




CQRS: Split Commands and Queries for Better Performance

CQRS: Split Commands and Queries for Better Performance
What is Command Query Responsibility Segregation (CQRS)?
Command Query Responsibility Segregation (CQRS) is a design pattern that separates the actions that change data (commands) from those that retrieve data (queries). Instead of using the same model for both, CQRS splits them into two distinct paths. By separating commands and queries, systems can handle each task more efficiently, leading to better performance, clearer code, and easier scaling as your application grows.
Key Concepts of CQRS
Command
A command is an action that changes data in the system, such as a write operation in the database. It represents a request to perform a specific task, like creating, updating, or deleting something. Commands don’t return data; they tell the system to "do something."
Example: When users update their profile information, a command like “UpdateUserProfile” is sent to change their name, email, or other system details.
Query
A query is a request to retrieve data without changing it, i.e., the read operation in the database. Queries are used to get information, like searching for or displaying data. Unlike commands, queries only return data and don’t alter anything.
Example: When a user wants to view their profile details, a query like “GetUserProfile” fetches the relevant information from the system.
How does CQRS Work?
A real-world analogy to understand the workings of CQRS is to think of it as having separate lanes for cars and trucks on a highway. Trucks handle heavy loads (commands), while cars move quickly and smoothly (queries). By keeping them in their own lanes, traffic flows better, and both tasks are done more efficiently.
CQRS operates by clearly separating the handling of commands (data modifications) and queries (data retrieval). When a command is issued, such as inserting or updating data, it flows through a dedicated path designed to process changes. The system processes these commands accurately, often triggering related business logic or events. Queries, on the other hand, are funneled through a different path optimized for fast and efficient data reads.
