




An Overview of Milvus Storage System and Techniques to Evaluate and Optimize Its Performance
Welcome to our exploration of Milvus, the open-source vector database known for its impressive horizontal scalability and lightning-fast performance. At the core of Milvus lies its robust storage system, a critical foundation for reliable data persistence and storage. This system comprises several essential components: meta storage, log broker, and object storage.
This guide will delve into Milvus' architecture, break down its key storage components, and explore effective techniques to evaluate their performance.
An Overview of the Milvus Architecture
Milvus adopts a distributed architecture that ensures storage and compute separation and supports horizontal scalability for its computing nodes. This setup is organized into four key layers: the access layer, coordinator service, worker nodes, and storage, each independently scalable and optimized for disaster recovery.
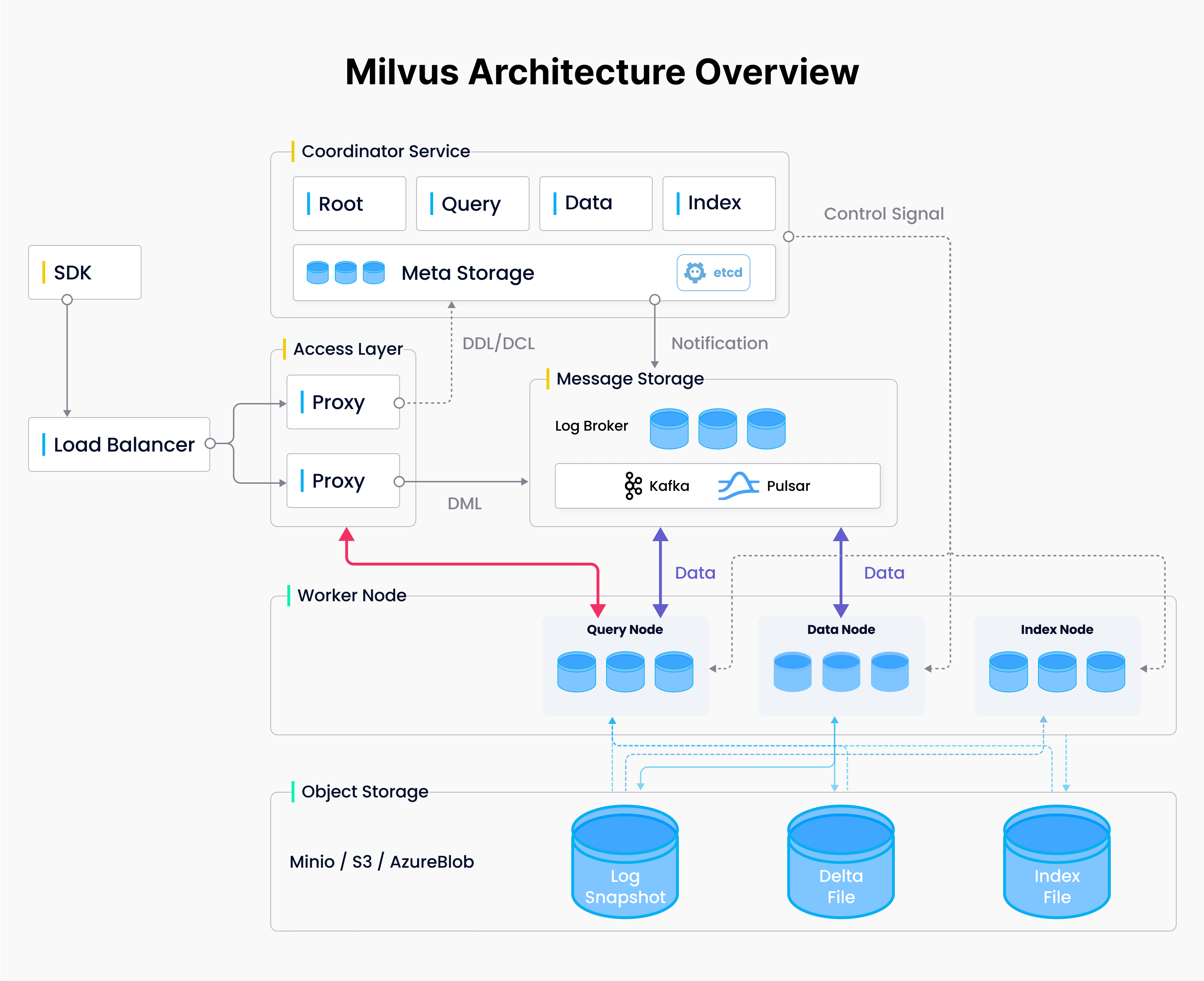 Milvus Architecture Overview.png
Milvus Architecture Overview.png
Access Layer: This front-end layer consists of stateless proxies that handle user requests and optimize responses, serving as the system’s primary user interface.
