




高度なビデオ検索:意味検索のためのTwelve LabsとMilvusの活用
2024年8月、サンフランシスコで開催されたUnstructured Data Meetupで、Twelve Labsのデベロッパー・エクスペリエンス責任者であるJames Le氏が、セマンティック検索のための高度なビデオ検索について洞察に満ちた講演を行った。まだTwelve Labsのことをご存知でない方は、ぜひご聴講いただきたい。Twelve Labsは、機械が人間のように直感的にビデオを理解できるよう、最先端のマルチモーダルモデルを開発している。彼らは、人間のような精度で動画コンテンツを検索、生成、分類できるAPIとともに、動画埋め込みを生成するための最先端の基礎モデルを作成した。
講演では、Jamesが動画理解の重要な概念と、彼らの基礎モデルとAPIの全体的なワークフローについて説明します。ジェームズはまた、ビデオ理解モデルをZillizのMilvusのような効率的なベクトル・データベースと統合し、意味検索のためのエキサイティングなアプリケーションを作成することについても話す。AIが動画コンテンツにどのような革命をもたらすことができるのかに興味をお持ちの方にとって、このミートアップは貴重な機会となったことでしょう。
それでは、「高度なビデオ検索 - Twelve LabsとMilvusを活用したセマンティック検索」と題したジェームズの講演を紹介しよう。YouTubeで講演を見る.
8月のSouth Bay Unstructured Data Meetupで講演するJames Le氏](https://assets.zilliz.com/DSC_0024_1a06000953.JPG)
ビデオ理解とは何か?
動画は現実世界に関する強力な情報源である。静的なシーンのみを捉える画像とは異なり、動画は変化する行動、振る舞い、イベントなどの時間的情報を捉える。人間と同じように、機械もコンピュータビジョンやディープラーニングの技術を用いて、動画から意味のある情報を分析、解釈、抽出するように教えることができる。
動画理解の進化
ビデオが最初に発明されたのは19世紀後半で、当時は解釈のための技術はなかった。その後、1996年に最初の音声テキスト化技術が実用化され、トランスクリプトが作成された。しかし、その文字起こしは読みにくく、映像情報とは切り離されていた。さらに1997年には、最初のCNNベースの画像認識モデルLeNet - 5が発表され、ビデオフレーム内の「人」「犬」「衣服」などのオブジェクトを理解するためのタグが作成された。これらのタグは動画の文脈を理解する助けにはならず、齟齬を生じさせていた。その後、2012年以降、ビデオ理解は畳み込みニューラルネットワーク(CNN)によって革命的に変化し、行動認識などの高度なタスクを実行できるようになった。
映像理解の過去・現在・未来
過去において、ビデオ理解は、手作りの特徴やHOG(Histogram of Gradients)のような単純なコンピュータビジョン技術を使用して、色、テクスチャ、動きのような低レベルの特徴を抽出するような、低レベルのビデオ知覚タスクを解決することがすべてでした。初期のビデオ知覚タスクには、ビデオオブジェクト検出、ビデオオブジェクト追跡、ビデオインスタンス分割、アクション認識などがあった。
初期のタスクは、範囲が狭く、オブジェクトのラベル付けミスやタグの見逃しなどの非効率性を伴うことが多かった。現在では、ビデオ理解は、ビデオ分類、ビデオ検索、ビデオ質問応答、ビデオキャプションのような、より広範なタスクを扱うように進化している。CNN、リカレントニューラルネットワーク(RNN)、そして最近ではトランスフォーマーなどの技術により、モデルは空間的・時間的パターンを効率的に処理できるようになった。アクション認識は、モデルが単一のアクションを認識するだけでなく、シーケンス全体を分類するビデオ分類へと進化した。同様に、動画検索システムは、クエリに基づいてインデックスを作成し、関連動画を検索できるようになった。同時に、質問応答モデルはビデオ関連の質問に答えることができ、ビデオキャプションはシーンのテキスト説明を生成することができる。
現在のモデルは、特定のタスクに集中しているか、特定のデータに基づいて訓練されているか、単一のモダリティに基づいているかのいずれかである。将来的には、汎用的な理解を提供するマルチモーダルビデオ基礎モデルに焦点が当てられるだろう。これらのモデルは、映像、音声、テキストといった複数のソースからの情報を統合し、映像コンテンツの全体的な理解を発展させる。これらのモデルの背後にある主な考え方は、多様なユースケースや業界に対応し、動的なタスクに対処し、すべてのモダリティの統一された理解を提供し、リアルタイムで機能する複雑なアプリケーションを可能にすることである。
Twelve Labsによるビデオ・ファウンデーション・モデル
Video Foundation Modelsは、ビデオを包括的に理解するために設計された、事前にトレーニングされた大規模なモデルです。言語モデル(GPTなど)が様々なテキストベースのアプリケーションの基礎として機能するのと同様に、膨大な量のマルチモーダルデータ(ビデオ、オーディオ、テキスト)に対してトレーニングされたビデオ基礎モデルは、マルチモーダル埋め込みを生成する機能を備えており、さらに、様々なダウンストリームタスクを処理し、業界全体でビデオ中心のアプリケーションを作成するために使用することができます。
講演の中でJames Lee氏は、実世界のアプリケーションを作成する上でのビデオ基盤モデルの役割と、それがエンドユーザーにとってどのように有益であるかを非常に明確に概説している。
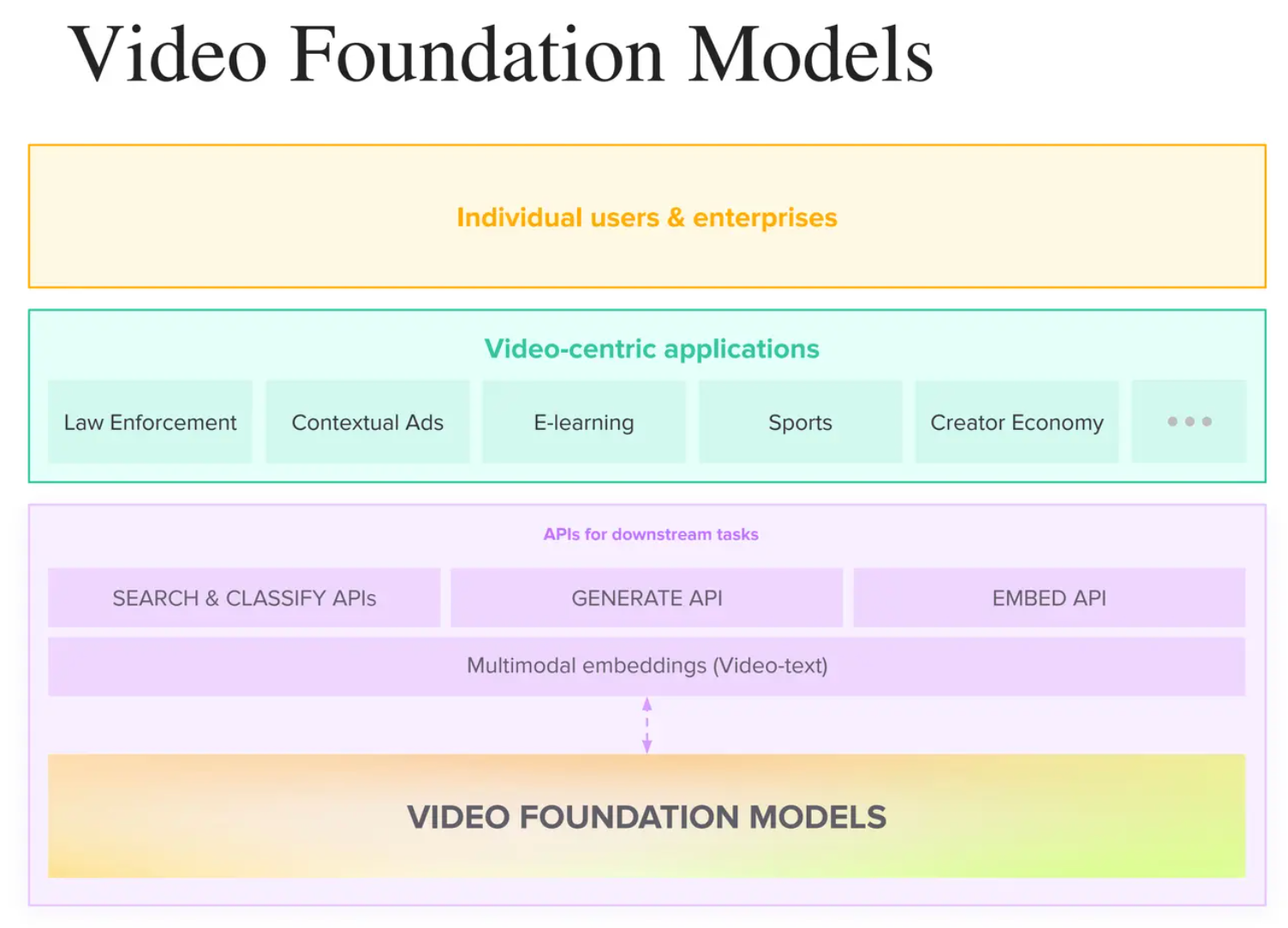
エンベッディング生成:**まず、基礎モデルは入力データに対してマルチモーダルエンベッディングを生成する。これらの埋め込みは、ビデオからの全ての会話と視覚的意味情報を格納する数値表現である。
下流タスク:***生成された埋め込みは、検索や分類、生成、埋め込みなどの下流タスクのためのAPIを作成するためにさらに使用することができます。
エンベッディングベースのゲートウェイAPIは、法執行、E-ラーニング、スポーツ、クリエイター・エコノミーなど、様々な業界にわたるビデオ中心のアプリケーションを生成するためにさらに使用することができます。
エンドユーザー:***上記のステップは、個人ユーザーや企業の需要に有益なインテリジェントなビデオ理解のパイプラインを作成します。
全体的なスタックを理解した上で、動画基盤モデルの技術的なニュアンスに深く飛び込んでみよう。
動画埋め込みとは何か?
動画の埋め込みは、本質的に、数値ベクトルの形で低次元のベクトル空間における動画の表現です。これらの埋め込みは、基礎モデルがビデオの内容を理解することを可能にする、ビデオの視覚的特徴とセマンティクスをキャプチャします。従来、ベクトル埋め込みは、画像、テキスト、音声のような単一のモダリティにのみ属し、それらは独立して処理されていました。しかし、マルチメディアコンテンツの台頭とトランスフォーマアーキテクチャの普及に伴い、視覚、テキスト、音声の情報を共有潜在空間に取り込むことができるエンベッディングの開発へとシフトしています。
動画埋め込みの魔法](https://assets.zilliz.com/the_magic_of_video_embeddings_edc34c64c3.png)
最先端のビデオ・ファンデーション・モデル - Marengo 2.6
James Leeが、Twelve Labsで開発された最新の最先端ビデオ基盤モデル「Marengo 2.6」を紹介する。このモデルは「Any-to-Any」検索タスクを実行できる。つまり、テキスト-動画、テキスト-画像、テキスト-音声、音声-動画、画像-動画など、様々な入力フォーマットを使って動画データを照会できる。このモデルは、動画検索の効率を大幅に向上させ、異なるモダリティ間でロバストなインタラクションを可能にするため、動画理解領域において変革をもたらす。

ブログ「【Marengo 2.6の紹介】(https://www.twelvelabs.io/blog/introducing-marengo-2-6)」でも触れているように、このアーキテクチャの基本コンセプトは「Gated Modality Experts」であり、マルチモーダル入力を専用のエンコーダーで処理してから、包括的なマルチモーダル表現にまとめることができる。このアーキテクチャには3つの主要モジュールがある。
ビジュアル・エキスパート - 映像内の外観、動き、時間的変化を捉えるために視覚情報を処理する。
Audio Expert - 音声情報を処理し、映像に関連する言語および非言語の音声信号をキャプチャします。
ゲーテッド・フュージョンモジュール - 各エキスパートの動画に対する寄与を評価し、それらを統合してマルチモーダル表現とし、あらゆる検索に対応します。
さらに、Marengo 2.6は微調整に優れており、ユーザーは特定のコンテンツのニーズやドメインに合わせてモデルをカスタマイズすることができます。このモデルのインフラストラクチャは、膨大なビデオデータセットの取り扱いをサポートしているため、大規模なビデオライブラリを持つ組織にも適応できます。このモデルは、シームレスな API インテグレーションの助けを借りて、検索、分類、コンテンツ管理の改善など、下流のタスクにさらに使用することができます。
Twelve Labs API を使用したダウンストリームタスク
動画検索API
テニスのグランドスラム大会のビデオで、ロジャー・フェデラーが相手を粉砕しながらポイントを獲得したシーンを、自然言語で説明するだけで正確に検索できることを想像してみてください。あまりに良さそうでしょう?これをビデオ検索と呼ぶ。
下図に示すように、動画検索は、まず動画基礎モデルによって動画の埋め込みを作成することで機能する。次に、検索APIは自然言語によるクエリを入力する。最後に、クエリのエンベッディングを動画のエンベッディングと照らし合わせて検索し、動画のシーンをタイミング付きで配信する。
Twelve Labs Search API](https://assets.zilliz.com/Twelve_Labs_Search_API_7b606cd812.png)
一方、従来の動画検索は、動画のインデックスを作成し検索するために、主にキーワードマッチングに依存していたため、そのアプローチと実行には大きな限界があった。しかし、マルチモーダルAI動画理解では、すべてのモダリティ間の複雑な関係を同時に捉え、より人間に近い動画解釈を提供することが可能である。
動画分類API
AIによる動画理解では、動画を事前に定義されたクラスに自動的に分類することができます。ゼロショット・アプローチを使用することで、事前にクラスを定義することなく、その場でクラスを取得することも可能です。Twelve LabsのClassify APIを使用すると、意味的特徴、オブジェクト、アクション、コンテンツのその他の要素を分析することで、動画をスポーツ、ニュース、エンターテイメント、ドキュメンタリーに整理することができます。
Twelve Labs Classify API](https://assets.zilliz.com/Twelve_Labs_Classify_API_374dd62089.png)
動画埋め込みAPI
Twelve Labs Embed API](https://assets.zilliz.com/Twelve_Labs_Embed_API_e9af2ed746.png)
Twelve Labsはまた、開発者向けにEmbed APIをプライベートベータでリリースした。SearchとClassifyのAPIはエンドツーエンドだったが、このAPIは、メタデータを追加したり、追加の計算をしたりすることで、埋め込みレイヤーで実験したい人のためのものだ。
このAPIは、異常検知、多様性ソート、感情分析、レコメンデーション、検索拡張世代(RAG)システムの構築など、様々なカスタムダウンストリームタスクに使用することができるが、これらに限定されない、ビデオレベルとクリップレベルのマルチモーダル埋め込みを作成する。
トゥエルブ・ラボとMilvusの出会い
Twelve Labs Meets Milvus](https://assets.zilliz.com/Twelve_Labs_Meets_Milvus_d40b441bfb.png)
2024年8月、Twelve LabsとMilvus(Zillizによるベクトルデータベース)が強力なビデオ検索アプリケーションを作るために手を結んだ。Milvusは、ベクトル埋め込みを管理、照会、検索するためのスケーラブルで効率的なベクトルデータベースです。Milvusは、高性能なAIアプリケーションを作成するために特別に設計されています。Twelve Labsの先進的なマルチモーダル埋め込み](https://www.twelvelabs.io/blog/multimodal-embeddings)のパワーを活用し、Milvusと統合することで、開発者は検索エンジン、推薦システム、コンテンツベースの動画検索などのアプリケーションを作成し、動画コンテンツ分析の新たな可能性を引き出すことができます。
Twelve LabsとMilvusを利用したセマンティック検索
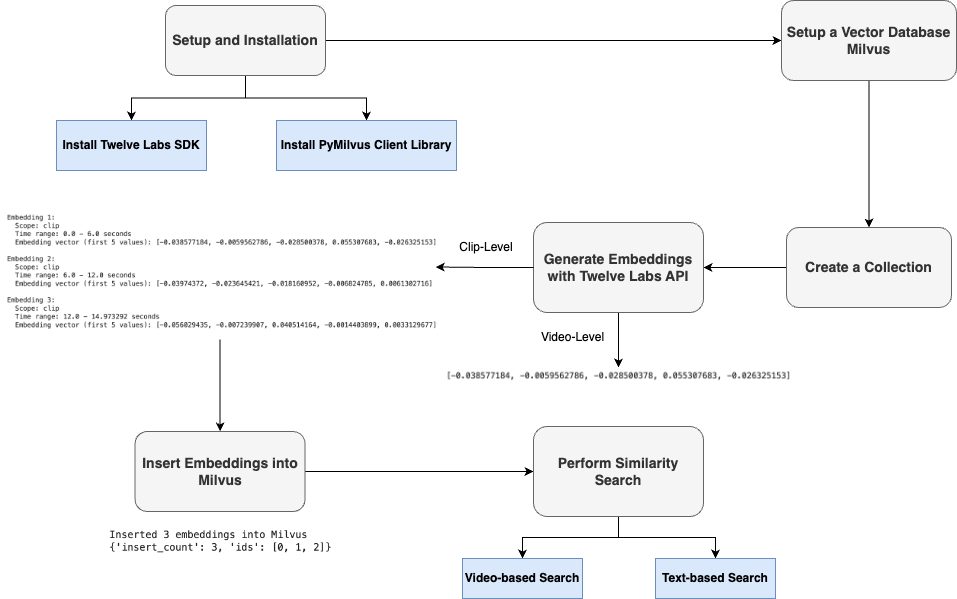
セマンティック検索を行うためには、まず、エンベッディングを生成するために必要なSDKやベクターデータベースのライブラリ、APIを選択し、セットアップする必要があります。次に、Twelve LabsのEmbed APIを使って、クリップレベルまたはビデオレベルに基づいて動画のマルチモーダル埋め込みを生成する。クリップレベルでは、動画を分割するクリップの長さを定義することができる。例えば、ビデオ全体が18秒で、クリップの長さを6秒とすると、3つのクリップレベルの埋め込みが得られる。埋め込みはベクトルデータベースに挿入され、最後に類似検索が実行される。ユーザがクエリ(ビデオまたはテキスト)を送信すると、同じ埋め込みモデルを使用して、クエリもベクトルに変換される。そして、システムはこのクエリ・ベクトルとデータベースに格納されたベクトルを比較し、最も意味的に類似した結果を検索する。
開発者向けリソース
Twelve LabsとMilvusを活用したセマンティック検索](https://colab.research.google.com/drive/1nTOAxo82E71_d9XhSfFuVmkMPv1Fj4u9?usp=sharing)の完全なコード実装。
Twelve Labs APIドキュメンテーション](https://docs.twelvelabs.io/)
Milvusドキュメント](https://milvus.io/docs)
ベクターデータベースとは何か、どのように機能するのか - Zilliz blog](https://zilliz.com/learn/what-is-vector-database)
検索の進化:伝統的なキーワードマッチからベクトル検索と生成AIへ](https://zilliz.com/learn/evolution-of-search-from-traditional-keyword-matching-to-vector-search-and-genai)
読み続けて

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.