




推薦システムにおける近似最近傍探索
#はじめに
2024年2月、我々はSF Unstructured Data MeetupでYury Malkovから近似最近傍(ANN)とレコメンダー・システムにおけるその重要な役割について聞いた。ANN検索は、すでに世界で最も人気のあるツールのプロダクション・スタックに組み込まれています。ユーリー氏は、大規模なレコメンダー・システムにANNが採用された主なコンセプトと背景を理解する手助けをしてくれる。
ユーリー・マルコフの講演のYouTube再生へのリンク:YouTubeで講演を見る
なぜANNを気にする必要があるのか?
ユーリ・マルコフは文字通り天才だ。もし信じられないなら、彼のGoogle Scholarのリストhttps://scholar.google.com/citations?user=KvAyakQAAAAJ&hl=enを見てください。物理学者であり、レーザー研究者であり、HNSWの発明者である。HNSWはグラフベースのインデックス作成アルゴリズムで、現在ではすべての主要なベクトルデータベースに統合されている。現在はOpenAIでリサーチ・サイエンティストとして働いている。2024年のトニー・スタークの経歴のような気がしないでもない。
それでは、ユーリの「推薦システムにおける近似最近傍探索」の講演に入りましょう。
ANN検索とは?
ANNサーチの基本については短くと長くですでに説明したので、ここでは簡単に説明する。
最近傍探索は、機械学習やデータサイエンスのアプリケーションで類似性探索を行うために使用できる統計的手法のセットである。検索を完了する際にシステム内の全てのデータポイントを互いに比較するKNNとは異なり、ANN検索アルゴリズムは様々なインデックス作成テクニックを使って近似最近傍を返す。 ANN検索は、今日、顧客が直面する多くのアプリケーションやテクノロジーの中核となっている。検索エンジン(Googleのような、ベクトル検索ではない)からソーシャルメディアサイトに至るまで、ANNとレコメンダーシステムは、すでに生産現場で、スタックを通して統合されている。
ANNはレコメンダー・システムの唯一のソリューションではなかった。では、どうやってここまで来たのか?現在市場に出回っている成熟したANNソリューション、レコメンダーシステムが最近傍アルゴリズムにとって難しい問題である理由、開発者がどのようにレコメンダーシステムを構成してきたか、研究者がどのようにANNを使ってレコメンダーシステムスタックを書き換えているか、について説明します。 Yuriは講演の中で、多くの成熟したANNソリューションが存在することを指摘する。 これらのトピックの多くは、我々のVisual Guide to Choosing a Vector Indexで詳しくカバーされているが、Yuriのプレゼンテーションでリストアップされたツールの表をまとめた。
##言及されたANNインデックスの表
| ANNインデックス|分類|シナリオ
|-----------|------------------------------------|----------------------------------------------------------------------------------------------------|
| LSH|グラフベースのインデックス|-非常に複雑な多次元データセット
-ユークリッド距離を使ってデータポイントをバケット化
-最も近い結果のみを返す。
| HNSW|グラフベースのインデックス|-非常に高速なクエリ
-可能な限り高い想起率を要求
-大きなメモリ資源を必要とする。
| SCANN|量子化ベースのインデックス|-非常に高速なクエリ
-可能な限り高い想起率を必要とする
-大きなメモリ資源を必要とする。
| IVF_PQ|量子化ベースのインデックス(反転)|- 反転インデックス
- 非常に高速なクエリ
- 限られたメモリ資源
- 回収率の大幅な妥協を受け入れる
| IVF_HSNW|グラフベースのインデックス(転置)|-転置インデックス
-HSNWベース
-可能な限り高い想起率を要求
-大きなメモリ資源を必要とする。
| DiskANN|複数の最近傍インデックス|- ANN検索用のANN修正とツールキット
| ANNOY|複数の最近傍インデックス|- LSHまたはKDtreesの実装
-メモリ効率が良く、高次元空間を高速に探索する。
| その他|FAISS, cuHNSW, ngt, song
ANNベンチマークについて
YuriはANNベンチマークを軽快にこなし、ANNBenchmarksを紹介している。逆ANNアルゴリズムのベンチマークはトリッキーになる可能性があるという注意書きがある。ゆっくり話そう:
