




データサイエンスに向けたチャット:Zilliz Cloudでチャットボットを構築する
*この記事は、「データサイエンスに向けたチャット」ブログシリーズの第1部です。
ジェネレーティブAIの時代、開発者はよりインテリジェントなアプリケーションのために大規模言語モデル(LLM)を活用している。しかし、LLMは知識が限られているため、幻覚を見やすい。Retrieval Augmented Generation (RAG)は、LLMを外部の知識で補うことで、この問題に効果的に対処する。Chat Towards Data Scienceブログシリーズでは、あなたのデータセットを知識のバックボーンとして使い、RAGベースのチャットボットを構築する手順を説明します。
ブログシリーズの最初のパートでは、WebサイトTowards Data Science用のチャットボットの作成についてご案内します。Webスクレイピングを活用して、Milvus上に構築されたフルマネージドベクターデータベースサービスであるZilliz Cloudに格納されたナレッジベースを作成します。
BeautifulSoup4によるウェブデータのスクレイピング
機械学習(ML)プロジェクトの最初のステップは、必要なデータを収集することである。このプロジェクトでは、知識ベース用のデータを収集するためにWebスクレイピング技術を採用する。ウェブページを取得するために requests ライブラリを利用し、HTML情報を解析して段落を抽出するためにBeautifulSoup4(ウェブページから情報をスクレイピングするライブラリ)を利用する。
WebスクレイピングのためのBeautifulSoup4とRequestsの準備
始めるには、pip install beautifulsoup4 sentence-transformersを実行してBeautifulSoupをインストールする。このセクションで必要なインポートは requests と BeautifulSoup の2つだけである。次に、スクレイピングしたいURLの辞書を作成する。この例ではTowards Data Scienceのコンテンツのみをスクレイピングしているが、他のウェブサイトをスクレイピングすることもできる。各アーカイブページから、以下のコードに示すフォーマットでデータを取得する。
インポートリクエスト
from bs4 import BeautifulSoup
urls = {
'Towards Data Science': 'https://towardsdatascience.com/archive/{0}/{1:02d}/{2:02d}'、
}
ウェブスクレイピングには2つのヘルパー関数も必要だ。最初の関数は、年の日数を月と日の形式に変換します。2つ目は、記事から拍手数(拍手はMediumの記事への支持を示す)を取得します。
日数変換関数は比較的シンプルです。毎月の日数をハードコードし、そのリストを使って変換を行います。このウェブスクレイピングプロジェクトは2023年をターゲットにしているので、うるう年を考慮する必要はありません。もしお望みであれば、ご自由に変更してください。
拍手カウント機能は、Mediumの記事の拍手数を表します。いくつかの記事は何千もの拍手を受けることがあり、Mediumはそれを "K "という文字で表します。そのため、この関数ではこの表現を考慮する必要があります。
# その年の "日 "を受け取り、"月"、"日 "を返す
def convert_day(day):
month_days = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31].
m = 0
d = 0
while day > 0:
d = day
day -= month_days[m]
m += 1
return (m, d)
# claps文字列を変換
def get_claps(claps_str):
if (claps_str is None) or (claps_str == '') or (claps_str.split is None):
return 0
split = claps_str.split('K')
claps = float(split[0])
claps = int(claps*1000) if len(split) == 2 else int(claps)
return claps
BeautifulSoup4 Webスクレイピングのレスポンスを解析する
必要なコンポーネントをセットアップしたので、ウェブスクレイピングを進めよう。このセクションでは、"time "という追加のライブラリをインポートする。このライブラリを追加したのは、処理中に429エラー(リクエストが多すぎる)に遭遇したからだ。timeライブラリを使うことで、リクエストを送信する間に遅延を導入することができる。さらに、Hugging Faceから埋め込みモデル、具体的にはMiniLMモデルを取得するために、文変換ライブラリを利用します。
前述したように、我々は2023年のデータをスクレイピングするだけなので、年を2023年に設定する。さらに、1日目(1月1日)から243日目(8月30日)までのデータだけが必要です。スクレイピングした時点では9月上旬だった。今にして思えば、244日目までスクレイピングしたほうがよかったのだが、とりあえずはすでにやったことで進めることにする。関数の最初の部分、最初の time.sleep() 呼び出しまでで、必要なコンポーネントをセットアップする。イテレータを月と日に変換し、それを日付文字列に変換し、アーカイブURLからHTMLレスポンスを取得します。
HTMLを取得した後、BeautifulSoupを使って解析し、特定のクラス名(コードで示されている)を持つdiv要素を検索する。そこから、タイトル、サブタイトル、記事のURL、拍手数、読書時間、回答数を解析する。その後、記事のURLから記事を取得するために再び requests を使用します。
time.sleep()`を2回呼び、このforループの2番目のセクションを終了する。この時点で、各記事に必要なメタデータのほとんどを取得したことになる。各段落とそれに対応する埋め込みを、Hugging Faceモデルを使って抽出する。そして、その特定の段落と記事のすべてのメタデータを含む辞書を作成する。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