It’s important to note that in CQRS, separating commands and queries doesn’t necessarily mean you need to use different databases for each. The focus is on separating the behaviors and responsibilities, which can be done within the same database or across multiple databases if needed.
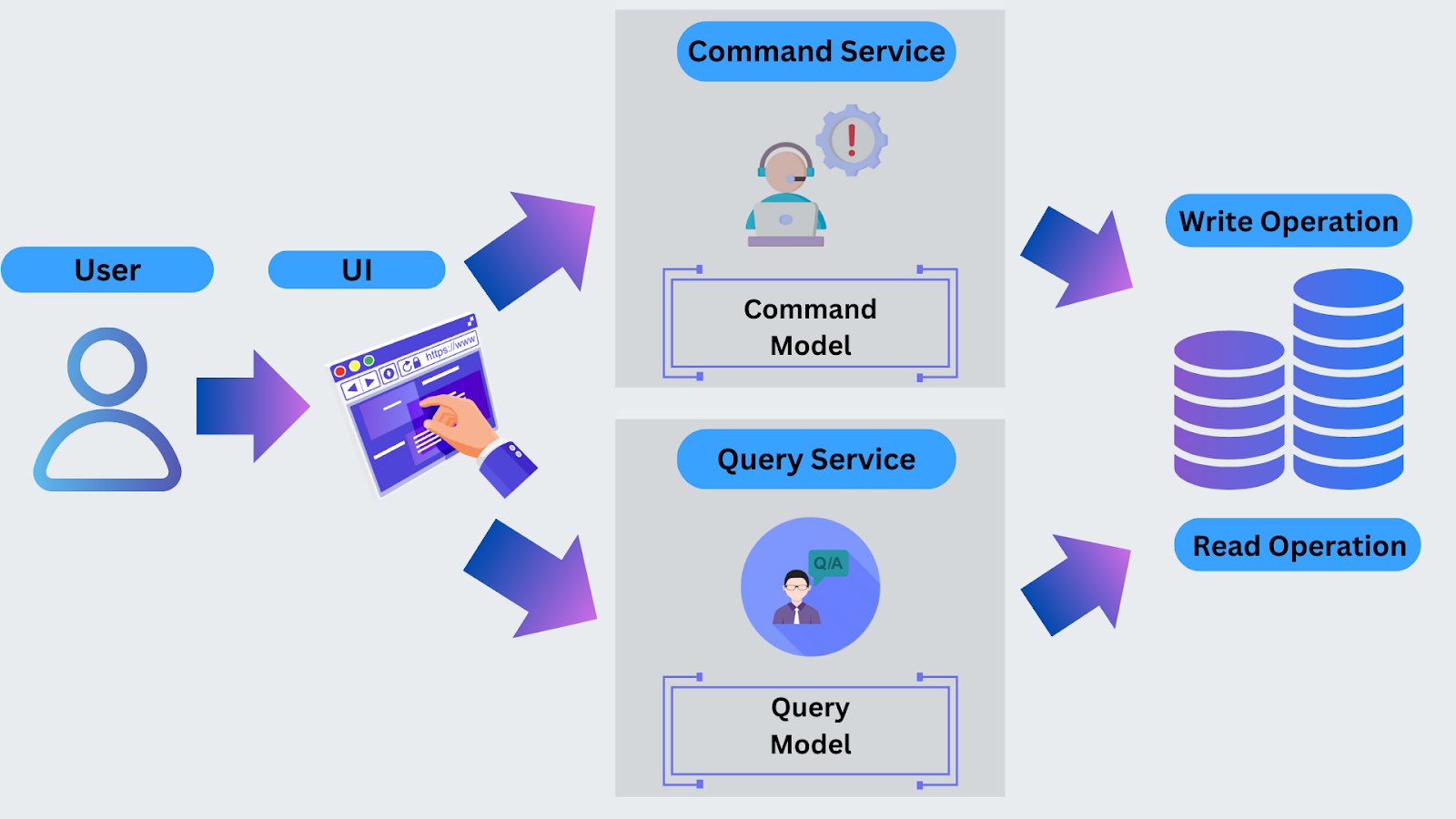 Figure- CQRS High-Level Architecture.png
Figure- CQRS High-Level Architecture.png
Figure: CQRS High-Level Architecture
Example: A user registration system
When a user registers, a command called RegisterUserCommand is triggered. This command creates the new user, validates their details, and adds them to the database. Behind the scenes, an event like `UserRegisteredEvent` is stored that records this change.
Later, when another part of the system (or the user) needs to view the user’s details, a query called GetUserProfileQuery is used. The query retrieves the user’s profile data from the database without making any modifications.
CQRS and Event Sourcing
Event Sourcing is a technique often used with CQRS. In traditional systems, when data changes (like a user updating their profile), we only save the final state of the data. For example, if a user changes their email address, we only store the new email in the database, and the old email is lost.
With Event Sourcing, instead of saving just the final state, we store every change as a separate event. So, in the case of a user profile update, we store events like "User created," "Email updated," or "Profile picture changed." Each event records what happened and when. These events are saved in a sequence, almost like a history log of everything in the system.
These events become the system's source of truth. When a command is executed (e.g., updating the user's profile), a new event is created and added to this list of events. Over time, all these events build up to represent the entire history of changes.
When you need to query or view the current state of the system (like fetching the user profile), the system can replay these events in the correct order to reconstruct the current state. For instance, it might replay the events "User created" and "Email updated" to show the current email and profile details.
Difference between CQRS and CQS
While CQRS (Command Query Responsibility Segregation) and CQS (Command Query Separation) are both design principles that emphasize the distinction between commands and queries, they are slightly different in some aspects.
