




Introducing the Databricks Connector, a Well-Lit Solution to Streamline Unstructured Data Migration and Transformation
With the rapid evolution of AI and machine learning (AI/ML) technologies, vector embeddings have become the method of choice for indexing unstructured data and conducting semantic searches.
The AI-driven search typically comprises two distinct phases: offline data indexing and online query serving, necessitating the utilization of different technological stacks. However, attempting to seamlessly transition data from the offline processing stack to the online serving stack efficiently can be challenging. The latest release of Zilliz Cloud introduces a Databricks Connector, a well-lit solution to streamline this process by integrating Apache Spark/Databricks and Milvus/Zilliz Cloud.
In this post, we’ll introduce this integration, explore its practical usage in real-world scenarios, and walk you through how to use it.
How the Databricks Connector works and its use cases
Spark is renowned for its capacity to process large-scale data and its proficiency in machine learning. On the other hand, Milvus excels in efficiently handling and searching vector embeddings generated by machine learning models. Combining these two powerhouse technologies facilitates the development of cutting-edge applications in fields like Generative AI, recommendation systems, and image and video search.
Transferring data from Spark to Milvus is a common task in building AI-powered search, but it often involves intricate glue code in the backend of the search system. The Spark-Milvus connector simplifies this process, condensing it into a single function call within the Spark program.
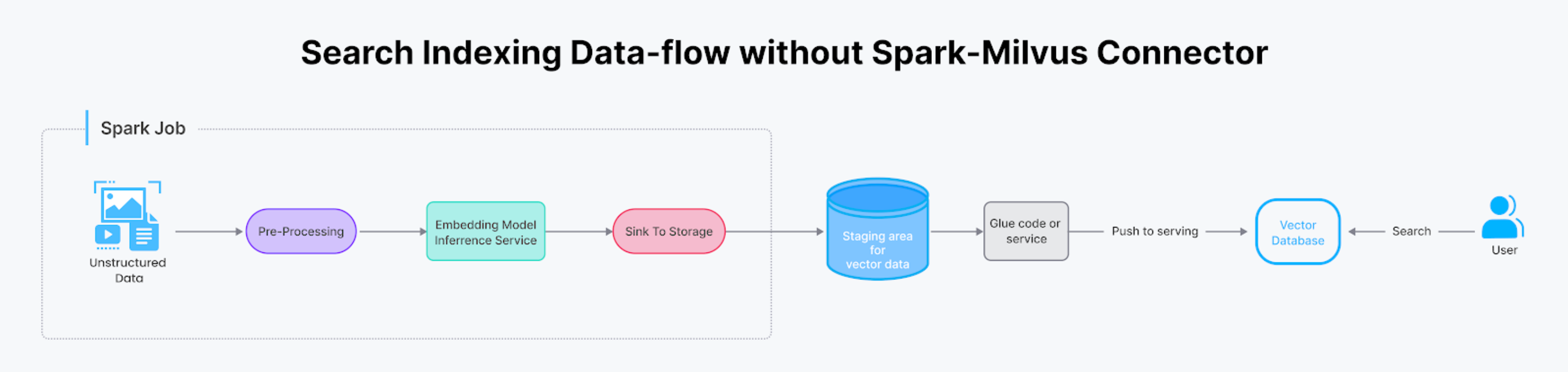
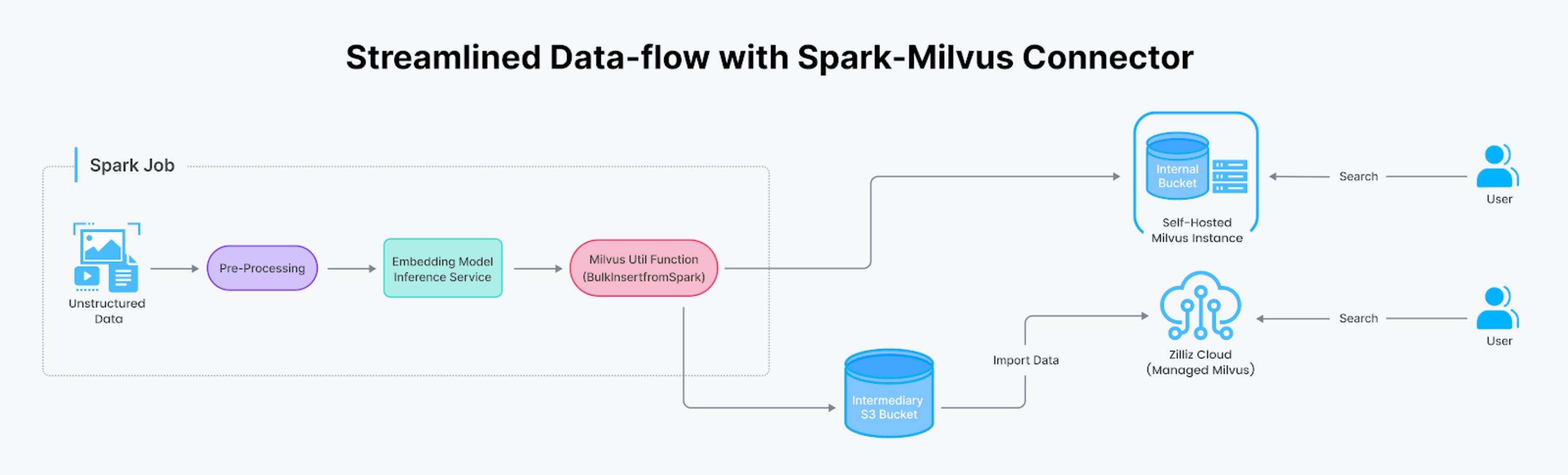
This connector proves beneficial in various scenarios.
Batch data import
Teams with machine learning expertise often update their embedding models to incorporate the latest research findings. After each upgrade to the embedding model, requiring the entire data corpus to undergo reprocessing by the Spark job and generating a new set of vectors, teams often need custom 'glue code,' a dedicated service, or another Spark job to integrate these new vectors into the serving stack. However, with the Databricks Connector, this task becomes as simple as granting the job access to write to the S3 bucket of Milvus (or an ephemeral bucket when using Zilliz Cloud). This streamlined process allows the vector-generating Spark job to load data directly into the Milvus instance through a straightforward utility function call.
Iterative insertion
Users not operating at large scales can also benefit from directly inserting Spark DataFrame records into Milvus using the Spark-Milvus connector. This approach saves the effort of writing connection-establishing code and API calls, making the integration process smoother.
How to use the Databricks Connector
This section demonstrates using the Databricks Connector to streamline data migration and transformation.
Inserting a Spark Dataframe iteratively
With the Spark-Milvus connection, streaming data from Spark to Milvus has never been easier. You can now directly push data from Spark to Milvus with Spark's native Dataframe API. The same code also works for Databricks and Zilliz (fully managed Milvus). Here's a code snippet that demonstrates this approach:
// Specify the target Milvus instance and vector data collection
df.write.format("milvus")
.option(MILVUS_URI, "https://in01-xxxxxxxxx.aws-us-west-2.vectordb.zillizcloud.com:19535")
.option(MILVUS_TOKEN, dbutils.secrets.get(scope = "zillizcloud", key = "token"))
.option(MILVUS_COLLECTION_NAME, "text_embedding")
.option(MILVUS_COLLECTION_VECTOR_FIELD, "embedding")
.option(MILVUS_COLLECTION_VECTOR_DIM, "128")
.option(MILVUS_COLLECTION_PRIMARY_KEY, "id")
.mode(SaveMode.Append)
.save()
Batch load a collection
We recommend using the `MilvusUtils. bulkInsertFromSpark ()` function for situations where you need to transfer large volumes of data efficiently. This approach is super-efficient for handling huge datasets.
Approach for Milvus
The integration involves S3 or MinIO buckets for self-hosted Milvus instances as internal storage. By granting access to Spark or Databricks, the Spark job can use Milvus connectors to write data to the bucket in batch and then bulk-insert the entire collection for serving.
// Write the data in batch into the Milvus bucket storage.
val outputPath = "s3a://milvus-bucket/result"
df.write
.mode("overwrite")
.format("parquet")
.save(outputPath)
// Specify Milvus options.
val targetProperties = Map(
MilvusOptions.MILVUS_HOST -> host,
MilvusOptions.MILVUS_PORT -> port.toString,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// Bulk insert Spark output files into Milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "parquet")
An Approach for Zilliz Cloud
If you are using Zilliz Cloud (the managed Milvus), you can leverage its convenient Data Import API. Zilliz Cloud provides comprehensive tools and documentation to help you efficiently move your data from various data sources, including Spark. By setting up an S3 bucket as an intermediary and granting access to Zilliz Cloud, the Data Import API seamlessly loads data from the S3 bucket to the vector database.
Before running this integration, you must load the Spark runtime by adding a jar file to the Databricks Cluster. There are different ways to install a library. The screenshot below shows uploading a jar from local to the cluster.
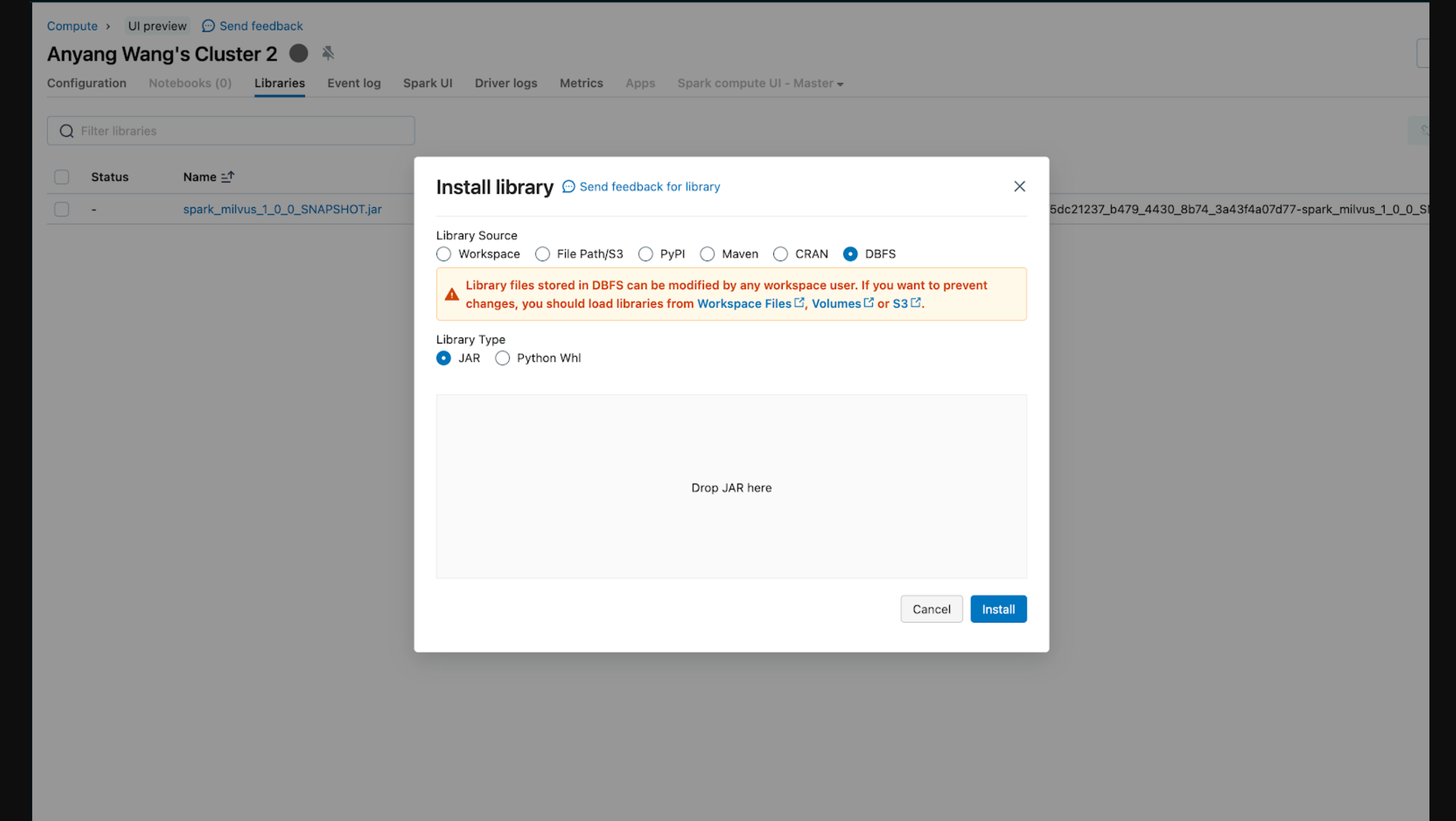
For more details about installing a library in the Databricks workspace, refer to Databrick's official documentation to learn more.
Bulk insert requires storing data in a temporary bucket so Zilliz Cloud can import it in batches. You can create an S3 bucket and configure it as an external location of Databricks. Refer to this documentation for details. To reduce the security risk of your Zilliz Cloud credentials, you can securely manage them on Databricks by following the Databricks instructions.
Here's a code snippet showcasing the batch data migration process. Similar to the above Milvus example, you just need to replace the credential and S3 bucket address.
// Write the data in batch into the Milvus bucket storage.
val outputPath = "s3://my-temp-bucket/result"
df.write
.mode("overwrite")
.format("mjson")
.save(outputPath)
// Specify Milvus options.
val targetProperties = Map(
MilvusOptions.MILVUS_URI -> zilliz_uri,
MilvusOptions.MILVUS_TOKEN -> zilliz_token,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// Bulk insert Spark output files into Milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "mjson")
Putting it all together: a notebook example walking you through the whole process
To help you get started quickly, we have prepared a notebook example that walks you through the streaming and batch data transfer processes with Milvus and Zilliz Cloud.
Conclusion
The integration of Spark and Milvus presents exciting possibilities for AI-powered applications. With our streamlined approach to data portability, developers can effortlessly transfer data from Spark/Databricks to Milvus/Zilliz Cloud, whether in real-time or batch mode. This integration empowers you to build efficient and scalable AI solutions, unlocking the full potential of these powerful technologies.
Ready to embark on your AI journey? Start for free with Zilliz Cloud today with no installation hassles and without requiring a credit card.

Keep Reading

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.