




Comprendere il Deep Reinforcement Learning (DRL): Una guida completa
Risposta breve: Il Deep Reinforcement Learning (DRL) è un campo dell'IA in cui un agente impara a prendere decisioni interagendo con un ambiente e migliorando nel tempo in base al feedback o alle "ricompense." Il DRL combina il reinforcement learning (RL), un metodo di apprendimento per tentativi ed errori, con il deep learning, che consente all'agente di gestire dati complessi come immagini o letture di sensori. Il DRL può utilizzare reti neurali profonde per insegnare agli agenti a navigare in compiti complicati con input ad alta dimensionalità. È ampiamente utilizzato in applicazioni come la robotica e i giochi, dove i metodi di apprendimento tradizionali faticano a causa della complessità e della variabilità dell'ambiente.
Comprendere il Deep Reinforcement Learning (DRL): Una guida completa
Nel 2016, quando AlphaGo sconfisse il campione del mondo Lee Sedol a Go—un gioco con più mosse possibili degli atomi nell'universo—segnò un momento spartiacque nella tecnologia aziendale. Il segreto dietro questa vittoria? Deep Reinforcement Learning—un metodo che addestra i computer a migliorare attraverso la pratica, proprio come un tennista che perfeziona il proprio servizio dopo anni sul campo. Laddove i programmi informatici tradizionali faticano con cambiamenti imprevisti, questa tecnologia eccelle in situazioni che cambiano costantemente—dal dirigere robot in magazzini affollati al prendere decisioni rapide nel trading azionario. Questo nuovo approccio al machine learning apre porte alle aziende, affrontando problemi che un tempo erano troppo complessi perché il software tradizionale potesse risolverli.
Questa guida offre un'esplorazione approfondita del deep reinforcement learning, evidenziando i concetti chiave, le sue varie applicazioni, i suoi vantaggi e le sfide che possono emergere nella sua implementazione.
Cos'è il Deep Reinforcement Learning?
Deep Reinforcement Learning (DRL) combina due efficaci tecniche di IA, Reinforcement Learning (RL) e Deep Learning, consentendo agli agenti IA di apprendere azioni ottimali attraverso tentativi ed errori in ambienti complessi. Nel RL, un agente interagisce con il proprio ambiente e adatta il suo comportamento in base a ricompense e strategie di apprendimento per massimizzare le ricompense a lungo termine. Il deep learning aggiunge la capacità di gestire rappresentazioni dettagliate dello stato utilizzando reti neurali.
Ad esempio, un robot che naviga in un labirinto inizialmente si muove in modo casuale, ma col tempo impara a raggiungere l'obiettivo in modo efficiente attraverso il feedback. Il DRL aiuta gli agenti ad adattarsi ad ambienti dinamici e a risolvere problemi complessi senza istruzioni dettagliate. È utile nei videogiochi, nelle auto a guida autonoma e nelle raccomandazioni personali. Combinando Reinforcement Learning e Deep Learning, gli agenti DRL possono gestire efficacemente compiti complessi del mondo reale.
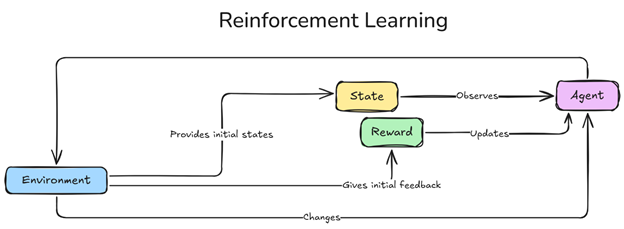 Figura 1 Framework del Reinforcement Learning.png
Figura 1 Framework del Reinforcement Learning.png
Come funziona il Deep Reinforcement Learning
Per capire come funziona il DRL, è importante conoscerne i componenti chiave:
Agente
Ambiente
Stato
Azioni e Ricompense
Politica
Agente
L'agente è il decisore incaricato di navigare nell'ambiente e fare scelte per massimizzare le ricompense cumulative nel tempo. Attraverso interazioni ripetute (episodi di apprendimento), l'agente affina la propria strategia in base al feedback, adattando il suo comportamento per ottenere successo a lungo termine. Proprio come un giocatore in un gioco, le azioni dell'agente sono guidate da una politica—un insieme di regole apprese nel tempo per migliorare le prestazioni e raggiungere risultati ottimali.