| Aspect | CQS (Command Query Separation) | CQRS (Command Query Responsibility Segregation) |
|---|---|---|
| Definition | Methods are either commands (modify data) or queries (retrieve data). | System separates commands and queries into distinct models or paths. |
| Complexity | Simple principle applied within methods. | More complex, and involves separate models or layers for commands and queries. |
| Use Case | Suitable for simpler systems where commands and queries are handled within the same structure. | Ideal for large, complex systems where reads and writes can be optimized separately. |
| Data Handling | Same data model is used for both commands and queries. | Commands and queries can use different data models or even databases. |
| Focus | Primarily focused on the fact that methods have a single responsibility. | Focuses on scalability, performance, and separation of responsibilities across the system. |
| Scalability | Less impact on system scalability as both are handled in one model. | High scalability as commands and queries are handled independently. |
| Flexibility | Limited flexibility as both operations are tied together in one structure. | Greater flexibility; you can use different databases or storage mechanisms for commands and queries. |
| Event Sourcing | Not typically used. | Often used with event sourcing to track all changes over time. |
Table: CQS and CQRS Difference
Use Cases for CQRS
Here are some common scenarios where CQRS is useful:
High Read/Write Workloads
In scenarios where there is a significant imbalance between the number of read and write operations, CQRS is ideal. For example, an e-commerce platform may have a large number of users querying product information (reads) but fewer users updating their carts or making purchases (writes). CQRS allows the system to scale the query side independently to handle the high volume of read requests without affecting the write operations.
Complex Business Logic
When handling complex business rules that apply only to data modifications (commands), CQRS helps by isolating this complexity. For instance, the command side can enforce strict validation and processing rules in a financial system where transactions are heavily regulated. In contrast, the query side remains simple and focused on retrieving account balances or transaction histories.
Event Sourcing and Audit Trails
In systems where maintaining a full audit trail of every change is necessary, CQRS pairs well with event sourcing. For example, in a healthcare application, every change to a patient's medical record can be stored as an event, allowing the system to easily track who made changes and when, while queries can quickly access the current state of the record.
Real-time Analytics
For applications requiring real-time analytics, such as social media platforms, CQRS can handle constant updates to user data (e.g., likes, shares) while processing queries for real-time insights (e.g., trending topics). The query side can be optimized for speed without being affected by the ongoing updates on the command side.
Microservices Architectures
In microservices-based systems, CQRS provides different services to handle commands and queries independently. For example, in a logistics company, one service can manage order processing (commands), while another handles tracking and reporting (queries), improving the system's flexibility and maintainability.
Tools and Frameworks that Support CQRS
Several tools and frameworks make it easier to implement CQRS. Here’s a brief overview of some popular options:
Axon Framework (Java) is a full-featured framework that supports CQRS and event sourcing. It provides built-in components for handling commands, queries, and events, which makes it a popular choice for complex Java applications.
MediatR is another lightweight library for .NET applications that simplifies the separation of commands and queries. It helps route requests in a clean and organized way, which is perfect for CQRS in small- to medium-sized systems.
Laravel Command Bus is part of the Laravel framework. Developers use this tool to define commands and queries separately. It’s a great option for PHP-based applications looking to implement CQRS.
EventStore is a specialized database designed for event sourcing, often paired with CQRS. It stores events rather than just data, enabling easy replay of past events to reconstruct the system's state.
NServiceBus is a messaging framework that works well with CQRS by handling commands, events, and messages across distributed systems. It’s ideal for microservices architectures that use CQRS.
Advantages of CQRS
Improved scalability and performance
By separating commands and queries, CQRS can scale each part independently. For example, if your application handles many more read operations (queries) than write operations (commands), you can scale the query side without affecting the command side, improving overall performance.
Clearer code organization
CQRS promotes a clean separation of concerns. Commands deal with making changes, and queries handle data retrieval. This makes the code easier to understand and maintain, as each system part has a clear responsibility.
Better handling of complex business rules
With CQRS, complex business rules related to updating data can be handled on the command side, while simpler, efficient queries can be used for reading data. This division helps manage intricate logic without overloading the system or making the code too complicated.
Flexibility in database choices for reading vs. writing data
CQRS gives you an open choice to use different databases for commands and queries. For instance, you could use a highly optimized NoSQL database for fast reads (queries) and a relational database during writes (commands). This flexibility lets you choose the best tools for each task.
Challenges and Considerations of CQRS
Increased complexity
With CQRS, you must manage two separate models: one for handling commands (writes) and another for handling queries (reads). This adds complexity to the codebase since you must maintain and update both models, increasing the effort needed to develop and maintain the system.
