




レポート機能付きLangChain RAGエージェントの構築方法
AIエージェントを検索拡張世代アプリケーションで本番稼動させる上で最も重要なことの1つは、AIエージェントが水面下で何を行っているかを監視することである。Arize、TruEra、Portkeyなど多くの監視ツールが市販されています。この例では、LangChain、Milvus、OpenAIを使ってAI Agentを作成します。そして、トークンの使用量、トークン数、リクエストレイテンシを監視するためにPortkeyを使用します。AIエージェントのクックブック](https://github.com/ytang07/ai_agents_cookbooks)のコードはGitHubのレポにあります。
技術スタックの紹介
コードに入る前に、この技術スタックの構成要素について簡単に説明しましょう。このチュートリアルでは、4つの主要な技術を使います:LangChainは検索拡張生成アプリのオーケストレーションに、Milvusはベクトル・データベースとして、関連する情報を保存し、お気に入りの大規模言語モデル(LLM)に送信するために、Portkeyはシステムのモニタリングに、そしてOpenAIはLLMに使用します。
ラングチェーン
LangChainは、2024年5月現在、最も人気のあるオープンソースのLLMオーケストレーションフレームワークです。検索拡張生成のために市場に出回っている多くのフレームワークの一つである。LangChainの専門は連鎖である。特に、大規模な言語モデル(LLMsや他の関連機能の入力(または関連データ)と出力を組み立てるのに適している。人気のある3つのフレームワークの違いについては、LangChain vs. LlamaIndex vs. Haystackの記事を参照してください。
Milvus
Milvusは最も人気のあるオープンソースで唯一の分散ベクトルデータベースであり、検索拡張世代アプリケーションを構築する際に複数のデータソースを保存するためによく使用されます。Milvusは、他のベクターデータベースと比較して、スケーラビリティ、柔軟性、エンタープライズ対応機能の点で特に優れたベクター類似検索を実行します。このチュートリアルでは、Docker Compose経由でMilvusを実行します。
ポートキー
Portkeyは、2024年5月に最も人気のあるオープンソースのLLM Gatewayを取り上げました。これは LLM アプリケーションのための多くの監視ソリューションの一つです。Portkey は、そのゲートウェイを経由してコールをルーティングすることで、モニタリングを提供する。通話のコスト、トークン数、レイテンシを監視します。Portkeyはまた、GPTCacheに似たセマンティックキャッシュのような補助ツールを設定することもできます。
OpenAI
OpenAIはChatGPTを通じてLLMを一般に知らしめた。それ以来、彼らはGPTのいくつかの異なるバージョンをリリースし、Mistral、Meta AIなどの多くの競合他社に市場への参入を促した。
LangChain RAGエージェントの構築
主要な技術がわかったところで、LangChain Retrieval Augmented Generation (RAG) を構築してみましょう。エージェントを作りましょう。以下の行はPythonノートブックセルで実行することもできますし、先頭に!を付けずにターミナルで直接実行することもできます。5つの必須ライブラリと、オプションの6つ目のライブラリが必要です。
必要なライブラリは以下の5つです:
- pymilvus`(Milvusアクション用
- langchain` - LangChain用
- langchain-community` - Milvus + LangChain統合を含むコミュニティ統合用
- langchain-openai`: OpenAI + LangChain ライブラリ。
- データのロードを支援する
unstructured
6番目のオプションライブラリは langchainhub です。このライブラリを使ってLangChain hubからエージェントのプロンプトにアクセスする。番目のコマンド `docker compose up-d' はMilvusを実行するためのDocker composeファイルを実行する。
pip install --upgrade --quiet pymilvus langchain langchain-community langchainhub langchain-openai unstructured
docker-compose up -d
セットアップ
RAGエージェントを構築する最初の部分は簡単です。ここで行うことは、環境変数をロードし、多くのインポートを行うだけです。必要な環境変数はPortkey APIキーとOpenAI APIキーの2つです。ローカルでホストする場合は、Portkeyキーは不要です。
from dotenv import load_dotenv
import os
load_dotenv()
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]。
PORTKEY_API_KEY = os.environ["PORTKEY_API_KEY"]。
インポートを2つに分けてみる:LangChain関連とPortkey関連に分ける。LangChainからのインポートは9つ必要だ。必要なのは
- 指定したディレクトリからデータをロードするDirectoryLoader
- ドキュメント内のテキストを分割するRecursiveCharacterTextSplitter
- Milvusに接続するためのMilvus
- 埋め込みベクトルを作成するためのOpenAIEmbeddings
- hub`はプロンプトを取得するLangChainハブである。
- create_retriever_tool`はデータを取得するツールを作成する。
- ChatOpenAI は GPT をチャットのエンドポイントとして使うためのものである。
- エージェントを実行する AgentExecutor
そして
- create_openai_tools_agent`は tools と OpenAI エンドポイントからエージェントを作成します。
Portkeyを管理するために3つのインポートが必要です。PortkeyゲートウェイのURL、ヘッダーを作成する関数、そして各実行を追跡するためのUUIDライブラリです。
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Milvus
from langchain_openai import OpenAIEmbeddings
from langchain import hub
from langchain.tools.retriever import create_retriever_tool
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_tools_agent
from portkey_ai import PORTKEY_GATEWAY_URL, createHeaders
インポート uuid
ドキュメントをMilvusに取り込む
RAGエージェントを作成する最初のステップは、データソース(この場合はドキュメント)をMilvusに送信することです。まず、テキストスプリッタを定義します。この例では、チャンクサイズとチャンクのオーバーラップを定義します。この2つの概念は、巨大なドキュメントを適度な大きさのチャンクに分割するためのものです。オーバーラップは文脈情報の検索と連続性を考慮するのに役立つ。
テキストスプリッタの準備ができたら、ディレクトリを読み込み、テキストスプリッタを使ってLangChain文書に分割します。次に埋め込み関数を定義します。この場合はOpenAIEmbeddings言語モデルを使います。ドキュメントと埋め込み関数の準備ができたので、Milvusに接続し、OpenAI embeddings関数でチャンクを読み込みます。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
loader = DirectoryLoader("../city_data")
docs = loader.load_and_split(text_splitter=text_splitter)
embeddings = OpenAIEmbeddings()
db = Milvus.from_documents(
docs、
embeddings、
connection_args={"host":"127.0.0.1", "port":"19530"})
RAG用レトリーバーツールの作成
RAG構築の第一段階は、ドキュメントをMilvusのようなベクターデータベースに取り込むことです。LangChainのようなフレームワークを使用する場合、次のステップは情報検索コンポーネントです。このオブジェクトは自動的に文字列を受け取り、ベクトル化し、ベクトルデータベースから関連する応答を検索します。
AIエージェントを作るのだから、リトリーバーをツールに変えなければならない。LangChainでレトリーバ・ツールを作るには、3つのパラメータが必要です:レトリーバ・モデルそのもの、ツールの名前、機能の説明です。
ここで、ツールのリストを作成し、このレトリーバー・ツールを追加します。このステップは後で重要になる。
retriever = db.as_retriever()
tool = create_retriever_tool(
retriever、
"search_cities"、
"多くの都市のウィキペディアのエントリーを検索し、抜粋を返す、
)
ツール = [ツール]
RAGエージェントのセットアップ
プロンプトを取得することからRAGエージェントのセットアップを開始する。プロンプトを作成するか、LangChainハブから直接プロンプトを取得します。LLMを取得する前に最後に作成しなければならないのは、Portkeyヘッダーです。
私たちはここでPortkeyを使用して、使用状況を監視し、レイテンシ、使用したトークン数、コストなど、LLM呼び出しの内部詳細をチェックします。Portkeyヘッダには、Portkey API Key、UUID、LLMプロバイダの名前(OpenAI)、Portkey configの4つが必要です。コンフィグファイルはどのような設定でも構いません。ユーザダッシュボード用にデフォルトの設定を作成することもできます。
次に、ChatOpenAI を使って LLM をインスタンス化します。OpenAI APIキー、PortkeyゲートウェイURL、Portkeyヘッダー、LLMの温度です。これらの準備ができたら、 create_openai_tools_agent を使ってエージェントを作成します。エージェントを作成するために必要なパラメータは、LLM、ツールリスト、プロンプトの3つだけです。
prompt = hub.pull("hwchase17/openai-tools-agent")
portkey_headers = createHeaders(
api_key=PORTKEY_API_KEY、
trace_id=uuid.uuid4()、
provider="openai"、
config="pc-basic-b390c9"
)
llm = ChatOpenAI(api_key=OPENAI_API_KEY, base_url=PORTKEY_GATEWAY_URL, default_headers=portkey_headers, temperature=0)
agent = create_openai_tools_agent(llm, tools, prompt)
RAG エージェントを試してみる
最後のステップは、エージェントのタスクを実行する関数を作成することです。よく考えると変な名前ですね。とにかく、エージェントのワークフローを実行する関数は2つのパラメータを取ります: ツールエージェントとツール自身です。
agent_executor = AgentExecutor(agent=agent, tools=tools)
エージェントの実行準備ができたので、入力でエージェントを呼び出すことができる。この例では、サンフランシスコの面積を求める。
result = agent_executor.invoke(
{
"input":"サンフランシスコの大きさは?"
}
)
このエージェントはサンフランシスコのウィキペディアのページで作成されたドキュメントから情報を取得することができる。サンフランシスコの大きさは46.9平方マイル(121平方キロメートル)であることがわかる。

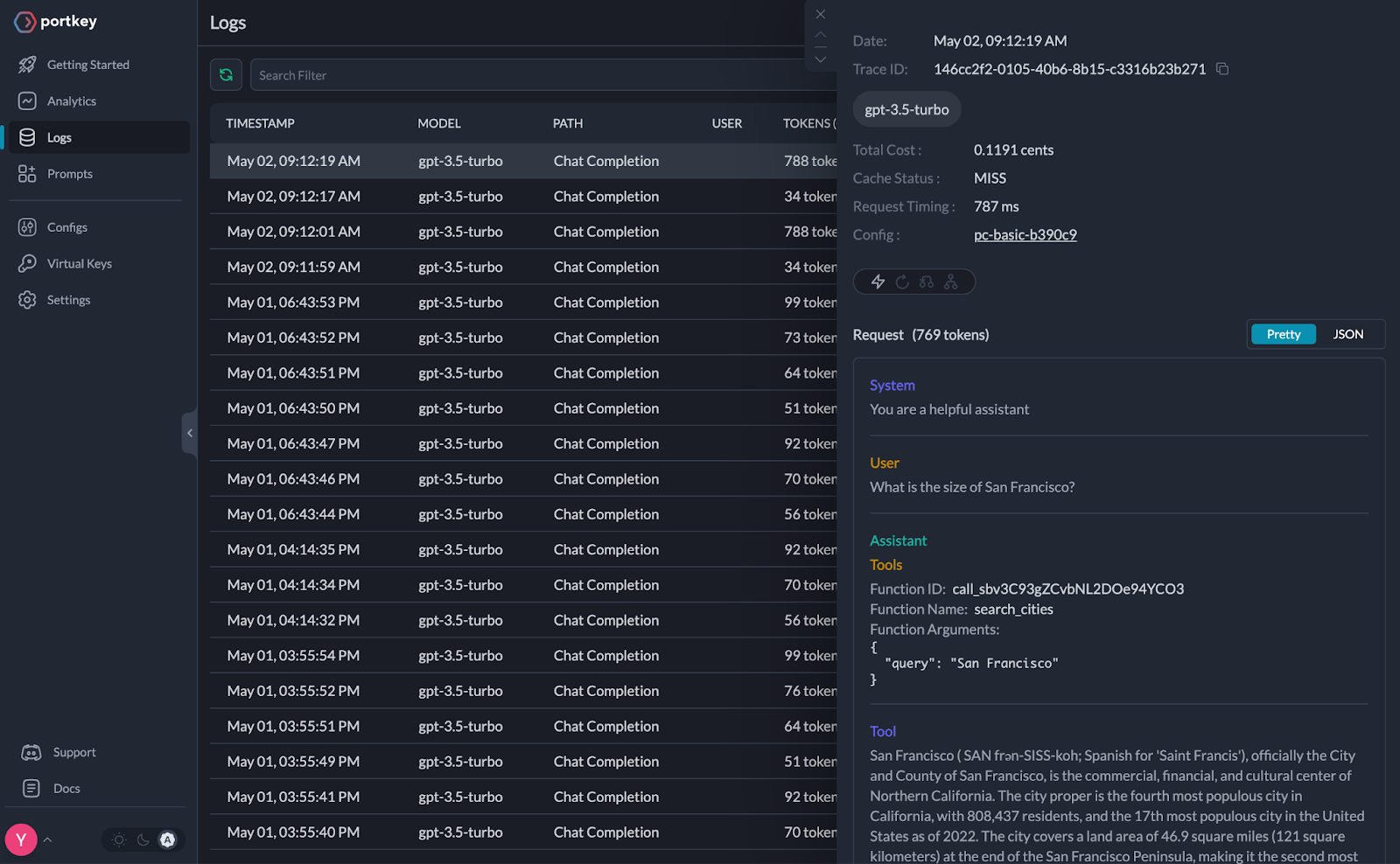
監視をチェックし、LangChain RAGエージェントがどのように動作しているかを確認するには、Portkeyのダッシュボードをチェックします。この特定のRAGエージェントの質問には0.1191セントかかり、787ミリ秒かかり、769トークンを使用したことがわかります。
LangChain RAGエージェントの構築まとめ
このチュートリアルでは、LangChainを使ってRAGを行うAIエージェントを構築する方法を学びました。AIエージェントに加えて、ゲートウェイを使ってエージェントのコスト、レイテンシ、トークン使用量を監視することができます。このチュートリアルで選んだゲートウェイはPortkeyです。
このLangChain RAGエージェントの構築、使用、監視には5つのステップがあります。まず、最も退屈なステップ、セットアップです。基本的なセットアップが完了したら、外部知識(ドキュメント)をMilvusにインポートし、効率的な検索のためのセマンティック検索を実行しました。そして、LangChain Milvusオブジェクトをリトリーバにし、そのリトリーバをリトリーバツールにしました。
もし検索の段階で止まっていたら、標準的なRAGの基礎ができていただろう。ツールを作ることで、その上にエージェントを構築することができる。ツールの準備ができたら、ゲートウェイ(Portkey)を経由するLLMを定義し、ツールにアクセスできるようにしました。次に、RAGエージェントに質問をし、回答を得ました。その結果、エージェントがどのようにLLMを実行し、レスポンスの詳細、コスト、レイテンシ、トークンの使用量などを知ることができました。
その他のLangchainリソース
- 究極のLangChain入門ガイド](https://zilliz.com/blog/langchain-ultimate-guide-getting-started)

読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.