




Un guide complet des benchmarks ANN : évaluer les performances de la recherche approximative du plus proche voisin (ANNS)
Un guide complet des benchmarks ANN : évaluer les performances de la recherche approximative du plus proche voisin (ANNS)
Imaginez que vous construisiez un moteur de recherche qui doit trouver rapidement les éléments les plus similaires dans une base de données contenant des milliards d’images, de documents texte ou d’autres données non structurées. Comment garantir que votre algorithme de recherche renvoie non seulement des résultats précis, mais le fasse aussi à une vitesse fulgurante ? C’est là qu’intervient la recherche Approximate Nearest Neighbor (ANN). La recherche ANN est cruciale dans de nombreuses applications du monde réel, des systèmes de recommandation à la recherche d’images à grande échelle.
Avec autant de solutions de recherche ANN disponibles sur le marché, comment évaluer l’efficacité des différents algorithmes ANN, en particulier à grande échelle ? Voici les ANN Benchmarks, qui sont devenus la référence absolue pour tester les performances des méthodes de recherche ANN sur de grands ensembles de données.
Dans cet article de blog, nous explorerons les benchmarks ANN, pourquoi ils sont importants et comment ils aident les développeurs et les ingénieurs en algorithmes à choisir les bonnes solutions de recherche vectorielle pour la tâche à accomplir. Nous examinerons également certains des benchmarks les plus populaires utilisés aujourd’hui et ce qui les rend essentiels dans la recherche vectorielle.
Qu’est-ce que la recherche ANN et comment fonctionne-t-elle ?
Avant de plonger dans les benchmarks, il est important de comprendre la recherche Approximate Nearest Neighbor (ANN), ou ANNS, et son fonctionnement. La recherche ANN est une technique puissante en apprentissage automatique (ML) qui permet une recherche efficace de similarité sémantique dans de grands ensembles de données que l’on trouve souvent dans des bases de données vectorielles comme Zilliz Cloud. Elle peut trouver rapidement les éléments les plus proches d’un élément de requête donné dans un ensemble de données. Contrairement aux méthodes de recherche exacte, qui garantissent une précision de 100 %, l’ANNS échange une petite quantité de précision contre des améliorations significatives en vitesse et en évolutivité.
Comment fonctionne la recherche ANN :
Représentation des données : Chaque élément de l’ensemble de données est représenté sous forme de vecteur dans un espace multidimensionnel. Les vecteurs sont généralement encodés par un modèle d’embedding tel que les modèles d’embedding de texte OpenAI, les modèles multilingues Cohere et les modèles multimodaux OpenAI. Par exemple, une image peut être représentée comme un vecteur de caractéristiques, telles que la couleur ou la forme, dans un espace à 128 dimensions.
Traitement des requêtes : Lorsqu’une requête est effectuée, l’algorithme de recherche ANN parcourt l’ensemble de données pour trouver les vecteurs proches du vecteur de requête, en utilisant des approximations pour accélérer le processus.
Classement des résultats : L’algorithme classe les plus proches voisins en fonction de leur distance par rapport à la requête dans l’espace de grande dimension, en utilisant souvent des métriques comme la distance euclidienne ou la similarité cosinus. Plus les vecteurs sont proches, plus ils sont similaires et pertinents.
Efficacité : L’avantage clé de la recherche ANN est sa capacité à fournir des résultats en une fraction du temps qu’il faudrait pour une recherche exacte, ce qui la rend idéale pour les ensembles de données à grande échelle.
Les méthodes ANNS utilisent diverses stratégies pour approximer rapidement les plus proches voisins :
Méthodes basées sur les arbres : Des techniques telles que les KD-Trees et les Ball Trees organisent les données de manière hiérarchique afin de simplifier le processus de recherche. Bien qu’efficaces dans les dimensions inférieures, leurs performances se dégradent à mesure que la dimensionnalité augmente.
Méthodes de hachage : Le hachage sensible à la localité (LSH) regroupe les points de données similaires dans les mêmes compartiments de hachage, réduisant le nombre de comparaisons nécessaires pendant la recherche.
Méthodes basées sur les graphes : Des algorithmes comme les graphes Navigable Small World (NSW) et les graphes Hierarchical Navigable Small World (HNSW) créent des réseaux de points de données afin d’accélérer les recherches de voisins.
Méthodes de quantification : Des techniques telles que la Product Quantization (PQ) compressent les données sous une forme plus facile à gérer, améliorant ainsi l’efficacité de la recherche.
En exploitant ces méthodes, les algorithmes ANNS peuvent trouver un équilibre entre précision de recherche et performance, ce qui les rend adaptés aux ensembles de données à grande échelle.
Recherche ANN vs. recherche KNN
La recherche exacte des K plus proches voisins (KNN) et la recherche approximative des plus proches voisins (ANNS) sont deux approches fondamentales utilisées dans la recherche vectorielle, chacune ayant ses propres avantages et compromis.
La recherche KNN exacte fournit des résultats précis en évaluant la distance entre le point de requête et chaque point de données de l’ensemble de données, garantissant que les voisins identifiés sont les plus proches possibles. Cependant, cette méthode peut être coûteuse en calcul et lente en raison de sa nature exhaustive, en particulier lorsqu’il s’agit de grands ensembles de données ou d’espaces à haute dimension. Cela rend la recherche KNN exacte adaptée aux ensembles de données plus petits ou aux scénarios où la précision est primordiale et où les ressources de calcul sont moins préoccupantes.
À l’inverse, l’ANNS offre une solution pratique pour gérer des données à grande échelle en sacrifiant un certain degré de précision au profit de performances plus rapides. L’ANNS utilise divers algorithmes et techniques, tels que des structures basées sur les arbres, des méthodes de hachage et des approches basées sur les graphes, afin d’approximer efficacement les plus proches voisins. Cette approche réduit considérablement les coûts de calcul et s’adapte bien aux ensembles de données massifs, ce qui la rend idéale pour les applications en temps réel comme les moteurs de recherche et les systèmes de recommandation, où la vitesse est cruciale. Bien que l’ANNS ne fournisse pas toujours les voisins les plus proches exacts, sa capacité à fournir rapidement des résultats presque précis en fait un outil précieux dans les tâches modernes de récupération et d’analyse de données.
Pour plus d’informations, consultez notre page de glossaire ANNS.
Qu’est-ce que l’ANN Benchmark ?
L’ANN Benchmark est un outil d’évaluation complet conçu pour mesurer et comparer les performances de différents algorithmes ANNS. Hébergé sur ann-benchmarks.com, il fournit des tests et des métriques standardisés pour évaluer divers aspects des méthodes ANNS, notamment :
Vitesse de recherche : La rapidité avec laquelle l’algorithme peut trouver les plus proches voisins.
Précision : Le degré auquel les résultats de l’algorithme se rapprochent des véritables plus proches voisins.
Évolutivité : La capacité de l’algorithme à maintenir ses performances à mesure que la taille ou la dimensionnalité de l’ensemble de données augmente.
Ce benchmark propose une gamme d’ensembles de données et de critères d’évaluation, permettant aux développeurs d’évaluer l’efficacité de différents algorithmes dans diverses conditions, sur un pied d’égalité.
Métriques clés dans les benchmarks ANN :
Rappel : Le pourcentage de véritables plus proches voisins récupérés avec succès par l’algorithme. Un rappel élevé indique une meilleure précision.
Temps de recherche : Le temps nécessaire à l’algorithme pour renvoyer un résultat. Des temps de recherche plus rapides sont essentiels pour les applications qui nécessitent des réponses en temps réel.
Utilisation de la mémoire : La quantité de mémoire dont l’algorithme a besoin pour stocker et rechercher dans le jeu de données. Une utilisation efficace de la mémoire est importante pour la scalabilité.
Scalabilité : La capacité de l’algorithme à maintenir ses performances à mesure que la taille du jeu de données augmente. La scalabilité est un facteur essentiel dans les applications réelles où les jeux de données peuvent croître rapidement.
Principaux jeux de données utilisés dans les ANN Benchmarks
ANN Benchmark utilise divers jeux de données pour tester les algorithmes. Ces jeux de données couvrent un éventail de domaines, tels que les caractéristiques d’images, les embeddings de texte et les données synthétiques. Les principaux jeux de données utilisés dans les benchmarks incluent :
| Jeu de données | Dimensions | Taille d’entraînement | Taille de test | Voisins | Distance | Téléchargement |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angulaire | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euclidienne | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euclidienne | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angulaire | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angulaire | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angulaire | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angulaire | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euclidienne | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angulaire | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euclidienne | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Angulaire | HDF5 (135MB) |
Algorithmes ANN ou moteurs de recherche vectorielle testés
Les ANN Benchmarks ont évalué un large éventail d’algorithmes ANN et de moteurs de recherche vectorielle, notamment Annoy, Faiss, Knowhere (le moteur de recherche de Milvus) et Glass (le moteur de recherche historique de Zilliz Cloud). Le nombre d’algorithmes testés continue de croître. Vous trouverez ci-dessous une liste des algorithmes et moteurs de recherche testés en septembre 2024.
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (bibliothèque pour espaces non métriques) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
Remarque : Zilliz Cloud a lancé un nouveau moteur de recherche appelé Cardinal, qui offre des performances trois fois supérieures à celles de l’ancien moteur Glass et un débit de recherche (QPS) jusqu’à dix fois supérieur à celui de Milvus. Cependant, en raison de contraintes de temps et d’autres facteurs, les performances de Cardinal ne sont pas incluses dans les résultats du benchmark ANN. Dans la section suivante, vous pouvez explorer ses performances à l’aide de VectorDBBench.
Résultats du benchmark
Le graphique ci-dessous présente les résultats des tests de rappel/requêtes par seconde de divers algorithmes basés sur le jeu de données GIST1M (1 million de vecteurs avec 960 dimensions). Il représente le taux de rappel sur l’axe des x et le QPS sur l’axe des y, illustrant les performances de chaque algorithme à différents niveaux de précision de récupération.
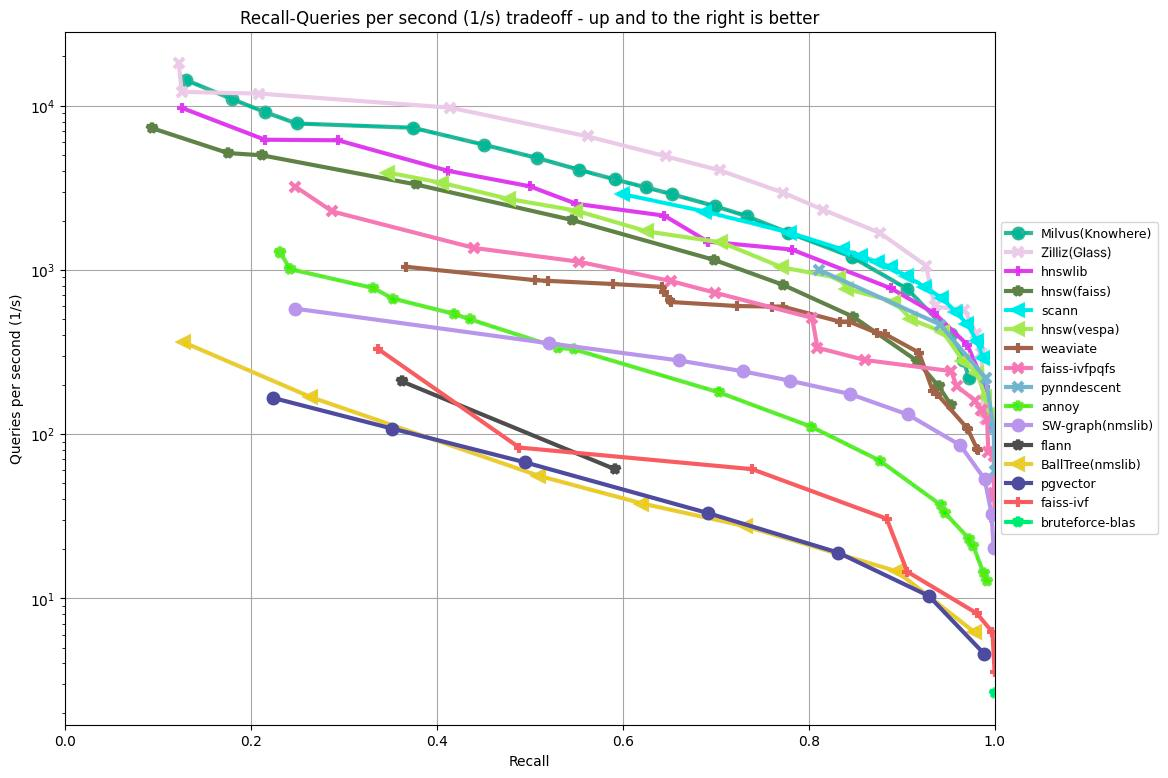 Figure 1 : Résultats du benchmark ANN sur le jeu de données GIST1M
Figure 1 : Résultats du benchmark ANN sur le jeu de données GIST1M
Figure 1 : Résultats du benchmark ANN sur le jeu de données GIST1M
Selon les résultats présentés dans le graphique ci-dessus, Knowhere (le moteur de recherche de Milvus), Glass (l’ancien moteur de recherche de Zilliz Cloud) et les bibliothèques HNSW ont obtenu les trois meilleurs résultats lors du traitement de 1 000 000 de vecteurs avec 960 dimensions.
Pour davantage de résultats de benchmarking, consultez le site web d’ANN-Benchmark.
VectorDBBench : un outil de benchmarking open source pour les bases de données vectorielles
La recherche vectorielle, ou recherche de similarité vectorielle, est un concept plus large qui désigne le processus consistant à trouver des vecteurs similaires au sein d’un jeu de données. ANNS représente un ensemble d’algorithmes qui alimentent la recherche vectorielle. Les bases de données vectorielles sont des solutions spécialement conçues pour des recherches efficaces de similarité vectorielle.
Bien que l’ANN-Benchmark soit extrêmement utile pour sélectionner et comparer différents algorithmes de recherche vectorielle, il ne fournit pas une vue d’ensemble complète des bases de données vectorielles. Nous devons également prendre en compte des facteurs tels que la consommation de ressources, la capacité de chargement des données et la stabilité du système. De plus, l’ANN Benchmark omet de nombreux scénarios courants, tels que les recherches vectorielles filtrées.
Pour relever ces défis, les développeurs de Zilliz ont proposé VectorDBBench, un outil de benchmarking open source conçu pour les bases de données vectorielles open source comme Milvus et Weaviate et les services entièrement gérés comme Zilliz Cloud et Pinecone. Étant donné que de nombreux services de recherche vectorielle entièrement gérés n’exposent pas leurs paramètres pour que les utilisateurs puissent les ajuster, VectorDBBench affiche séparément le QPS et les taux de rappel.
Les graphiques ci-dessous présentent les résultats des tests pour le QPS et le taux de rappel de diverses bases de données vectorielles grand public lors du traitement de 1 000 000 vecteurs à 768 dimensions.
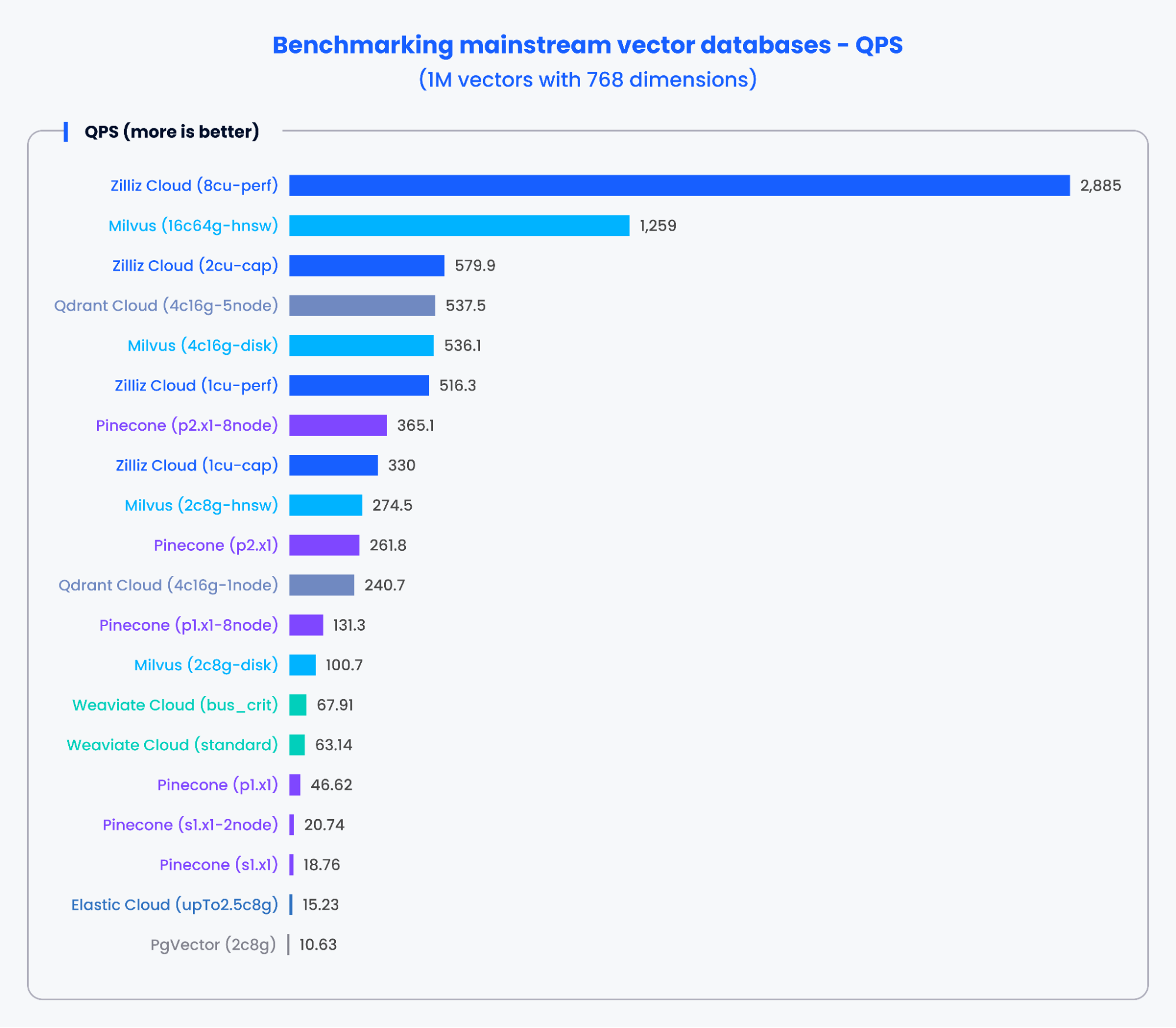 Figure 2 : Résultats du benchmark pour le QPS
Figure 2 : Résultats du benchmark pour le QPS
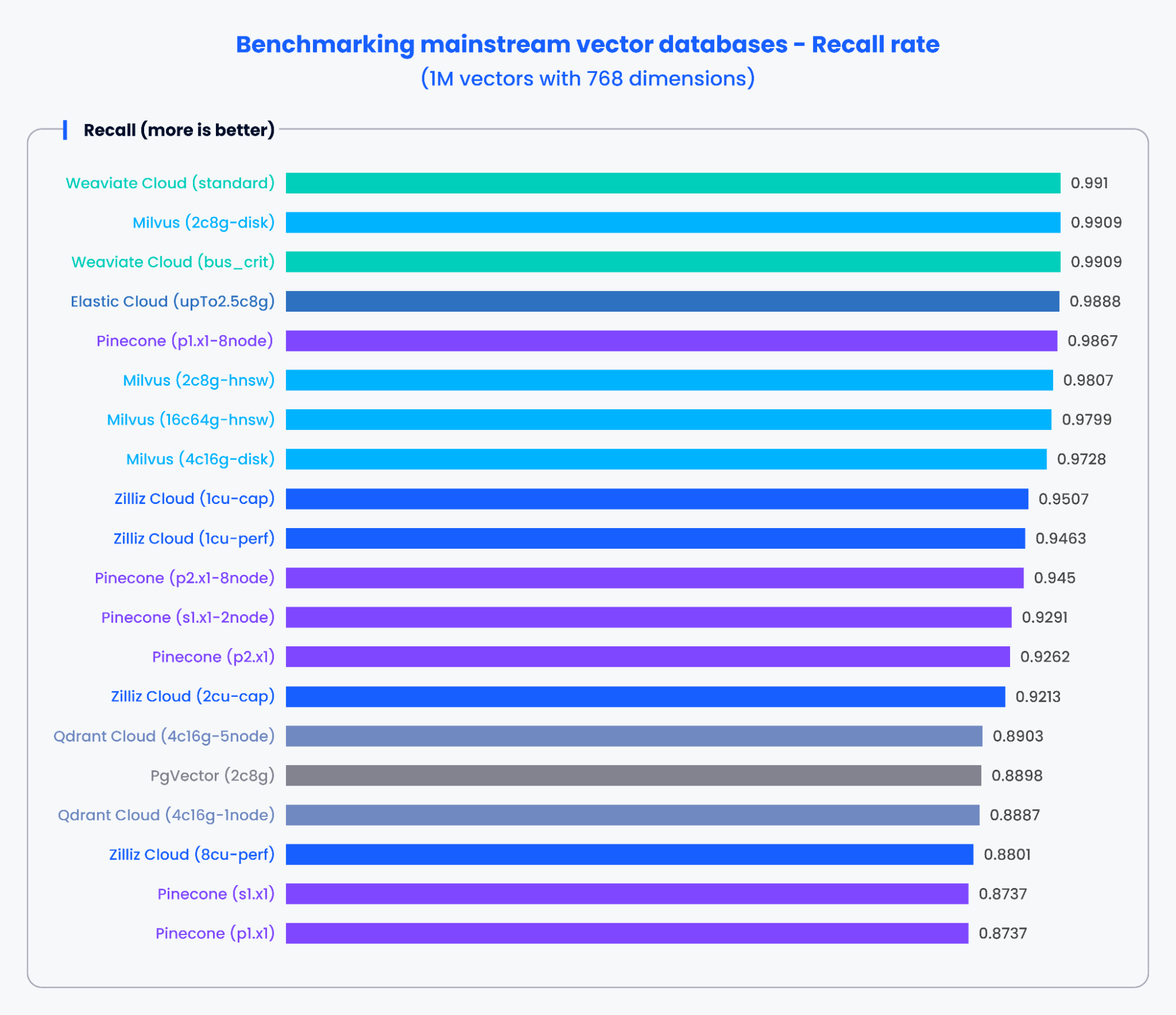 Figure 3 : Résultats du benchmark pour le taux de rappel
Figure 3 : Résultats du benchmark pour le taux de rappel
D’après les résultats des graphiques ci-dessus, les bases de données vectorielles spécialement conçues comme Milvus et Zilliz ont démontré des performances exceptionnelles à la fois en QPS et en taux de rappel. Ces résultats indiquent que les bases de données vectorielles spécialement conçues peuvent traiter rapidement d’immenses volumes de données et récupérer des résultats plus précis. En revanche, les extensions de recherche vectorielle basées sur des bases de données traditionnelles ont affiché des performances moins bonnes.
Téléchargez VectorDBBench depuis son dépôt GitHub pour reproduire nos résultats de benchmark ou obtenir des résultats de performance sur vos propres jeux de données.
Classement VectorDBBench
VectorDBBench propose également une page de classement dédiée, conçue pour simplifier la présentation des résultats de test et fournir un rapport d’analyse de performance approfondi. Ce classement nous permet de sélectionner des indicateurs clés tels que les requêtes par seconde (QPS), les métriques de prix des requêtes ($) et la latence pour une évaluation complète des performances.
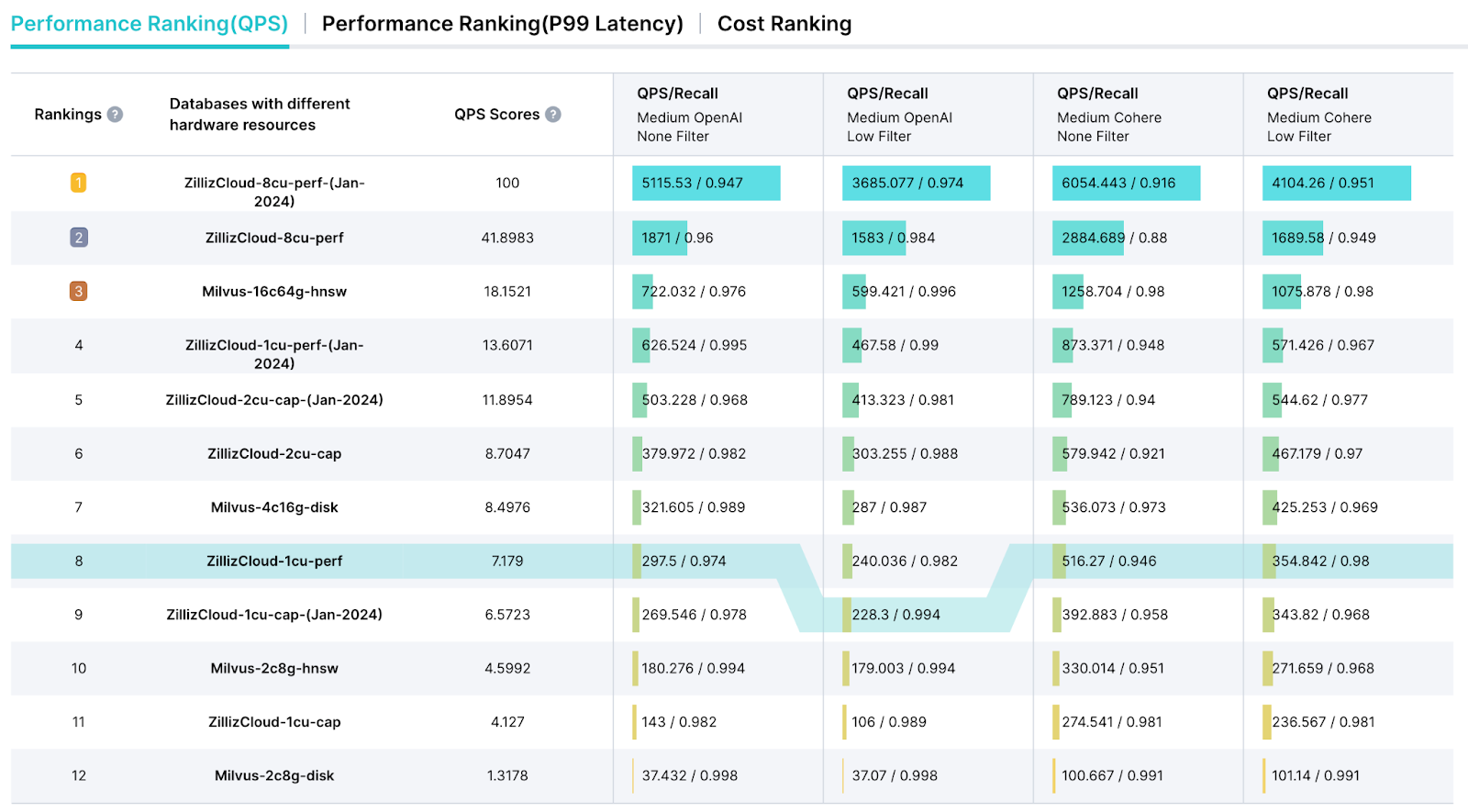 une capture d’écran du classement vectordbbench
une capture d’écran du classement vectordbbench
Figure 4 : Une capture d’écran du classement VectorDBBench
ANN Benchmarks vs. VectorDBBench
Les ANN Benchmarks évaluent les algorithmes d’indexation vectorielle, aidant à sélectionner et comparer différentes bibliothèques de recherche vectorielle. Cependant, ils ne conviennent pas à l’évaluation de bases de données vectorielles complexes et matures et négligent des situations telles que la recherche vectorielle filtrée.
Les ingénieurs de Zilliz ont créé VectorDB Bench afin qu’il soit adapté à une évaluation complète des bases de données vectorielles. Il prend en compte des facteurs essentiels tels que la consommation de ressources, la capacité de chargement des données et la stabilité du système. En séparant le client de test et la base de données vectorielle et en garantissant un déploiement indépendant, VectorDB Bench permet des tests qui reflètent étroitement les environnements de production réels.
Facteurs influençant l’évaluation des performances
Plusieurs facteurs influencent les performances d’une base de données vectorielle ou d’un algorithme ANN, notamment le jeu de données, les conditions réseau et la configuration de la base de données.
Réseau
Les conditions réseau sont critiques. La latence peut ralentir les réponses aux requêtes, tandis que la bande passante limitée affecte les débits de transfert des données. La stabilité du réseau est également importante, car les fluctuations peuvent entraîner des performances incohérentes.
Jeux de données
La taille du jeu de données influence l’utilisation de la mémoire et du disque : les jeux de données plus volumineux nécessitent davantage de ressources. La dimensionnalité des vecteurs affecte la complexité des opérations et les temps de requête. La distribution des données et la structure d’indexation (p. ex., hiérarchique, plate) ont également un impact sur l’efficacité et la précision de la recherche.
Configuration de la base de données
Les paramètres d’index (p. ex., nombre d’arbres) et les paramètres de recherche (p. ex., plus proches voisins) affectent directement l’efficacité et la vitesse de récupération. La mise en cache peut améliorer les temps de réponse pour les données fréquemment consultées.
Facteurs environnementaux
Le système d’exploitation et les processus en arrière-plan peuvent influencer la disponibilité des ressources et la réactivité du système, affectant les performances globales.
La prise en compte de ces facteurs vous aide à comprendre et à optimiser les performances de votre base de données vectorielle.
Ressources complémentaires
- Qu’est-ce que la recherche ANN et comment fonctionne-t-elle ?
- Qu’est-ce que l’ANN Benchmark ?
- VectorDBBench : un outil de benchmarking open source pour les bases de données vectorielles
- ANN Benchmarks vs. VectorDBBench
- Facteurs influençant l’évaluation des performances
- Ressources complémentaires
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement