




Conditional Variational Autoencoders (CVAEs): Generative Models with Conditional Inputs

Conditional Variational Autoencoders (CVAEs): Generative Models with Conditional Inputs
Have you ever wondered how AI can generate specific, realistic images or data based on a condition, like creating an image of a cat in a certain style?
Variational Autoencoders (VAEs) are powerful generative models but lack control over data attributes. Conditional Variational Autoencoders (CVAEs) overcome this limitation by incorporating conditions, such as labels or attributes, into both the encoder and decoder. This enables CVAEs to generate data tailored to specific requirements, making them ideal for tasks like targeted image creation or personalized content generation, expanding their potential across various fields.
Let's explore how Conditional Variational Autoencoders (CVAEs) work, their advantages, and how they change how data is generated across various domains.
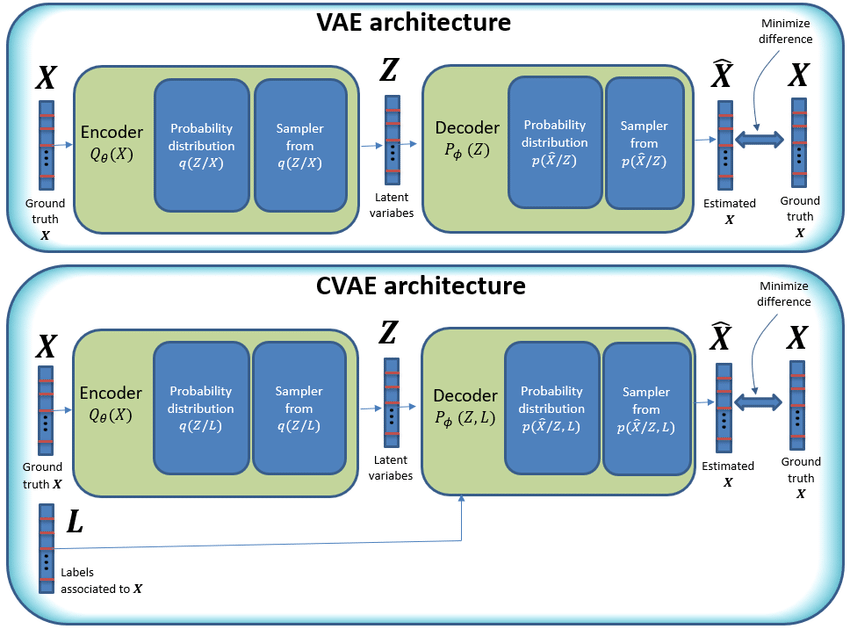
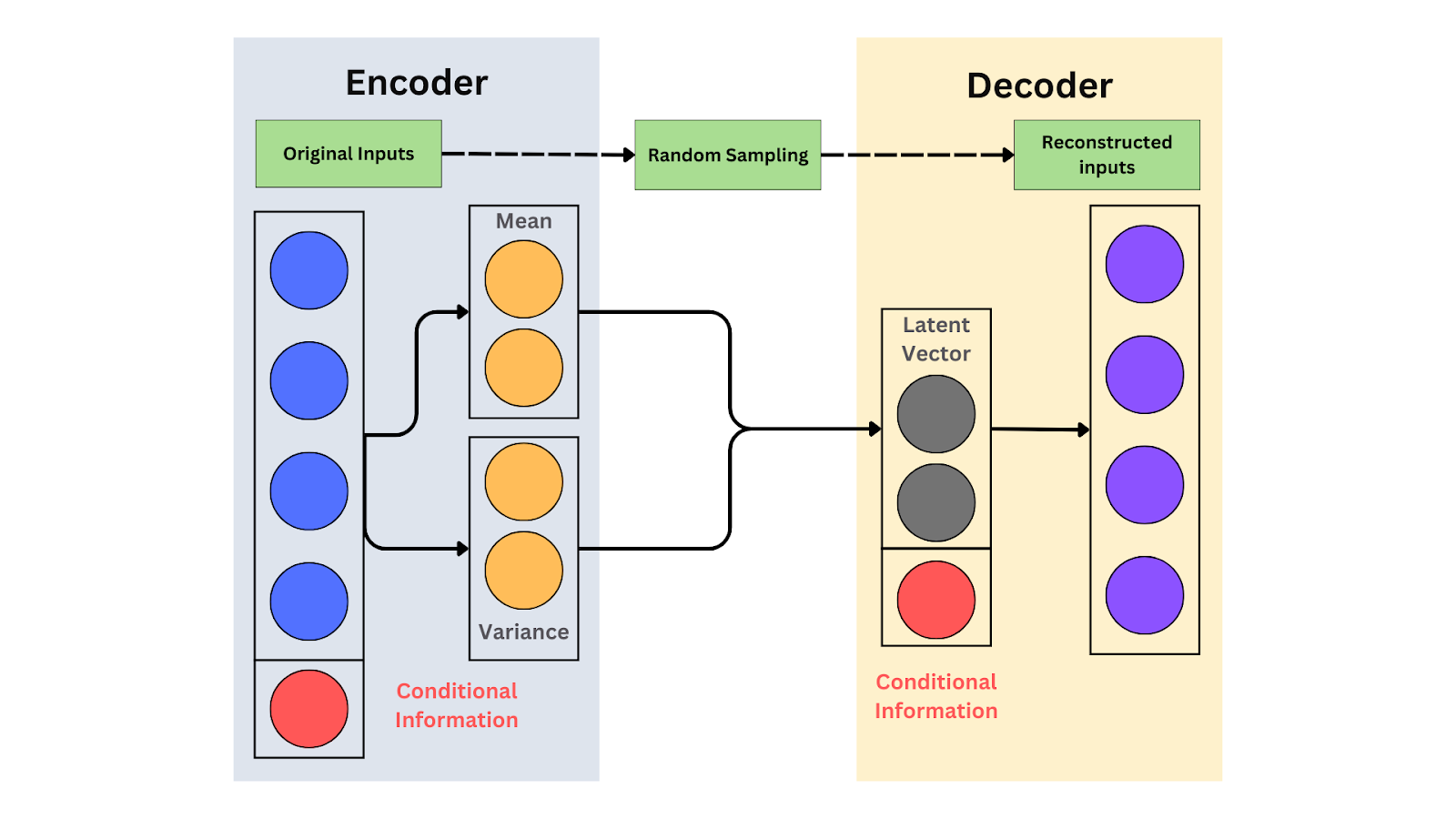 The schematic of a CVAE.png
The schematic of a CVAE.png
The schematic of a CVAE
What are Conditional Variational Autoencoders (CVAE) ?
A Conditional Variational Autoencoder (CVAE) is an extension of the Variational Autoencoder (VAE) that incorporates conditional inputs, such as labels or attributes, to guide the data generation process. The generated data meets specific requirements by conditioning the model. For example, if you want to create images of cats or dogs, you can provide the label "cat" or "dog" to guide the generation. This allows the model to produce the desired output based on the condition.
CVAEs are important because they provide control over data generation. The conditional inputs ensure that outputs match predefined features. This makes them useful for tasks such as image generation for fashion design, where models can create clothing items in different colors or styles, and in targeted simulations, where specific scenarios need to be generated based on certain conditions.