Ambiente
L'ambiente è lo spazio strutturato all'interno del quale l'agente opera, definendo possibili stati, azioni e ricompense. Reagisce a ogni azione dell'agente, fornendo feedback che influenza le decisioni future dell'agente e modella il suo processo di apprendimento.
Stato
Lo stato rappresenta un’istantanea dell’ambiente in un particolare momento, contenente informazioni importanti per il processo decisionale dell’agente. Ad esempio, uno stato potrebbe includere la posizione di un agente e gli ostacoli in un labirinto oppure la velocità di un veicolo e la vicinanza ad altre auto. Ogni stato aiuta l’agente a valutare la propria situazione e a selezionare l’azione più vantaggiosa.
Azioni e ricompense
Le azioni rappresentano le scelte di un agente in ciascuno stato, dirigendo il suo percorso attraverso l’ambiente. Le azioni possono essere:
Azioni discrete: Opzioni limitate, come muoversi su, giù, a sinistra o a destra, negli ambienti a griglia rendono più facile per gli agenti esplorare e sviluppare policy.
Azioni continue: Queste includono un intervallo di valori, come regolare velocità o angolo, che richiedono modelli avanzati per gestire la maggiore complessità.
L’agente mira a compiere azioni ottimali nel tempo e a massimizzare le ricompense.
Le ricompense forniscono feedback per guidare l’apprendimento dell’agente. Le ricompense positive segnalano azioni riuscite, mentre le ricompense negative penalizzano gli errori. Le ricompense possono includere:
Ricompense immediate: Vengono assegnate direttamente dopo un’azione, come ottenere punti per aver catturato un pezzo dell’avversario negli scacchi.
Ricompense ritardate: Ottenute dopo aver completato una sequenza di azioni, come attraversare un labirinto.
È importante progettare la struttura delle ricompense, nota come reward shaping. Ad esempio, ricompense intermedie lungo un percorso complesso possono accelerare l’apprendimento, motivando l’agente a compiere passaggi specifici verso l’obiettivo finale.