Synchronization challenges
Keeping the command and query sides synchronized can be tricky. When data is written through a command, it may take time for the changes to be reflected on the query side, leading to potential delays. Managing this synchronization is important to ensure accurate data across the system.
Deciding when CQRS is overkill
CQRS isn’t necessary for simple CRUD (Create, Read, Update, Delete) applications. In systems with straightforward data requirements, the added complexity of CQRS may not be worth it. CQRS is best suited for complex systems with a high volume of reads and writes or intricate business logic.
Cost
Implementing CQRS often requires additional infrastructure, such as maintaining separate databases for commands and queries. This can increase hardware and cloud service costs, especially when scaling both sides. The need for multiple technologies to handle these tasks can drive up expenses.
How CQRS Plays a Role in Vector Databases and Big Data
In vector databases like Milvus, CQRS offers a structured way to handle different types of operations:
Commands: These involve tasks like inserting or updating large volumes of vectors (e.g., vector embeddings generated by machine learning models). In Milvus, commands would update the state of the database.
Queries: These operations retrieve vectors, like finding similar items in a large dataset using similarity search. Milvus queries can return high-dimensional vectors that match specific criteria, and they are often used in real-time analytics or AI applications like recommendation systems and retrieval augmented generation (RAG).
Example: Handling real-time analytics queries vs. inserting/updating vectors
Let’s say you’re running an AI-powered recommendation system on Zilliz Cloud (the managed version of Milvus). When new user data or product vectors are generated, the system issues commands to update the vector database with fresh embeddings. These commands ensure the latest vectors are inserted or updated in Milvus.
At the same time, real-time analytics are performed using queries to retrieve the most similar vectors for recommendations. The query side is optimized to quickly find relevant data without being impacted by the constant vector insertions on the command side.
Conclusion
CQRS provides a powerful way to manage complex systems by separating commands (data changes) and queries (data retrieval). This separation improves scalability, performance, and code clarity, especially in large-scale applications with complex business logic. While CQRS adds some complexity, it offers significant benefits when used in the right scenarios, such as systems handling real-time analytics, high read/write workloads, or event sourcing. However, for simpler applications, the additional complexity may not be necessary. In conclusion, CQRS is a valuable tool for enhancing system efficiency and flexibility when applied appropriately.
FAQ’s of CQRS
- What is the main benefit of using CQRS?
CQRS separates the responsibilities of updating data (commands) and retrieving data (queries), which improves system scalability, performance, and code clarity. Each side can be optimized independently, which makes it useful for high-volume or complex systems.
- When should I avoid using CQRS?
CQRS can add unnecessary complexity for simple CRUD applications where there’s no need for distinct handling of reads and writes. If your application doesn't have significant performance requirements or complex business logic, CQRS may be overkill.
- Do I need to use separate databases for commands and queries in CQRS?
No, using separate databases for commands and queries is not required. While you can use different databases for CQRS, the key is to separate the behavior and responsibility in the code. You can still use a single database if it suits your application's needs.
- How does CQRS work with event sourcing?
In event sourcing, every change to the system is stored as an event. CQRS complements this by handling commands that generate events and using queries to reconstruct the system’s state by replaying those events. So, a full history of changes is maintained, making it easier to audit or debug.
- Can CQRS improve the performance of real-time analytics applications?
Yes, CQRS is useful for real-time analytics. It allows the system to handle continuous updates (commands) separately from real-time data queries, optimizing each for its purpose and preventing one from slowing down the other.
- What are the challenges of implementing CQRS?
The main challenges include increased complexity, managing synchronization between the command and query models, handling eventual consistency issues, and potentially higher infrastructure costs due to maintaining separate paths or databases.
Related Resources
- What is Command Query Responsibility Segregation (CQRS)?
- Key Concepts of CQRS
- How does CQRS Work?
- CQRS and Event Sourcing
- Difference between CQRS and CQS
- Use Cases for CQRS
- Tools and Frameworks that Support CQRS
- Advantages of CQRS
- Challenges and Considerations of CQRS
- How CQRS Plays a Role in Vector Databases and Big Data
- Conclusion
- FAQ’s of CQRS
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free