Coordinator Layer: Acting as the system's central command, the coordinator service manages task distribution, cluster topology, load balancing, and data management across worker nodes.
Worker Nodes: These are the executors that process Data Manipulation Language (DML) commands under the direction of the coordinator service.
Storage: Fundamental to data persistence, this layer includes meta storage, a log broker, and object storage, ensuring data integrity and availability.
Milvus Storage Components
Milvus uses three main storage components to ensure data integrity and availability: meta storage, object storage, and a log broker.
Meta storage
Meta storage in Milvus stores metadata snapshots, such as collection schemas, node statuses, and message consumption checkpoints. Given the need for high availability, strong consistency, and transaction support, Milvus utilizes etcd as its meta-storage solution. Etcd is a robust and distributed key-value store that is crucial to the distributed systems within Milvus. It handles tasks like service registration and health checks alongside metadata preservation.
Object storage
Object storage in Milvus handles the storage of log snapshot files, index files for scalar and vector data, and intermediate query results. Milvus integrates MinIO for object storage due to its high performance and compatibility with Kubernetes, facilitating seamless operation within cloud environments like AWS S3 and Azure Blob Storage.
Log broker
The log broker in Milvus adopts a pub-sub system with playback capabilities. It is essential for streaming data persistence, execution of reliable asynchronous queries, event notifications, and query result returns. It also ensures the integrity of incremental data during worker node recovery from system breakdowns. Depending on the deployment, Milvus uses different log broker tools. Milvus Cluster setups use Pulsar or Kafka, while Milvus standalone versions typically use RocksDB.
How to Evaluate and Optimize the Performance of Milvus Storage
Constantly evaluating and improving storage performance is crucial.
Etcd: The Metadata Store of Milvus
Etcd is a robust, distributed key-value store designed for distributed systems. In Milvus, etcd is a metadata store that stores essential data such as collection schemas, node statuses, and message consumption checkpoints.
Disk write latency is critical for etcd's performance; slow disk speed can significantly increase request latency and risk system stability. We recommend sustaining at least 500 sequential IOPS (input/output operations per second) for optimal performance in production environments, ensuring that 99% of the fdatasync durations remain below ten milliseconds. While etcd typically demands only moderate disk bandwidth, increasing this bandwidth can markedly reduce recovery times. Consequently, we recommend a baseline disk bandwidth of at least 100MB/s for production environments.
To verify whether your storage solution meets these criteria, consider conducting performance assessments using Fio, a disk benchmarking tool. Below is a guide on how to use Fio to evaluate your storage performance.
First, ensure Fio is installed on your system. Then, run the following command, specifying the directory where your storage is mounted as the test-data directory. This directory should be under your storage connection point.
fio --rw=write --ioengine=sync --fdatasync=1 --directory=test-data --size=22m --bs=2300 --name=mytest
Inspect the results to ensure that 99% of the fdatasync duration is less than 10ms and the write IOPS is higher than 500. If these conditions are met, your storage performs adequately.
Below is an example of the output results:
Jobs: 1 (f=1): [W(1)][100.0%][w=1771KiB/s][w=788 IOPS][eta 00m:00s]
mytest: (groupid=0, jobs=1): err= 0: pid=703: Mon Jul 25 08:36:48 2022
write: IOPS=967, BW=2173KiB/s (2225kB/s)(220MiB/103664msec); 0 zone resets
clat (nsec): min=1903, max=29662k, avg=287307.76, stdev=492386.04
lat (nsec): min=1981, max=29662k, avg=287583.67, stdev=492438.10
clat percentiles (usec):
| 1.00th=[ 3], 5.00th=[ 4], 10.00th=[ 4], 20.00th=[ 5],
| 30.00th=[ 6], 40.00th=[ 9], 50.00th=[ 233], 60.00th=[ 343],
| 70.00th=[ 437], 80.00th=[ 553], 90.00th=[ 701], 95.00th=[ 742],
| 99.00th=[ 1172], 99.50th=[ 2114], 99.90th=[ 6390], 99.95th=[ 8455],
| 99.99th=[15533]
bw ( KiB/s): min= 1630, max= 2484, per=100.00%, avg=2174.66, stdev=193.65, samples=207
iops : min= 726, max= 1106, avg=968.37, stdev=86.19, samples=207
lat (usec) : 2=0.03%, 4=16.49%, 10=27.68%, 20=3.21%, 50=0.71%
lat (usec) : 100=0.27%, 250=2.65%, 500=24.64%, 750=20.40%, 1000=2.57%
lat (msec) : 2=0.82%, 4=0.30%, 10=0.18%, 20=0.03%, 50=0.01%
fsync/fdatasync/sync_file_range:
sync (usec): min=309, max=21848, avg=741.93, stdev=489.64
sync percentiles (usec):
| 1.00th=[ 392], 5.00th=[ 437], 10.00th=[ 474], 20.00th=[ 529],
| 30.00th=[ 578], 40.00th=[ 619], 50.00th=[ 660], 60.00th=[ 709],
| 70.00th=[ 742], 80.00th=[ 791], 90.00th=[ 988], 95.00th=[ 1369],
| 99.00th=[ 2442], 99.50th=[ 3523], 99.90th=[ 6915], 99.95th=[ 8586],
| 99.99th=[11994]
When deploying a Milvus cluster in cloud environments, selecting the appropriate type of block storage for etcd is crucial due to its sensitivity to disk performance. Cloud providers offer various block storage options, each with distinct performance characteristics suited for different workloads.
