




Webinar Recap: Retrieval Techniques for Accessing the Most Relevant Context for LLM Applications
Connecting large language models (LLMs) with external data sources is crucial to improve the performance of many AI applications. These connections involve linking with pre-existing data collections, recalling user conversations, or generating "new memories" through reflection. Retrieval is extracting relevant information from connected external sources and incorporating it into the query to provide context.
In our recent webinar, Harrison Chase, Co-founder and CEO of LangChain, and Filip Haltmayer, Software Engineer at Zilliz, discussed retrieval with LangChain and vector databases, semantic search, and its edge cases. In this post, we'll explore the key takeaways from the webinar and address some of the audience's unanswered questions.
What is retrieval, and why is it important?
In general, retrieval refers to accessing information from memory or other storage devices. During the webinar, Harrison explained how we could leverage retrieval techniques to bring external knowledge to LLMs using a vector database like Milvus and an AI agent like LangChain.
While LLMs are very powerful, they have limitations since they only know the pre-trained information, which may need updating. For instance, ChatGPT's data only covers up to the year 2021, so they don't know what happened afterward. LLMs also lack data about domain-specific or proprietary information and data about your business and project. Additionally, even if the information is present within the LLM, recognizing it may be challenging. In such cases, retrieval can be a great supplement to give LLMs more context for more accurate answers or bring the target information already in the LLM to the forefront.
Semantic search overview
Retrieval through semantic search is one of the most critical use cases. During the recent webinar, Harrison provided an overview of how semantic search functions within a typical CVP architecture (ChatGPT+Vector store+Prompt as code).
The following diagram explains how semantic search works in a CVP stack. If a user asks a general question that the LLM can answer, the LLM responds directly to the question. However, if the question is domain-specific, it is transformed into vectors and sent to a vector database, such as Milvus, that already contains relevant documents. The vector database breaks down the pre-stored records into chunks and embeddings, performs semantic searches to find the top-k most relevant results for the user's query, and then sends these results to an AI agent, such as LangChain, along with the user's query. LangChain combines the results with the user's question and sends them to the LLM. The LLM then provides a satisfying response.
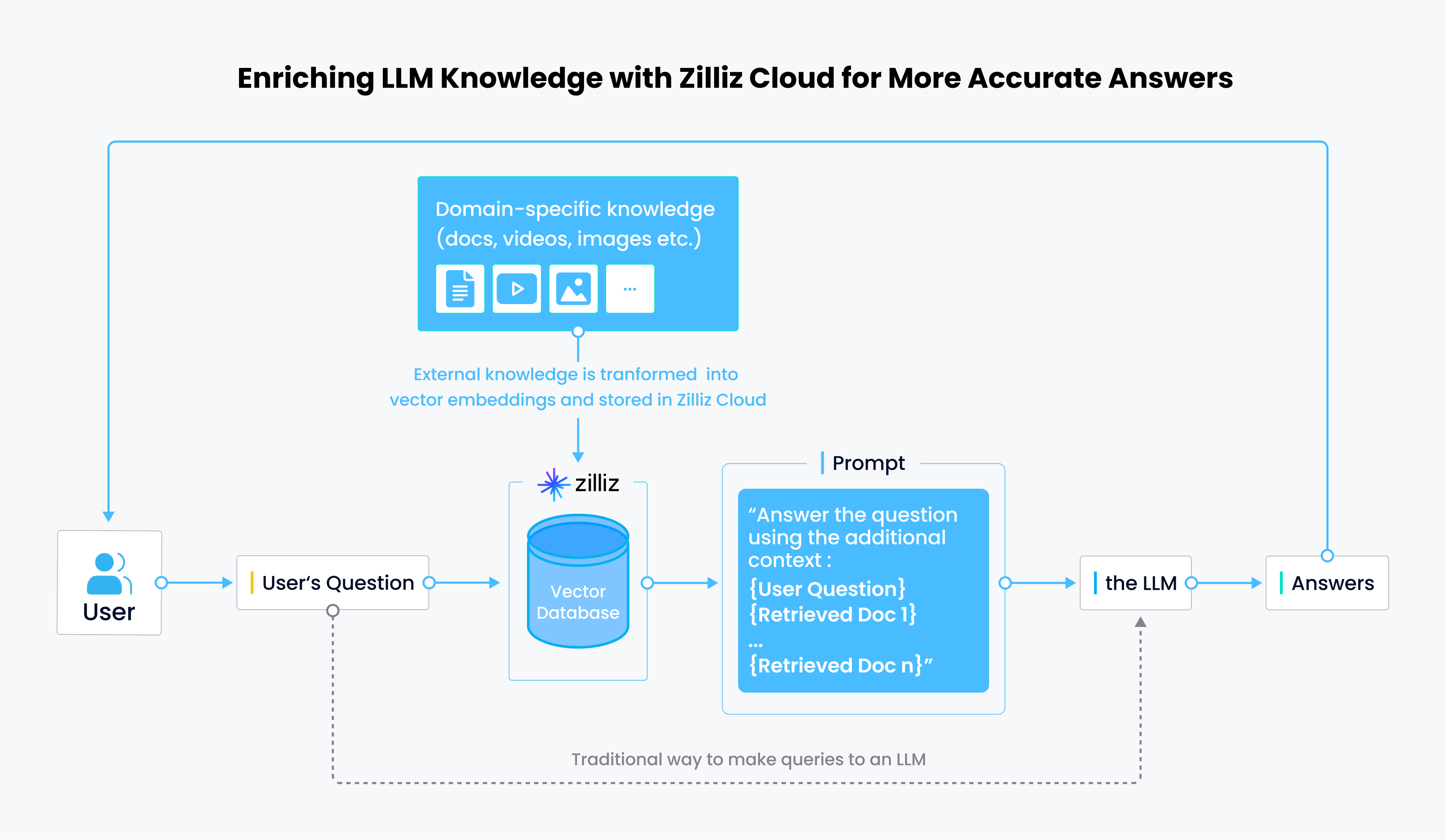 How semantic search works in a typical CVP stack
How semantic search works in a typical CVP stack
Edge cases of semantic search
Semantic search has been used for a while and has proven helpful in addressing many challenges. Harrison demonstrated five edge cases of semantic searches during the webinar and thoroughly analyzed each case.
Repeated information
When dealing with numerous similar or copied documents, retrieving relevant information can be challenging. This type of content is not suited for LLMs and can create unnecessary context. Harrison proposed three solutions to overcome this issue:
Filter out similar documents through semantic searches before sending them to the LLM. For instance, before LangChain sends the prompts to ChatGPT, it retrieves 20-30 documents and eliminates similar ones through embeddings or bypasses them to the LLM.
Leverage max marginal relevance to optimize diversity. This search focuses on similarity and diversity from other retrieved vectors.
Deduplicate documents before storing them in the vector database. However, this approach can be challenging as determining the similarity score that equates to a duplicate takes a lot of work. One vector element could be vastly different, resulting in significant differences.
Conflicting information
Conflicting information occurs when multiple sources provide different answers to a question, which can be very confusing if you present all of the data to an LLM. For instance, if you inquire about your company's vacation policy, you may receive different responses from sources like the HR document and some random meeting notes.
Harrison proposed two solutions to this problem:
Prioritize sources and build that ranking into retrieval.
Pass the source information to the generation step, allowing the LLM to decide which source is more reliable.
Temporality
When information changes over time, it is called temporality. For instance, your company's vacation policy may change occasionally.
To tackle this problem, Harrison proposes three solutions:
Recency weighting in retrieval: filtering out outdated information completely.
Including timestamps while generating information: asking the LLM to rely on more recent information.
Reflection: revising the understanding of a topic over time.
Metadata querying
Sometimes, users ask questions that are more about metadata than content. For instance, a user may query movies featuring aliens in 1980. While "movies about aliens" can be searched semantically, 1980 is more of an exact match.
So, how can we solve this problem? Harrison suggests generating a metadata filter before performing a semantic search retrieval. This approach involves dividing the question into two parts: the metadata filter (which is an exact match, like "year equals 1980") and the query (like "aliens or something" in this case).
But how do we apply the metadata filter? Many vector stores allow the direct inclusion of metadata filters in the query. If that isn't possible, filtering the results after retrieval is still possible.
Multi-hop questions
Sometimes, users may ask multiple questions at once, making it difficult for the semantic search to retrieve all the necessary information from the original question.
Harrison suggested that we use AI agents like LangChain to tackle this challenge. LangChain can break down the question into several steps and use the language model as a reasoning engine to retrieve the required information. However, this compelling approach may generate many LLM calls, leading to higher costs.
Filip recommended integrating GPTCache with LangChain because GPTCache can store questions and answers generated by the LLM. When users make similar queries next time, GPTCache performs semantic searches and gives responses before querying the LLM, thus saving users money on LLM calls.
Q&A
We received a lot of questions from our audience during the webinar and appreciated their participation. Harrison and Filip answered some of the questions during the Q&A session, but due to time constraints, some were left unanswered. Below, we have compiled a list of the questions and answers.
Q: Can you talk more about generating prompts using external knowledge sources? What are some examples or tricks that you have used? Is LangChain planning to add features that create optimized prompts?
The key to prompting is to be clear about what you want. If you don’t clearly express all your intentions and the relevant information, the LLM will not know what to do, just like a human would not know what to do. Yes, we will add some features around prompt optimization.
Q: How do you see the current landscape of retrieval augmented generation? There are many solutions like Langchain, Llama Index, Vectara, and others. What is the best solution to fine-tune the retrieval steps, including router query engines and others? You have mentioned that retrieval could differentiate the importance of documents, and is this available through LangChain already?
The whole space is still in an early stage and moving super fast. I’ll distinguish the retrieval step and the generation step. On retrieval, I would argue LangChain provides the most flexibility and modularity for customizing a vector-based retrieval system. Vectara is an excellent end-to-end fully managed solution for retrieval, which abstracts away a lot of the details. LlamaIndex provides some more interesting data structures like trees to experiment with. Regardless of the retrieval step you choose, all are using LangChain during the generation step — we have integrations with all three. You can accomplish that differentiation with customized prompts.
Q: How do you expect the use cases for retrieval and associated tradeoffs to be affected as LLM context limits increase over time?
Why is it still necessary to have a vector database for extended context transformers like Anthropic's 100k context length LLM? Well, vector databases offer a much more cost-effective solution. When it comes to these LLMs, they do all the heavy computation work, while the vector database takes care of storage. Please be aware that computing expenses can add up quickly. So, if you want to cram more context into your LLMs, you must deal with those increased costs. That's where the beauty of a vector database comes in. It's a cost-effective alternative because most expenses are related to computation, which is always 100 times more expensive.
Long-range dependencies — LLMs can still forget stuff from "early" in the conversation, even with the transformer architecture.
Q: What are your thoughts on open-source projects to put out pre-vectorized content? Cohere put out Wikipedia, and another project has put out arXiv abstracts. What’s the best model for putting out open-sourced vector content?
It's a great idea to learn about semantic search and avoid the extra time and cost of generating the vectors. Outside of this, having the vectors precomputed severely limits you as it does not allow you to modify how or what is getting embedded. Regarding the best model, there isn’t one giving the best results for the data you are using—the more popular the model you use, the higher the chance your dataset will be used.
Q: How does the memory subpackage work in LangChain? Why is chat message history separated from memory? Why did you design it this way?
We are working on a revamp of memory to make this more clear.
Watch the complete webinar recording!
Watch the webinar recording for more information about LangChain and the discussion between Filip and Harrison.

Keep Reading

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.