 Figure- Reinforcement Learning architecture.png
Figure- Reinforcement Learning architecture.png
Figura: architettura del Reinforcement Learning
Il processo di apprendimento
Il processo di apprendimento o addestramento del deep reinforcement learning è un ciclo iterativo di interazione, feedback e miglioramento che coinvolge:
Esplorazione
Sfruttamento
Reti neurali profonde
Backpropagation
Esplorazione
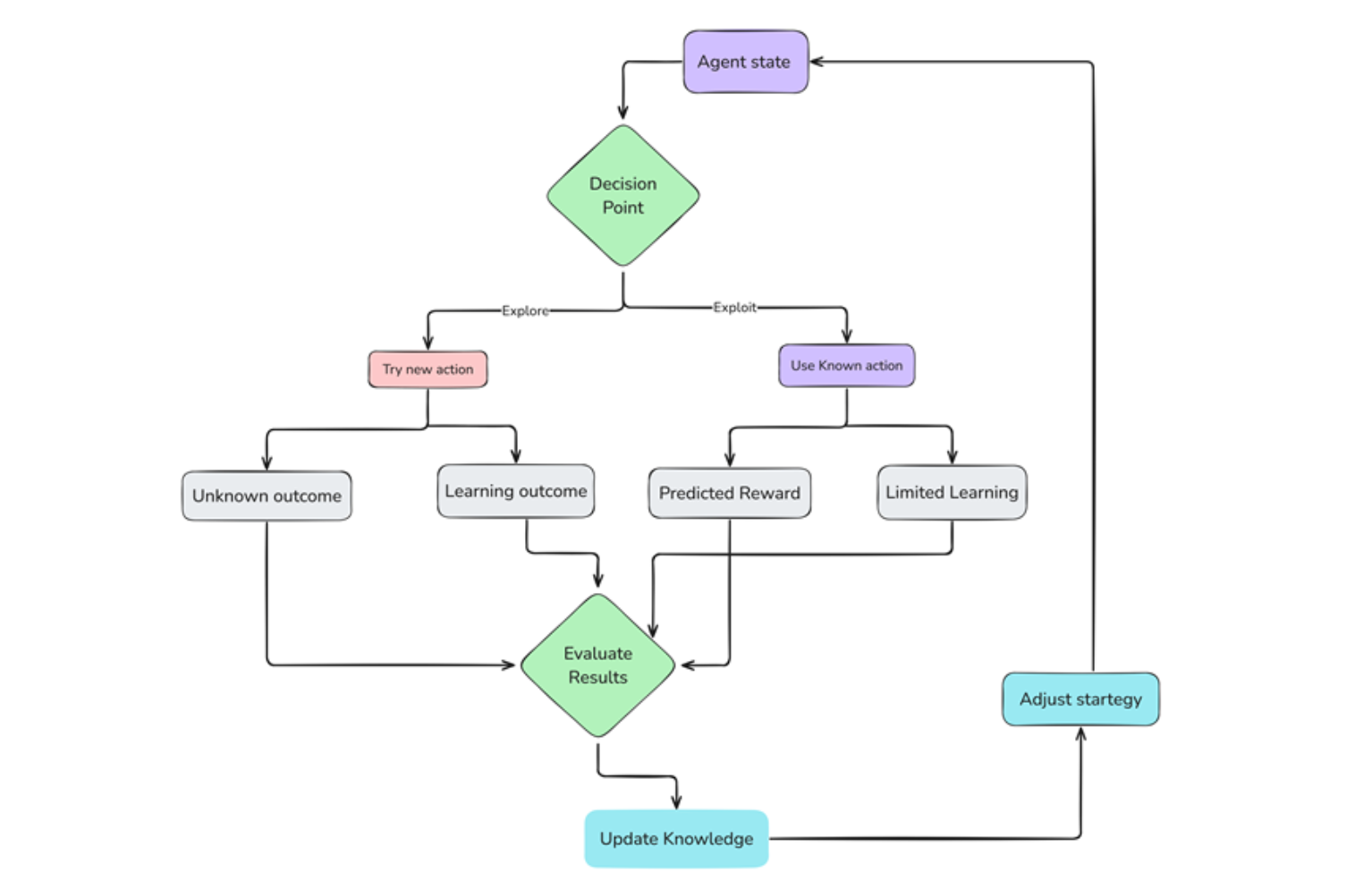
Inizialmente, l’agente non conosce l’ambiente. Comincia esplorando casualmente, provando azioni diverse e osservandone le conseguenze. Questa fase di esplorazione è importante per raccogliere informazioni sull’ambiente e scoprire azioni gratificanti.
Sfruttamento
Man mano che l’agente esplora e accumula esperienza, inizia a identificare azioni che portano a ricompense positive. Quindi sfrutta questa conoscenza, scegliendo quelle azioni più frequentemente per massimizzare le proprie ricompense.
Reti neurali profonde
L’agente utilizza reti neurali profonde per approssimare la policy dell’agente e la funzione di valore.
Rete di policy: Questa rete prende lo stato corrente come input e restituisce la probabilità di intraprendere diverse azioni.
Rete di valore: Questa rete stima il valore a lungo termine dell’essere in un determinato stato, aiutando l’agente a prendere decisioni che portano a ricompense cumulative più elevate. Queste reti neurali consentono all’agente di apprendere schemi e relazioni ambientali complessi, aiutandolo a prendere decisioni più intelligenti.
 Exploration vs Exploitation Process .png
Exploration vs Exploitation Process .png
Figura 3 Processo di esplorazione vs sfruttamento
Backpropagation
La backpropagation, abbreviazione di "backward propagation of errors", è un algoritmo chiave nell’addestramento delle reti neurali. Regola i pesi in una rete neurale per minimizzare l’errore nelle previsioni.
La retropropagazione aiuta gli agenti a migliorare i loro modelli decisionali apprendendo dal feedback. Quando un agente compie un’azione, riceve un feedback su quanto quell’azione sia stata buona o cattiva (sotto forma di ricompensa). La retropropagazione quindi regola i pesi della rete neurale, riducendo l’errore tra gli esiti previsti e le ricompense effettive. Applicando ripetutamente la retropropagazione, la rete neurale impara ad approssimare meglio le funzioni di valore o di policy, portando a decisioni più accurate. Questo processo consente all’agente di migliorare gradualmente la propria comprensione dell’ambiente e di prendere decisioni sempre più ottimali nel tempo, il che è essenziale per padroneggiare compiti complessi in ambienti dinamici e ad alta dimensionalità.
Algoritmi popolari nel Deep Reinforcement Learning
Il DRL impiega una varietà di algoritmi, ciascuno progettato per affrontare diverse sfide nel processo di apprendimento. Ecco alcuni dei metodi più ampiamente utilizzati:
Q-Learning: Il Q-Learning è uno degli algoritmi fondamentali dell’apprendimento per rinforzo. Stima il valore delle coppie stato-azione, denominate Q-values, aiutando l’agente a determinare quali azioni siano preferibili in determinati stati. L’algoritmo aggiorna questi Q-values in base alle ricompense immediate e alle ricompense future previste, affinando gradualmente le scelte dell’agente per favorire azioni con un valore a lungo termine più elevato.
Deep Q-Networks (DQN): DQN migliora il Q-learning utilizzando reti neurali per approssimare i Q-values. Questo approccio rende le DQN efficaci in ambienti complessi come l’IA nei giochi, la navigazione robotica e la guida autonoma.
Policy Gradients: A differenza dei metodi basati sul valore, gli algoritmi policy gradient ottimizzano direttamente la policy di un agente regolando i pesi di una rete neurale in base alle ricompense ricevute. Questo approccio consente all’agente di migliorare le prestazioni aumentando la probabilità di azioni riuscite, il che è particolarmente importante nei compiti di controllo che richiedono regolazioni precise, come la manipolazione di un braccio robotico.
Actor-Critic Methods: Gli approcci ibridi combinano i punti di forza dei metodi basati sulla policy, che mirano a stimare il valore di ciascuna azione in un determinato stato, e dei metodi basati sul valore, che si concentrano sull’apprendimento diretto della policy ottimale. In questo framework, l’actor è responsabile della selezione delle azioni, mentre il critic valuta queste azioni e fornisce feedback. Questo feedback consente miglioramenti continui alla policy.
Confronto del Deep Reinforcement Learning con altri concetti
Il Deep Reinforcement Learning (DRL) viene spesso confrontato con altri approcci di IA. Per chiarire differenze e somiglianze, analizziamo gli aspetti chiave:
| Aspetto | Apprendimento per rinforzo profondo (DRL) | Apprendimento per rinforzo regolare (RL) | Apprendimento supervisionato | Apprendimento non supervisionato | |
| Concetto di base e gestione dei dati | Combina l'RL con reti neurali profonde; elabora dati complessi e ad alta dimensionalità | Si concentra sull'RL con modelli più semplici; funziona bene in ambienti a bassa dimensionalità | Apprende da dati etichettati con output predefiniti; si basa su dataset etichettati | Trova pattern in dati non etichettati; lavora con dataset non etichettati | |
| Processo di apprendimento | Tentativi ed errori tramite interazione con l'ambiente. | Tentativi ed errori tramite feedback dall'ambiente. | Apprende pattern da coppie input-output etichettate. | Identifica cluster o strutture nei dati. | |
| Obiettivo | Massimizzare le ricompense cumulative nel tempo. | Massimizzare le ricompense cumulative nel tempo. | Prevedere gli output in base ai dati di input. | Scoprire pattern nascosti o raggruppamenti nei dati. | |
| Applicazioni | Compiti complessi: IA per giochi, robotica, veicoli autonomi. | Sistemi di controllo di base e semplici compiti decisionali. | Classificazione, regressione, modellazione predittiva. | Clustering, riduzione della dimensionalità, rilevamento delle anomalie. |
Vantaggi e sfide del Deep Reinforcement Learning
Il deep reinforcement learning offre molte possibilità, ma è importante sapere in cosa eccelle e dove potrebbe mostrare dei limiti. Esaminiamo alcuni dei principali vantaggi e sfide del DRL.
Vantaggi:
Adattabilità: Un vantaggio chiave del DRL è la sua adattabilità. Gli agenti DRL possono gestire situazioni nuove e impreviste senza richiedere programmazione aggiuntiva. Ad esempio, un veicolo autonomo basato su DRL può rispondere a cambiamenti improvvisi della strada, come ostacoli o condizioni meteorologiche avverse, regolando il proprio comportamento per navigare in sicurezza.
Decisioni ottimali: Il DRL consente anche un processo decisionale più intelligente e spesso più efficace. A differenza dei sistemi tradizionali basati su regole, i modelli DRL possono scoprire strategie che persino i progettisti umani potrebbero trascurare. In finanza, ad esempio, il DRL è stato applicato con successo per creare trading bot che prendono spesso decisioni più redditizie rispetto ai sistemi convenzionali.
Potenziale di automazione: Il DRL consente l'automazione di attività in settori come la movimentazione delle merci, l'assistenza medica e il supporto ai clienti. In questi ambiti spesso complessi e in continuo cambiamento, il DRL aiuta a semplificare le cose automatizzandole.
Sfide:
Efficienza dei campioni: Una delle maggiori sfide del DRL è la sua richiesta di enormi quantità di dati di addestramento. I modelli DRL in genere richiedono dati estesi per funzionare bene, il che può essere costoso e richiedere molto tempo da raccogliere. Tecniche come l'experience replay aiutano consentendo ai modelli di apprendere dai dati passati, ma sono ancora necessari miglioramenti nell'efficienza dei dati per rendere il DRL più pratico.
Progettazione delle ricompense: Un'altra sfida risiede nella progettazione di funzioni di ricompensa efficaci. Impostare le ricompense giuste è fondamentale perché ricompense progettate male possono portare a comportamenti degli agenti indesiderati e talvolta problematici. Di conseguenza, la progettazione delle ricompense nel DRL richiede un'attenta pianificazione per garantire che gli agenti agiscano in modi allineati con gli obiettivi previsti.
Stabilità e convergenza: Infine, l'addestramento del DRL può essere instabile. A volte, i modelli rimangono bloccati in strategie non ideali o non riescono a raggiungere una soluzione stabile. Migliorare la stabilità dell'addestramento è essenziale per rendere i modelli DRL più affidabili, soprattutto per applicazioni ad alto rischio in cui la coerenza è fondamentale.
Applicazioni reali del Deep Reinforcement Learning
Ora che abbiamo esplorato il funzionamento del deep reinforcement learning (DRL), spostiamo la nostra attenzione sulle sue applicazioni pratiche. Il DRL viene utilizzato per risolvere problemi reali in vari domini. Tra cui:
Giochi: Il DRL ha reso possibile la creazione di agenti AI avanzati che eccellono in giochi come Chess, Go e Dota 2. Per chi è interessato all'esplorazione pratica, Unity ML-Agents offre un toolkit accessibile per sperimentare l'apprendimento basato sui giochi.
Robotica: Nella robotica, il DRL insegna alle macchine abilità come la navigazione e la manipolazione di oggetti. Il DRL si dimostra altamente efficace nei magazzini, consentendo ai robot di adattarsi a nuovi layout e a compiti mutevoli, aumentando l'efficienza delle operazioni.
Veicoli autonomi: Nelle auto a guida autonoma, il DRL svolge un ruolo cruciale nel prendere decisioni in frazioni di secondo per cambiare corsia, evitare ostacoli o regolare la velocità. Waymo, ad esempio, utilizza il DRL per aiutare i suoi veicoli a fare scelte sicure in situazioni di traffico complesse.
Trading finanziario: Il DRL è anche ampiamente utilizzato in finanza per sviluppare trading bot che rispondono ai cambiamenti del mercato. Utilizzando approcci come il Deep Q-Learning, i trading bot basati su DRL analizzano trend storici e dati in tempo reale per prendere decisioni informate di acquisto, mantenimento o vendita, ottenendo spesso risultati migliori rispetto alle strategie di trading manuale.
Raccomandazioni personalizzate: Il DRL alimenta sistemi di raccomandazione sempre più avanzati. Per fornire raccomandazioni su misura, gli algoritmi DRL analizzano il comportamento e le preferenze degli utenti su servizi di streaming, negozi online e piattaforme di social media. Osservando le azioni degli utenti, il DRL può raccomandare contenuti o prodotti che si allineano più strettamente alle preferenze individuali.
Domande frequenti sul Deep Reinforcement Learning
- Come apprende un agente nel deep reinforcement learning?
Nel DRL, un agente apprende compiendo azioni in un ambiente e ricevendo feedback sotto forma di ricompense. L’agente utilizza l’esplorazione (provando nuove azioni) per scoprire strategie efficaci e lo sfruttamento (utilizzando azioni note) per massimizzare le ricompense. Le reti neurali profonde aiutano l’agente a generalizzare dalle sue esperienze e ad adattarsi a scenari complessi.
- In che modo i modelli di deep reinforcement learning bilanciano esplorazione e sfruttamento?
I modelli DRL bilanciano l’esplorazione (provando nuove azioni per scoprire strategie migliori) e lo sfruttamento (utilizzando azioni note per massimizzare le ricompense) tramite algoritmi come epsilon-greedy o Thompson Sampling. Queste tecniche aiutano a mantenere un equilibrio, assicurando che l’agente scopra nuove strategie mentre massimizza le ricompense note.
- Come funzionano le funzioni di valore nel deep reinforcement learning?
Le funzioni di valore stimano la ricompensa attesa derivante dall’essere in un determinato stato (funzione valore-stato) o dal compiere un’azione specifica in un dato stato (funzione valore-azione). Aiutano l’agente a dare priorità a stati e azioni che portano a ricompense più elevate, guidando il processo decisionale.
- Come può essere utilizzato il DRL con Milvus per applicazioni di IA?
Milvus può archiviare e gestire le rappresentazioni di stato ad alta dimensionalità generate dagli agenti DRL. Può fungere da replay buffer per esperienze passate o assistere nell’archiviazione delle rappresentazioni di stato, migliorando l’efficienza dell’ottimizzazione della policy e della stima del valore.
- Quali sono le preoccupazioni etiche legate all’uso del deep reinforcement learning?
Le preoccupazioni etiche includono potenziali bias nei dati di addestramento, comportamenti indesiderati derivanti da funzioni di ricompensa progettate in modo inadeguato e problemi di equità in applicazioni sensibili. Per mitigare questi rischi, è fondamentale implementare test robusti, trasparenza e IA spiegabile.
Risorse correlate
Per ulteriori approfondimenti, considera queste risorse:
Paper: [1811.12560] Un’introduzione al Deep Reinforcement Learning
Comprendere la regolarizzazione delle reti neurali e le principali tecniche di regolarizzazione
Rendere il Machine Learning più accessibile per gli sviluppatori
Evoluzione della ricerca: dal matching di parole chiave alla ricerca vettoriale e alla GenAI
Introduzione alla ricerca di similarità vettoriale - Zilliz blog
- Cos'è il Deep Reinforcement Learning?
- Come funziona il Deep Reinforcement Learning
- Algoritmi popolari nel Deep Reinforcement Learning
- Confronto del Deep Reinforcement Learning con altri concetti
- Vantaggi e sfide del Deep Reinforcement Learning
- Applicazioni reali del Deep Reinforcement Learning
- Domande frequenti sul Deep Reinforcement Learning
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente