




時系列データベースとベクトルデータベースによる分析の改善
時系列分析は、多くの分野、特にモノのインターネット(IoT)機器において重要な役割を果たしている。時系列データを使えば、特定の期間におけるパターンや傾向を検出することができ、将来の時間に依存する事象の予測や分析が可能になる。時系列データの一般的な使用例としては、気温や株価の予測、センサーデータのモニタリングなどがあります。
時系列データベースとして、InfluxDBは膨大な量の時系列データを保存するためのソリューションを提供する。InfluxDBは、集約やダウンサンプリングなどのテクニックを用いて、時系列に依存するデータの保存やクエリに高度に最適化されている。しかし、時系列データベースだけに依存することは、特にユースケースで類似検索を行う必要がある場合、困難な場合がある。
先日のZilliz Unstructured Data Meetupでの講演で、InfluxDBのDeveloper AdvocateであるZoe Steinkamp氏は、InfluxDBとMilvusを組み合わせて、時系列に依存するユースケースの保存、クエリ、類似検索の実行を行うアプローチについて議論しました。
本記事では、このトピックをより詳しく掘り下げ、InfluxDBに時系列データを保存し、データをクエリし、ベクトル埋め込みに変換し、埋め込みをMilvusに保存し、最後にMilvusで類似検索を実行するユースケースを説明します。それでは、早速始めましょう。
時系列データの理解
時系列データとは、時系列に並んだ観測データを、時間毎、日毎、週毎、月毎など特定の間隔で記録したものである。
1時間ごとの気温、毎日の道路交通統計、毎月の小売売上高など、日常生活の中で時系列データを使用するケースを見つけることができます。時系列データを分析することで、過去のパターンを明らかにし、これらの洞察を将来の意思決定に役立てることができる。
時系列データを分析する場合、次のようなパターンがよく見られる:
1.季節性:平日や月などの要因に影響され、一定の時間間隔で繰り返し変動する。
2.トレンド:トレンド**:長期にわたるデータの安定した増減。
3.周期性:季節的なパターンに類似した変動だが、一定の頻度はない。
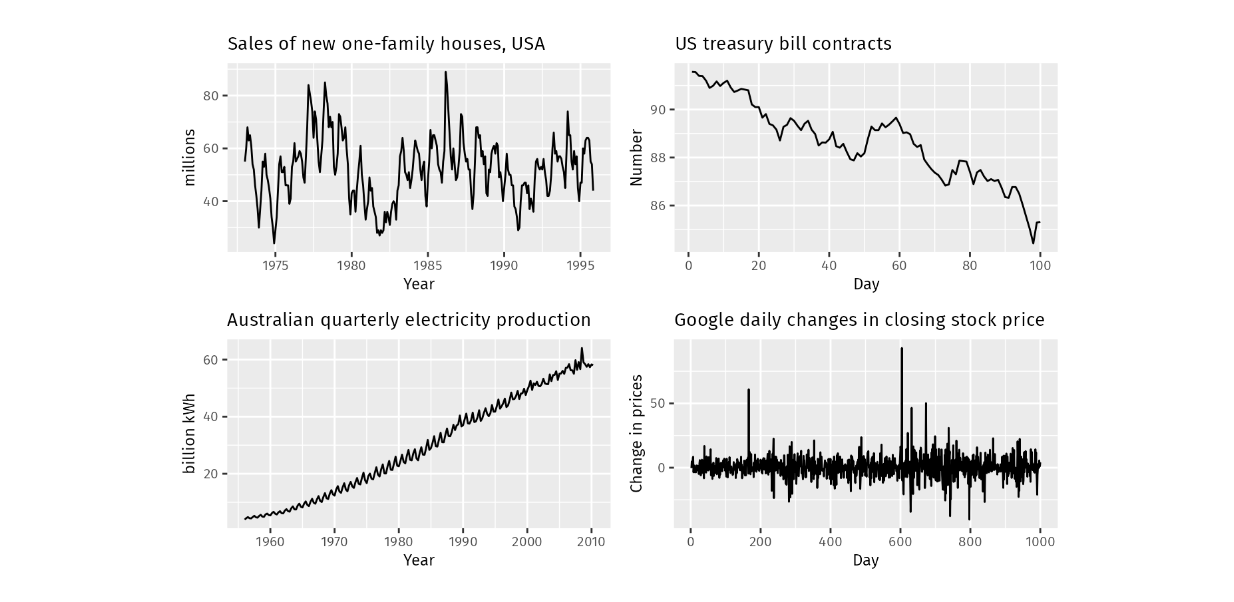
左上-季節性、右上-減少傾向、左下-増加傾向、右下-周期性_ Source..
これらのパターンを理解することは、効果的な時系列予測を行う上で極めて重要である。時系列予測は、過去のデータに基づいて時間に依存する変数の将来の値を予測する強力な分析手法です。例えば、過去2年間の株価履歴があり、明日の株価を予測したい場合、基本的には時系列予測を行っていることになります。
さまざまな分野の企業が、さまざまな目的で時系列予測のコンセプトを日常業務に応用している:
金融機関:**株価の予測、為替変動の予測、顧客支出の異常なパターンの特定、あるいは強固なリスク管理戦略の策定。
ヘルスケア分野:** 病気の蔓延を監視する、患者のバイタルサインをリアルタイムで追跡する、あるいは全体的な患者ケアと転帰を向上させる。
小売業界:**販売量の予測、顧客の購買行動の理解、在庫管理の最適化、価格戦略の微調整、全体的な収益性の向上。
モノのインターネット(IoT): **スマートホームシステムは、センサーデータを使用してタスクを自動化し、サーモスタットとホームハブはエネルギー使用を最適化するために情報を交換します。
製造業: **機械のダウンタイムを減らし、予知保全戦略を実施し、全体的な業務効率を改善する。
時系列データは、その時間に依存する性質から、通常、リアルタイムで継続的に収集される。その結果、時系列データの量は急速に増大する可能性があり、ストレージにはスケーラブルで効率的なソリューションが必要となります。そこで、時系列データベースが活躍します。
時系列データベースとしてのInfluxDB
時系列データベースは、大量の時系列データの保存と検索処理を容易にするために、従来のリレーショナルデータベースと比較していくつかの重要な特徴を持つ必要がある。前述したように、時系列データはリアルタイムで収集されることが多いため、データがデータベースに到達するとすぐに処理され、すべてのシステム間で同期される必要があります。
時系列データベースは、特に大量のデータと高頻度の書き込みを扱う場合、時間ベースのワークロードに対してリレーショナルデータベースよりも優れたパフォーマンスと効率を提供する。さらに、時系列データベースは、時間ベースの分析や集計と同様に、時間範囲にわたるデータの取り込み、クエリ、検索などの操作に対して高度に最適化されたソリューションを提供します。
時系列データベースにおける重要な機能](https://assets.zilliz.com/Important_features_in_a_time_series_database_26f71593b1.png)
InfluxDBは、オープンソースの時系列データベースの1つで、時系列データを保存するのに使うことができる。Rustで書かれており、データベースの抽出、変換、ロード(ETL)操作に高度に最適化されている。高速なデータの取り込みとタイムスタンプの同期を容易にするために、InfluxDBにはネットワークタイムプロトコル(NTP)を使用するタイムサービスが組み込まれている。
時系列データベースに格納される時系列データは、通常、タグ、フィールド、タイムスタンプの3つのカラムのみで構成されます。タグには測定したデータのメタデータが含まれ、フィールドにはさらに分析する値が含まれ、タイムスタンプはデータがいつ収集されたかを示します。
例えば、5分ごとにセンサーの測定データを保存しているとしよう。時系列内のデータは、以下の可視化のようになる:
時系列データベースに格納されたデータの例](https://assets.zilliz.com/Example_of_data_stored_inside_a_time_series_database_852617b686.png)
時系列データベースの基本がわかったところで、次はベクトル・データベースについて説明しよう!
