




レイ・データとミルバスによるRAGアプリケーションのためのスケール推論の組み込み
Retrieval Augmented Generation (RAG)は、エンタープライズGenerative AIで最も人気のあるユースケースの1つです。ほとんどのRAGチュートリアルは、埋め込みモデルと大規模言語モデル(LLM)推論の両方にOpenAI APIを使う方法を示しています。 特に開発プロセスにおいて、なぜお金を払って自分のデータにアクセスする必要があるのでしょうか? オープンソースを使えば、自分のデータにアクセスし、好きなだけ素早く反復することができます。
最も興味深い発見のひとつは、 レイ・データ データをベクトルに変換するエンベッディングの段階で、パフォーマンスが著しく向上したことです。
Ray Dataのようなツールでプールされたバッチ推論リクエストを使ってオープンソースのエンベッディングを実行することで、Pandasに比べてリソースと時間が節約されました。 Ray Dataは、16GBのRAMを搭載したMac M2ラップトップ上で4人のワーカーを使用した場合、60倍高速でした。
オープンソースのRAGスタック
新しいBGM-M3埋め込みモデル(1ラウンドで3種類のベクトルを生成:スパース、デンス、マルチベクトル)
高速な分散埋め込み推論のためのRayデータ
推論結果を一時的に保存するAWS S3
MilvusまたはZillizクラウドベクトルデータベース
Kaggle IMDBポスター](https://www.kaggle.com/datasets/yashgupta24/48000-movies-dataset)からダウンロードしたデータ例
オープンソースRAGスタック
BGM-M3 埋め込みモデル
BGE-M3エンベッディングモデルは、その "マルチ "な機能から愛称が付けられました:BGE-M3エンベッディングモデルは、その "マルチ "機能(マルチリンガル、マルチファンクショナリティ、マルチグラニュラリティ)にちなんで命名されました。BGE-M3は100以上の言語を扱うことができ、3つの一般的な検索手法である密埋め込み、疎埋め込み、多ベクトル埋め込みを同時に計算することができます。また、短い文章から長い文書(最大8,192トークン)まで、様々な長さのテキストを扱うことができます。詳しくは、こちらのPaperや、こちらの modelに関するHuggingFaceのページをご覧ください。
バージョン2.4以降、MilvusはBGE M3をビルトインサポートしています。
レイデータ
長時間のデータ変換タスク
Ray Dataのスケーラブルなデータ処理は、複数のマシン(CPU、GPUなど)にまたがる大量のデータの並列処理をより簡単かつ高速にします。Ray Dataは、多くのチャンキンやエンベッディング変換を同時に行うような、データを並列処理に分割できる場合に特に役立ちます!Ray Dataには強力なストリーミング実行エンジンがあり、クラスタのGPU利用率を最大化します。オンラインサービス(OpenAIのエンベッディングAPIなど)でエンベッディングを実行するのに比べ、Ray Dataでオフラインのエンベッディングジョブを実行すると、コストの大部分を節約できます。
Anyscaleは、Rayのマネージドプラットフォームです。Anyscale上でエンベッディングジョブを簡単にスケールアウトし、数百のGPUマシンを活用することができます。
MilvusとZilliz
電光石火のRAGアプリの秘密のソースは、強力なベクトルデータベースです!_ Milvusは、企業が大規模に使用する大量のデータを処理するために構築されています。 いくつかのベクターデータベースとは異なり、Milvusはデータニーズの増加に合わせて柔軟に拡張することができます。 Milvusは、クエリがリアルタイムで実行される前や実行中にオフラインの計算をスマートに行うため、RAGアプリを高速化することができます。さらに、Milvusには、データを安全に整理し(マルチテナンシーとロールベースのアクセス制御)、常に利用可能な状態に保つ(高可用性)といった、ビジネスにとって重要な機能も備わっています。
Zilliz**はマネージドクラウド製品で、オープンソースのMilvusを使用している。
RAGツールのセットアップ
Milvus、Ray Data、Amazon S3、ZillizのPython SDKを使います。
Amazon S3については、AWSアカウントtにサインアップする必要があります。
ブラウザでconsole.aws.amazon.com > IAM > My security credentials > Create access keyに移動します。 キーとシークレットキーをコピーし、ローカルに安全に保存します。
ライブラリをインストールし、aws configを実行する。 これでAWSの変数がクレデンシャルファイルに格納される。
pip install boto3
pip install awscli -force-reinstall -upgrade
aws config #キーとシークレットキーを埋める
more ~/.aws/credentials #これが正しいか確認する
Ray Dataをインストールする:
pip install -U "ray[data]"
Pymilvusをインストールします:
pip install -U pymilvus "pymilvus[model]" langchain
BGE-M3エンベッディングモデルはv2.4からPymilvusに同梱されています。
import ray, os, pprint, time, boto3
from langchain.text_splitter import RecursiveCharacterTextSplitter
import numpy as np
import pymilvus
print(pymilvus.__version__) # >= 2.4.0でなければならない。
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
Zilliz free tier** (up to 2 collections, 100 million vectors each), sign up for an account and create a Starter cluster.
データの準備
このブログのコードでは、よく知られている公開されているKaggle IMDB poster dataを使用します。 このデータには、約48,000の映画、レビュー、ポスターリンク、その他のメタデータが含まれています。
私はすべてのテキストフィールド(映画名、説明、レビューテキスト)を'text'という新しいカラムにコピーし、CSVよりも効率的なので、Parquet形式で保存しました。
エンベッディングの生成
エンベッディングを作成する手順は以下の通りです:
- データをチャンクする:入力テキストをチャンク(塊)に分割し、意味的に関連するテキストをまとめる。
- 埋め込みモデルを推論モードで呼び出し、チャンクのベクトル表現を生成する。
Ray Dataは、これらのデータ処理を以下の方法で並列化できる: 1)1) flat_map() データをチャンキングする。 2)map_batches()は、呼び出し可能なClassメソッドの内部から埋め込みモデルを呼び出します。
チャンクサイズ = 512
chunk_overlap = np.round(chunk_size * 0.10, 0)
# LangChainテキストスプリッタを定義します。
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size、
chunk_overlap=chunk_overlap、
length_function=len) #lenはPython組み込み関数
# 1.チャンキングのための通常のPython関数を定義する。
def chunk_row(row, splitter=text_splitter):
# 行の列をメタデータにコピーします。
metadata = row.copy()
del metadata['text'] # メタデータからテキストを削除する。
# テキストをチャンクに分割する。
chunks = splitter.create_documents(
text=[row["text"]]、
metadatas=[metadata])
chunk_list = [{ }.
"text": chunk.page_content、
チャンク内のチャンクのための**チャンク.メタデータ}] 。
return chunk_list
# 2.埋め込みを計算する呼び出し可能なメソッドを持つクラスを定義する。
class ComputeEmbeddings:
def __init__(self):
# Milvus組み込みの疎密-遅延-相互作用-ランキングエンコーダを初期化する。
# https://huggingface.co/BAAI/bge-m3
self.model = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
print(f "dense_dim: {self.model.dim['dense']}")
print(f "sparse_dim: {self.model.dim['sparse']}")
def __call__(self, batch):
# バッチは辞書で、値は配列の値。
# BGEM3EmbeddingFunctionの入力は、文字列のリストとしてのdocsです。
docs = list(batch['text'])
# bge-m3 dense embeddingsは既に正規化されている。
embeddings = self.model(docs)
batch['vector_dense'] = embeddings['dense'].
バッチを返す
if __name__ == "__main__":
FILE_PATH = "s3://zilliz/kaggle_imdb.parquet"
# データをロードして変換する。
ds = ray.data.read_parquet(FILE_PATH)
# 入力テキストをチャンクする
chunked_ds = ds.flat_map(chunk_row)
# 埋め込みモデルを呼び出すクラスで埋め込みを計算する。
embeddings_ds = chunked_ds.map_batches(ComputeEmbeddings, concurrency=4)
# エンベッディングをS3に保存する。
embeddings_ds.write_parquet('s3://zilliz/kaggle_imdb_embeddings')
これを実行するには、Rayジョブとして投入します:
1.コードをPythonスクリプトファイルに保存します。 私はこれをray_data_demo.pyと名付けました。
2.ラップトップからローカルに実行するには、**クリーンディレクトリを作成し、.pyスクリプトファイルと.parquetデータファイルのみを置きます。 私は'ray_cluster'と名付けました。
3.**これでRayクラスタが起動し、自動的にジョブが投入されます。
4.http://127.0.0.1:8265`に移動する。 ClusterとJobsのタイミングを見る。
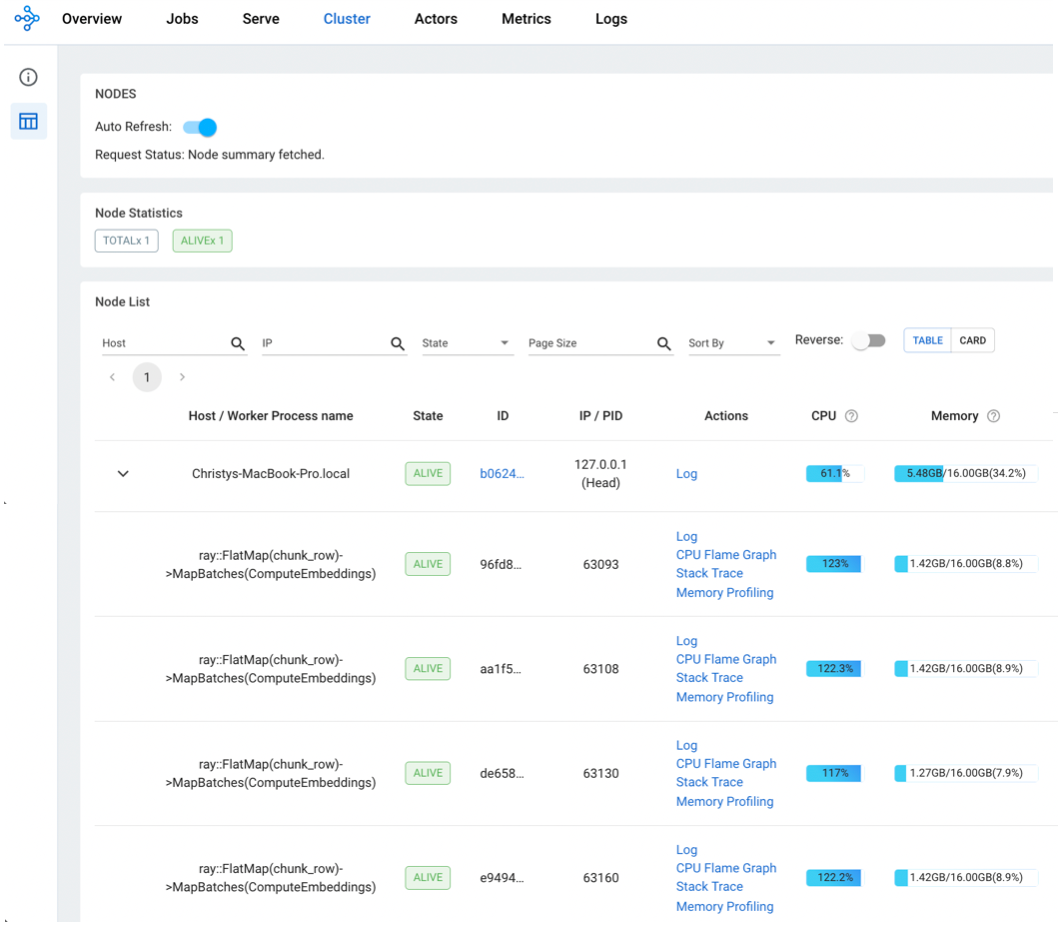
埋め込み遅延 - ラップトップで60倍速い
| アプローチ|入力データサイズ|総時間|スクリーンショット | ||||||||
パンダ|100行|23秒|

| ||||||||
レイデータ|100行|50秒|

| ||||||||
| パンダ | 45K行 | >4時間 |

| レイ・データ | 45K行 | >4時間 |
| |
| レイデータ | 45K行 | 4分 |

|
表M2 16GBノートパソコンでのデータ埋め込みタイミング。 Rayデータのバッチ処理はシングルノードのRayクラスタで行い、同時実行数は4ワーカーでした。 Pandasはプロセッサが1つしかなかったので遅かったが、Ray Dataはプロセッサが4つあった。 Pandasはプロセッサが1つしかなかったので遅かったが、Ray Dataは4プロセッサだった。
S3からMilvusまたはZillizに直接エンベデッドデータをバルクインサートする。
Milvusと[Zilliz]は、AWS, GCP, Azureから既に埋め込まれているデータを直接インポートするためのbulk-insertを提供しています。 Webコンソール](https://docs.zilliz.com/docs/import-data-on-web-ui)(下図)に加え、Zillizはrestful API and SDKも提供しています。
バッチ生成されたエンベッディングの大規模なコーパスの場合、バルクインポートを使用することで、インクリメンタル挿入と比較して、マシンリソースを大幅に節約し、挿入時間を短縮することができます。さらに重要なことに、バルクインポートによって構築されるベクトル検索インデックスは、インクリメンタル挿入によるインデックスよりもはるかに効率的です(大域的最適化v.s.局所的最適化を考えてみてください)。
Zilliz Cloudのウェブ・コンソールを数回クリックするだけで、簡単に一括インポートを行う方法を見てみましょう。 新しいコレクションを作成したいクラスタから始めて、AutoIDで新しいコレクションを作成し、正しいEMBEDDING_DIMENSIONで "vector"カラムのみを作成し、便利な "Dynamic Field"オプションを使用し、"Create Collection"をクリックします。
次に "Import Data"をクリックし、画面の指示に従ってRay Dataジョブが書き込んだパーケットファイルへのパスをコピーします。(S3バケットがプライベートの場合、アクセスキーとシークレットキーも指定する必要があります。)Amazon S3, Google Cloud Storage, Azure Blob Storageのいずれかのクラウドソースがサポートされています。 "インポート"をクリックして、ベクターデータベースコレクションへの全データのインポートを開始します。
インポートが完了したら、Query your dataステップでベクトル検索をより効率的にするために、オプションでコレクションにインデックスを構築するをクリックすることができます。

画像Zilliz一括挿入画面のスクリーンショット。
データを照会する
新しくインポートされたコレクションをテストするために、質問をしてムービーデータから答えを取得してみましょう。
def mc_run_search(question, output_fields, top_k=2, filter_expression=""):
# 同じエンコーダを使って質問を埋め込みます。
embeddings = model_bgem3([question])
query_embeddings = embeddings['dense'].
# クエリとベクトルデータベースを使って意味ベクトル検索を実行する。
results = mc.search(
コレクション名
data=query_embeddings、
search_params=SEARCH_PARAMS、
output_fields=output_fields、
# Milvusは検索をフィルタリングするためにブーリアン式のメタデータを利用することができます。
filter=filter_expression、
limit=top_k、
consistency_level="Eventually"
)
# 検索されたコンテキストとコンテキストのメタデータを組み立てる。
# 検索結果は `results[0]` という変数に格納される。
# 'pymilvus.orm.search.SearchResult' です。
METADATA_FIELDS = [f for f in output_fields if f != 'chunk'].
formated_results, context, context_metadata = _utils.client_assemble_retrieved_context(
results, metadata_fields=METADATA_FIELDS, num_shot_answers=top_k)
return formatted_results, context, context_metadata
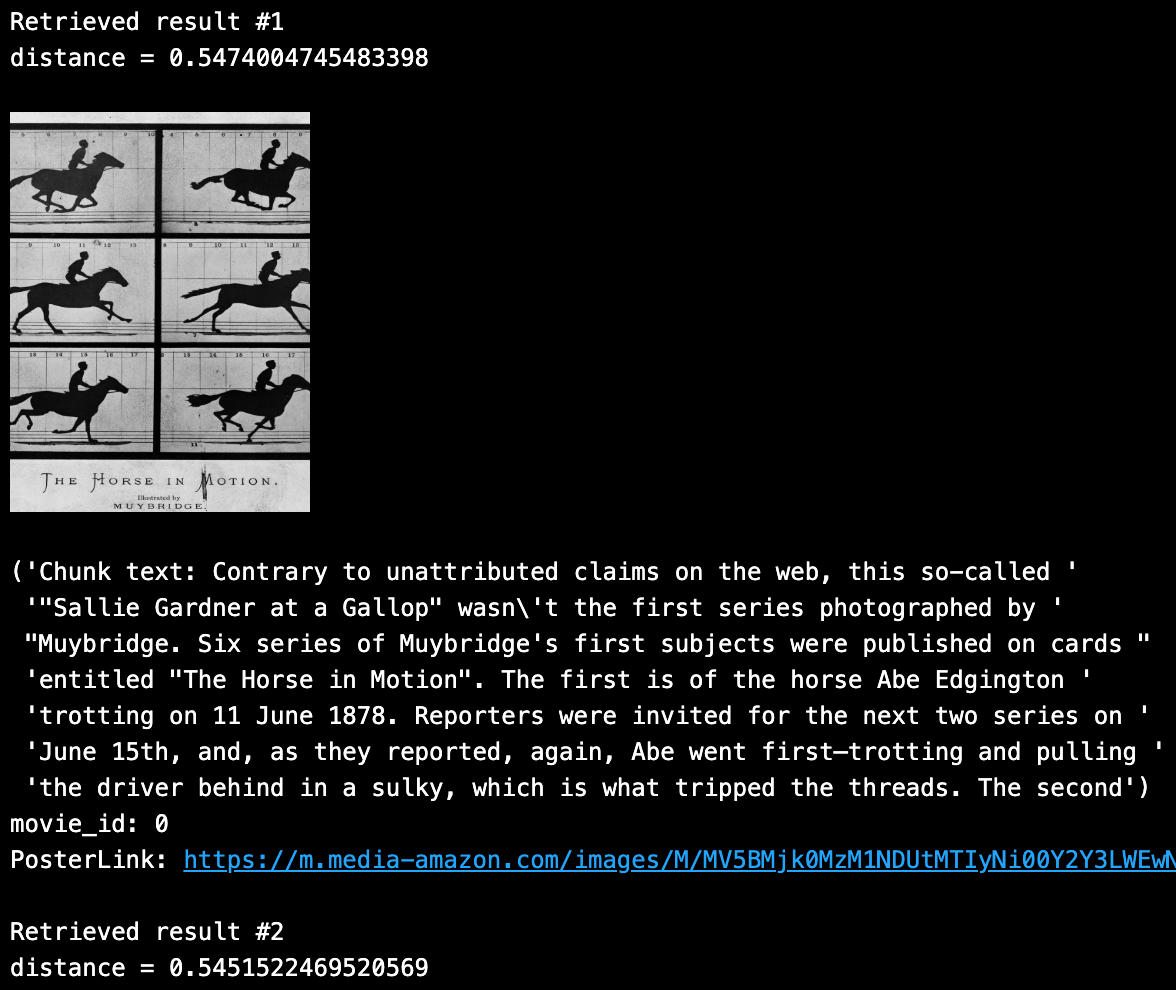
SAMPLE_QUESTION = "マイブリッジの馬の映画"
# HNSWインデックスを持つユニークな上位k個の結果を返す。
TOP_K = 2
# 返す出力フィールドを定義する。
OUTPUT_FIELDS = ["movie_id", "chunk", "PosterLink"] # 出力フィールドを定義する。
formatted_results、context、context_metadata = \
mc_run_search(SAMPLE_QUESTION, OUTPUT_FIELDS, TOP_K)
上位2つのユニークな結果をループすると、上記の検索クエリから次のようなコンテンツが密接に返されることがわかります:
完全なRay Data scriptはGitHubで公開されている。
結論
今回のブログでは、Ray DataとMilvusのBulk Import機能を使ってベクター生成を大幅に高速化し、効率的にベクターデータベースにバッチロードする方法を紹介しました。例えば、Ray Dataを使って102K行のデータをエンベッドした場合、素朴なPandasのアプローチでは4時間かかったのに対し、4分で済みました!****さらに、MilvusでBulk Importを使用すると、非常に効率的なベクターインデックスを構築することができ、通常のインクリメンタル挿入と比較してリソースと時間を節約することができます。詳しくはRay DataとMilvusとZilliz CloudのBulk Import機能をご覧ください!
 Christy Bergman
Christy BergmanChristy Bergman is a passionate Developer Advocate at Zilliz. She previously worked in distributed computing at Anyscale and as a Specialist AI/ML Solutions Architect at AWS. Christy studied applied math, is a self-taught coder, and has published papers, including one with ACM Recsys. She enjoys hiking and bird watching.
 Cheng Su
Cheng SuCheng Su is the manager of the Data team at Anyscale, a committer of the Ray open source project (https://github.com/ray-project/ray), and the code owner of the Ray Data module. Previously, Cheng Su worked in the Data Infrastructure teams at Meta, Spark, and Hadoop.
読み続けて

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.