




高効率なRAGパイプラインを構築するためのDSPyとMilvusとの統合を探る
#はじめに
大規模言語モデル(LLMs)は、変換可能な生成能力を持ち、知識ベースやリトリーバーなどのツールで補強され、チャットボットやエージェントのような高度なGenAIアプリケーションに燃料を供給している。LLMとの対話の中心はプロンプトであり、これはこれらのモデルが特定のタスクを実行するよう導く指示である。しかし、効果的なプロンプトを作成することは、ニュアンスが複雑なプロセスであり、しばしばChain-of-ThoughtやReActのような洗練された技術を必要とする。それに加えて、プロンプトはますます複雑になっている。さらに、GPT-4やGeminiのような異なるLLMでは、事前学習方法やデータセットが異なるため、同じプロンプトであっても結果が異なることがある。この課題により、プロンプトエンジニアリングへの関心が急速に高まっている。プロンプトエンジニアリングとは、より良い結果を得るためにプロンプトを調整し最適化することに焦点を当てた労力のかかる作業である。
手作業によるプロンプト作成は、単純なLLMアプリケーションでは問題なく機能するが、複数のコンポーネントを含む複雑なLLMベースのパイプラインでは、フラストレーションと時間のかかる作業となる。DSPyはDSPy モデルのプロンプトとウェイトのアルゴリズム的最適化を可能にするプログラム可能なインターフェースを導入することで、開発者が言語モデルと対話する方法のパラダイムシフトを提示し、より効率的な言語モデル開発に導きます。 DSPyはMilvusベクトルデータベースをシームレスに統合し、プログラム的アプローチを使用してRAG(RAG)アプリケーションの最適化を自動化します。
以下のセクションでは、DSPyのエッセンスとその運用の仕組みを探求し、DSPyとMilvusベクトルデータベースを使用したRAGアプリケーションの構築と最適化の方法を示す実践的な例を提供します。
DSPyとは?
DSPyは、スタンフォードNLPグループによって導入された、言語モデルのプロンプトとウェイトを最適化するために設計されたプログラムフレームワークであり、LLMが複数のパイプラインステージにわたって統合されている場合に特に有用である。Pythonic構文でLLMに指示するための、様々な構成可能で宣言的なモジュールを提供する。
プロンプトを手動で作成し、微調整することに依存する従来のプロンプトエンジニアリング技術とは異なり、DSPyはクエリ-アンサーの例を学習し、この学習を模倣して、よりカスタマイズされた結果を得るために最適化されたプロンプトを生成します。このアプローチにより、タスクのニュアンスに合わせてパイプライン全体を動的に組み直すことができるため、手動でプロンプトを調整する必要がなくなります。
キーコンセプトと基本コンポーネント
DSPyでは、シグネチャー、モジュール、オプティマイザー(以前はテレプロンプターと呼ばれていた)という3つの基本要素が、プロンプトの自動最適化とモデルの微調整のための中核となるビルディングブロックを形成しています。
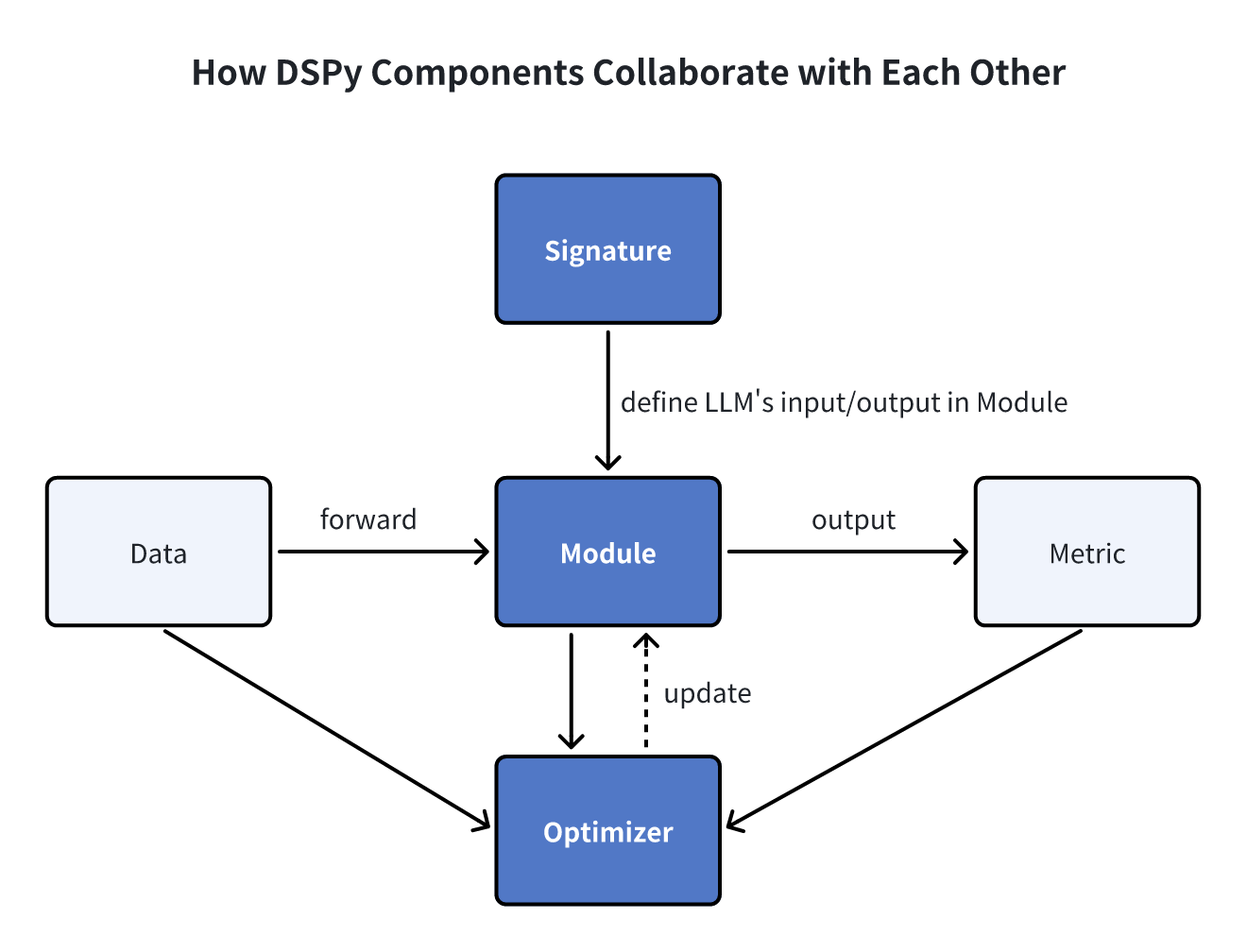
シグネチャ
シグネチャは、DSPyモジュールの入出力動作を定義する宣言的な仕様です。シグネチャは、言語モデルにどのようなプロンプトを出すかではなく、言語モデルがどのようなタスクを実行すべきかを指示します。
- シグネチャは3つの必須要素から構成される:
- 言語モデルが解決しようとするサブタスクの簡潔な記述。
- 言語モデルに与える1つ以上の入力フィールド(例:入力質問)の記述。
- 言語モデルに期待する1つ以上の出力フィールド(例:質問に対する答え)の記述。
一般的なLLMタスクのシグネチャの例を以下に示す:
- 質問応答:質問→答え
- センチメント分類:
"sentence -> sentiment" - 検索拡張質問応答:文脈、質問→回答
- 推論付き多肢選択問題:
"質問、選択肢 -> 推論、選択"。
これらのシグネチャは、DSPyが様々なモジュール内でLLMオペレーションを効率的にオーケストレーションするための指針となり、合理的で正確なタスク実行を促進する。
モジュール
DSPyモジュールは、LLMパイプライン内の従来のプロンプト技術を抽象化したものです。モジュールには3つの重要な特徴があります:
1.各ビルトインモジュールは、特定のプロンプト技法(Chain of ThoughtsやReActなど)を抽象化し、DSPyシグネチャを処理します。
2.DSPyモジュールは、プロンプトコンポーネントやLLMウェイトを含む学習可能なパラメータを持ち、入力を処理して出力を生成することができる。
3.DSPyモジュールは、より大きく複雑なモジュールを作成するために組み合わせることができます。
4.DSPyには、dspy.ReAct、dspy.ChainofThought、dspy.Predict、dspy.ProgramOfThought、dspy.ReAct、dspy.MultiChainComparison、dspy.Retrieveの7つの組み込みモジュールが用意されている。
オプティマイザ
DSPyオプティマイザ(以前のテレプロンプター)は、DSPyプログラムのパラメータ(プロンプトやLLMの重みなど)を微調整して、精度などの指定されたメトリクスを最大化するように設計されたアルゴリズムです。典型的なDSPyオプティマイザは3つの入力を必要とします:
あなたのDSPyプログラム**:単一のモジュール(例:
dspy.Predict)でも、複雑な複数モジュールプログラムでもかまいません。プログラムの出力を評価し、スコアを割り当てる関数です(スコアが高いほど良い結果を示します)。
学習入力の小さなセット**:多くの場合、わずか5~10例です。
学習データ、モジュール、および測定基準を定義すると、オプティマイザはLLMの重み、プロンプト命令、および数発のデモンストレーションを最適化し、プログラムの効率を高めます。例えば、BootstrapFewShotオプティマイザは指定されたメトリクスに沿った答えを生成し、COT (Chain of Thought)のようなモジュールは正確な答えを導き出すために構造化された推論を生成します。DSPyは、これらの成功したインスタンスとその根拠を、将来のテストクエリに対応するための数発デモとして記録する。
DSPyには、上記のコア・ビルディング・ブロックに加えて、データ、メトリクス、アサーションが補足コンポーネントとして組み込まれており、機能性と適応性を高めています。詳細はDSPy documentationを参照。
DSPyワークフロー:効率的なLLMパイプラインの構築
LLMパイプラインの構築において、DSPyは具体的にどのように機能するのでしょうか?わかりやすくするために、プロセスをいくつかの重要なステップに分けることができます。
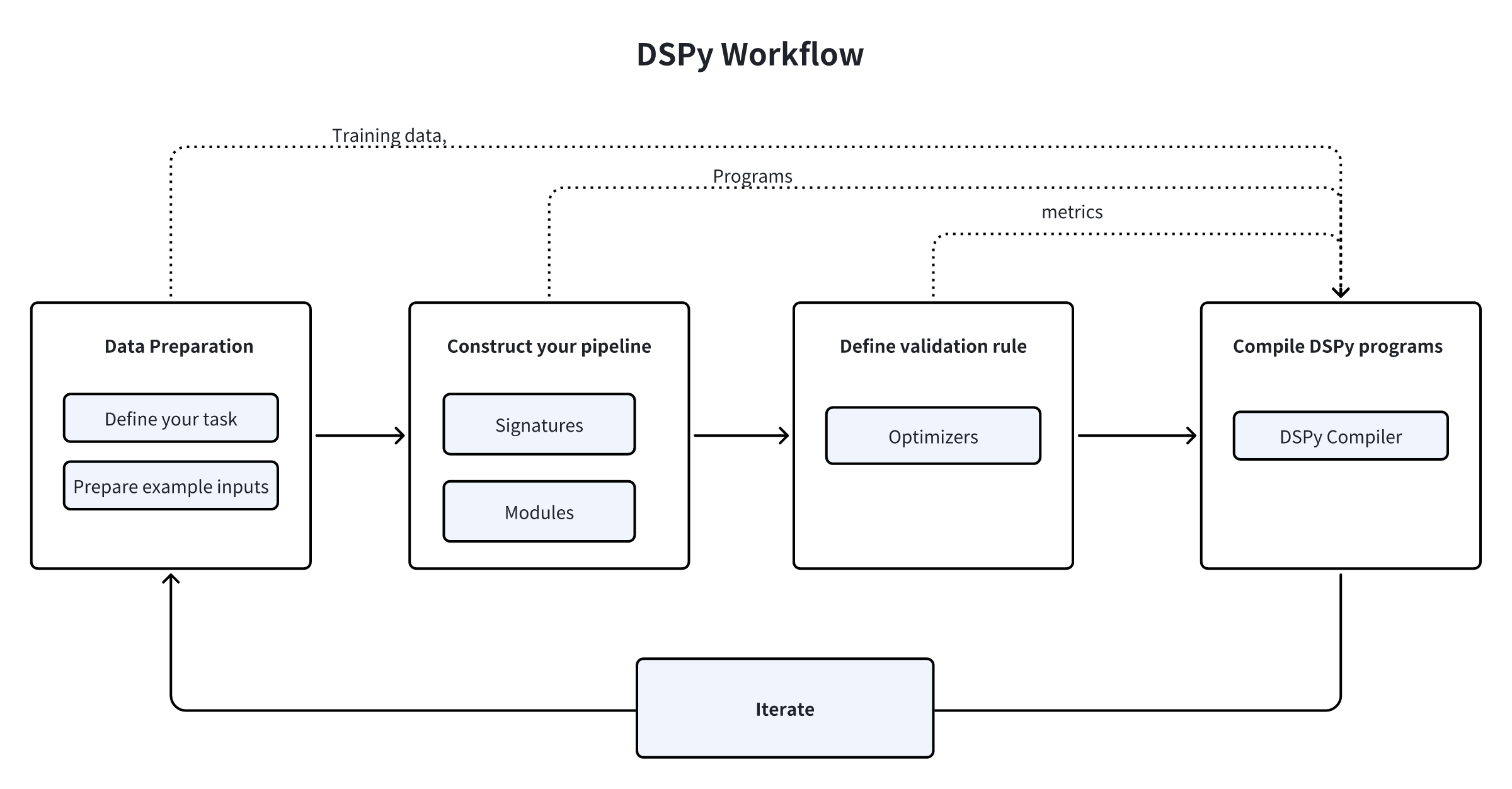
- まず、タスクを定義し、いくつかの入力例を用意する必要があります。多くの場合、ラベルなしです(または、最終出力にラベルが必要な場合は、ラベルのみ)。
- 第2に、組み込みモジュールから選択してパイプラインを構築し、各モジュールにシグネチャ(入出力仕様)を割り当て、これらのモジュールをPythonコードにシームレスに組み込みます。
- 第三に、プロンプトの品質と最終結果を評価するために使用するメトリクスや入力例など、パイプラインの検証ロジックを定義します。
- 第4に、DSPyオプティマイザを使用してコードをコンパイルします。このオプティマイザは、高品質の命令、自動的な数ショット例、または更新されたLLMウェイトを生成します。
- 最後に、データセット、プログラム、または検証ロジックを改良する反復プロセスに取り組み、パイプラインの望ましいパフォーマンスレベルを達成する。進化する要件を満たし、結果を最適化するために、継続的に評価と改善を行います。
DSPyとLlamaIndex/LangChain/AutoGPTの比較
DSPyは、LangChain、LlamaIndex、AutoGPTのような他の多くの一般的なAIフレームワークと比較して、そのアプローチが際立っています。ここでは、それらの違いと整合性について詳しく見ていこう:
LangChain**](https://zilliz.com/learn/LangChain)は、カスタマイズされたアプリケーションを作成するためのツールキットです。様々な言語モデルとユーティリティ・パッケージを活用することで、開発者は特定のニーズに合わせてアプリケーションをカスタマイズすることができる。
LlamaIndex**](https://zilliz.com/learn/getting-started-with-llamaindex#What-is-LlamaIndex)は、様々なプライベートデータソースと言語モデルの統合を効率化するために設計されたオーケストレーションフレームワークです。データ操作と処理タスクを簡素化する。
AutoGPT**](https://zilliz.com/blog/how-to-customize-auto-gpt-for-unique-use-case)は、GPT-4とGPT3.5を搭載した高度なAIエージェントです。事前に定義されたルールと目標に基づいて意思決定を行い、行動を起こすようにプログラムされている。自律性と意思決定能力を重視しています。
DSPyの特徴
- DSPyは、言語モデルとのインタラクションを強化するために、プロンプトの作成を最適化し、自動化する。
- LangChainやLlamaIndexのようなビルド済みのモジュールで高レベルのアプリケーション開発に対応するものとは異なり、DSPyはカスタムパイプライン内でLLMのプロンプトや微調整を学習できる強力で汎用的なモジュールを提供する。 DSPyの強みは、変化するデータ、プログラムの制御フロー調整、またはターゲット言語のバリエーションに基づいて、プロンプトを動的に適応させ、LLMを微調整する能力にあります。この自動化された最適化プロセスは、特に開発者がシンプルなプログラムやプロトタイピングのプログラムを、より洗練された本番用のプログラムへと拡張することに前向きな場合に、最小限の労力でより優れた品質の出力を導くことができます。
- DSPyは、LangChainやLlamaIndexのようなライブラリによって提供される定義済みのプロンプトや統合に依存するのではなく、軽量でありながら自動的に最適化されるプログラミングモデルを必要とするユースケースに最適です。
DSPyとMilvus Vector Databaseの統合
Milvusは、非常に柔軟で信頼性が高く、高速なクラウドネイティブのオープンソースベクターデータベースです。ベクトル類似検索を強化し、様々なGenAIや検索拡張世代(RAG)アプリケーションの構築に特に有益です。
Milvusは、MilvusRM Clientの形で検索モジュールとしてDSPyワークフローに統合されており、高速で効率的なRAGパイプラインの実装を容易にしています。
DSPyとMilvusによるRAGアプリケーションの構築
Retrieval Augmented Generation(RAG)は、LLMが外部の知識リポジトリにアクセスし、ユーザのクエリに関連するコンテキスト情報を検索し、洗練された応答を生成するための手法です。
このデモでは、回答生成にGPT-3.5(gpt-3.5-turbo)を使用したシンプルなRAGアプリケーションを構築する。RAGパイプラインの設定と最適化のために、MilvusRMとDSPyを通してベクトルストアとしてMilvusを使用します。
前提条件
RAGアプリをビルドする前に、MilvusRMクライアントとMilvusをインストールしてください。
- MilvusRMをインストールするには、以下のコードを実行してください。
pip install dspy-ai[milvus]
- Milvusをインストールします。詳しい手順はMilvus documentationを参照してください。
データセットのロード
この例では、複雑な質問と回答のペアを集めたHotPotQAをトレーニングデータセットとして使用します。HotPotQAクラスを通して読み込むことができます。
from dspy.datasets import HotPotQA
# データセットを読み込む
データセット = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
# DSPyに'question'フィールドが入力であることを伝えます。その他のフィールドはラベルやメタデータです。
trainset = [x.with_inputs('question') for x in dataset.train].
devset = [x.with_inputs('question') for x in dataset.dev].
データをMilvusベクトルデータベースにインポートする
ベクトル検索のためにコンテキスト情報をMilvusコレクションに取り込む。このコレクションには embedding フィールドと text フィールドが必要である。この場合、デフォルトのクエリ埋め込み関数としてOpenAIの text-embedding-3-small モデルを使用する。
インポートリクエスト
milvus_uri = "http://localhost:19530"
milvus_token = ""
from pymilvus import MilvusClient, DataType, Collection
from dspy.retrieve.milvus_rm import openai_embedding_function
client = MilvusClient(
uri=MILVUS_URI、
token=MILVUS_TOKEN
)
if 'dspy_example' not in client.list_collections():
client.create_collection(
コレクション名="dspy_example"、
overwrite= True、
dimension=1536、
primary_field_name="id"、
vector_field_name="embedding"、
id_type="int"、
metric_type="IP"、
max_length=65535、
enable_dynamic=True
)
text = requests.get('https://raw.githubusercontent.com/wxywb/dspy_dataset_sample/master/sample_data.txt').text
for idx, passage in enumerate(text.split('\n')):
if len(passage) == 0:
続ける
client.insert(collection_name="dspy_example", data = [{"id": idx , "embedding": openai_embedding_function(passage)[0], "text": passage}])
MilvusRMを定義する。
次にMilvusRMを定義する。
from dspy.retrieve.milvus_rm import MilvusRM
import os
インポート dspy
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
retriever_model = MilvusRM(
コレクション名="dspy_example"、
uri=MILVUS_URI、
token=MILVUS_TOKEN, # Milvus接続にトークンが必要ない場合は無視する。
embedding_function = openai_embedding_function
)
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
dspy.settings.configure(lm=turbo)
シグネチャのビルド
データをロードしたので、パイプラインのサブタスクのシグネチャを定義しよう。単純な入力questionと出力answerを識別することができるが、RAGパイプラインを構築しているので、Milvusからコンテキスト情報を取得する。そこで、シグネチャを context, question --> answer と定義する。
class GenerateAnswer(dspy.Signature):
"""短いファクトで質問に答える"""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="1~5語の間であることが多い")
contextフィールドとanswerフィールドには、モデルが何を受け取り、何を生成すべきかという明確なガイドラインを定義するために、短い説明を記述します。
パイプラインの構築
では、RAGパイプラインを定義してみよう。
class RAG(dspy.Module):
def __init__(self, rm):
super().__init__()
self.retrieve = rm
# このシグネチャは、COTモジュールに課せられたタスクを示す。
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
# 質問のコンテキストを取得するためにmilvus_rmを使用します。
コンテキスト = self.retrieve(question).passages
# COTモジュールは "コンテキスト、クエリ "を受け取り、"答え "を出力する。
予測 = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=[item.long_text for item in context], answer=prediction.answer)
パイプラインの実行と結果の取得
さて、このRAGパイプラインを構築した。試しに実行して結果を出してみよう。
rag = RAG(retriever_model)
print(rag("who write At My Window").answer)
# 結果
# タウンズ・ヴァン・ザント
定量的な結果をデータセットで評価することができます。
from dspy.evaluate.evaluate import Evaluate
from dspy.datasets import HotPotQA
evaluate_on_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=False, display_table=5)
メトリック = dspy.evaluate.answer_exact_match
score = evaluate_on_hotpotqa(rag, metric=metric)
print('rag:', score)
# 結果
# rag: 50.0
パイプラインの最適化
このプログラムを定義したら、次はコンパイルだ。このプロセスでは、各モジュール内のパラメータを更新してパフォーマンスを向上させる。コンパイルのプロセスは、3つの重要な要素に左右される:
- トレーニングセット:トレーニングセット:トレーニングデータセットから20の質問と回答の例をこのデモに利用する。
- 検証メトリック:単純な
validate_context_and_answerメトリックを確立する。このメトリックは予測された答えの正確さを検証し、検索されたコンテキストに答えが含まれていることを保証する。 - 特定のオプティマイザ(テレプロンプタ):DSPyのコンパイラには、プログラムを効果的に最適化するために設計された複数のテレプロンプターが組み込まれています。
from dspy.teleprompt import BootstrapFewShot
# 検証ロジック: 予測された答えが正しいかチェックする。
# また、取得されたコンテキストがその答えを含んでいることをチェックします。
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
answer_EMとanswer_PMを返す
# 基本的なテレプロンプターをセットアップし、RAGプログラムをコンパイルする。
teleprompter = BootstrapFewShot(metric=validate_context_and_answer)
# コンパイルする!
compiled_rag = teleprompter.compile(rag, trainet=trainset)
# これでcompiled_ragは最適化され、新しい質問に答える準備が整いました!
では、コンパイルされたRAGプログラムを評価してみましょう。
score = evaluate_on_hotpotqa(compiled_rag, metric=metric)
print(score)
print('compile_rag:', score)
# 結果
# compile_rag: 52.0
評価スコアは前回の50.0から52.0に上昇し、回答の質が向上していることがわかります。
要約
DSPyは、プログラマブルなインターフェイスにより、言語モデルのインタラクションを飛躍的に向上させ、モデルのプロンプトとウェイトのアルゴリズムによる自動最適化を容易にした。RAGの実装にDSPyを活用することで、様々な言語モデルやデータセットへの適応が容易になり、面倒な手作業の必要性が大幅に減少します。
さらにDSPyは、Milvusベクトルデータベースを統合することで、ワークフロー内にMilvusRM retrieverモジュールを導入します。この新しい統合により、開発者はRAGアプリケーション内で迅速な最適化とモデルパラメータ調整を自動化し、回答品質を向上させることができます。もっと詳しく知りたい方は、DSPyドキュメントのMilvusRMの詳細ガイドをご覧ください! ;
参考文献
DSPy GitHubページ:https://github.com/stanfordnlp/dspy
DSPyドキュメント:https://dspy-docs.vercel.app/quick-start/installation/
MilvusRM ガイド:https://dspy-docs.vercel.app/docs/deep-dive/retrieval_models_clients/MilvusRM
Milvus ドキュメンテーション:https://milvus.io/docs

読み続けて

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.