**ANN-Benchmarksとは?
ANN-Benchmarksは、様々な近似最近傍探索アルゴリズムを評価するベンチマーク環境であり、距離尺度とデータセットごとに分割された結果をウェブサイトで提供している。ベンチマークには再現率や1秒あたりのクエリ数などの性能指標が表示され、ユーザーは GitHub のプルリクエストでコードを投稿して貢献することができます。
GitHub ](https://assets.zilliz.com/benchmark_results_e348318dac.png)
ANNアルゴリズムのベンチマークデータは様々な場所で見つけることができます(github、ANN-Benchmarks、さらには製品ドキュメント)が、常にQPS - queries per secondをプロットしたチャートを見ることができます。QPSは多ければ多いほど良い!Vroom vroom!
ANN(および他のベクトル探索)アルゴリズムを選択する際の注意点
アルゴリズムのベンチマークを見ると鼻血が出そうになるのはあなただけではありません。だからこそMilvusチームはKnowhereを作ったのだ。KnowhereはMilvusのコアとなるオープンソースのベクトル実行エンジンで、 Faiss、 Hnswlib、 Annoyを含むいくつかのベクトル類似性検索ライブラリを組み込んでいます。Knowhereは、インデックス構築と検索要求をどのハードウェア(CPUまたはGPU)で実行するかを制御する。これがKnowhereの名前の由来である。将来のリリースでは、DPUやTPUを含む、より多くの種類のハードウェアがサポートされる予定です。
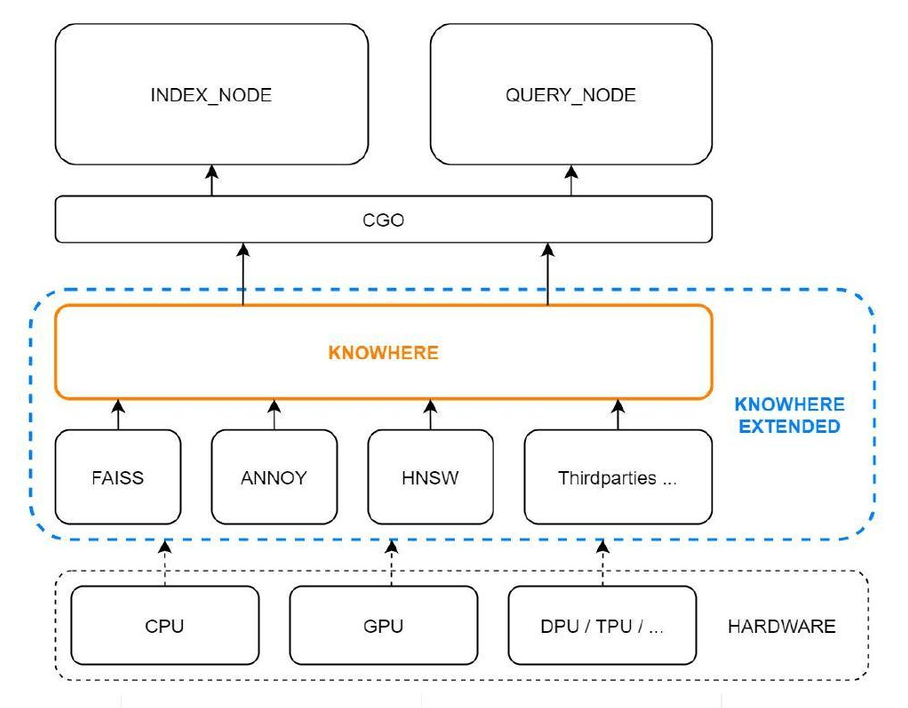
Knowhereを基盤に - Zilliz CloudチームはZillizのコアベクター検索エンジンであるCardinalをリリースした。この検索エンジンは、すでに旧バージョンと比較して3倍の性能向上を実証しており、Milvusの10倍に達する検索性能(QPS)を提供している。 ANN検索がレコメンダー・システムに統合されて久しい。なぜANN検索アルゴリズムがこれほどまでに実稼働中のレコメンダーシステムに普及したのかを知るためには、一歩引いて、ANNが競争した動機、アーキテクチャ、斬新なソリューションを見てみる必要がある。