ベクトルデータベースとしてのMilvus
その名の通り、ベクトルデータベースはデータ(画像、テキスト、ドキュメントなど)をベクトルで保存します。私たちは、多くのディープラーニングモデルのいずれかを使ってデータをベクトルに変換する。
ベクトルの次元は、それを生成するために使用する技術やディープラーニングモデルによって異なります。例えば、all-MiniLM-L6-v2というモデルを使えば、384次元のベクトルが得られる。一方、all-mpnet-base-v2というモデルを使えば、768次元のベクトルが得られる。
ご存知かもしれませんが、vectorは単なる数学的なオブジェクトではありません。大きさと方向の両方をカプセル化し、それが表すテキスト、画像、文書の意味的な意味を運びます。ベクトルが持つこの深遠な側面が、ベクトル空間内で互いに近接して配置し、類似したテキストや画像を表現することを可能にしているのです。
ベクトル空間におけるベクトル間の意味的類似性](https://assets.zilliz.com/Semantic_similarity_between_vectors_in_a_vector_space_ee6fb35909.png)
ベクトルがデータの意味的な意味を持つという考え方は、余弦類似度やユークリッド距離のような測定基準を介して、任意のペアのベクトルの類似性を比較することを可能にします。2つのベクトル間の余弦類似度が1に近い場合、2つのベクトルは非常に類似しており、その逆も同様です。
数個のベクトルしかなければ、類似性の保存と検索は簡単に実装できるかもしれない。しかし、現実のアプリケーションでは、通常数十万から数百万のベクトルを扱うことになり、時間的にも計算資源的にも、操作全体の維持にコストがかかります。そこで必要になるのがベクトル・データベースです。
MilvusやZilliz Cloudのようなベクターデータベースは、何百万ものベクターを保存するための非常にスケーラブルで効率的なプロセスを提供します。また、IVF-Flat、HNSWなど、多様で高度なインデックス作成手法により、ベクトルの類似性検索やデータ検索を高速化するために高度に最適化されています。
ベクトル検索操作の完全なワークフロー](https://assets.zilliz.com/Complete_workflow_of_a_vector_search_operation_7283d7546a.png)
Milvusやその他のベクトルデータベースからデータを保存・検索するワークフローは以下の通りである:まず、テキストや画像などの入力データを、好みの技術やモデルを使ってベクトルに変換します。次に、これらのベクトルをメタデータとともにベクトルデータベースに取り込み、任意のインデックス作成方法を用いてインデックスを作成する。
検索プロセスでは、まず、取り込みプロセスで使用したのと同じ手法やモデルを使用して、クエリをベクトルに変換する必要があります。次に、このクエリーベクトルをベクトルデータベースに格納されているベクトルと比較するために、ベクトル検索を実行します。最後に、データベース内の最も類似したベクトルが結果として返されます。
時系列データベースとベクトルデータベースを組み合わせた使用例
時系列データベースとベクトルデータベースは異なるユースケースに対して高度に最適化されているため、現実のプロジェクトでは両方のデータベースの長所を活用することができる。
例えば、スマートシティにおけるリアルタイムの交通状況を分析するシステムを開発するシナリオを想像してみよう。これを実現するために、車両速度、車両数、その他の関連する指標を追跡できるセンサーを多くの場所に設置する。特定の時間間隔の平均車速と車両数は、時系列データベース内に継続的に保存することができる。
センサーだけでなく、カメラを設置して実際の交通状況を写真やビデオで撮影することもできる。この場合、写真や動画を任意のディープラーニングモデルを使ってベクトルに変換し、ベクトルデータベースに格納することができる。時系列データベースの時系列データとベクトルデータベースのベクトルを組み合わせることで、交通状況の異常検知を行うことができる。
InfluxDBとMilvusを組み合わせてトラフィック状況を分析するユースケース例】(https://assets.zilliz.com/Example_use_case_of_combining_Influx_DB_and_Milvus_to_analyze_traffic_conditions_655bf05bea.png)
ここでは、InfluxDBとMilvusを利用して、交通状況に関する簡単なユースケースを実装します。具体的には、時系列データをInfluxDBに、対応するベクトルをMilvusに格納します。
まず、タイムスタンプ、平均車速、車両数、異常タイプからなるダミーの時系列データを生成してみよう。異常タイプは2つの異なる値からなる:「平常時 "と "事故時 "である。
まず、10分ごとに収集した500点の「通常」データを生成する。
npとしてnumpyをインポートする
import pandas as pd
from datetime import datetime, timedelta
インポートランダム
def generate_sensor_data(anomaly_type, start_time, vehicle_count_range, avg_speed_range, rows=500, seed = 42):
np.random.seed(seed)
vehicle_counts = np.random.randint(vehicle_count_range[0], vehicle_count_range[1], size=rows)
avg_speeds = np.random.uniform(avg_speed_range[0], avg_speed_range[1], size=rows)
start_time = datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
timestamps = [start_time + timedelta(minutes=10*i) for i in range(rows)].
df = pd.DataFrame({の
'Timestamp': timestamps、
車両数': vehicle_counts、
'Average Speed': avg_speeds、
'異常タイプ': anomaly_type
})
return df
vehicle_count_range = (5, 10)
平均速度範囲 = (60.0, 80.0)
df_normal = generate_sensor_data("normal", "2024-09-15 18:00:00", vehicle_count_range, avg_speed_range)
 DataFrame normal
DataFrame normal
次に、同じく10分ごとに収集した500点の「事故」データを生成してみよう。ご想像の通り、路上での事故の兆候として考えられるのは、車両数の増加と渋滞による平均速度の低下である。
vehicle_count_range = (20, 40)
平均速度範囲 = (10.0, 20.0)
df_accident = generate_sensor_data("accident", "2024-09-19 05:20:00", vehicle_count_range, avg_speed_range)
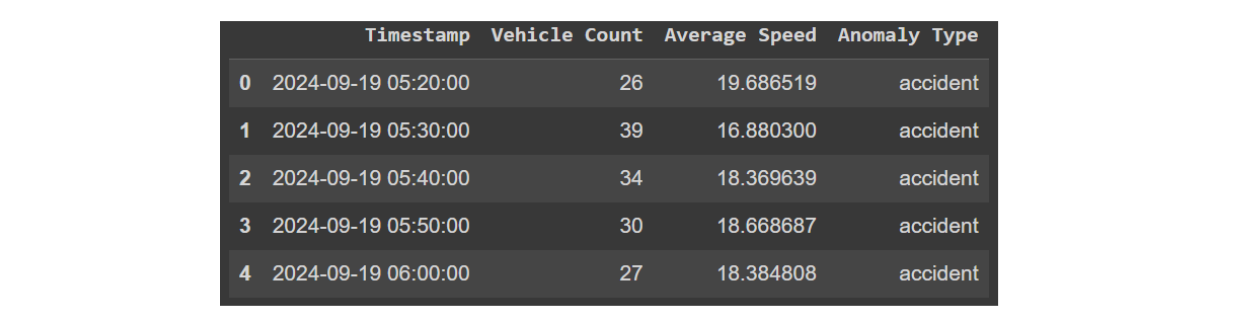 データフレーム事故
データフレーム事故
では、2つのデータフレームを連結し、連結したデータをInfluxDBに挿入するコマンドを以下のようにしてみよう:
from influxdb_client_3 import InfluxDBClient3
df = pd.concat([df_accident, df_normal], axis=0)
client = InfluxDBClient3(token="DATABASE_TOKEN"、
host="HOST"、
データベース="DATABASE_NAME")
client.write(bucket="DATABASE_NAME", record=df, data_frame_measurement_name='traffic_data', data_frame_tag_columns=['Anomaly Type'], data_frame_timestamp_column='Timestamp')
そして、以下のコマンドで InfluxDB 内のデータをクエリすることができる。
query = "SELECT * FROM traffic_data WHERE time >= now() - INTERVAL '90 days'"
pd = client.query(query=query, mode="pandas")
様々な操作についてもっと詳しく知りたい方は、こちらの InfluxDB Python Client Library ドキュメントをご覧ください。
それではベクトルデータを生成してみよう。上で説明したように、特定の時間間隔での交通状況の写真やビデオをデータソースとして使用し、ディープラーニングモデルを使ってベクトルに変換することができます。しかし、写真や動画がないので、特定の時間間隔の平均車速をリストに集め、実質的にベクトル化することにする。時系列分析では、この方法をウィンドウ処理と呼ぶ。
以下の例では、ウィンドウ・サイズを24に設定しますが、これはお好きなサイズに調整できます。これは、各データ・ポイントが10分ごとに収集されるため、各オブザベーションについて、次の240分間の平均車速値を収集することを意味します。その結果、各オブザベーションについて24次元のベクトルが得られます。
各観測について、ステップサイズ10を使用します。これは、連続するオブザベーション間の開始時間が100分異なることを意味します。さらに、各オブザベーションの各ベクトル要素で正規化を実行し、ベクトルが0から1まで一様にスケーリングされることを保証する必要があります。
ウィンドウサイズ = 24
ステップ・サイズ = 10
min_val = 10 # 最小平均車速
max_val = 80 # 最大平均車速
def vectorize_data(df):
ウィンドウズ = [
df.iloc[i : i + window_size].
for i in range(0, len(df) - window_size + 1, step_size)
]
start_times = [w["Timestamp"].iloc[0] for w in windows] ]。
end_times = [w["Timestamp"].iloc[-1] for w in windows].
avg_speed_values = [w["Average Speed"].tolist() for w in windows].
anomaly_types = [w["アノマリー・タイプ"].tolist()[0]for w in windows].
# 収集したデータから新しいDataFrameを作成する
embedding_df = pd.DataFrame(
{"start_time": start_times, "end_time": end_times, "vectors": avg_speed_values, "anomaly_types": anomaly_types}.
)
embedding_df["vectors"] = embedding_df["vectors"].apply(normalize_vector)
# タイムスタンプをUnixタイムスタンプ形式に変換するラムダ関数を適用する。
embedding_df['start_time'] = embedding_df['start_time'].apply(lambda x: pd.Timestamp(x).timestamp()).astype(int)。
embedding_df['end_time'] = embedding_df['end_time'].apply(lambda x: pd.Timestamp(x).timestamp()).astype(int)
return embedding_df
# センサ列を正規化する関数
def normalize_vector(vectors: list) -> list:
return (
[0.0] * len(vectors)
if max_val == min_val
else [(v - min_val) / (max_val - min_val) for v in vectors].
)
embedding_df = vectorize_data(df)
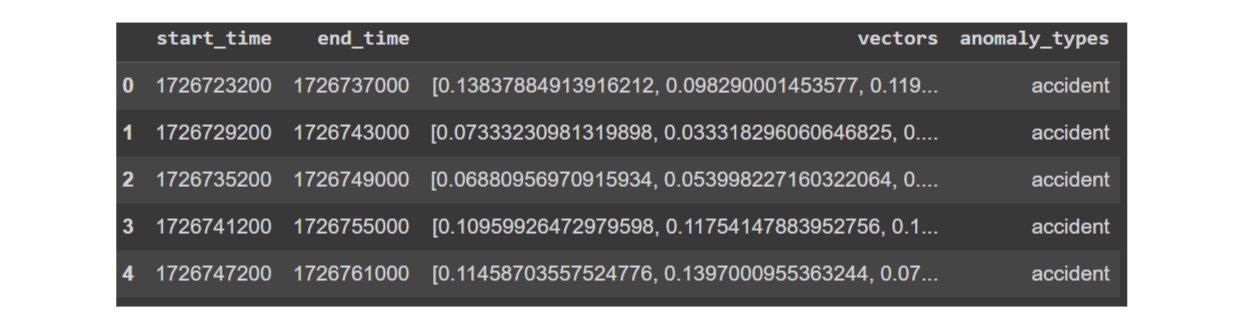 データフレームのベクトル
データフレームのベクトル
上記のように、開始時刻、終了時刻、ベクトル、アノマリータイプを持つデータフレームが出来上がりました。次に、このデータを直接Milvusデータベースに取り込むことができます。Milvusを使い始める最も簡単な方法はMilvus Liteを使うことです。まずMilvus Liteをインストールし、データフレーム内のカラムに従ってスキーマを作成します。
pip install pymilvus==2.4.6
from pymilvus import MilvusClient, DataType
dim = 24
コレクション名 = "traffic_data"
milvus_client = MilvusClient("./local_test.db")
has_collection = milvus_client.has_collection(collection_name, timeout=5)
if has_collection:
milvus_client.drop_collection(collection_name)
schema = milvus_client.create_schema(enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("start_time", DataType.INT64)
schema.add_field("end_time", DataType.INT64)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=dim)
schema.add_field("anomaly_type", DataType.VARCHAR, max_length=64)
index_params = milvus_client.prepare_index_params()
index_params.add_index(field_name = "vector", metric_type="L2")
milvus_client.create_collection(collection_name, schema=schema, index_params=index_params, consistency_level="Strong")
上記で定義したスキーマを作成したので、以下のコマンドでデータフレームをMilvusに取り込むことができます:
data = [
{
"id": i、
"vector": embedding_df['vectors'].iloc[i]、
"start_time": embedding_df['start_time'].iloc[i]、
"end_time": embedding_df['end_time'].iloc[i]、
"anomaly_type": embedding_df['anomaly_types'].iloc[i].
