




Milvus、QwQ-32B、OllamaでRAGを構築する方法
AIモデルは急速に進化しており、AlibabaのQwQ-32Bが最近、力強く登場しています。わずか320億のパラメータで、この中規模の推論モデルは、数学的推論、クリエイティブライティング、コード生成において印象的な性能を発揮し、DeepSeek-R1のようなはるかに大規模なモデルに匹敵します。ベンチマーク全体での効率性と精度により、幅広いAIアプリケーションにとって魅力的な選択肢となっています。
 11.jpeg
11.jpeg
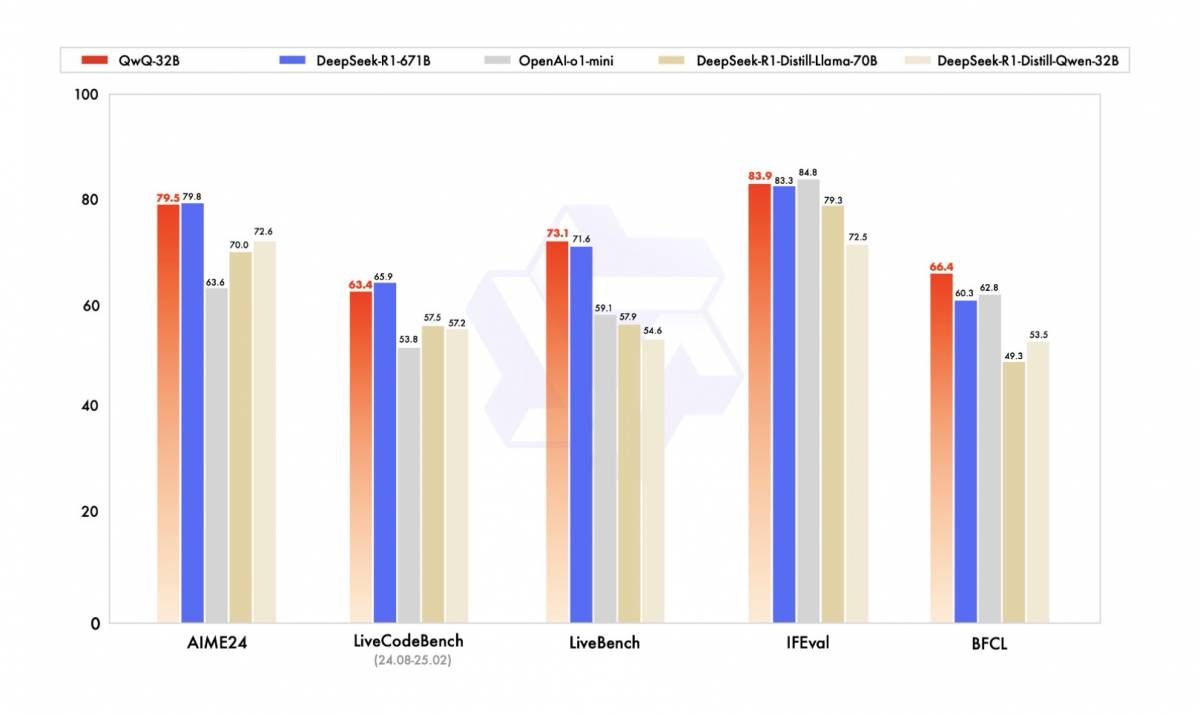
図 1: 他の主要モデルと比較したQwQ-32Bの性能(出典)
その能力に加えて、QwQ-32Bはアクセスのしやすさでも際立っています。特殊なハードウェアを必要とする一部の巨大モデルとは異なり、RTX 4090のようなコンシューマー向けGPU上で効率的に動作するため、エンタープライズ規模のリソースなしで高品質なAIを求める開発者や研究者にとって優れた選択肢です。ただし、密なモデルであるQwQ-32Bは、長文における複雑な推論で苦戦することがあり、特に拡張されたコンテキストウィンドウを扱う際にはハルシネーションを示す場合があります。
これらの課題を緩和し、信頼性を高めるために、QwQ-32BをRetrieval-Augmented Generation(RAG)と統合できます。このチュートリアルでは、QwQ-32B、Milvus(高性能ベクトルデータベース)、Ollamaを使用してRAGシステムを構築する方法を順を追って説明します。最後まで進めると、効率性、精度、スケーラビリティのバランスが取れた、合理化された強力なAIパイプラインを手に入れることができます。
RAGアプリケーションの構築方法の詳細に入る前に、このチュートリアルで使用するすべてのテクノロジーを簡単に確認しましょう。
QwQ-32B vs. DeepSeek-R1
QwQ-32BとDeepSeek-R1はいずれも推論に特化していますが、後者はMixture-of-Experts (MoE)アーキテクチャを採用している一方、QwQ-32Bは古典的な密なモデルです。
- MoEモデルは、知識集約型のシナリオ(例:Q&Aシステム、情報検索)や大規模データ処理に優れており、異なるエキスパートが別々のデータサブセットを処理することで効率を向上させます。ただし、その膨大なパラメータ数のため、クラウドまたは専用サーバーのリソースが必要です。
- 密なモデルは、計算負荷は高いものの、深く一貫した推論タスク(例:複雑な論理推論、詳細な読解)や、リアルタイム性能が必須ではないアルゴリズム設計により適しています。そのコンパクトなサイズによりローカルデプロイが可能ですが、時として冗長で不要なメッセージを生成する場合があります。
| 密なモデル (QwQ-32B) | MoEモデル (DeepSeek-R1) | |
|---|---|---|
| 利点 | トレーニングの複雑さが低い;プロセスが単純 | 高い計算効率(推論時に一部のエキスパートを有効化) |
| 利点 | 一貫した推論;文脈理解のためにすべてのニューロンが関与 | エキスパートの拡張によるスケーラブルなモデル容量 |
| 欠点 | トレーニングと推論の計算コストが高い | 複雑なトレーニング(ゲーティングネットワークとエキスパートの負荷分散が必要) |
| 欠点 | スケーラビリティが限定的;過学習しやすい;ストレージ/デプロイコストが高い | ルーティングのオーバーヘッド(ゲーティング判断のための追加計算) |
どちらのアーキテクチャも完璧ではありません。選択は、タスク要件、データ特性、利用可能な計算リソース、予算制約に応じて決めるべきです。
近い将来、ハイブリッドなアプローチが検討されるようになると考えています。初期の知識検索と粗い処理にはMoEを使用し、その後、深い推論と精緻化にはdense modelsを使用することで、より優れたパフォーマンスを達成するというものです。
Milvusを選ぶ理由
Milvusは、オープンソースで高性能かつ高いスケーラビリティを備えたvector databaseであり、高次元のvector embeddingsを通じて、10億規模のunstructured dataを保存、インデックス化、検索できます。retrieval augmented generation(RAG)、セマンティック検索、マルチモーダル検索、レコメンデーションシステムなどの最新のAIアプリケーションの構築に最適です。
QwQ-32Bで起こり得るハルシネーション(実際にはLLMで起こり得るもの)を軽減するために、Milvusは外部またはプライベートな知識を保存し、QwQ-32Bモデルにコンテキスト情報を提供します。これにより、QwQ-32Bモデルはより正確な結果を生成できます。
Ollamaを選ぶ理由
Ollamaは、large language models (LLMs)のローカルでのデプロイと管理を簡素化するオープンソースプラットフォームです。ユーザーフレンドリーでクラウド不要の体験を提供し、高度な技術スキルを必要とせずに、モデルのダウンロード、インストール、操作を簡単に行えるようにします。シンプルなコマンドラインツールやDocker統合を通じてモデルを迅速にデプロイでき、Modelfile管理をサポートしてバージョン管理とモデルの再利用を効率化します。
さらに、Ollamaは汎用からドメイン特化型まで、豊富なモデルライブラリを提供します。macOS、Linux、Windows、Dockerコンテナデプロイをサポートするクロスプラットフォームおよびハードウェア互換性を備え、自動GPU検出と高速化の優先利用に対応しています。また、REST APIやPython SDKなどの開発者向けツールも提供し、さまざまなアプリケーションへのモデル統合を容易にします。
そして、データプライバシーと柔軟性を確保し、ユーザーが自分のマシン上でAI駆動のソリューションを完全にファインチューニング、最適化、デプロイできるようにします。
それでは、言語モデルとしてQwQ-32B、vector databaseとしてMilvus、フレームワークとしてOllamaを使用して、シンプルなRAGパイプラインの構築を始めましょう。
準備
依存関係と環境
! pip install pymilvus ollama
注: Googleを使用している場合、インストールしたばかりの依存関係を有効にするには、ランタイムを再起動する必要がある場合があります(画面上部の「Runtime」メニューをクリックし、ドロップダウンメニューから「Restart session」を選択します)。
データの準備
RAGのプライベート知識として、Milvus Documentation 2.4.xのFAQページを使用します。これはシンプルなRAGパイプラインに適したデータソースです。
zipファイルをダウンロードし、ドキュメントをmilvus_docsフォルダーに展開します。
! wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
! unzip -q milvus_docs_2.4.x_en.zip -d milvus_docs
milvus_docs/en/faqフォルダーからすべてのmarkdownファイルを読み込みます。各ドキュメントについては、ファイル内のコンテンツを分割するために単純に「# 」を使用します。これにより、markdownファイルの各主要部分のコンテンツをおおまかに分けることができます。
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")
LLMとEmbedding Modelの準備
Ollama は、LLM ベースのタスクと埋め込み生成の両方で複数のモデルをサポートしているため、RAG アプリケーションを簡単に開発できます。このセットアップでは:
- テキスト生成タスク用の LLM として QwQ (32B) を使用します。
- 埋め込み生成には、意味的類似性に最適化された 334M パラメータのモデルである mxbai-embed-large を使用します。
開始する前に、両方のモデルがローカルにプルされていることを確認してください:
! ollama pull mxbai-embed-large
! ollama pull qwq
これらのモデルの準備ができたら、LLM 駆動の生成と埋め込みベースの検索ワークフローの実装に進めます。
import ollama
from ollama import Client
ollama_client = Client(host="http://localhost:11434")
def emb_text(text):
response = ollama_client.embeddings(model="mxbai-embed-large", prompt=text)
return response["embedding"]
テスト用の埋め込みを生成し、その次元数と最初のいくつかの要素を出力します。
test_embedding = emb_text("This is a test")
embedding_dim = len(test_embedding)
print(embedding_dim)
print(test_embedding[:10])
1024
[0.23217937350273132, 0.42540550231933594, 0.19742339849472046, 0.4618139863014221, -0.46017369627952576, -0.14087969064712524, -0.18214142322540283, -0.07724273949861526, 0.40015509724617004, 0.8331164121627808]
Milvus にデータをロードする
Collection を作成する
from pymilvus import MilvusClient
milvus_client = MilvusClient(uri="./milvus_demo.db")
collection_name = "my_rag_collection"
MilvusClient パラメータの設定について:
uriをローカルファイル(例:./milvus.db)として設定するのが最も便利な方法です。これは自動的に Milvus Lite を利用して、このファイルにすべてのデータを保存します。- データ規模が大きい場合は、docker or kubernetes 上に、より高性能な Milvus サーバーをセットアップできます。このセットアップでは、サーバーの
uri(例:http://localhost:19530)をuriとして使用してください。 - Milvus のフルマネージドクラウドサービスである Zilliz Cloud を使用したい場合は、Zilliz Cloud の Public Endpoint and Api key に対応する
uriとtokenを調整してください。
Collection が既に存在するかを確認し、存在する場合は削除します。
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
指定したパラメータで新しい Collection を作成します。
フィールド情報を指定しない場合、Milvus は主キー用のデフォルトの id フィールドと、ベクトルデータを保存するための vector フィールドを自動的に作成します。予約済みの JSON フィールドは、スキーマで定義されていないフィールドとその値を保存するために使用されます。
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
metric_type="IP", # Inner product distance
consistency_level="Strong", # Strong consistency level
)
データを挿入する
テキスト行を反復処理し、埋め込みを作成してから、そのデータを Milvus に挿入します。
ここには新しいフィールド text があります。これは Collection スキーマで定義されていないフィールドです。これは予約済みの JSON 動的フィールドに自動的に追加され、高レベルでは通常のフィールドとして扱うことができます。
from tqdm import tqdm
data = []
for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
data.append({"id": i, "vector": emb_text(line), "text": line})
milvus_client.insert(collection_name=collection_name, data=data)
Creating embeddings: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 72/72 [00:06<00:00, 11.86it/s]
{'insert_count': 72, 'ids': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71], 'cost': 0}
RAG パイプラインを構築する
クエリのデータを取得する
Milvus に関するよくある質問を指定してみましょう。
question = "How is data stored in milvus?"
コレクション内でその質問を検索し、セマンティックな上位3件の一致を取得します。
search_res = milvus_client.search(
collection_name=collection_name,
data=[
emb_text(question)
], # Use the `emb_text` function to convert the question to an embedding vector
limit=3, # Return top 3 results
search_params={"metric_type": "IP", "params": {}}, # Inner product distance
output_fields=["text"], # Return the text field
)
クエリの検索結果を見てみましょう。
import json
retrieved_lines_with_distances = [
(res["entity"]["text"], res["distance"]) for res in search_res[0]
]
print(json.dumps(retrieved_lines_with_distances, indent=4))
[
[
" Where does Milvus store data?\n\nMilvus deals with two types of data, inserted data and metadata. \n\nInserted data, including vector data, scalar data, and collection-specific schema, are stored in persistent storage as incremental log. Milvus supports multiple object storage backends, including [MinIO](https://min.io/), [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls), [Google Cloud Storage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes) (GCS), [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs), [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service), and [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS).\n\nMetadata are generated within Milvus. Each Milvus module has its own metadata that are stored in etcd.\n\n###",
231.9922637939453
],
[
"How does Milvus flush data?\n\nMilvus returns success when inserted data are loaded to the message queue. However, the data are not yet flushed to the disk. Then Milvus' data node writes the data in the message queue to persistent storage as incremental logs. If `flush()` is called, the data node is forced to write all data in the message queue to persistent storage immediately.\n\n###",
226.54090881347656
],
[
"What is the maximum dataset size Milvus can handle?\n\n \nTheoretically, the maximum dataset size Milvus can handle is determined by the hardware it is run on, specifically system memory and storage:\n\n- Milvus loads all specified collections and partitions into memory before running queries. Therefore, memory size determines the maximum amount of data Milvus can query.\n- When new entities and and collection-related schema (currently only MinIO is supported for data persistence) are added to Milvus, system storage determines the maximum allowable size of inserted data.\n\n###",
210.63682556152344
]
]
LLM を使用して RAG レスポンスを取得する
取得したドキュメントを文字列形式に変換します。
context = "\n".join(
[line_with_distance[0] for line_with_distance in retrieved_lines_with_distances]
)
LLM のシステムプロンプトとユーザープロンプトを定義します。このプロンプトは、Milvus から取得したドキュメントを使って組み立てられます。
SYSTEM_PROMPT = """
Human: You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided.
"""
USER_PROMPT = f"""
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
Ollama が提供する QwQ (32B) モデルを使用して、プロンプトに基づくレスポンスを生成します。
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = ollama_client.chat(
model="qwq",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
],
)
print(response["message"]["content"])
<think>
さて、提供されたコンテキストを使って「How is data stored in Milvus?」という質問に答える必要があります。まず、コンテキストを注意深く読んでみます。
まず、「Where does Milvus store data?」というタイトルの最初のコンテキストセクションを見ると、Milvus は挿入データとメタデータの2種類のデータを扱うと書かれています。
挿入データにはベクトル、スカラーデータ、コレクションスキーマが含まれ、永続ストレージに増分ログとして保存されます。サポートされているバックエンドとして MinIO、S3、GCS などが列挙されています。したがって、挿入データは増分ログを介してこれらのオブジェクトストレージに保存されることを記載すべきです。
次に、メタデータは各 Milvus モジュール用に etcd に保存されます。これは明快で、メタデータは etcd に保存されます。
データのフラッシュに関する2番目のコンテキストでは、データはまずメッセージキューに入り、フラッシュ時に永続ストレージに移されると説明されています。ただし、これは保存場所というよりプロセスに関する内容なので、永続ログとして書き出される前に、挿入はまずメッセージキューに入ることを述べるとよさそうです。
最大データセットサイズに関する3番目のセクションでは、ハードウェア制約について触れています。クエリ可能なデータにはメモリ、永続化にはストレージが必要です。これは、メモリとディスクの観点でデータがどのように管理されるかに関連する可能性があります。ユーザーは「どのようにデータが保存されるか」を尋ねているので、保存場所(オブジェクトストア、etcd など)とプロセス(メッセージキュー、その後永続ログ)の両方を含めるとよいでしょう。
まとめると、回答では以下に言及すべきです。
- 2種類:挿入データとメタデータ。
挿入データについて:
- MinIO、S3 などのバックエンドを使用して、永続ストレージに増分ログとして保存される。
- 最初にメッセージキューにロードされ、その後ディスクに書き込まれる。必要に応じて flush() が即時書き込みを強制する。
メタデータ:
- 各モジュール用に etcd に保存される。
また、ハードウェアの部分では、メモリがクエリ可能なデータサイズを制限し、ストレージ(オブジェクトストアなど)が総データセットサイズを制限すると述べています。したがって、容量制約を考慮したデータ保存の一部として、これらの要素にも触れるとよいでしょう。
これを明確に構成し、挿入データとメタデータに関する箇条書きまたはセクション、その後にフラッシュなどのプロセス、最後にハードウェアに基づく制限を示すのがよさそうです。
</think>
Milvus のデータは主に2つの方法で保存されます。
1. **挿入データ**:
- ベクトルデータ、スカラーデータ、コレクションスキーマを含みます。
- MinIO、AWS S3、Google Cloud Storage (GCS)、Azure Blob Storage、Alibaba Cloud OSS、Tencent Cloud Object Storage (COS) などのオブジェクトストレージバックエンドでサポートされる **永続ストレージ** に、**増分ログ** として保存されます。
- 挿入時には最初に **メッセージキュー** にロードされます。Milvus はキューへの挿入が完了した時点で成功を返しますが、すぐにディスクへ書き込むわけではありません。バックグラウンドプロセスが後でこのデータを永続ストレージに書き込みます。`flush()` メソッドを使用すると、キュー内のすべてのデータをストレージへ即時に書き込むことができます。
2. **メタデータ**:
- Milvus モジュールによって内部的に生成されます(例:コレクション設定、パーティション)。
- 分散キー・バリューストアである **etcd** に保存されます。
**ハードウェアに関する考慮事項**:
- **メモリ**: Milvus がクエリできるデータ量は、クエリのために指定されたコレクション/パーティションをメモリにロードするため、システムメモリによって制限されます。
- **ストレージ容量**: 最大データセットサイズは、すべての挿入データとスキーマを増分的に保存する基盤となるストレージバックエンド(例:オブジェクトストレージ)によって制約されます。
素晴らしいです!Milvus、QWQ-32B、Ollama を使って RAG パイプラインを正常に構築できました。
結論
これらの技術を統合することで、効率的なデータ保存と検索に Milvus を活用し、QwQ-32B の推論能力によって正確で文脈に即した応答を生成する RAG システムを構築できます。Ollama はデプロイプロセスを簡素化し、シームレスで効率的なセットアップを可能にします。この組み合わせは、AI 支援型チュータリング、論理ベースの問題解決など、リアルタイムの情報検索と生成を必要とするアプリケーションに特に有益です。
このチュートリアルに従うことで、ニーズに合わせたRAGシステムを作成し、ご自身の制作物から真に恩恵を受けられることを願っています。

読み続けて

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.