スケールの大きなレコメンデーションシステムへの応用:動機と課題
**全てのレコメンダーシステムの基本的なゴールは、クエリ(ユーザー、アプリケーション、コンテキスト)に対してアイテム(ビデオ、製品、ドキュメント、メッセージ)を返すことである。このアイテムとクエリの関係を覚えておいて欲しい-それは検索(レコメンダー)アルゴリズムを理解する上で重要だ。
市場:* レコメンダー技術は、消費者行動を生成する能力を持つことから、大きな市場を提示し、代表するものである。
**規模における典型的な課題
Generability:
- 従来のレコメンダーシステムは、主に内部データ、モデル、インフラに依存していたため、汎用性が低かった。
**膨大なコーパス
- 大規模なデータセット(数百万から数兆のアイテム、クエリー)は大きな推論コストを生む。
- 効率化と推論コストの抑制は非常に重要である。
- 重いビデオや画像の処理には、インフラを維持するための専任のエンジニアが必要だった。
ソリューション、成熟度:
- 国産ソリューション/インフラは通常国産(例:Google、Meta、X、)。
- 通常、推論コストを節約するために多段階レコメンダーファネル(下記参照
- ベクターデータベースやLLMの台頭により、すぐに使えるツールが人気と支持を集めている。
典型的な多段階ファネル
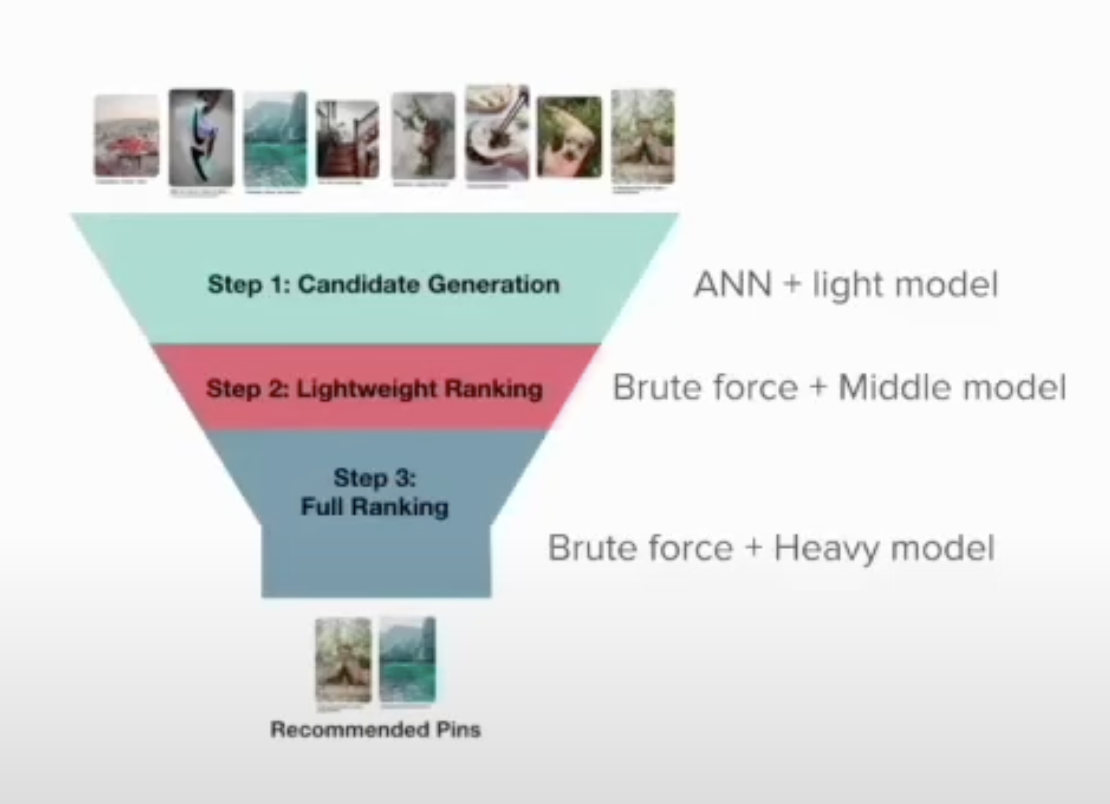
Yuriは、プロダクションにおける典型的なレコメンダーシステムのダイアグラムを掘り下げている。以下のビデオ推薦の例では、アプリケーションはアイテムとクエリを渡され、ビデオ推薦のピンを返さなければなりません。これらのアプリケーションは、アイテム候補が生成され、検索結果を絞り込むために連続したランキングモデルを通して実行される多段階ファネルである。
ステップ 1: 候補の生成 - ANN + ライトモデル
