




Bewährte Praktiken bei der Implementierung von Retrieval-Augmented Generation (RAG)-Anwendungen
Die Retrieval-Augmented Generation (RAG) ist eine Methode, die sich als sehr effektiv bei der Verbesserung der Antworten von LLMs und der Bewältigung von LLM-Halluzinationen erwiesen hat. Kurz gesagt, RAG versorgt LLMs mit Kontext, der ihnen helfen kann, genauere und kontextualisierte Antworten zu geben. Die Kontexte können von überall her kommen: aus Ihren internen Dokumenten, Vektordatenbanken, CSV-Dateien, JSON-Dateien, usw.
RAG ist ein neuartiger Ansatz, der aus vielen Komponenten besteht, die zusammenarbeiten. Zu diesen Komponenten gehören die Verarbeitung von Anfragen, [Context Chunking] (https://zilliz.com/learn/beginner-guide-to-website-chunking-and-embedding-for-your-genai-applications), das Abrufen von Kontexten, [Context Reranking] (https://zilliz.com/learn/what-are-rerankers-enhance-information-retrieval) und das LLM selbst, um die Antwort zu generieren. Jede Komponente beeinflusst die Qualität der endgültigen Antwort, die von einer RAG-Anwendung erzeugt wird. Das Problem ist, dass es schwierig ist, die beste Kombination von Methoden in jeder Komponente zu finden, die zu einer optimalen RAG-Leistung führt.
In diesem Artikel werden wir verschiedene Techniken erörtern, die in allen RAG-Komponenten verwendet werden, den besten Ansatz für jede Komponente bewerten und dann die beste Kombination finden, die zur optimalsten RAG-generierten Antwort führt, gemäß[ diesem Papier] (https://arxiv.org/pdf/2407.01219). Beginnen wir also ohne Umschweife mit einer Einführung in die RAG-Komponenten.
RAG-Komponenten
Wie bereits erwähnt, ist RAG eine leistungsfähige Methode, um die Halluzinationsprobleme von LLMs zu lindern, die häufig auftreten, wenn wir Fragen stellen, die über ihre Trainingsdaten hinausgehen, oder wenn sie Spezialwissen erfordern. Wenn wir zum Beispiel einem LLM eine Frage über unsere internen Daten stellen, werden wir wahrscheinlich eine ungenaue Antwort erhalten. RAG löst dieses Problem, indem es unseren LLM mit Kontext versorgt, der bei der Beantwortung unserer Anfrage helfen kann.
RAG besteht aus einer Kette von Komponenten, die einen Arbeitsablauf bilden. Zu den typischen RAG-Komponenten gehören:
Anfrageklassifizierung:, um festzustellen, ob unsere Anfrage die Abfrage von Kontexten benötigt oder direkt vom LLM verarbeitet werden kann.
Kontextabfrage: Abruf der k besten Kandidaten in den für unsere Anfrage relevantesten Kontexten.
Kontext-Reranking: Sortieren der obersten k Kandidaten, die von der Abrufkomponente geholt wurden, beginnend mit dem ähnlichsten Kandidaten.
Kontext-Repacking: Organisation der relevantesten Kontexte in einem strukturierteren Format zur besseren Generierung von Antworten.
Zusammenfassung von Kontexten: Extrahieren von Schlüsselinformationen aus relevanten Kontexten zur besseren Generierung von Antworten.
Antwortgenerierung: zur Generierung einer Antwort auf der Grundlage der Anfrage und der relevanten Kontexte.
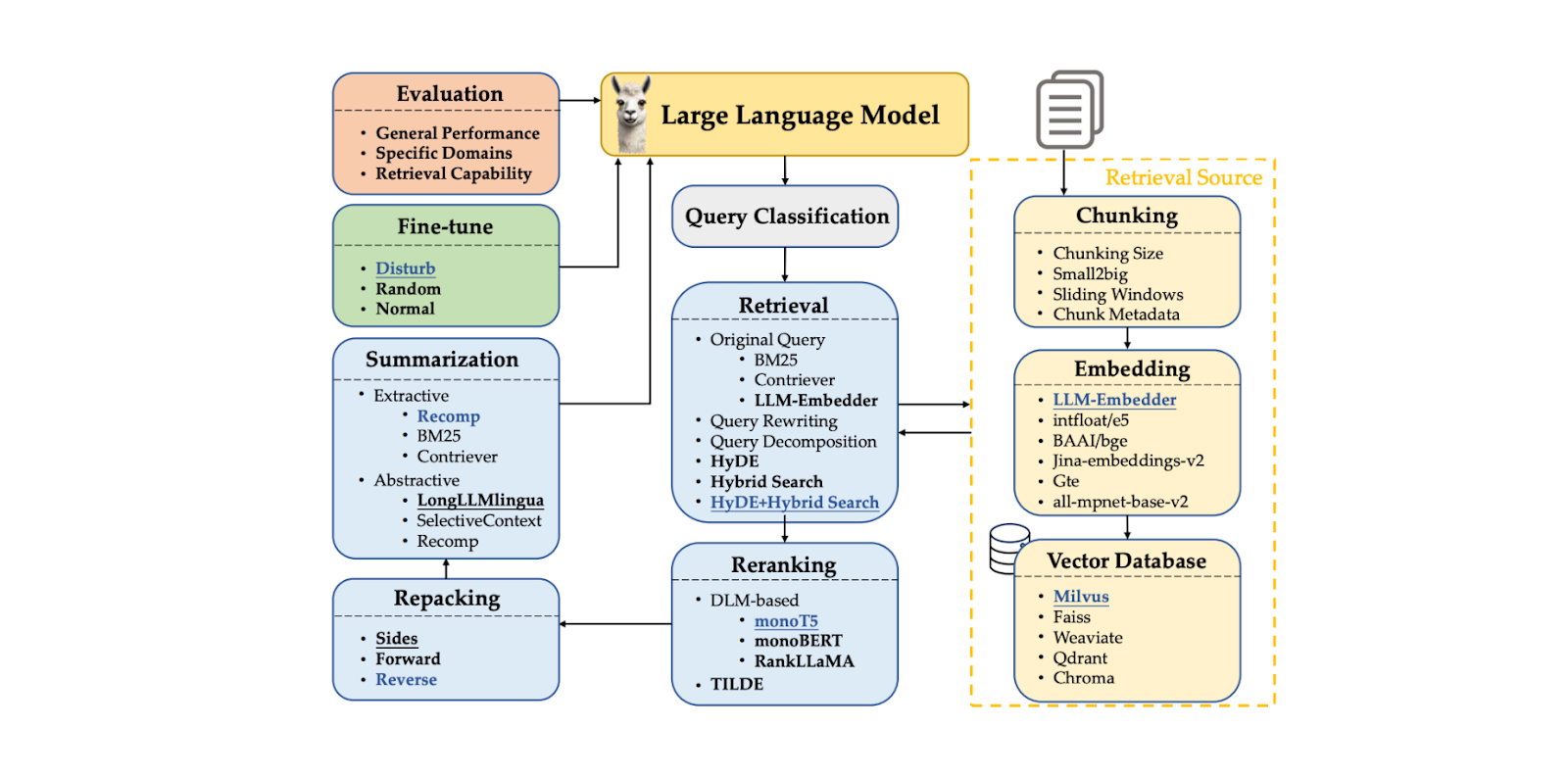 Abbildung- RAG Komponenten..png
Abbildung- RAG Komponenten..png
Abbildung: RAG-Komponenten. Quelle
Während diese RAG-Komponenten während des Antwortgenerierungsprozesses nützlich sind (d. h., wenn wir bereits alle Kontexte gespeichert haben und sie abrufbereit sind), müssen vor der Implementierung einer RAG-Methode mehrere andere Faktoren berücksichtigt werden.
Wir müssen unsere Kontextdokumente in Vektoreinbettungen umwandeln, damit unsere Kontextdokumente in einem RAG-Ansatz nützlich sind. Daher ist die Wahl[ des am besten geeigneten Einbettungsmodells] (https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data) und der Strategie zur Darstellung unserer Eingabedokumente als Einbettungen entscheidend.
Eine Einbettung enthält eine semantisch reichhaltige Darstellung unseres Eingabedokuments. Wenn das als Kontext verwendete Dokument jedoch zu lang ist, kann es den LLM bei der Generierung einer geeigneten Antwort verwirren. Ein üblicher Ansatz zur Lösung dieses Problems ist die Anwendung einer Chunking-Methode, bei der wir unser Eingabedokument in mehrere Chunks aufteilen und dann jeden Chunk in ein Embedding umwandeln. Es ist wichtig, die beste Chunking-Methode und -Größe zu wählen, da zu kurze Chunks wahrscheinlich nicht genügend Informationen enthalten.
 Abbildung- RAG Arbeitsablauf.png
Abbildung- RAG Arbeitsablauf.png
Abbildung: RAG-Arbeitsablauf
Sobald wir jedes Chunk in eine Einbettung umgewandelt haben, müssen wir über eine geeignete Speicherung für diese Einbettungen nachdenken. Wenn Sie es nicht mit vielen Einbettungen zu tun haben, können Sie sie direkt im lokalen Speicher Ihres Geräts speichern. In der Praxis werden Sie jedoch häufig mit Hunderten oder sogar Millionen von Einbettungen zu tun haben. In diesem Fall benötigen Sie eine Vektordatenbank wie Milvus oder seinen verwalteten Dienst Zilliz Cloud, um sie zu speichern, und die Wahl der richtigen Vektordatenbank ist entscheidend für den Erfolg unserer RAG-Anwendung.
Die letzte Überlegung betrifft das LLM selbst. Falls zutreffend, können wir den LLM feinabstimmen, um unsere spezifischen Bedürfnisse genauer zu erfüllen. Eine Feinabstimmung ist jedoch kostspielig und in den meisten Fällen unnötig, insbesondere wenn wir einen leistungsfähigen LLM mit vielen Parametern verwenden.
In den folgenden Abschnitten werden wir die besten Ansätze für jede RAG-Komponente diskutieren. Anschließend werden wir Kombinationen dieser besten Ansätze untersuchen und mehrere Strategien für den Einsatz von RAG vorschlagen, die ein Gleichgewicht zwischen Leistung und Effizienz herstellen.
Abfrageklassifizierung
Wie im vorigen Abschnitt erwähnt, ist RAG nützlich, um sicherzustellen, dass der LLM genaue und kontextbezogene Antworten generiert, insbesondere wenn spezielles Wissen aus unseren internen Daten erforderlich ist. RAG erhöht jedoch auch die Laufzeit des Antwortgenerierungsprozesses. Die Sache ist die, dass nicht alle Abfragen den Abrufprozess erfordern und viele von ihnen direkt vom LLM verarbeitet werden können. Daher wäre es vorteilhafter, den Kontextabrufprozess zu überspringen, wenn eine Anfrage ihn nicht benötigt.
Wir können ein Abfrage-[Klassifizierungs]-Modell (https://zilliz.com/glossary/classification) implementieren, um zu bestimmen, ob eine Abfrage vor dem Antwortgenerierungsprozess eine Kontextabfrage benötigt. Ein solches Klassifizierungsmodell besteht in der Regel aus einem überwachten Modell wie BERT, dessen Hauptziel die Vorhersage ist, ob eine Abfrage einen Abruf benötigt oder nicht. Wie andere überwachte Modelle müssen wir es jedoch trainieren, bevor wir es für Inferenzen verwenden können. Um das Modell zu trainieren, müssen wir einen Datensatz mit Beispielaufforderungen und ihren entsprechenden binären Kennzeichnungen erstellen, einschließlich der Angabe, ob die Aufforderung abgerufen werden muss oder nicht.
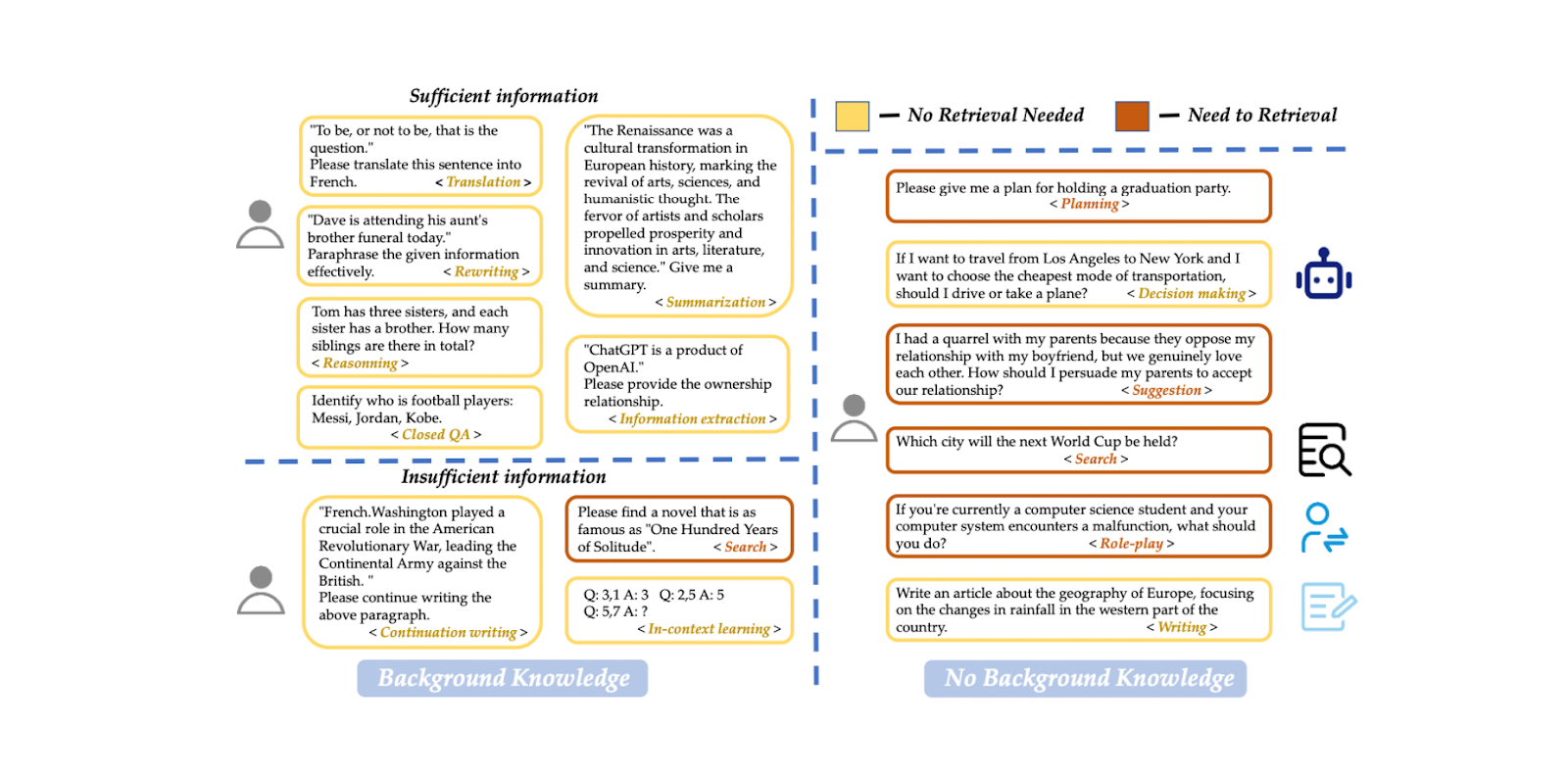 Abbildung- Abfrageklassifizierungsdatensatz Beispiel..png
Abbildung- Abfrageklassifizierungsdatensatz Beispiel..png
Abbildung: Abfrageklassifizierungsdatensatz Beispiel. Quelle
In dem Papier wird ein BERT-basiertes mehrsprachiges Modell zur Klassifizierung von Anfragen verwendet. Die Trainingsdaten umfassen insgesamt 15 Arten von Aufforderungen, wie z.B. Übersetzung, Zusammenfassung, Umschreiben, kontextbezogenes Lernen, etc. Es gibt zwei verschiedene Labels: "ausreichend", wenn die Eingabeaufforderung vollständig auf benutzerdefinierten Informationen basiert und keine Abfrage erforderlich ist, und "unzureichend", wenn die Eingabeaufforderung unvollständig ist, spezielle Informationen benötigt und einen Abfrageprozess erfordert. Mit diesem Ansatz erreichte das Modell sowohl bei der Genauigkeit als auch beim F1-Score 95 %.
Dieser Schritt der Abfrageklassifizierung kann die Effizienz des RAG-Prozesses erheblich verbessern, da unnötige Abfragen für Abfragen, die direkt vom LLM bearbeitet werden können, vermieden werden. Er fungiert als Filter, der sicherstellt, dass nur Abfragen, die zusätzlichen Kontext benötigen, durch den zeitaufwändigeren Abrufprozess geschickt werden.
 Abbildung - Ergebnis des Abfrageklassifizierers..png
Abbildung - Ergebnis des Abfrageklassifizierers..png
Abbildung: Abfrage Klassifikator Ergebnis. Quelle
Chunking-Technik
Chunking bezieht sich auf den Prozess der Aufteilung langer Eingabedokumente in kleinere Segmente. Dieser Prozess ist sehr nützlich, um dem LLM einen granulareren Kontext zu geben. Es gibt mehrere Methoden für das Chunking, darunter Ansätze auf Token- und Satzebene. Chunking auf Satzebene führt oft zu einem guten Gleichgewicht zwischen Einfachheit und semantischer Bewahrung des Kontexts. Bei der Auswahl einer Chunking-Methode müssen wir auf die Größe der Chunks achten, da zu kurze Chunks möglicherweise keinen hilfreichen Kontext für das LLM liefern.
 Abbildung- Aufteilung eines langen Dokuments in kleinere Stücke.png
Abbildung- Aufteilung eines langen Dokuments in kleinere Stücke.png
Abbildung: Aufteilung eines langen Dokuments in kleinere Abschnitte
Um die optimale Chunk-Größe zu finden, wurde eine Evaluierung des Lyft 2021 Dokuments durchgeführt. Die ersten 60 Seiten des Dokuments wurden als Korpus ausgewählt und in verschiedene Größen zerlegt. Ein LLM wurde dann verwendet, um 170 Abfragen auf der Grundlage dieser 60 Seiten zu generieren. Das text-embedding-ada-002 -Modell wurde für Einbettungen verwendet, während das Zephyr 7B-Modell als LLM verwendet wurde, um Antworten auf der Grundlage der ausgewählten Abfragen zu generieren.
Um die Leistung des Modells bei verschiedenen Chunk-Größen zu bewerten, wurde GPT-3.5 Turbo verwendet. Zur Bewertung der Antwortqualität wurden zwei Metriken verwendet: Treue und Relevanz. Die Treue misst, ob die Antwort halluziniert ist oder mit den abgerufenen Kontexten übereinstimmt, während die Relevanz misst, ob die abgerufenen Kontexte und Antworten mit den Abfragen übereinstimmen.
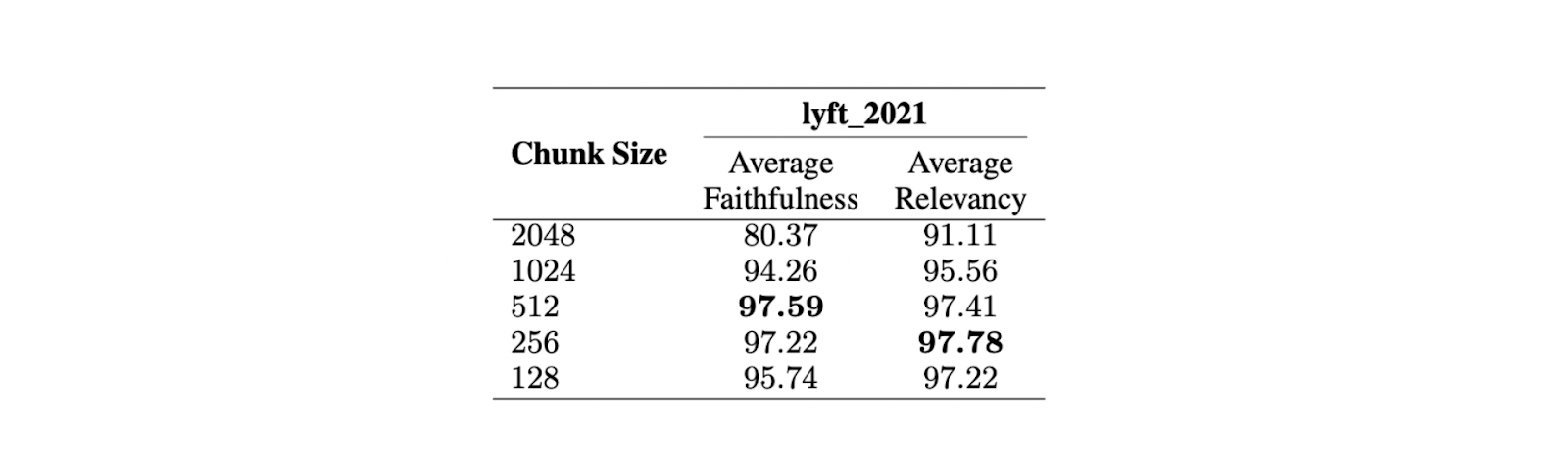 Abbildung- Vergleich verschiedener Chunk-Größen. .png
Abbildung- Vergleich verschiedener Chunk-Größen. .png
Abbildung: Vergleich verschiedener Chunk-Größen. Quelle
Die Ergebnisse zeigen, dass eine maximale Chunk-Größe von 512 Token für eine hochrelevante Antwortgenerierung aus dem LLM bevorzugt wird. Kürzere Chunk-Größen, wie z. B. 256 Token, sind ebenfalls gut geeignet und können die Gesamtlaufzeit der RAG-Anwendung verbessern. Erweiterte Chunking-Techniken wie small2big und sliding windows können verwendet werden, um die Vorteile verschiedener Chunk-Größen zu kombinieren.
Small2big ist ein Chunking-Ansatz, der die Beziehungen zwischen Chunk-Blöcken organisiert. Kleine Chunks werden zum Abgleich von Abfragen verwendet, und größere Chunks, die die Informationen der kleineren Chunks enthalten, werden als endgültiger Kontext für das LLM verwendet. Ein Sliding Window ist eine Chunking-Methode, die Token-Überlappungen zwischen Chunks vorsieht, um Kontextinformationen zu erhalten.
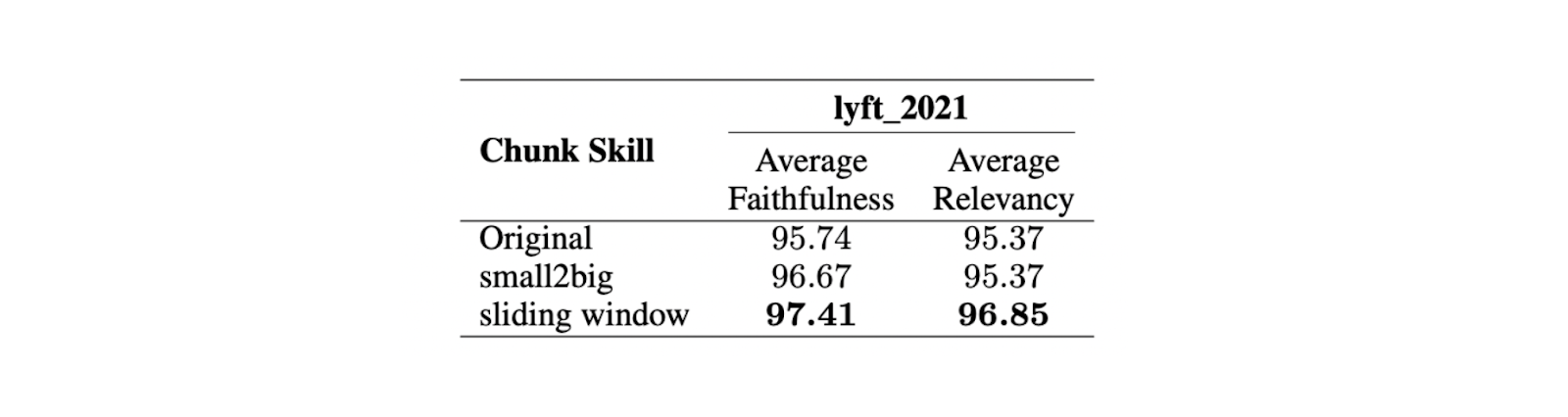 Abbildung- Vergleich verschiedener Chunking-Techniken..png
Abbildung- Vergleich verschiedener Chunking-Techniken..png
Abbildung: Vergleich verschiedener Chunking-Techniken. Quelle
Experimente zeigen, dass bei einer kleineren Chunk-Größe von 175 Token, einer größeren Chunk-Größe von 512 Token und einer Chunk-Überlappung von 20 Token beide Chunking-Techniken die Treue- und Relevanzwerte der LLM-Antworten verbessern.
Als nächstes ist es entscheidend, das beste Einbettungsmodell zu finden, um jedes Chunk als Vektoreinbettung darzustellen. Zu diesem Zweck wurde ein Test auf Namespace-Pt/msmarco durchgeführt. Die Ergebnisse zeigen, dass die Modelle LLM Embedder und bge-large-en am besten abschneiden. Da LLM Embedder jedoch dreimal kleiner ist als bge-large-en, wurde es als Standardeinbettung für das Experiment gewählt.
Abbildung- Ergebnisse für verschiedene Einbettungsmodelle auf Namespace-Pt:msmarco. .png](https://assets.zilliz.com/Figure_Results_for_different_embedding_models_on_namespace_Pt_msmarco_5e4b6f5e16.png)
Abbildung: Ergebnisse für verschiedene Einbettungsmodelle auf Namespace-Ptmsmarco. Quelle
Vektordatenbanken
Vektordatenbanken spielen eine entscheidende Rolle in RAG-Anwendungen, insbesondere bei der Speicherung und dem Abruf relevanter Kontexte. In den üblichen realen RAG-Anwendungen haben wir es mit einer riesigen Menge von Dokumenten zu tun, was zu einer großen Anzahl von Kontexteinbettungen führt, die gespeichert werden müssen. In solchen Fällen ist die Speicherung dieser Einbettungen im lokalen Speicher unzureichend, und die Berechnung des Abrufs relevanter Kontexte aus großen Sammlungen von Einbettungen würde viel Zeit in Anspruch nehmen.
Vektordatenbanken wurden entwickelt, um diese Probleme zu lösen. Mit einer Vektordatenbank können wir Millionen oder sogar Milliarden von Vektoreinbettungen speichern und die Kontextabfrage in Sekundenbruchteilen durchführen. Bei der Auswahl der besten Vektordatenbank für Ihren Anwendungsfall müssen wir mehrere Faktoren berücksichtigen, z. B. die Unterstützung des Index-Typs, die Unterstützung von Milliarden von Vektoren, die Unterstützung der [hybriden Suche] (https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus) und die Cloud-nativen Fähigkeiten.
Unter diesen Kriterien sticht Milvus im Vergleich zu seinen Konkurrenten wie Weaviate, Chroma, Faiss, Qdrant usw. als beste Open-Source-Vektordatenbank hervor.
 Vergleich verschiedener Vektordatenbanken..png
Vergleich verschiedener Vektordatenbanken..png
Vergleich verschiedener Vektordatenbanken. Quelle.
Was die Unterstützung von Index-Typen betrifft, so bietet Milvus mehrere Indexierungsmethoden für verschiedene Bedürfnisse, wie den naiven flachen Index (FLAT) oder andere Indexierungsarten, die den Abrufprozess beschleunigen sollen, wie den invertierten Dateiindex (IVF-FLAT) und Hierarchical Navigable Small World (HNSW). Um den für die Speicherung der Kontexte benötigten Speicherplatz zu komprimieren, können Sie auch die Produktquantisierung (PQ) während des Indizierungsprozesses der Einbettungen implementieren.
Milvus unterstützt auch einen hybriden Suchansatz. Dieser Ansatz ermöglicht es uns, zwei verschiedene Methoden während des Kontextabrufs zu kombinieren. Beispielsweise können wir die dichte Einbettung mit der spärlichen Einbettung kombinieren, um relevante Kontexte abzurufen und die Relevanz des abgerufenen Kontexts in Bezug auf die Anfrage zu erhöhen. Dies wiederum verbessert auch die vom LLM generierte Antwort. Außerdem können wir die dichte Einbettung auf Wunsch mit der Filterung von Metadaten kombinieren.
Wenn Sie Milvus in der Cloud verwenden möchten, sei es auf GCP oder AWS, um Milliarden von Einbettungen zu speichern, können Sie sich für[ seinen verwalteten Dienst: Zilliz Cloud] (https://zilliz.com/cloud) entscheiden.
Mit Zilliz Cloud können Sie Cluster-Einheiten (CUs) erstellen, die sowohl für die Kapazität als auch für die Leistung optimiert sind, um große Einbettungen zu speichern. Sie können zum Beispiel 256 leistungsoptimierte CUs für 1,3 Milliarden 128-dimensionale Vektoren oder 128 kapazitätsoptimierte CUs für 3 Milliarden 128-dimensionale Vektoren erstellen.
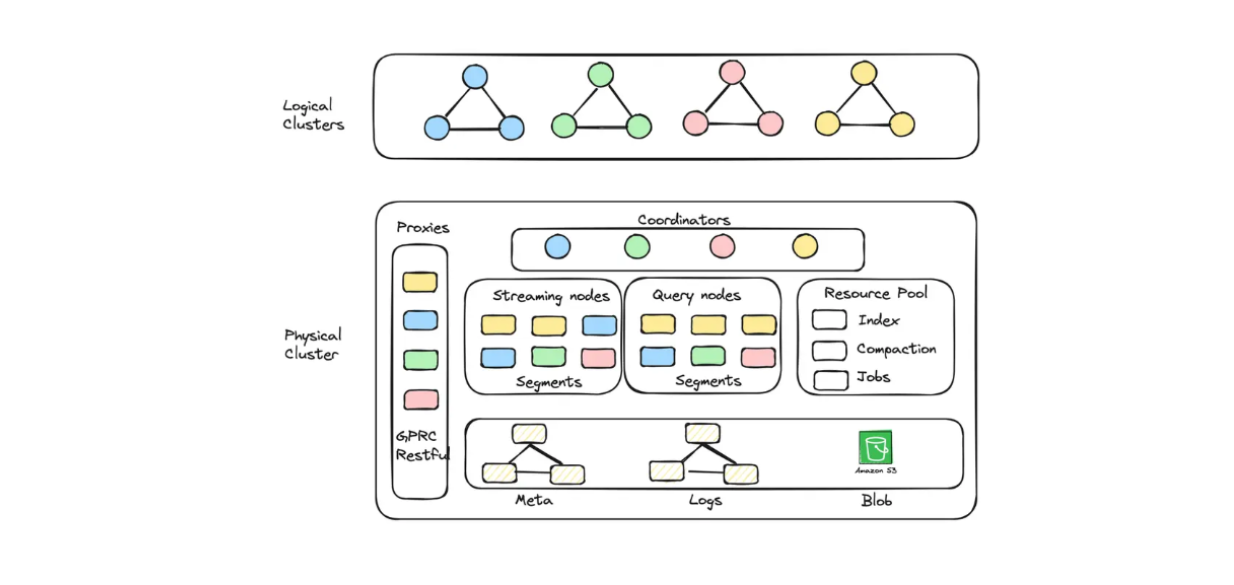 Diagramm des logischen Clusters und der automatischen Skalierung, implementiert in Zilliz Cloud Serverless..png
Diagramm des logischen Clusters und der automatischen Skalierung, implementiert in Zilliz Cloud Serverless..png
Diagramm des logischen Clusters und der automatischen Skalierung in der Zilliz Cloud Serverless.png
Wenn Sie eine RAG-Anwendung mit Milvus aufbauen möchten, aber auch Betriebskosten sparen wollen, können Sie sich für Zilliz Cloud Serverless entscheiden. Dieser Service bietet eine automatische Skalierungsfunktion innerhalb von Milvus, wobei die Kosten nur dann steigen, wenn Ihr Unternehmen wächst. Die serverlose Option eignet sich auch perfekt für Kosteneinsparungen, da Sie nur zahlen, wenn Sie den Dienst nutzen, und nicht, wenn er im Leerlauf ist.
Zilliz Cloud hat in letzter Zeit mehrere aufregende Updates auf den Markt gebracht, darunter einen neuen Migrationsdienst, mehrere Replikate, eine neue Integration mit Fivetran-Konnektoren, eine automatische Skalierungsfunktion und viele weitere produktionsreife Funktionen. Weitere Details finden Sie unten:
[Zilliz Cloud Update: Migrationsdienste, Fivetran-Konnektoren, Multireplikate und mehr] (https://zilliz.com/blog/zilliz-sep-24-launch)
KI-unterstützte Suche mit Fivetran und Milvus](https://zilliz.com/blog/unlock-ai-powered-search-with-fivetran-and-milvus)
Die 5 wichtigsten Gründe für die Migration von Open Source Milvus zu Zilliz Cloud](https://zilliz.com/blog/top-5-reasons-to-migrate-milvus-to-zilliz-cloud)
Retrieval-Techniken
Das Hauptziel der Retrieval-Komponente ist es, die k relevantesten Kontexte für eine gegebene Anfrage zu finden. Eine große Herausforderung in dieser Komponente, die die Gesamtqualität unserer RAG beeinträchtigen könnte, liegt jedoch in der Anfrage selbst. Ursprüngliche Abfragen sind oft schlecht geschrieben oder ausgedrückt und enthalten nicht die semantischen Informationen, die RAG-Anwendungen benötigen, um relevante Kontexte zu finden.
Zu den häufig angewandten Techniken zur Lösung dieses Problems gehören:
Query Rewriting: Der LLM wird aufgefordert, die ursprüngliche Abfrage umzuschreiben, um ihre Klarheit und semantischen Informationen zu verbessern.
Abfragezerlegung: Zerlegt die ursprüngliche Abfrage in Unterabfragen und führt die Abfrage auf der Grundlage dieser Unterabfragen durch.
Pseudo-Dokumentengenerierung](https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings): Erzeugt hypothetische oder synthetische Dokumente auf der Grundlage der ursprünglichen Abfrage und verwendet dann diese hypothetischen Dokumente, um ähnliche Dokumente in der Datenbank abzurufen. Die bekannteste Implementierung dieses Ansatzes ist HyDE (Hypothetical Document Embeddings).
Experimente zeigen, dass die Kombination von HyDE und hybrider Suche bei TREC DL19/20 im Vergleich zu Query Rewriting und Query Decomposition die besten Ergebnisse liefert. Die im Experiment erwähnte hybride Suche kombiniert LLM Embedder, um dichte Einbettungen zu erhalten und BM25, um spärliche Einbettungen zu erhalten.
Der Arbeitsablauf von HyDe + Hybridsuche ist wie folgt: Zuerst wird ein hypothetisches Dokument erzeugt, das die Anfrage mit HyDE beantwortet. Anschließend wird dieses hypothetische Dokument mit der ursprünglichen Anfrage verknüpft, bevor es mithilfe von LLM Embedder und BM25 in dense and sparse embeddings umgewandelt wird.
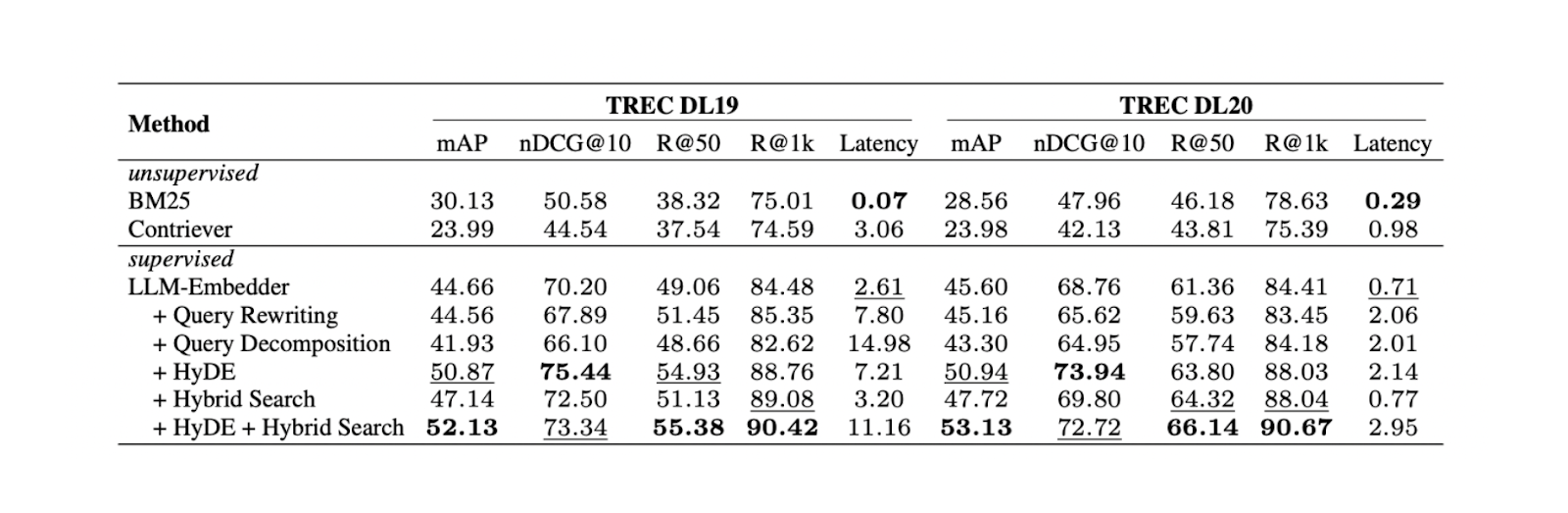 Ergebnisse für verschiedene Retrieval-Methoden. .png
Ergebnisse für verschiedene Retrieval-Methoden. .png
Ergebnisse für verschiedene Retrieval-Methoden. Quelle
Obwohl die Kombination aus HyDE und hybrider Suche die besten Ergebnisse liefert, ist sie auch mit höheren Rechenkosten verbunden. Weitere Tests mit verschiedenen NLP-Datensätzen ergaben, dass sowohl die hybride Suche als auch die ausschließliche Verwendung von dichten Einbettungen zu einer vergleichbaren Leistung wie HyDE + hybride Suche führen, jedoch mit einer fast 10-mal geringeren Latenzzeit. Daher ist die Verwendung einer hybriden Suche empfehlenswerter.
Da wir eine hybride Suche verwenden, basieren die abgerufenen Kontexte auf [Vektorsuche] (https://zilliz.com/learn/vector-similarity-search) aus dichten und spärlichen Einbettungen. Daher ist es auch interessant, die Auswirkungen des Gewichtungswertes zwischen dichten und spärlichen Einbettungen auf die Gesamtrelevanzbewertung gemäß dieser Gleichung zu untersuchen:
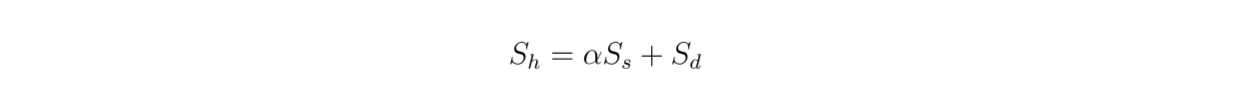 formula.png
formula.png
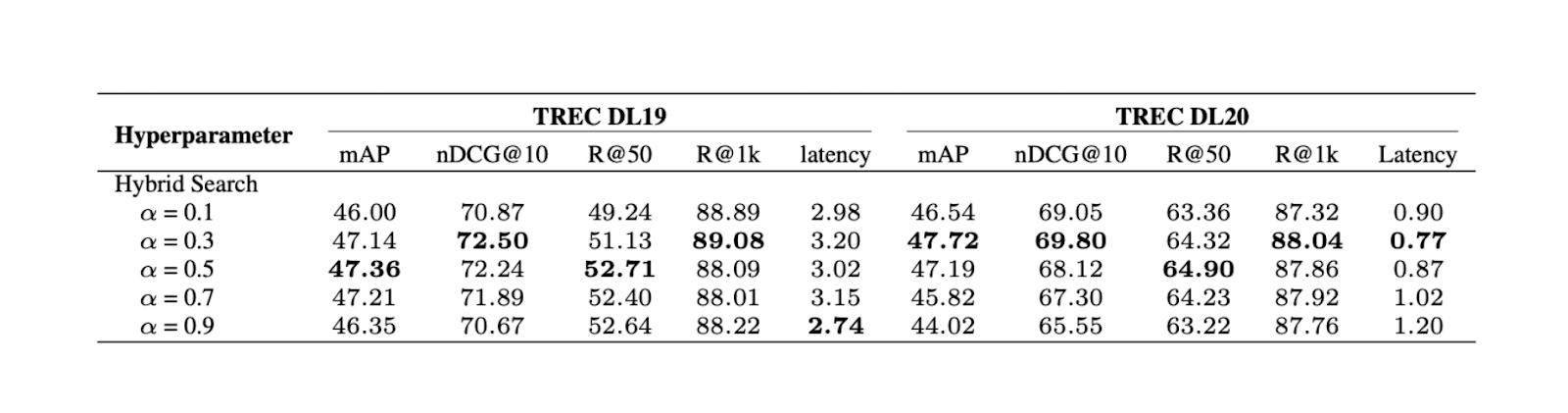 Abbildung- Ergebnisse der Hybridsuche mit verschiedenen Alphawerten..png
Abbildung- Ergebnisse der Hybridsuche mit verschiedenen Alphawerten..png
Abbildung: Ergebnisse der hybriden Suche mit verschiedenen Alphawerten. Quelle.
Das Experiment zeigt, dass ein Gewichtungswert von 0,3 die beste Gesamtrelevanzbewertung bei TREC DL19/20 ergibt.
Reranking und Repacking-Techniken
Das Hauptziel von [Reranking-Techniken] (https://zilliz.com/learn/what-are-rerankers-enhance-information-retrieval) besteht darin, die k relevantesten Kontexte, die von der Retrieval-Methode abgerufen werden, neu zu ordnen, um sicherzustellen, dass der ähnlichste Kontext an die Spitze der Liste gesetzt wird. Es gibt zwei gängige Ansätze, um die Kontexte neu zu ordnen:
DLM Reranking: Bei dieser Methode wird ein Deep-Learning-Modell für das Reranking verwendet. Das Modell wird mit einem Paar aus der ursprünglichen Abfrage und einem Kontext als Eingabe und einem binären Label "wahr" (wenn das Paar füreinander relevant ist) oder "falsch" als Ausgabe trainiert. Die Kontexte werden dann auf der Grundlage der Wahrscheinlichkeit sortiert, die das Modell liefert, wenn es ein Paar von Abfragen und Kontext als "wahr" vorhersagt.
TILDE Reranking: Bei diesem Ansatz wird die Wahrscheinlichkeit jedes Begriffs in der ursprünglichen Abfrage für das Reranking verwendet. Während der Inferenzzeit können wir entweder die Abfragelikelihood-Komponente (TILDE-QL) allein für ein schnelleres Reranking oder die Kombination von TILDE-QL mit seiner Dokumenten-Likelihood-Komponente (TILDE-DL) verwenden, um das Reranking-Ergebnis bei höheren Rechenkosten zu verbessern.
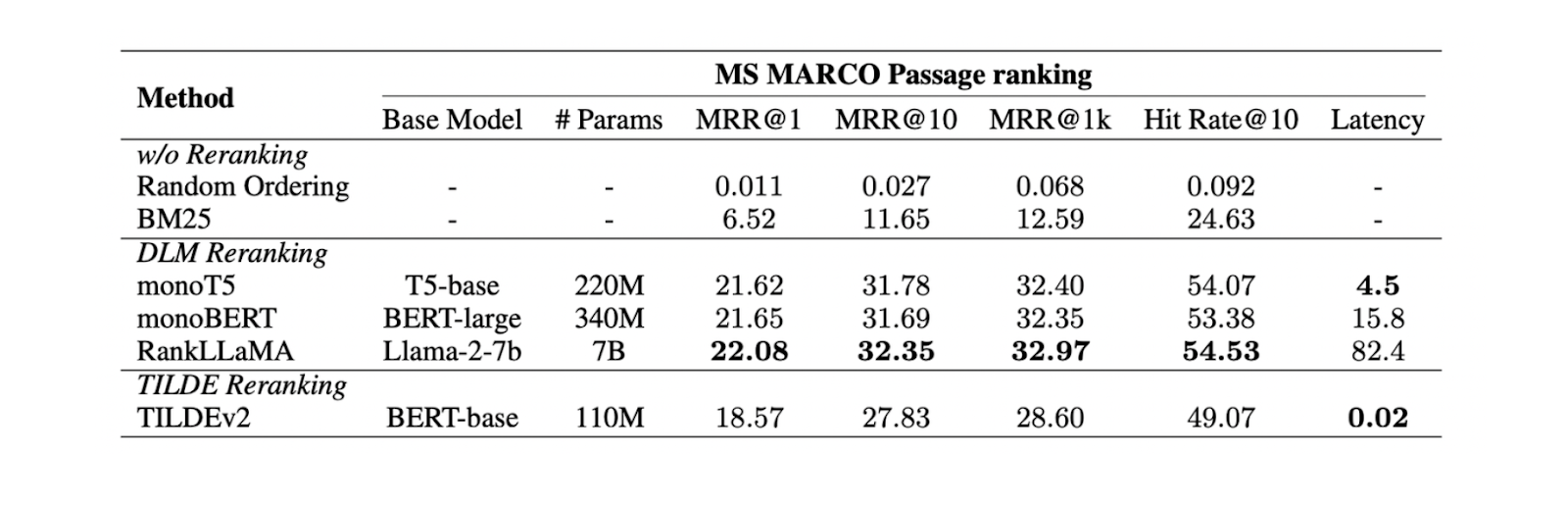 Abbildung- Ergebnisse der verschiedenen Reranking-Methoden..png
Abbildung- Ergebnisse der verschiedenen Reranking-Methoden..png
Abbildung: Ergebnisse der verschiedenen Ranking-Methoden. Quelle
Experimente mit dem MS MARCO Passage Ranking-Datensatz zeigen, dass die DLM-Reranking-Methode mit dem Llama 27B-Modell die beste Reranking-Leistung erbringt. Da es sich jedoch um ein großes Modell handelt, ist seine Verwendung mit einem erheblichen Rechenaufwand verbunden. Daher wird für das DLM-Reranking eher die Verwendung von mono T5 empfohlen, da es ein Gleichgewicht zwischen Leistung und Recheneffizienz bietet.
Nach der Reranking-Phase müssen wir auch überlegen, wie wir die neu gerankten Kontexte unserem LLM präsentieren: in absteigender ("forward") oder aufsteigender ("reverse") Reihenfolge. Aus den in dieser Arbeit durchgeführten Experimenten lässt sich schließen, dass die beste Antwortqualität bei der "umgekehrten" Konfiguration erzielt wird. Die Hypothese ist, dass die Positionierung relevanterer Kontexte näher an der Anfrage zu optimalen Ergebnissen führt.
Zusammenfassungstechniken
In Fällen, in denen wir lange Kontexte aus früheren Komponenten abrufen, möchten wir sie vielleicht kompakter gestalten und redundante Informationen entfernen. Um dieses Ziel zu erreichen, werden in der Regel Zusammenfassungsmethoden eingesetzt.
Es gibt zwei verschiedene Techniken zur Zusammenfassung von Kontexten: extraktiv und abstraktiv.
Bei der extraktiven Zusammenfassung wird das Eingabedokument in kleinere Segmente aufgeteilt, die dann nach ihrer Wichtigkeit geordnet werden. Bei der abstrakten Methode wird eine neue Kontextzusammenfassung erstellt, die nur relevante Informationen enthält.
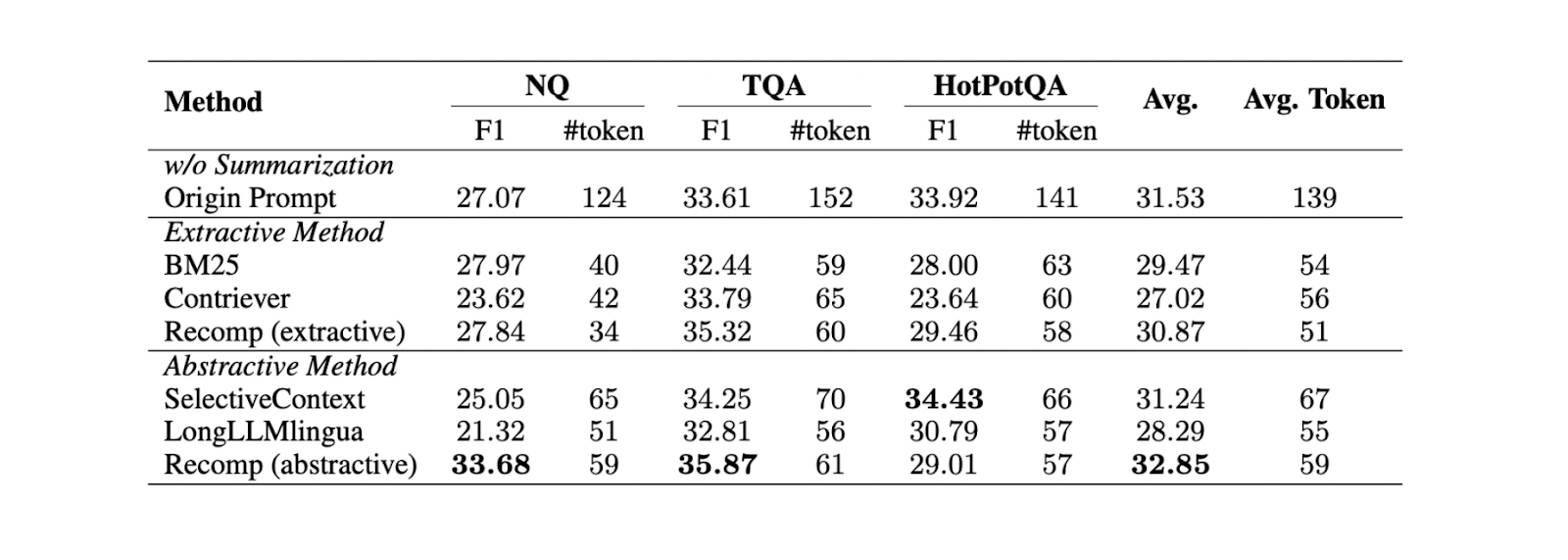 Abbildung- Vergleich zwischen verschiedenen Zusammenfassungsmethoden..png
Abbildung- Vergleich zwischen verschiedenen Zusammenfassungsmethoden..png
Abbildung: Vergleich zwischen verschiedenen Zusammenfassungsmethoden. Quelle
Basierend auf Experimenten mit drei verschiedenen Datensätzen (NQ, TriviaQA und HotpotQA) liefert die abstrakte Zusammenfassung mit Recomp die beste Leistung im Vergleich zu anderen abstrakten und extraktiven Methoden.
Die Zusammenfassung der besten RAG-Techniken
Da wir nun den besten Ansatz für jede RAG-Komponente für bestimmte Benchmark-Datensätze kennen, können wir alle in den vorherigen Abschnitten erwähnten Ansätze an weiteren Datensätzen testen. Die Ergebnisse zeigen, dass jede Komponente zur Gesamtleistung unserer RAG-Anwendung beiträgt. Im Folgenden finden Sie eine Zusammenfassung der Ergebnisse für jeden Ansatz in jeder Komponente auf der Grundlage von fünf verschiedenen Datensätzen:
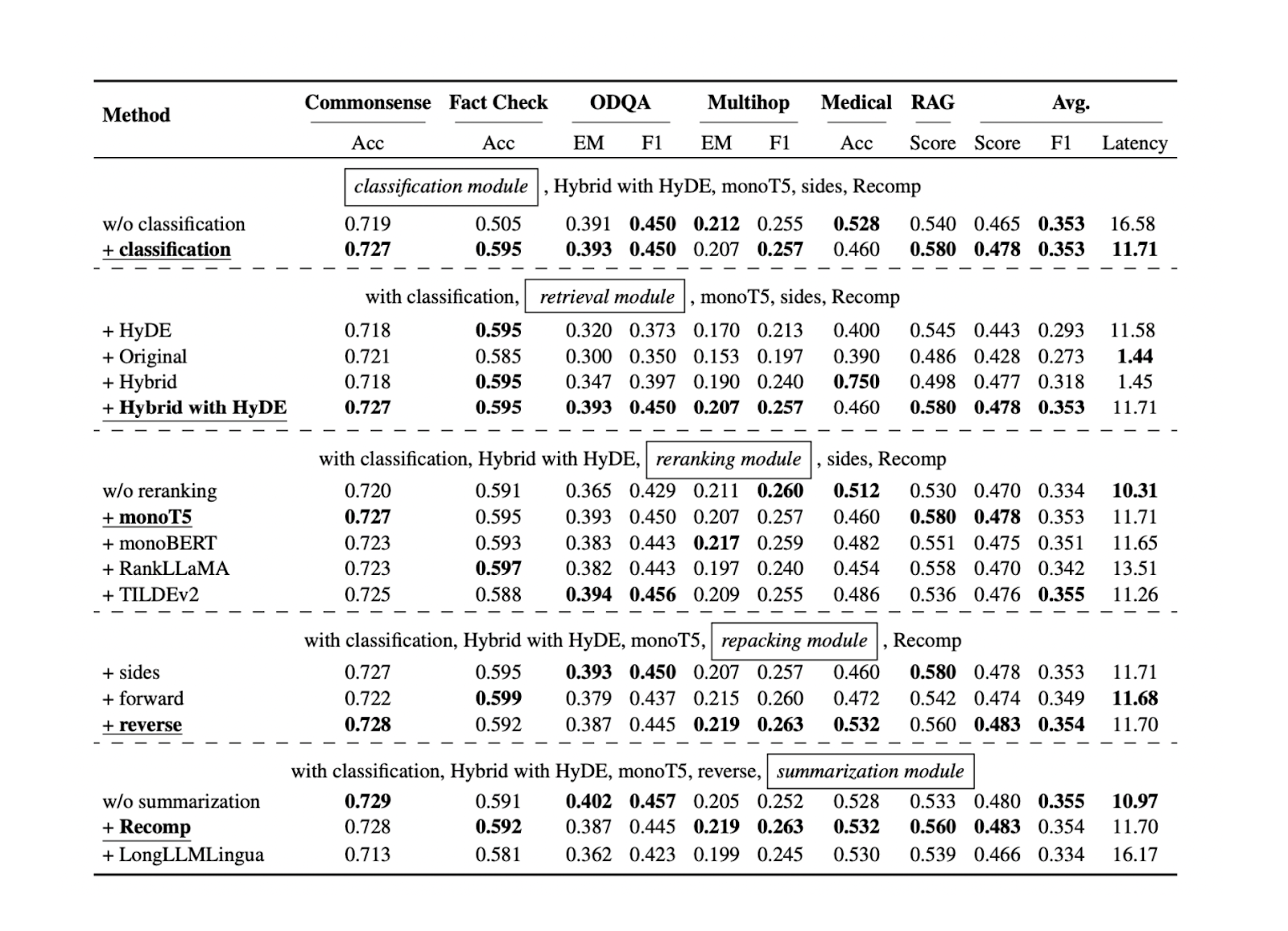 Abbildung- Ergebnisse der Suche nach optimalen RAG-Verfahren..png
Abbildung- Ergebnisse der Suche nach optimalen RAG-Verfahren..png
Abbildung: Ergebnisse der Suche nach optimalen RAG-Praktiken. Quelle
Die Abfrageklassifizierungskomponente trägt nachweislich dazu bei, die Genauigkeit der Antworten zu verbessern und die Gesamtlaufzeitlatenz zu verringern. Dieser erste Schritt hilft zu bestimmen, ob eine Anfrage eine Kontextabfrage erfordert oder direkt vom LLM verarbeitet werden kann, wodurch die Effizienz des Systems optimiert wird.
Die Abfragekomponente ist entscheidend, um sicherzustellen, dass wir relevante Kontextkandidaten für die Anfrage erhalten. Für diese Komponente wird eine skalierbarere und leistungsfähigere Vektordatenbank wie [Milvus] (https://milvus.io/docs/overview.md) oder ihr verwalteter Dienst, [Zilliz Cloud] (https://zilliz.com/cloud), empfohlen. Darüber hinaus wird eine hybride Suche oder eine Suche mit dichter Einbettung empfohlen. Diese Methoden schaffen ein Gleichgewicht zwischen umfassendem Kontextabgleich und Recheneffizienz.
Die Reranking-Komponente stellt sicher, dass wir die relevantesten Kontexte erhalten, indem die obersten k Kontexte, die von der Retrieval-Komponente abgerufen werden, neu geordnet werden. Für das Reranking wird das Modell monoT5 empfohlen, da es ein ausgewogenes Verhältnis zwischen Leistung und Rechenkosten bietet. In diesem Schritt wird die Auswahl der Kontexte verfeinert, indem die relevantesten Kontexte für die Anfrage priorisiert werden.
Für das Umpacken der Kontexte wird die umgekehrte Methode empfohlen. Dieser Ansatz positioniert den relevantesten Kontext am nächsten zur Anfrage, was zu genaueren und kohärenteren Antworten des LLM führen kann.
Schließlich hat die abstrakte Methode mit Recomp die beste Leistung bei der Zusammenfassung von Kontexten gezeigt. Diese Technik trägt dazu bei, lange Kontexte zu verdichten und dabei die wichtigsten Informationen zu erhalten, was es dem LLM erleichtert, sie zu verarbeiten und relevante Antworten zu generieren.
LLM-Feinabstimmung
In den meisten Fällen ist eine LLM-Feinabstimmung nicht notwendig, insbesondere wenn Sie einen leistungsfähigen LLM mit vielen Parametern verwenden. Wenn Sie jedoch Hardware-Einschränkungen haben und nur kleinere LLMs verwenden können, müssen Sie sie möglicherweise feinabstimmen, um sie robuster zu machen, wenn Sie Antworten in Bezug auf Ihren Anwendungsfall erzeugen. Vor der Feinabstimmung eines LLM müssen Sie die Daten berücksichtigen, die Sie als Trainingsdaten verwenden werden.
Während der Datenvorbereitung können Sie Trainingsdaten in Form von Eingabeaufforderung und Kontext als ein Paar von Eingaben sammeln, mit einem Beispiel von generiertem Text als Ausgabe. Experimente zeigen, dass die beste Leistung erzielt wird, wenn Sie Ihre Daten während des Trainings mit einer Mischung aus relevanten und zufällig ausgewählten Kontexten anreichern. Die Intuition dahinter ist, dass das Mischen von relevanten und zufälligen Kontexten während der Feinabstimmung die Robustheit unseres LLMs verbessern kann.
Schlussfolgerung
In diesem Artikel haben wir verschiedene RAG-Komponenten untersucht, von der Abfrageklassifizierung bis hin zur Kontextzusammenfassung. Wir haben die Ansätze mit optimaler Leistung in jeder Komponente diskutiert und hervorgehoben.
Diese optimierten Komponenten arbeiten zusammen, um die Gesamtleistung des RAG-Systems zu verbessern. Sie verbessern die Qualität und Relevanz der generierten Antworten bei gleichzeitiger Beibehaltung der Berechnungseffizienz. Durch die Implementierung dieser Best Practices in jeder Komponente können wir ein robusteres und effektiveres RAG-System schaffen, das in der Lage ist, ein breites Spektrum von Abfragen und Aufgaben zu bewältigen.
Weitere Lektüre
Leistungsstärkste KI-Modelle für Ihre GenAI-Anwendungen | Zilliz
KI-Anwendungen mit Milvus erstellen: Tutorials & Notebooks](https://zilliz.com/learn/milvus-notebooks)
Wie man einen mehrsprachigen RAG mit Milvus, LangChain und OpenAI erstellt
Erstellen eines multimodalen RAG mit Gemini, BGE-M3, Milvus und LangChain
Was ist GraphRAG? Erweiterung von RAG mit Wissensgraphen ](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
Wie man RAG-Anwendungen evaluiert ](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
Weiterlesen

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.