インポート時間
# data_batch = [].
年 = 2023
for i in range(1, 243):
月, 日 = convert_day(i)
date = '{0}-{1:02d}-{2:02d}'.format(year, month, day)
for publication, url in urls.items():
response = requests.get(url.format(year, month, day), allow_redirects=True)
if not response.url.startswith(url.format(year, month, day)):
続ける
time.sleep(8)
page = response.content
soup = BeautifulSoup(page, 'html.parser')
articles = soup.find_all(
"div"、
class_="postArticle postArticle--short js-postArticle js-trackPostPresentation js-trackPostScrolls")
for article in articles:
title = article.find("h3", class_="graf--title")
# print(title.contents)
もしtitleがNoneなら
続ける
title = str(title.contents[0]).replace(u'\xA0', u' ').replace(u'\u200a', u' ')
# タイトル = title.contents[0]
サブタイトル = article.find("h4", class_="graf--subtitle")
subtitle = str(subtitle.contents[0]).replace(u'\xA0', u' ').replace(u'\u200a', u' ') if subtitle is not None else ''
article_url = article.find_all("a")[3]['href'].split('?')[0]。
try:
claps = get_claps(article.find_all("button")[1].contents[0])
ただし
claps = 0
reading_time = article.find("span", class_="readingTime")
reading_time = 0 if reading_time is None else int(reading_time['title'].split(' ')[0])
responses = article.find_all("a")
if len(responses) == 7:
responses = responses[6].contents[0].split(' ')
if len(responses) == 0:
responses = 0
else:
responses = responses[0].
else:
responses = 0
article_res = requests.get(記事_url)
time.sleep(8)
soup = bs4.BeautifulSoup(article_res.text)
paragraphs = soup.select('[class*="pw-post-body-paragraph"]')
for i, paragraph in enumerate(paragraphs):
embedding = model.encode(paragraph.text)
data_batch.append({
"_id": f"{article_url}+{i}"、
"article_url": article_url、
"title": タイトル、
「サブタイトル": サブタイトル、
「拍手": 拍手、
"responses": レスポンス、
"reading_time":reading_time、
"publication": 出版物、
"date": 日付、
「段落": paragraph.text、
"embedding": 埋め込み
})
最後のステップは、ファイルをpickleすることです。
インポート pickle
filename="TDS_8_30_2023"
with open(f'{filename}.pkl', 'wb') as f:
pickle.dump(data_batch, f)
データはどのように見えるか?
データを視覚化することは常に役に立つ。下記はZilliz Cloudでデータがどのように見えるかです。ベクトルを表す埋め込みに注目してください。このベクトル埋め込みは、次の節でテキストから生成します。
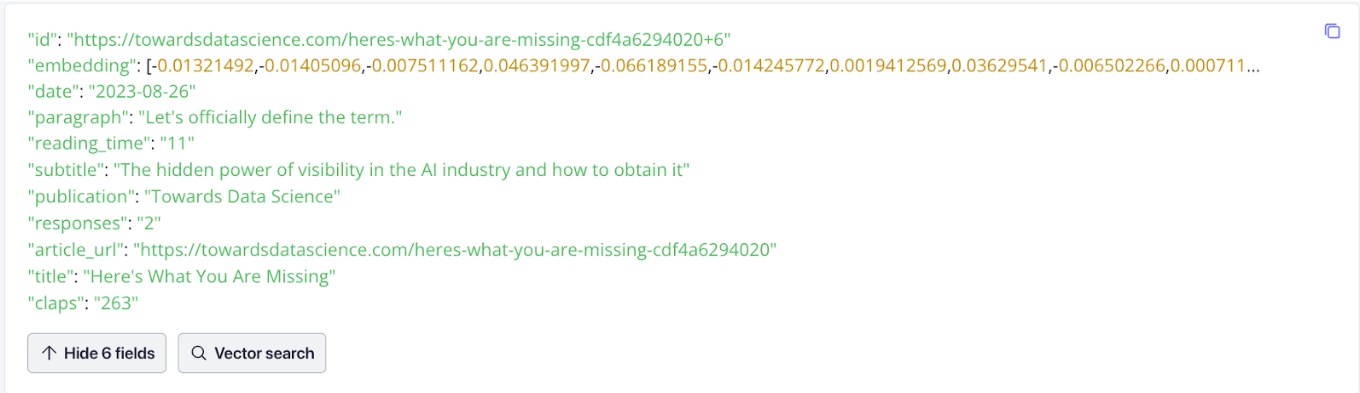
TDSからベクターデータベースにデータを取り込む
データを入手したら、次のステップはそれをベクターデータベースにパイプすることである。このプロジェクトでは、データをTowards Data Scienceからスクレイピングするのではなく、Milvus上に構築されたフルマネージド・ベクターデータベースサービスであるZilliz Cloudにインジェストするために、別のノートブックを利用した。
Zilliz Cloudにデータを取り込むには、以下の手順に従います:
Zilliz Cloudに接続する。
コレクションのパラメータを定義します。
Zilliz Cloudにデータを挿入する。
Jupyterノートブックのセットアップ
pip install pymilvus python-dotenvコマンドを実行してJupyter Notebookをセットアップし、データの取り込みを開始する。いつものように環境変数を管理するためにdotenvライブラリを使う。pymilvusパッケージでは、以下のモジュールをインポートする必要がある:
utility` - コレクションの状態をチェックする。
connections` - Milvusインスタンスに接続する。
FieldSchema- フィールドのスキーマを定義する。CollectionSchema- コレクションのスキーマを定義する。DataType` - フィールドに格納されるデータ型
Collection- コレクションへのアクセス方法
次に、以前pickleしたデータを開き、環境変数を取得し、Zilliz Cloudに接続する。
インポート pickle
インポート os
from dotenv import load_dotenv
from pymilvus import utility, connections, FieldSchema, CollectionSchema, DataType, Collection
filename="TDS_8_30_2023"
with open(f'{filename}.pkl', 'rb') as f:
data_batch = pickle.load(f)
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
connections.connect(
uri= zilliz_uri、
token= zilliz_token
)
Zillizベクターデータベースとデータ取り込みのセットアップ
次に、Zilliz Cloudをセットアップする必要があります。TDSウェブサイトからスクレイピングしたデータを保存し、整理するためにコレクションを作成する必要があります。dimensionとcollection nameの2つの定数が必要です。dimensionはベクトルの次元数です。この場合、384次元のMiniLMモデルを使用します。コレクション名は自明である。
Milvusの新しいdynamic schema機能を使えば、他のフィールドの数やデータ型を気にすることなく、コレクションのidとembeddingフィールドを定義することができます。しかし、フィールドを正しく取得するためには、保持するフィールドの具体的な名前を覚えておくことが重要です。
このプロジェクトの例では、動的スキーマ機能を使用して、IDと埋め込みフィールドのみを定義します。そして、これらのフィールドをスキーマに割り当て、スキーマをコレクションに割り当てます。次に、インデックスのパラメータを指定します。この場合、量子化(FLAT)なしの転置ファイルインデックス(IVF)、ユークリッド距離(L2)、128個のセントロイドをインデックスに使用する。
量子化なしのIVFは、最も直感的なインデックス作成方法です。基本的には、ベクトルを128のセクションにクラスタリングしてクエリーを実行する。128はこの場合任意の数である。これはハイパーパラメーターであり、結果がどのように見えるかによって調整することができる。ヒューリスティックには、クエリの初期の複雑さを軽減するだけでなく、クラスタの多様性を提供することができるので、これは良い出発点です。これらのパラメータを定義したら、埋め込みフィールドにインデックスを作成し、コレクションをメモリにロードします。
DIMENSION=384
COLLECTION_NAME="tds_articles"
fields = [
FieldSchema(name='id', dtype=DataType.VARCHAR, max_length=200, is_primary=True)、
FieldSchema(name='embedding',dtype=DataType.FLOAT_VECTOR,dim=DIMENSION)]。
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
コレクション = コレクション(name=COLLECTION_NAME, schema=schema)
index_params = { {インデックス・タイプ
「index_type":"IVF_FLAT"、
「metric_type":"L2",
「params":params": {"nlist":128},
}
collection.create_index(field_name="embedding", index_params=index_params)
コレクション.load()
コレクションを定義してメモリにロードしたら、データを挿入するために2つのオプションがあります:
データ・バッチをループし、各部分を個別に挿入する。
バッチでデータを挿入する
すべてのデータを挿入した後、コレクションをフラッシュしてインデックスを作成し、一貫性を確保することが重要です。大量のデータを取り込むには時間がかかることがあります。
for data in data_batch:
collection.insert([データ])
collection.flush()
TDSの記事セグメントを問い合わせる
これですべてがセットアップされ、クエリの準備が整いました。この記事では、クエリをベクトル化し、Zilliz Cloudで最も近いものを検索することで、この部分をシンプルにします。次の投稿では、LlamaIndexとLangChainも使います。
HuggingFaceモデルを取得し、Zillizにクエリするように設定します。
埋め込みモデルを取得し、Towards Data Scienceのナレッジベースに問い合わせるためにベクターデータベースをセットアップする必要があります。このステップでは、別のノートブックを実行する必要がある。環境変数を管理するために dotenv ライブラリを使います。さらに、Sentence TransformersのMiniLMモデルを使う必要がある。このステップでは、Webスクレイピングセクションで提供されたコードを再利用することができる。
import os
from dotenv import load_dotenv
from pymilvus import connections, Collection
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
ベクトル検索クエリを実行する
次に、ベクターデータベースに接続して検索を実行します。このプロジェクトでは、Zilliz Cloudインスタンスに接続し、先ほど作成したコレクションtds_articlesを取得します。クエリを取得するために、ユーザーに2023年9月までのTDSに関する質問を入力するように促します。
次に、Hugging Faceの埋め込みモデルを使用してクエリをエンコードする。このプロセスは、ユーザーの質問を384次元のベクトル表現に変換する。次に、このエンコードされたクエリーを使用して、ベクトル・データベースを検索する。検索時には、近似最近傍フィールド(anns_field)、インデックスパラメータ、検索結果数の上限、出力フィールドを指定する必要がある。
以前は、Milvusの動的スキーマ機能を利用してフィールドスキーマの定義を効率化した。現在、ベクターデータベースを検索する際、検索結果に希望のダイナミックフィールドを含めることが不可欠です。この具体的なシナリオでは、記事の各段落のテキストを含むparagraphフィールドを要求します。
connections.connect(uri=zilliz_uri, token=zilliz_token)
コレクション = コレクション(name="tds_articles")
query = input("9月までのTowards Data Scienceの2023年の出版物に何を聞きたいですか?")
embedding = model.encode(クエリ)
close = collection.search([embedding]、
anns_field='embedding'、
param={"metric_type":"L2",
「params":params: {"nprobe":16}},
limit=2、
output_fields=["paragraph"])
print(close[0][0])
print(close[0][1])
このアプリに大規模言語モデルに関する情報を提供するよう求めたところ、以下の2つの回答が返ってきた。これらのレスポンスは「言語モデル」に言及し、いくつかの関連情報を含んでいますが、大規模言語モデルについての詳細な説明はありません。2つ目の回答は意味的には似ていますが、私たちが要求した内容に十分に近づける必要があります。

ベクターデータベースの知識ベースへの追加
これまで、私たちはZillizをベクトルデータベースとして使い、TDSの記事に関する知識ベースを作ってきた。意味的に類似した検索結果を簡単に取得することはできたが、それは私たちが必要としているものに過ぎないこともある。次のステップは、新しいフレームワークや技術を取り入れることで、成果を高めることである。
次のセクションでは、LlamaIndexを追加して検索結果をルーティングする方法を探ります。以前のブログで紹介したQuery Multiple Documents using LlamaIndex, LangChain, and Milvusと同様のルーティングです。
まとめ
このチュートリアルでは、Towards Data Science の出版物のためのチャットボットの構築について説明します。ベクターデータベース(具体的にはZilliz Cloud)に知識ベースを作成し保存するためのウェブスクレイピングプロセスを説明します。次に、ユーザーにクエリーを促し、クエリーをベクトル化し、ベクトルデータベースにクエリーする方法を示します。
しかし、結果は意味的には似ていますが、私たちが望むものではありません。このブログ・シリーズの次のパートでは、クエリのルーティングにLlamaIndexを使用し、より良い結果が得られるかどうかを探ります。ここで説明したステップとは別に、モデルを置き換えたり、テキストを組み合わせたり、別のデータセットを使用したりして、Zilliz Cloudで実験することもできます!
Chat Towards Data Scienceシリーズをもう一度読むには、以下のリンクをクリックしてください:

読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.