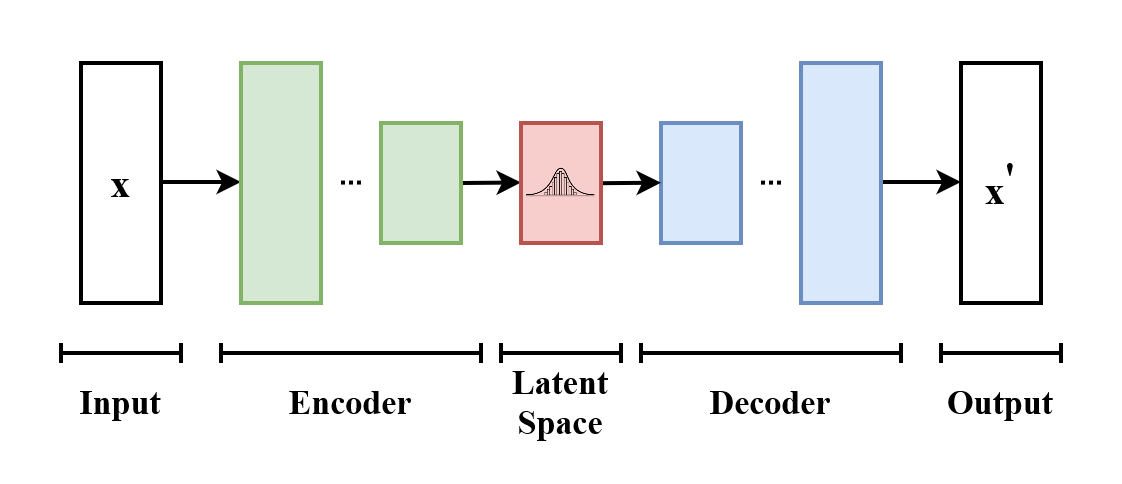
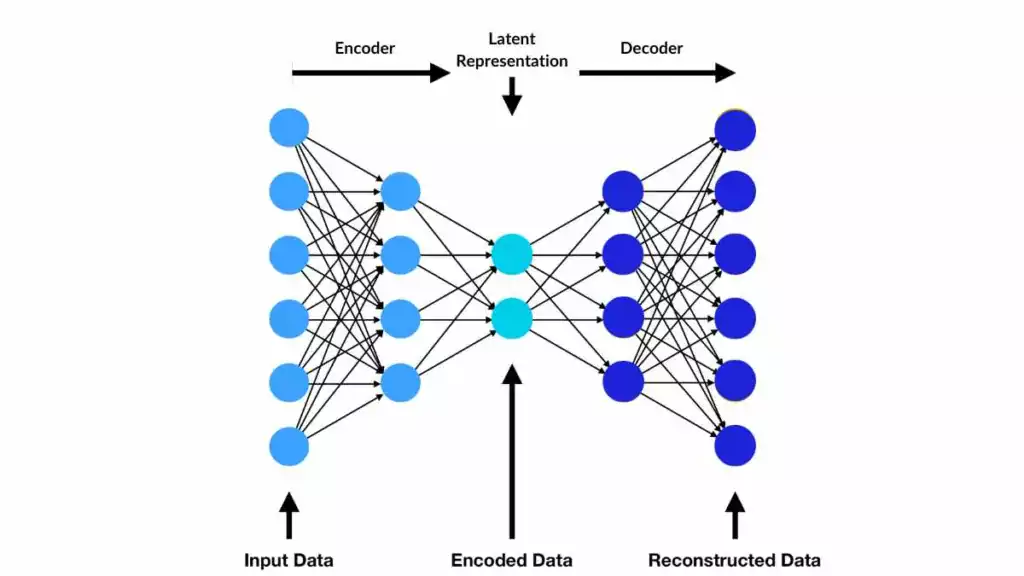 Autoencoder structure underlies VAEs and CVAEs.png
Autoencoder structure underlies VAEs and CVAEs.png
Autoencoder structure underlies VAEs and CVAEs | Source
Understanding Variational Autoencoders (VAEs)
Before we deep dive into CVAEs, let’s discuss the concept of Variational Autoencoders (VAEs). VAEs are generative models that learn to represent complex data distributions in a continuous latent space to generate new data samples.
VAEs contain two main components: an encoder and a decoder. The encoder compresses input data into a latent space, capturing its key features. The decoder reconstructs the input or generates new samples from this latent representation. A loss function plays a key role in training by balancing reconstruction accuracy and latent space regularity. Regularization ensures the latent space is smooth and structured, enabling coherent data generation.
Loss Function
The loss function in Variational Autoencoders (VAEs) consists of two main components: reconstruction loss and KL divergence.
- Reconstruction Loss measures how well the model reproduces the input data. It is typically calculated using Mean Squared Error (MSE) or Binary Cross-Entropy. The equation for reconstruction loss is:
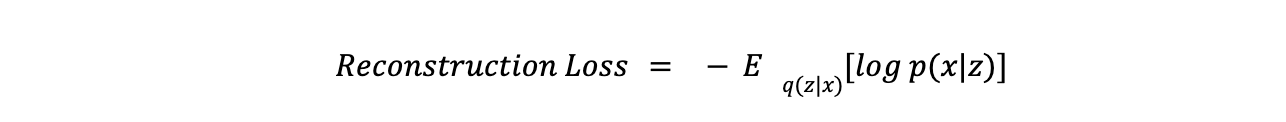
- KL Divergence, short for Kullback-Leibler divergence, is a statistical measure of how one probability distribution differs. In the context of VAEs, it ensures the latent distribution 𝒒(𝔃∣𝔁) (learned by the encoder) stays close to the prior 𝒑(𝔃), which is typically a standard Gaussian distribution. The equation for KL divergence is:
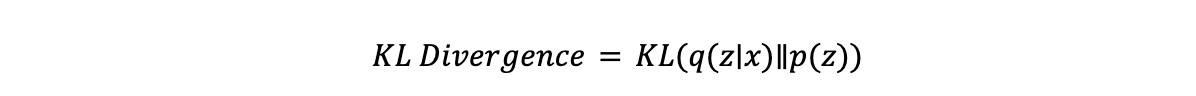
The overall loss function is a weighted sum of these two terms:
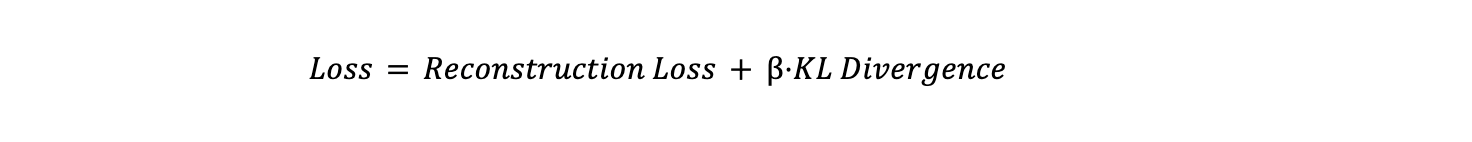
Where β is a hyperparameter that controls the trade-off between the reconstruction loss and the KL divergence. A higher β gives more importance to the latent space regularization, while a lower value allows the model to focus more on accurate reconstruction. This balance is crucial for ensuring that the model both generates accurate data and learns a meaningful, well-behaved latent space.
Regularization
Regularization uses Kullback-Leibler divergence to align the latent space with the prior distribution, ensuring that latent variables follow a Gaussian distribution. This smooths the latent space, enabling interpolation and meaningful sampling. Points close to each other in the latent space generate similar outputs. Regularization also improves generalization by preventing the model from overfitting to the training data. For example, in fashion design, regularization ensures that diverse clothing designs are generated while maintaining realistic patterns and styles. It helps create variations in clothing types, colors, and textures, without producing unrealistic outputs. By keeping the latent space structured, it generates designs that align with current trends but are different in their own way.
 Structure of a Variational Autoencoder (VAE) |.png
Structure of a Variational Autoencoder (VAE) |.png
Structure of a Variational Autoencoder (VAE) | Source
{kind=link}
How CVAE Improves VAE with Conditional Inputs?
CVAEs extend VAEs by adding conditional inputs, such as class labels, to guide data generation. The encoder processes both the input data and the condition. It maps them into a joint latent space, capturing the data and the condition combined. The decoder then uses this latent representation, a compressed data version, along with the condition to generate new samples.
For example, if the condition is "red sneakers," the decoder generates an image of red sneakers. The condition ensures the output matches specific requirements. Like VAEs, CVAEs use KL divergence to regularize the latent space and create a smooth distribution.
VAEs rely only on input data variations, limiting control over the output. CVAEs use labels or attributes to guide the generation process. This allows targeted and specific outputs. For example, in a CVAE trained on MNIST, the condition could be a digit label like "5." Given the label and an input, the model generates a specific "5." A VAE, in contrast, might generate any random digit depending on the latent space.
CVAEs are ideal for tasks like generating images with specific features or personalizing content. For instance, a CVAE can generate a sneaker design based on a user’s color, size, and style preferences, improving customization and user experience.
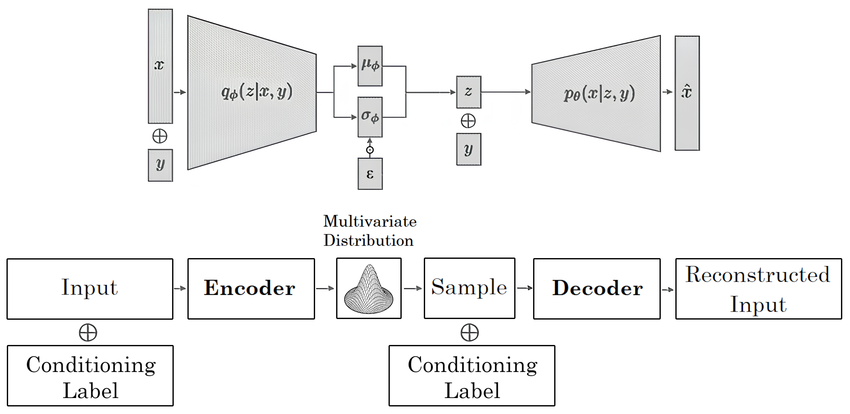 Conditional Variational Autoencoder (CVAE) Architecture.png
Conditional Variational Autoencoder (CVAE) Architecture.png
Conditional Variational Autoencoder (CVAE) Architecture | Source
Key Terms:
Latent Space: The latent space is a high-dimensional, compressed representation of data. It captures essential features of input data, like pose or color, in a compact form. For example, an image of a face could be compressed into a vector representing age or expression. The space typically follows a known distribution (e.g., Gaussian), allowing the generation of new, similar data points by sampling from this distribution. This representation enables the model to manipulate or interpolate between data points effectively.
Encoder: The encoder converts input data into a probabilistic latent representation. It maps input 𝔁 (like an image) to a distribution (mean 𝜇, variance 𝝈2) over the latent space. For example, for a cat image, the encoder outputs a distribution of features like color and breed. A latent vector is sampled from this distribution. The encoder learns how to efficiently compress data while preserving essential features.
Decoder: The decoder takes a latent variable 𝔃 and reconstructs or generates data. It maps the latent vector, a compressed version of the data, back to the original data space. For instance, the decoder generates an image of a cat from a latent vector representing cat features. The function is denoted as 𝒑(𝔁∣𝔃), where 𝔁 is the generated data. The decoder can create diverse outputs by learning from the latent variables, even for unseen data.
Conditional Inputs: Conditional inputs provide extra information (e.g., labels) that guide data generation. In CVAE, labels like "cat" help generate specific outputs, like cat images. The encoder and decoder use these inputs to create controlled outputs. For example, the encoder becomes 𝒒(𝔃∣𝔁,𝔂), and the decoder is 𝒑(𝔁∣𝔃,𝔂). These inputs ensure the model generates data tailored to the given conditions, enhancing flexibility.
- KL Divergence: KL Divergence measures how different the encoder's learned distribution is from the prior distribution (usually a Gaussian). It encourages the encoder to generate latent variables close to the prior, ensuring a structured latent space. The formula is:
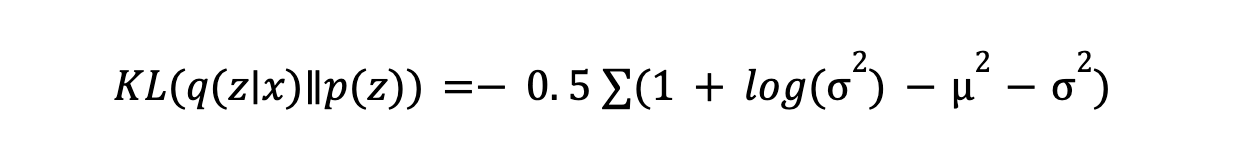
Minimizing KL divergence helps maintain a well-behaved latent space for data generation. This regularization technique ensures that the latent variables are distributed in a way that makes sampling and generating new data points reliable.
CVAEs vs. VAEs vs. GANs
This section compares Variational Autoencoders (VAEs) with Conditional Variational Autoencoders (CVAEs) and Generative Adversarial Networks (GANs). All are generative models, but they have several key differences.
The following table highlights the differences in their mechanisms, flexibility, and use cases.
| Aspect | VAE (Variational Autoencoder) | CVAE (Conditional Variational Autoencoder) | GANs (Generative Adversarial Networks) |
| Core Mechanism | Encodes input data into a compressed latent space and generates new data. | Similar to VAE, it incorporates conditional inputs (e.g., labels) to guide generation. | Composed of two networks: a generator creates data, and a discriminator evaluates it. |
| Input Data | Only the data itself is fed into the encoder. | Conditional data (e.g., class labels and attributes) is also used in the encoder. | Uses random noise as input for the generator, while the discriminator evaluates generated data. |
| Latent Representation | Represents the entire data distribution, providing a smooth, continuous latent space. | Latent space is conditioned on input data, providing more control over the generated output. | Latent space is learned during training, with no explicit control over specific features. |
| Generation Control | Generation is based purely on the latent space, with no external controls. | Conditional data allows the generation of data based on specific attributes (e.g., generating images of specific categories like “cat” or “dog”). | The generator “competes” with the discriminator, improving the generated data by “fooling” the discriminator. |
| Flexibility | Good for general-purpose data generation and anomaly detection. | Ideal for scenarios where controlled generation based on specific attributes is required. | Very flexible in generating realistic samples, but less control over specific outputs. |
| Training Data | It can be trained on a broad dataset with no explicit conditions. | Additional labeled or conditional data is required to guide the generation process. | Requires adversarial training with both generator and discriminator competing. |
| Use Cases | Data generation (e.g., generating faces), anomaly detection, and interpolating data points. | Controlled image generation (e.g., generating specific objects or conditions like color or style), semi-supervised learning. | High-quality image generation, image-to-image translation, style transfer, and data augmentation. |
| Key Advantages | Simpler to train, with no need for external conditions. | Allows generation of highly specific outputs, offering better control over generated data. | Generates highly realistic images and diverse data, with no need for explicit labels. |
| Example Application | Generating random images of faces. | Generating images of faces with specific attributes like age, gender, or expression. | Generating realistic images of human faces, generating art, or translating images from one style to another. |
 Comparison of CVAE with a typical VAE architecture.png
Comparison of CVAE with a typical VAE architecture.png
Comparison of CVAE with a typical VAE architecture | Source
 Comparison of the architectures of (A) VAEs and (B) GANs.png
Comparison of the architectures of (A) VAEs and (B) GANs.png
Comparison of the architectures of (A) VAEs and (B) GANs | Source
Benefits and Challenges of Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) offer significant advantages in generative modeling, but they also present challenges that need to be addressed. Let’s first discuss the benefits of using VAEs.
Conditional Generation: CVAEs can generate new samples based on specific conditions, making them useful for tasks like generating images with certain features or creating personalized content. This adds flexibility and versatility to various applications.
Meaningful Representations: Conditional VAEs (CVAEs) learn meaningful latent representations from the input, enabling better understanding and manipulation of data structures. This is particularly beneficial for tasks like feature extraction and analysis.
Customization: CVAEs can produce data tailored to specific needs, enabling customized recommendations and targeted content. This makes them highly valuable in areas like advertising and personalized user applications.
Data Augmentation: CVAEs can be used to augment datasets by generating diverse and realistic synthetic data. This capability helps improve the performance of machine learning models, especially in scenarios with limited or imbalanced datasets.
Now, let’s discuss the challenges faced when using VAEs.
Mode Collapse: It occurs when the model generates only a few types of samples, leading to repetitive outputs instead of diverse ones. Overfitting can worsen this issue by causing the model to memorize specific patterns rather than learning meaningful latent representations. This often happens due to poor latent space exploration or insufficient and unrepresentative training data. To address this, regularization techniques such as dropout and batch normalization can be used, along with advanced training algorithms like Importance-Weighted Autoencoders (IWAE).
High-Resolution Image Generation: CVAEs struggle to generate high-resolution images effectively. The model’s latent space may fail to capture enough fine-grained details, resulting in blurry or distorted outputs. This limitation arises from the restricted capacity of the latent space and the loss of quality in high-resolution outputs. Mitigating this challenge involves using more complex latent spaces or hierarchical VAEs, combining CVAEs with models like GANs, or employing progressive training techniques that gradually increase resolution during training.
Use Cases of Conditional Variational Autoencoders (CVAEs)
Conditional Variational Autoencoders (CVAEs) are versatile tools in deep learning, with applications across a variety of domains. Here are some key use cases:
Image Generation: CVAEs generate images conditioned on attributes like style, pose, or lighting. In design and fashion, they are used to visualize apparel in different styles or colors. Game developers leverage them to create diverse character appearances, while automotive manufacturers use them to render vehicles with various customizations for customers.
Content Recommendation Systems: CVAEs enhance personalization by learning user preferences to suggest relevant recommendations. They also adapt dynamically to user interactions, improving engagement over time.
Drug Discovery: CVAEs accelerate medical innovation by generating novel molecular structures based on desired properties. They also optimize existing compounds for improved therapeutic outcomes.
Anomaly Detection: CVAEs identify unusual patterns in critical systems. They flag deviations from normal operational parameters and enhance cybersecurity by detecting unusual network activity.
Natural Language Processing (NLP): CVAEs contribute to tasks like generating coherent text conditioned on context, style, or tone. They also facilitate nuanced language translations tailored to stylistic requirements.
Art and Creativity: CVAEs empower artists and creators by enabling style transfer to reimagine artworks in different aesthetics. They also assist in generating novel artistic creations based on specific themes or motifs.
AI Ethics and Accountability: CVAEs support responsible AI development by improving model interpretability through controlled data generation. They ensure AI systems align with ethical standards by enabling controllable outcomes.
Tools
Now, we will explore some of the popular tools and frameworks that facilitate the implementation and training of Conditional Variational Autoencoders (CVAEs).
TensorFlow: It is a powerful framework for designing CVAEs. It simplifies implementing encoder-decoder architectures and supports the computation of the KL divergence term through TensorFlow Probability. Its GPU/TPU support ensures efficient training for large datasets.
PyTorch: It is widely used for its flexibility and dynamic computation graph, making it ideal for custom CVAE implementations. It allows precise control over the model components, and libraries like Pyro add advanced probabilistic modeling capabilities for CVAE loss functions.
JAX and Flax: JAX, combined with its neural network library Flax, offers efficient computation for CVAEs. It provides flexibility for customizing gradient calculations and supports scalable architectures for complex CVAE tasks.
FAQS
What distinguishes CVAEs from standard VAEs? CVAEs use conditional inputs to control output features. Standard VAEs generate data based only on the input distribution.
How does conditioning influence the generative process in CVAEs? Conditioning guides the model in generating data that matches specific attributes. It adds control and precision to the output.
What are the common applications of CVAEs? CVAEs create customized images, personalized text, and augmented datasets. They work well in tasks needing specific feature generation.
What challenges might one encounter when training CVAEs? Training requires labeled data and careful tuning. It can also face issues with stability and complexity.
What are the limitations of CVAEs compared to GANs? CVAEs may produce less realistic outputs. GANs often achieve sharper and more detailed results but lack the same control.
- What are Conditional Variational Autoencoders (CVAE) ?
- Understanding Variational Autoencoders (VAEs)
- How CVAE Improves VAE with Conditional Inputs?
- CVAEs vs. VAEs vs. GANs
- Benefits and Challenges of Variational Autoencoders (VAEs)
- Use Cases of Conditional Variational Autoencoders (CVAEs)
- Tools
- FAQS
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free