




S3 Vectors から Zilliz Cloud への移行:階層型ストレージの力を解き放つ
非構造化データは現在、新たに生成される全データのほぼ90%を占めています。ChatGPTブームにより、この変化はさらに明確になりました。それ以来、ベクトル検索は非構造化データを理解するためのデフォルトの方法となり、RAGパイプライン、AIエージェント、レコメンデーションエンジン、チャットボットなどのGenAIシステムを支えています。
しかし、ベクトル検索は安くありません。 特に最適化されていないインデックスでは、NoSQLワークロードの10〜100倍の計算リソースを必要とすることがあり、場合によってはLLM呼び出しよりも高価になることさえあります。すべてのクエリが高性能ストレージとメモリにアクセスする場合、コストはパフォーマンスよりも速く拡大する可能性があります。
AWSはこれに対処するためにS3 Vectorsを導入し、ベクトル検索とオブジェクトストレージのコスト効率を組み合わせました。これは巧妙なアイデアですが、トレードオフがないわけではありません。レイテンシの増加、リコールの低下、大規模システムにおける柔軟性の制限です。Zilliz CloudのTiered Storageは、よりバランスの取れた道を取ります。データセット全体をオブジェクトストレージに保存しつつ、各クラスターのローカルSSDとメモリをインテリジェントなキャッシュとして使用して、クエリとデータアクセスを高速化します。
この記事では、S3 Vectorsが強みを発揮する場所と不足する場所を整理し、そのうえでZilliz CloudのTiered Storageがこれらの制約をどのように解決するかを示します。また、S3 VectorsからZilliz Cloudへ数ステップでデータを移行する短いチュートリアルも紹介します。
S3 Vectors: 安価だが、明確な制限がある
まずはうまく機能する点から始めましょう。S3 Vectorsは安価です。ストレージコストは1GBあたりわずか$0.06で、ほとんどのサーバーレスベクトルデータベースよりおよそ5倍安価です。4億ベクトル、月間1,000万クエリのサンプルワークロードでは、合計請求額は月額約$1,200になります。これは、他の場所で通常見られる5桁の請求額から大幅に下がります。低トラフィックまたはレイテンシを許容できるワークロードでは、この計算に異論を唱えるのは難しいでしょう。
パフォーマンスには限界がある: スケールや応答性を求め始めると、トレードオフが見えてきます。
コレクションサイズ: 各S3テーブルは最大5,000万ベクトルを保持でき、テーブル数にはグローバル上限として10,000があります。
クエリレイテンシ: 100万ベクトルのコレクションで約500 ms、1,000万では700 ms程度を想定してください。バックグラウンドジョブには許容できますが、リアルタイムアプリには向きません。
スループット: 200 QPSまでは200 ms未満のレイテンシが得られますが、それを超えてスケールするのは簡単ではありません。
書き込み速度: 2 MB/s未満に制限されており、GB/sレベルの書き込みを維持するMilvusのようなエンジンよりはるかに遅いです。利点は、書き込みが読み取りをブロックしないことですが、全体としては明らかに読み取り中心の静的データセット向けに最適化されています。
精度とクエリの柔軟性: リコールは通常85〜90%の範囲に収まり、それをさらに高めるための調整ノブはありません。フィルターを追加すると、リコールは急激に低下することがあり、時には50%を下回ります。あるベンチマークでは、データセットの半分を削除した後、Top-K=20のクエリが15件の結果しか返しませんでした。これは、精度制御が限定的であることを示す明確な兆候です。
不足している機能: S3 Vectorsはまた、本番システムで開発者がしばしば期待するいくつかの機能を省いています。
Top-Kクエリは30件の結果に制限されています。
レコードごとの厳格なメタデータ制限。
ハイブリッド検索、マルチテナンシー、高度なフィルタリングサポート、その他多くのエンタープライズ対応機能がありません。
S3 Vectorsは安価で、クエリ頻度が低く、レイテンシが重要でないシンプルな大規模検索タスクには堅実に適しています。しかし、ワークロードがリアルタイム検索、ハイブリッド検索、またはマルチテナントアーキテクチャを必要とする場合、そのシンプルさはすぐにボトルネックになります。
Zilliz Cloud Tiered Storage: コスト効率が高く、高速で、本番対応
AWSはコスト削減のためにオブジェクトストレージとベクトル検索を組み合わせました。Zilliz Cloudは新しいTiered Storageによりそのアイデアをさらに進め、同じコスト効率を実現しながら、本格的な本番パフォーマンスを提供します。
オープンソースの Milvus 上に構築された Zilliz Cloud は、大規模 AI ワークロード向けに設計されたフルマネージドのベクトルデータベースです。その Tiered Storage アーキテクチャは、すべてのベクトルデータをオブジェクトストレージ(AWS S3 など)に保存しながら、各クラスターのローカル SSD とメモリをインテリジェントなキャッシュとして使用して、クエリとデータアクセスを高速化します。その結果、S3 の低コストと専用ベクトルデータベースの速度と柔軟性を両立します。
内部では、Tiered Storage は Hot(メモリ)、Warm(SSD)、Cold(オブジェクトストレージ)の 3 つのレイヤーを管理します。
Hot データ は、即時の応答時間を実現するためにメモリ内に保持されます。
Warm データ は、速度とコストのバランスを取るためにローカル SSD 上に配置されます。
Cold データ は、長期保持のためにオブジェクトストレージに効率的に保存されます。
このシステムは実際のクエリパターンに基づいて階層間でデータを自動的に移動し、本番テストで 90% を超えるキャッシュヒット率を維持します。実際には、ほとんどのクエリが高速レイヤーから直接処理されることを意味し、オブジェクトストレージの経済性とメモリ内の応答性を組み合わせます。
Zilliz Cloud Tiered Storage の実用的なユースケース
1. 大規模マルチテナント RAG/AI アプリ
多くの本番 AI システムは数百万のテナントにサービスを提供しますが、任意の時点でアクティブなのは通常 1~5% のごく一部にすぎません。AI コーディングアシスタント、チャットアプリ、カスタマーサポートのコパイロットなどを想像してください。
Tiered Storage により、Zilliz Cloud はアクティビティに基づいてストレージを自動的にバランス調整します。
非アクティブなテナントデータの約 95% はオブジェクトストレージに保持され、ストレージコストを生の S3 レベルに近づけます。
アクティブな 5% はメモリまたは SSD 上に存在し、進行中のセッション中に低レイテンシの取得を保証します。
2. 大規模・低頻度データ分析
自動運転、ロボティクスモデルのトレーニング、創薬などの領域では、ペタバイト規模のデータセットが生成されますが、そのクエリワークロードは、多くの場合軽量で、1 日あたり数件から数百件程度です。このようなケースでは、常時メモリ内ストレージは過剰です。
Zilliz Cloud の Tiered Storage は、頻繁にクエリされるサンプルを高速な階層にキャッシュしながら、Cold データをオブジェクトストレージに保持します。完全なメモリ内システムに比べてストレージコストを数分の一に削減しつつ、実用的なレイテンシを維持するため、研究チームは分析ワークフローを変更することなく、大規模なデータセットを効率的かつ手頃なコストで探索できます。
S3 Vectors から Zilliz Cloud にデータを移行する方法
Zilliz Cloud の Tiered Storage により、パフォーマンスのトレードオフなしに S3 レベルのコスト効率が得られるようになった今、次の疑問はシンプルです。データをどのように移行するのでしょうか?
簡単な例を使ってみましょう。AWS リージョン us-west-2 に、books という名前のベクトルインデックスの下で 200 件の書籍レコード を保存しているとします。各レコードには以下が含まれます。
768 次元のコンテンツベクトル
主キーとしての書籍タイトル
メタデータに保存された著者情報
前提条件
Docker がインストールされ、実行されています。
VTS を実行するノードが S3 Vectors と Zilliz Cloud の両方にアクセスできます。
IAM ユーザーまたはロールに
s3vectors:ListVectors権限が含まれています。
移行前の検証
VTS をデプロイする前に、S3 Vectors のデータとアクセスを確認してください。
import boto3
import os
aws_access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
aws_secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY")
s3vectors = boto3.client("s3vectors", region_name="us-west-2", aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key)
resp = s3vectors.list_vectors(vectorBucketName="vectors", indexName="books", returnMetadata=True, returnData=True)
for vector in resp["vectors"]:
print(vector)
200件のレコードが返されるはずです。
{'key': 'First foot situation land bad.', 'data': {'float32': [0.7183347940444946……]}, 'metadata': {'author': 'Wendy Jones'}}
{'key': 'Face industry bit true.', 'data': {'float32': [0.9061349630355835……]}, 'metadata': {'author': 'Steven Smith'}}
{'key': 'Republican agreement probably home choose see.', 'data': {'float32': [0.26946496963500977……]}, 'metadata': {'author': 'Misty Lynch'}}
{'key': 'Before arrive design soon finally discuss.', 'data': {'float32': [0.35728317499160767……]}, 'metadata': {'author': 'Mark Johnson'}}
…………
移行を開始する
1.最新のVTSイメージ(バージョン1.2.0以上)をプルします:
docker pull zilliz/vector-transport-service:v1.2.0
2.設定ファイルを作成します:
vim ./s3-vector_to_milvus.conf
3.以下の内容を追加します(必要に応じて変更してください):
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
S3Vector {
region = "us-west-2"
vector_bucket_name = "vector-bucket" # Name of your vector bucket
index_name = "books" # Name of your vector index
ak = "ak" # aws_access_key_id
sk = "sk" # aws_secret_access_key
}
}
sink {
Milvus {
url="https://in01-***.<region>.zilliz.com.cn:19530"
token="***"
database="default" # Target database
batch_size=1 # Number of records per batch (larger batches are faster but use more memory)
}
}
ファイルを保存します。
4.VTSコンテナを実行し、設定ファイルをマウントします:
docker run -v ./s3-vector_to_milvus.conf:/config/s3-vector_to_milvus.conf -it zilliz/vector-transport-service:v1.2.0 /bin/bash
5.コンテナ内でVTSプロセスを開始します:
./bin/seatunnel.sh --config /config/s3-vector_to_milvus.conf -m local
プロセスが完了するまで待ちます。完了すると、データはZilliz Cloudへ正常に転送されます。
移行後の検証
移行が完了したら、Zilliz Cloud Consoleでデータを確認します。
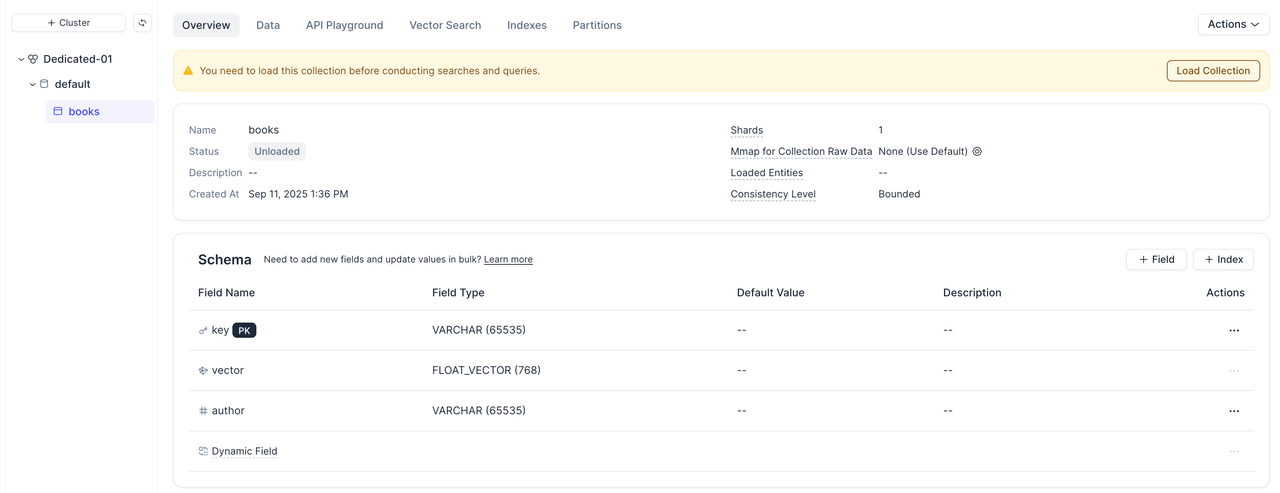
VTSはメタデータフィールドを自動的に検出し、各属性の列を作成します。keyフィールドは主キーとして使用されます。
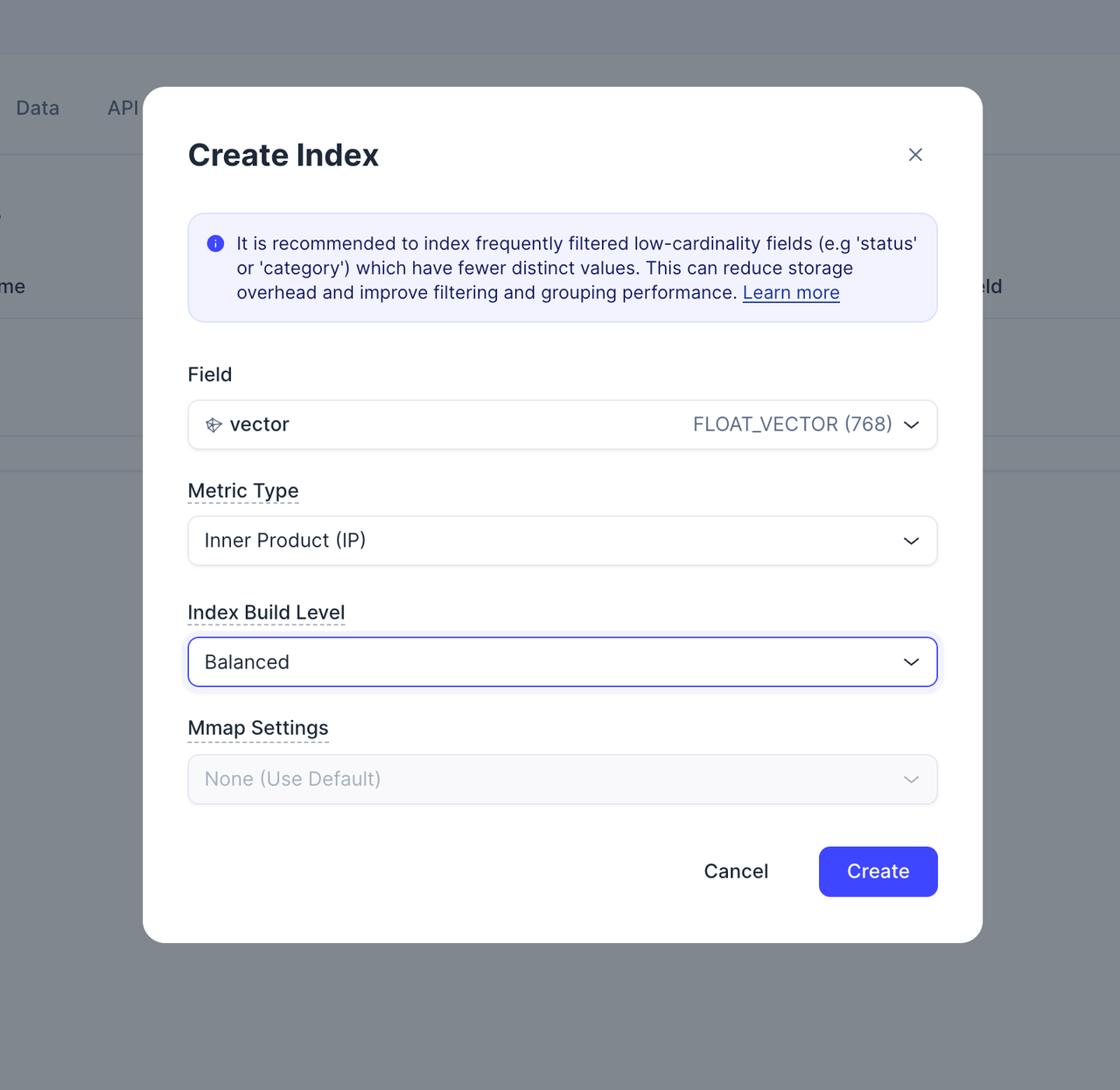
ベクトルフィールドにベクトルインデックスを作成します。
Load Collectionを実行してデータをプレビューします。
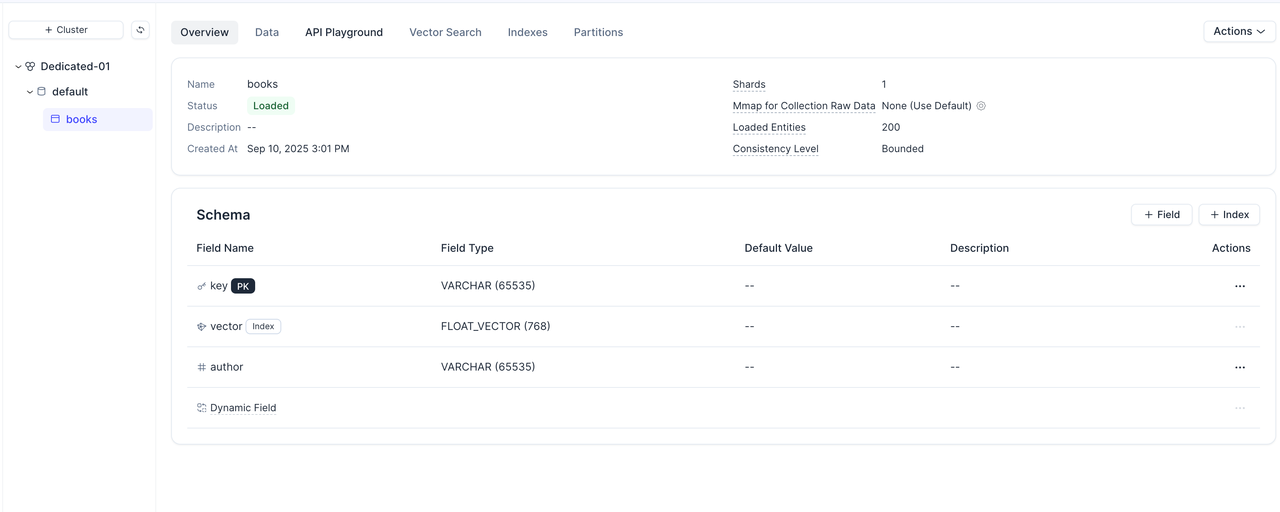
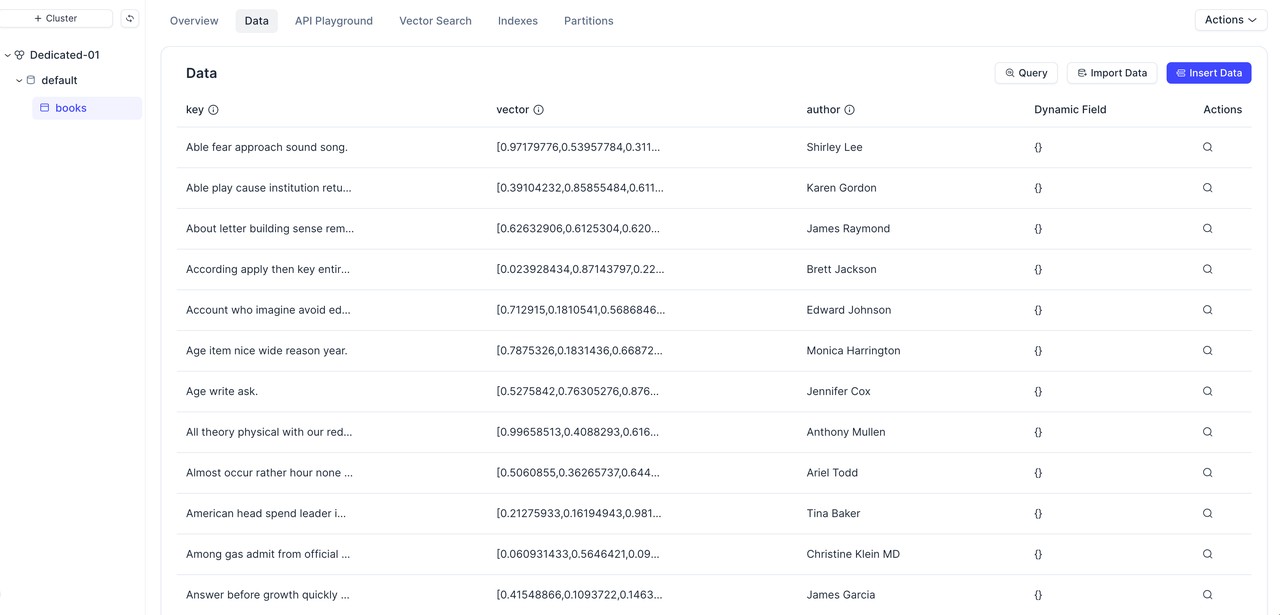
レコード数とその内容がS3 Vectorsのものと完全に一致していることを確認でき、移行が成功したことが分かります。
まとめ
S3 Vectorsは埋め込みをオブジェクトストレージに保存することでコストを低く抑えますが、パフォーマンス、再現率、エンタープライズ機能の面では不十分です。Zilliz Cloudは同じ発想をさらに推し進め、コスト面の利点を維持しながら、実際のAIアプリケーションに必要な速度、柔軟性、信頼性を追加します。
開発者にとって、これは手頃な価格とパフォーマンスのどちらかを選ぶ必要がなくなることを意味します。数十億のベクトルまでスケールし、高速ティアからアクティブなワークロードを提供し、それでもコールドデータをオブジェクトストレージにコスト効率よく保持できます — すべてを1つのマネージドプラットフォームで実現できます。
現在S3 Vectorsを使用している場合、移行はほんの数ステップで完了し、クエリ速度と運用のシンプルさにおけるメリットをすぐに実感できます。ぜひ試して、ご自身のデータでベンチマークし、Zilliz Cloudが大規模ベクトル検索で可能にすることを確認してください。
Zilliz Cloudを実際に体験する
Zilliz Cloudが本当に最適かまだ迷っていますか?無料でサインアップして、$100のクレジットを受け取り、世界をリードするマネージド型ベクトルデータベースを直接お試しください。
すでに別のベクトルデータベースを利用していますか?Zilliz Cloudは、Pinecone、Qdrant、Elasticsearch、PostgreSQL、OpenSearch、Weaviate、さらにはオンプレミスのMilvusからのシームレスな移行をサポートしているため、手間なくデータを移行できます。
移行について今後ご不明な点がある場合は、ドキュメントをご確認いただくか、お問い合わせください—Zilliz Cloudを最大限に活用できるようサポートいたします。

読み続けて

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.