Below are the recommended volume types and performance metrics from various cloud providers.
| Cloud Provider | Volume Type | SIZE | IOPS | P99 sync |
| AWS | gp3 | 20Gi | 660 | 4.3ms |
| GCP | pd-ssd | 20Gi | 1262 | 1.3ms |
| Azure | PremiumV2 | 20Gi | 705 | 2.6ms |
| Aliyun | cloud_essd | 20Gi | 1137 | 3.5ms |
You can also use Fio to confirm that the chosen block storage meets the performance benchmarks necessary for optimal functioning of etcd within your Milvus deployment.
MinIO: Milvus Object Storage Tool
MinIO is a high-performance, Kubernetes-native object storage solution optimized for cloud-native workloads. Milvus utilizes MinIO to store snapshot files of logs, index files for both scalar and vector data, and intermediate query results.
Performance for object storage like MinIO is primarily gauged by I/O throughput rather than IOPS. This metric significantly impacts various operations in Milvus, such as loading collections, building indexes, and inserting data. Many factors influence MinIO's throughput performance, including network bandwidth, Linux kernel performance tuning, and the performance of individual disk drives. Disk performance is particularly crucial.
We can use the dd command to measure single-drive performance. DD is a Unix tool that copies data from one file to another bit-by-bit. It provides various options to control the block size of each read and write.
In the example below, when testing a single NVMe drive with a 16MB block size, the O_DIRECT option for 64 counts generates a write performance exceeding 2GB per second per drive.
$ dd if=/dev/zero of=/mnt/drive/test bs=16M count=64 oflag=direct
64+0 records in
64+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.443096 s, 2.4 GB/s
In the same example, when testing a single NVMe drive with a 16MB block size, the O_DIRECT option for 64 counts generates a read performance exceeding 5GB per second per drive.
$ dd of=/dev/null if=/mnt/drive/test bs=16M count=64 iflag=direct
64+0 records in
64+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.187263 s, 5.7 GB/s
The higher your disk drive's read and write performance, the better MinIO's overall throughput performance. We recommend using SSD or NVMe-type drives as storage disks in a MinIO setup for optimal results. These drives can effectively support the high-throughput requirements of MinIO's operations. Avoid using SAN/NAS appliances for MinIO storage. Such setups often introduce concurrency issues and performance bottlenecks that can degrade the system's efficiency and responsiveness.
Pulsar/Kafka: Milvus Log Broker Tools
As mentioned above, Milvus uses different log broker tools tailored to specific deployment modes. Milvus Cluster setups use Pulsar or Kafka, while Milvus standalone versions typically use RocksDB.
Both Pulsar and Kafka are engineered to support persistent message storage and provide high throughput for message consumers. Their performance critically depends on the type of disk storage used, as they rely on sequential disk I/O operations.
For Pulsar, high-performance disks are essential for BookKeeper's journal files to ensure data integrity and durability, with low-latency SSDs being highly beneficial for this purpose. Both Pulsar Ledgers and Kafka are optimized for disk efficiency, utilizing the file system cache and performing well with HDDs and SSDs. However, for latency-sensitive applications or large-scale deployments, SSDs offer significant performance benefits.
To optimize performance, use multiple disk devices for Pulsar and Kafka. Specifically, for Pulsar, using separate disks for the journal and general storage allows bookies to isolate the latency of write operations from read operations. To ensure optimal latency, do not use the same drives for storing data, application logs, or other OS filesystem activities. These drives can be configured as a single volume using RAID, or each drive can be formatted and mounted as its own directory. Network-attached storage (NAS) should be avoided due to its slower performance, higher and more variable latencies, and potential as a single point of failure.
Summary
Our in-depth exploration of the Milvus storage system offers comprehensive insights into its architecture and components, highlighting their roles in supporting large-scale data management and analysis. We've dissected Milvus's three primary storage components—meta storage, object storage, and log broker—and provided strategies to evaluate and enhance their performance.
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
 Jay Zhu
Jay ZhuJay Zhu is the Senior Software Engineer and tech leader of the DevOps & Infrastructure team at Zilliz. He specializes in DevOps, cloud-native technologies, and Kubernetes projects. Additionally, Jay is actively involved in developing and maintaining various open-source projects, including Milvus, Milvus-helm, and Milvus-operator.
Keep Reading

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.