敵することを証明している。DeepSeekは、そのコスト効率、強力なLLM、幅広い統合機能により、従来の数分の一のコストで高性能なAIを実現し、同時に個人データを安全に取り扱うことができます。エンタープライズRAGのMilvusやコード最適化のCursorなどのツールにより、開発者は最大90%の低コスト、コンシューマーGPUでの2.5倍の高速推論、プライベートデータのエンタープライズグレードのセキュリティなどのメリットを得ることができます。データ検索、コード編集、個人の生産性向上などのツールを網羅するエコシステムが成長するにつれ、DeepSeekは、次世代AIをリードするためにシリコンバレーの予算が必ずしも必要ではないことを証明している。AIの未来はオープンで、手頃な価格で、そしてここに留まる。
## 関連リソース
これらの統合についてさらに詳しく調べたり、最新の動向を把握したりすることに興味がある方には、[ DeepSeek Open Platform](https://platform.deepseek.com) と[ awesome-deepseek-integration GitHub リポジトリ](https://github.com/deepseek-ai/awesome-deepseek-integration) が継続的に更新されるリソースを提供しています。

読み続けて

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.