}
for i in range(len(embedding_df))
]
insert_result = milvus_client.insert(collection_name, data)
これで完了だ!これでベクトル検索ができるようになりました。
一週間後、特定の地域で平均車速が異常に低下しているのを観測したとしよう。以下の例では、以前に定義した関数を使用してこのデータを手動で生成します。しかし、実際のシナリオでは、タイムスタンプに基づいてInfluxDBからこのデータを読み込んでクエリし、その結果得られたタイムスタンプを使ってMilvus内で対応するベクトルを検索することがほとんどでしょう。
vehicle_count_range = (20, 40)
平均速度範囲 = (10.0, 20.0)
df_test = generate_sensor_data("accident", "2024-09-26 12:00:00", vehicle_count_range, avg_speed_range, rows=30, seed = 1)
次に、このデータを先ほどと同じウィンドウ化と正規化の方法で変換する。
query_vector = vectorize_data(df_test).vectors.values
次のコマンドで、クエリーベクトルに対してベクトル検索を実行できる:
result = milvus_client.search(collection_name, query_vector, limit=3, output_fields=["vector", "anomaly_type"])
for hits in result:
for hit in hits:
print(f "hit: {hit}")
"""
出力する:
ヒット:{'id': 21, 'distance':0.04718003422021866, 'entity':{'anomaly_type': '事故'}}。
ヒット:{'id':41, 'distance':0.0641128420829773, 'entity':{'anomaly_type': '事故'}}。
ヒット:{'id':34, 'distance':0.06488440930843353, 'entity':{'anomaly_type': '事故'}}。
"""
見てわかるように、クエリに最も類似した上位3つのオブザベーションは、すべて "事故 "の異常タイプを持ち、これはクエリ・データで記録された低い平均速度を確認します。クエリ・データと上位3つの最も類似したオブザベーションの間のベクトル可視化を調べると、ベクトル値の範囲が互いに類似していることに気づきます。
クエリ・ベクトルと上位3つの最も類似したベクトルとの比較](https://assets.zilliz.com/Comparison_between_query_vector_and_top_three_most_similar_vectors_9ed17bd7cb.png)
結論
この記事では、モノのインターネット(IoT)アプリケーションにおけるユースケースを中心に、時系列データベースとベクトルデータベースの組み合わせについて検討した。InfluxDBのような時系列データベースは、気象予測、株式市場分析、センサーモニタリングのようなアプリケーションにとって重要な時系列データの保存とクエリにおいて非常に効率的である。しかし、類似検索の実行に関しては限界がある。
これを克服するために、我々は時系列データベースとMilvusのようなベクトルデータベースを組み合わせた。Milvusはベクトル形式でデータを格納し、余弦類似度やユークリッド距離のような技術を用いて効率的な類似性検索を可能にする。2つのデータベースを組み合わせることで、両システムの長所をフルに活用することができる。上の例でわかるように、センサーからの時系列データはInfluxDBに、ベクトルデータはMilvusに保存することができる。この統合により、リアルタイムの交通状況における異常検知のような高度なユースケースが可能になる。
この記事で紹介したMilvusに関連するコードは、 このColab notebook からアクセスできる。
また、この記事では、時系列データを予測タスクに適したエンベッディングに変換するための前処理方法を探求している。

読み続けて

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.