この初期段階では、システムは近似最近傍を使って膨大なビデオデータベースを素早くふるいにかけ、ユーザーのクエリに関連する候補ビデオの予備リストを特定する。このプロセスは高速かつ効率的に行われるように設計されており、クエリの特徴に一致する可能性が最も高いものに焦点を当てることで、潜在的に数百万ものアイテムを処理する。このステップで使用される「ライトモデル」は、通常、よりシンプルで計算量の少ないモデルであり、ユーザーの興味や検索条件に最も合致する候補を絞り込むのに役立ちます。
ステップ2:ライトウェイト・ランキング - ブルートフォース+ミドルモデル
候補セットが生成されると、次のステップではこれらの候補をより詳細に検討する。これは「ブルートフォース」アプローチを用いて行われ、各候補は最初のステップで使用されたライトモデルよりも複雑な「ミドルモデル」を用いてより徹底的に評価される。このモデルは、ユーザー・エンゲージメント・メトリクス、文脈上の関連性、コンテンツの質などの追加的な特徴を考慮に入れ、最も関連性の高い動画が推奨リストの上位に押し上げられるように候補をランク付けします。このステップでは、パフォーマンスと精度のバランスを取り、品質と関連性に重点を置いて選択を絞り込む。
ステップ3:完全なランキング - ブルートフォース+ヘビーモデル
レコメンデーションプロセスの最終段階は、「ヘビーモデル」(使用されるモデルの中で最も洗練され、リソース集約的なモデル)を採用するフルランキングステージである。このモデルには、より深いユーザープロファイル分析、長期的な嗜好、詳細なコンテンツ分析、そして場合によっては現在の視聴傾向のようなリアルタイムデータなど、幅広いシグナルとデータポイントが組み込まれている。ここで適用されるブルートフォース手法は、各動画が包括的にスコアリングされ、ランク付けされることを保証し、最終的なレコメンデーションが高度にパーソナライズされ、適切であることを保証する。このステップは最高品質のレコメンデーションを保証しますが、より多くの処理能力と時間を必要とするため、レコメンデーションリストの最終的な洗練に適しています。
なぜHSNWは伝統的な推薦システムと(不完全な)解決策で失敗するのか? 大規模なプロダクション・レコメンデーション・システムが大規模なデータセットとそれに伴うコストに制約されていることを知っているユーリは、アイテムとクエリは2つの - 相容れない平面 にあると主張する。 クエリとアイテムが異なる相容れない空間に存在する場合、HNSW(Hierarchical Navigable Small World)のような伝統的な類似検索アルゴリズムは、クエリとアイテムの間の測定可能なリレーションシップや距離関数に直接依存するため、課題に直面する。近さを評価する明確なメトリックがなければ、HNSWは、クエリに最も近いマッチを見つけるためにアイテムのグラフをナビゲートするというその機能を効果的に実行することができない****。
項目とクエリの非互換性に対する新しい解決策のレビュー
データベクトル上のL2距離
**ベクトル化されたデータ入力間のL2距離を使って、推薦システムのための代理グラフ構造を作成する。
長所:* 候補の生成と再ランキング段階において、単純な距離計算を使用することでプロセスを簡素化し、スピードの優位性を提供する。
**より洗練されたモデルほど効果的にアイテムやクエリ間の複雑な関係やニュアンスを捉えられない可能性があり、パーソナライズされたレコメンデーションにならない可能性がある。
二部グラフランキング
**アイテムとクエリを二部グラフに投影し、アイテムは最も近いユーザーやクエリにリンクされ、これらの関係に基づいてエッジを生成することができます。
**他の手法との直接的な比較は限定的だが、ユーザーとアイテム間の関係データを構造化するのに効果的。
短所:* 二部グラフの構築と維持はリソース集約的であり、グラフの接続の密度と質によって有効性が大きく変わる可能性がある。
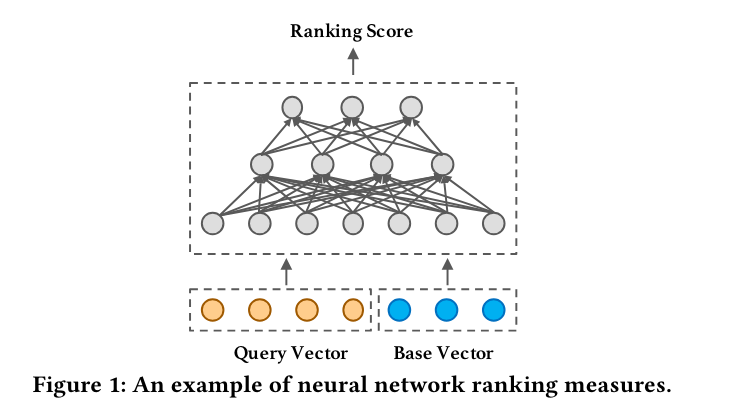
画像ソースhttps://www.vldb.org/pvldb/vol15/p794-tan.pdf
グラフ再ランキング(テキスト重視)
**ベクトルから作成したグラフを候補生成に利用し、そのグラフに直接重ランカーを適用してテキスト検索を行うことで、検索結果の品質を向上させる。
長所:* 従来の多段階ファネルを排除し、候補者フィルタリングの初期段階でのエラーの修正を可能にする。
短所:* 主にテキストベースの検索に効果的である。非テキスト特徴が支配的な他の文脈ではあまり効果的でない可能性があり、適用範囲が限定される。
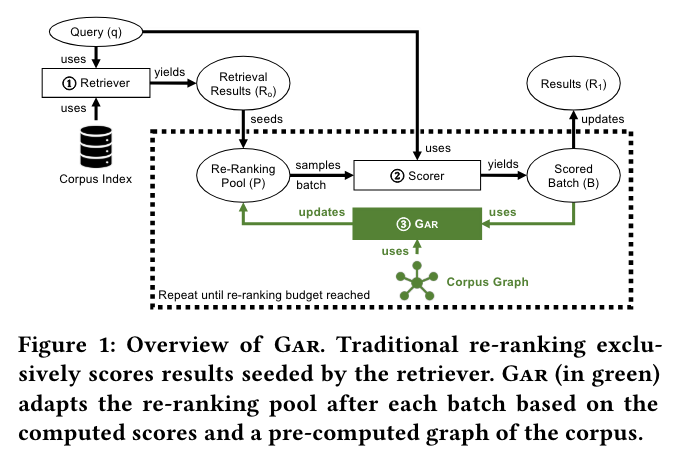
画像ソースhttps://arxiv.org/pdf/2208.08942
カスケード・グラフ検索
仕組み: 最初の検索では軽い距離関数で開始し、検索プロセス中にシームレスに重い距離関数に移行する。
Pros: 距離関数をリアルタイムに適応させることで柔軟性を提供し、検索プロセス全体を通して速度と精度の両方を最適化します。
短所:* デュアル距離関数の管理と最適化の複雑さは、システムの計算オーバーヘッドと複雑さを増加させ、スケーラビリティに影響を与える可能性がある。
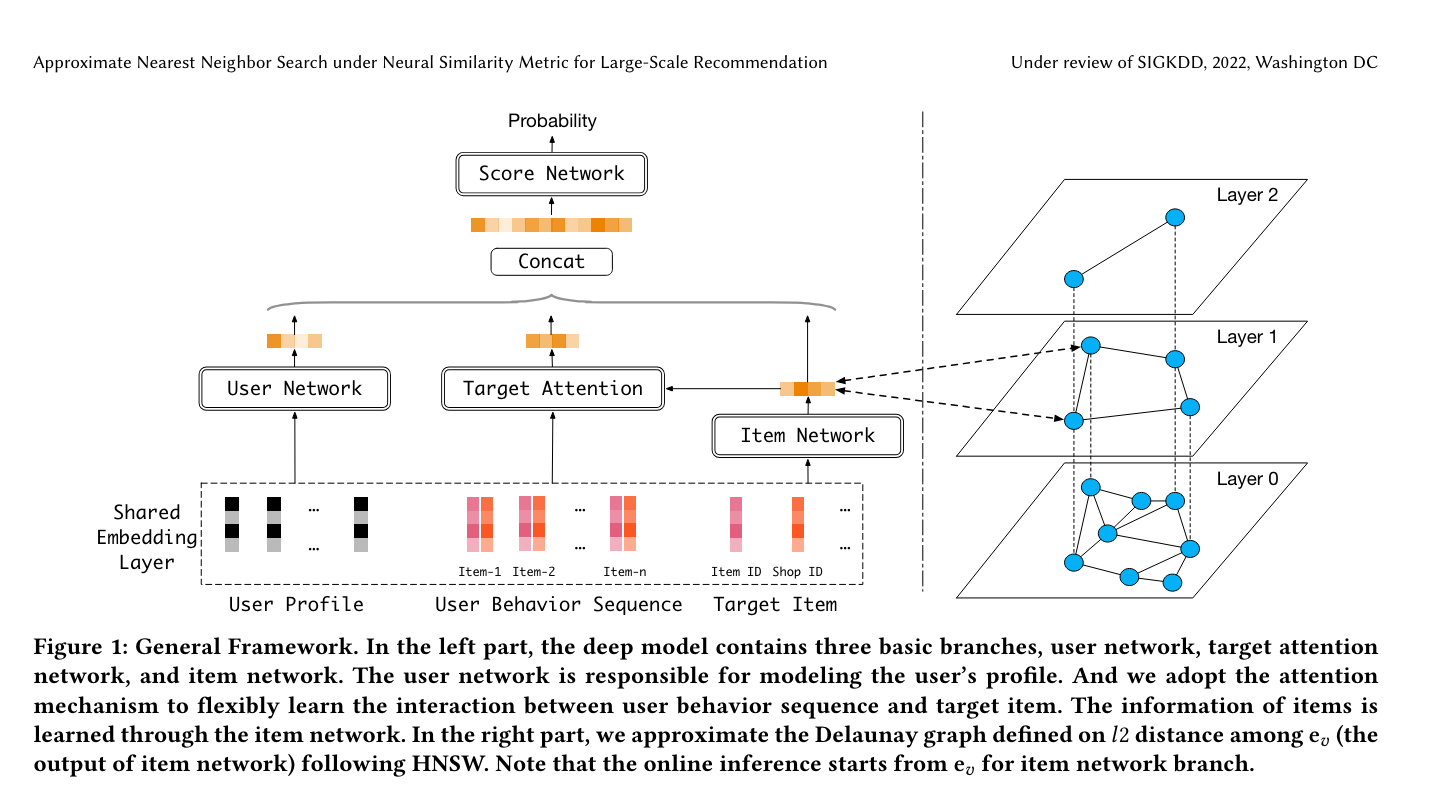
画像ソースhttps://arxiv.org/pdf/2202.10226
なぜANNサーチが人気なのか?
これらをまとめると、ユーリはANNアルゴリズムが、特に高次元のデータセットを扱うアプリケーション(大規模なレコメンダー・システムなど)において、これほど大規模に実装されている理由をよく描き出している。
- 完全なマッチングを必要としないのであれば、ANNアルゴリズムは他のNNアルゴリズムよりも常に良い解決策となる。
- 柔軟性** - 幅広い実装で、開発者はコストを選択することができます。
- 成熟度** - ANNはすべての主要なプログラミング言語で実装されており、ANN検索を選択し実行するためのいくつかの一般的なフレームワークがあります。
その他のリソース
ユーリー・マルコフ講演のYouTube再生へのリンク: YouTubeで講演を見る

読み続けて

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.