




Advanced Video Search: Leveraging Twelve Labs and Milvus for Semantic Retrieval
In August 2024, at the Unstructured Data Meetup in San Francisco, James Le, Head of Developer Experience at Twelve Labs, offered an insightful talk on advanced video search for semantic retrieval. If you haven’t heard of Twelve Labs yet, you’re in for a treat. Twelve Labs develops cutting-edge multimodal models that help machines understand videos as intuitively as humans do. They have created state-of-the-art foundation models for generating video embeddings along with APIs that can search, generate, and classify video content with human-like precision.
In the talk, James explains the key concepts of video understanding and the overall workflow of their foundation model and APIs. James also talks about integrating video understanding models with efficient vector databases such as Milvus by Zilliz to create exciting applications for semantic retrieval. If you are intrigued by how AI can revolutionize video content, this meetup was one for the books.
With that, let’s dig into James’ talk on ‘Advanced Video Search - Leveraging Twelve Labs and Milvus for Semantic Retrieval’: Watch the talk on YouTube.
 James Le speaking at the August South Bay Unstructured Data Meetup
James Le speaking at the August South Bay Unstructured Data Meetup
What is Video Understanding?
Videos are a powerful source of information about the real world. Unlike images, which capture only static scenes, videos capture temporal information such as changing actions, behaviors, or events. Like humans, machines can be taught to analyze, interpret, and extract meaningful information from videos using computer vision and deep learning techniques.
Evolution of Video Understanding
The videos were first invented in the late 19th century, and at that time, there was no technology for interpretation. Later, in 1996, the first speech-to-text technology was commercialized, which created transcripts. However, those transcripts were awful to read and were disconnected from the visual information. Furthermore, in 1997, the first CNN-based image recognition model was released - LeNet - 5, which created tags to understand objects in the video frames such as ‘person,’ ‘dog,’ ‘clothing,’ and so on. These tags did not help understand the context of the video, and they would create discrepancies. Later, from 2012 onwards, video understanding was revolutionized with convolutional neural networks (CNNs), which allowed the models to perform advanced tasks such as action recognition.
Past, Present, and Future of Video Understanding
In the past, video understanding was all about solving low-level video perception tasks such as extracting low-level features like color, texture, and motion using handcrafted features or simple computer vision techniques such as Histogram of Gradients (HOG). Some of the earliest video perception tasks involved Video Object Detection, Video Object Tracking, Video Instance Segmentation, and Action Recognition.
The earlier-mentioned tasks were often narrow in scope and involved inefficiencies such as mislabeled objects or missed tags. In the present, video understanding has evolved to handle broader tasks such as Video Classification, Video Retrieval, Video Question Answering, and Video Captioning. Techniques like CNNs, Recurrent Neural Networks (RNNs), and, more recently, Transformers have enabled models to process spatial and temporal patterns efficiently. Action recognition evolved into video classification, where models classify a whole sequence instead of just recognizing a single action. Similarly, video retrieval systems can now index and retrieve relevant videos based on queries. At the same time, question-answering models can respond to video-related questions, and video captioning can generate text descriptions of scenes.
The current models are either focused on a specific task, trained on specific data, or based on a single modality. In the future, the focus will be on multimodal video foundation models that offer general-purpose understanding. These models will integrate information from multiple sources - video, audio, and text to develop a holistic comprehension of video content. The main idea behind these models is that they cater to diverse use cases and industries, address dynamic tasks, and provide a unified understanding of all modalities, enabling complex applications that function in real-time.
Video Foundation Models by Twelve Labs
Video Foundation Models are large, pre-trained models designed to understand videos comprehensively. Much like language models (e.g., GPT) serve as foundations for various text-based applications, video foundation models trained on vast amounts of multimodal data (video, audio, text) are equipped to generate multimodal embeddings that can be further used to handle a wide variety of downstream tasks and create video-centric applications across industries.
In the talk, James Lee very clearly outlines the role of video foundation models in creating real-world applications and how it is beneficial for end users.
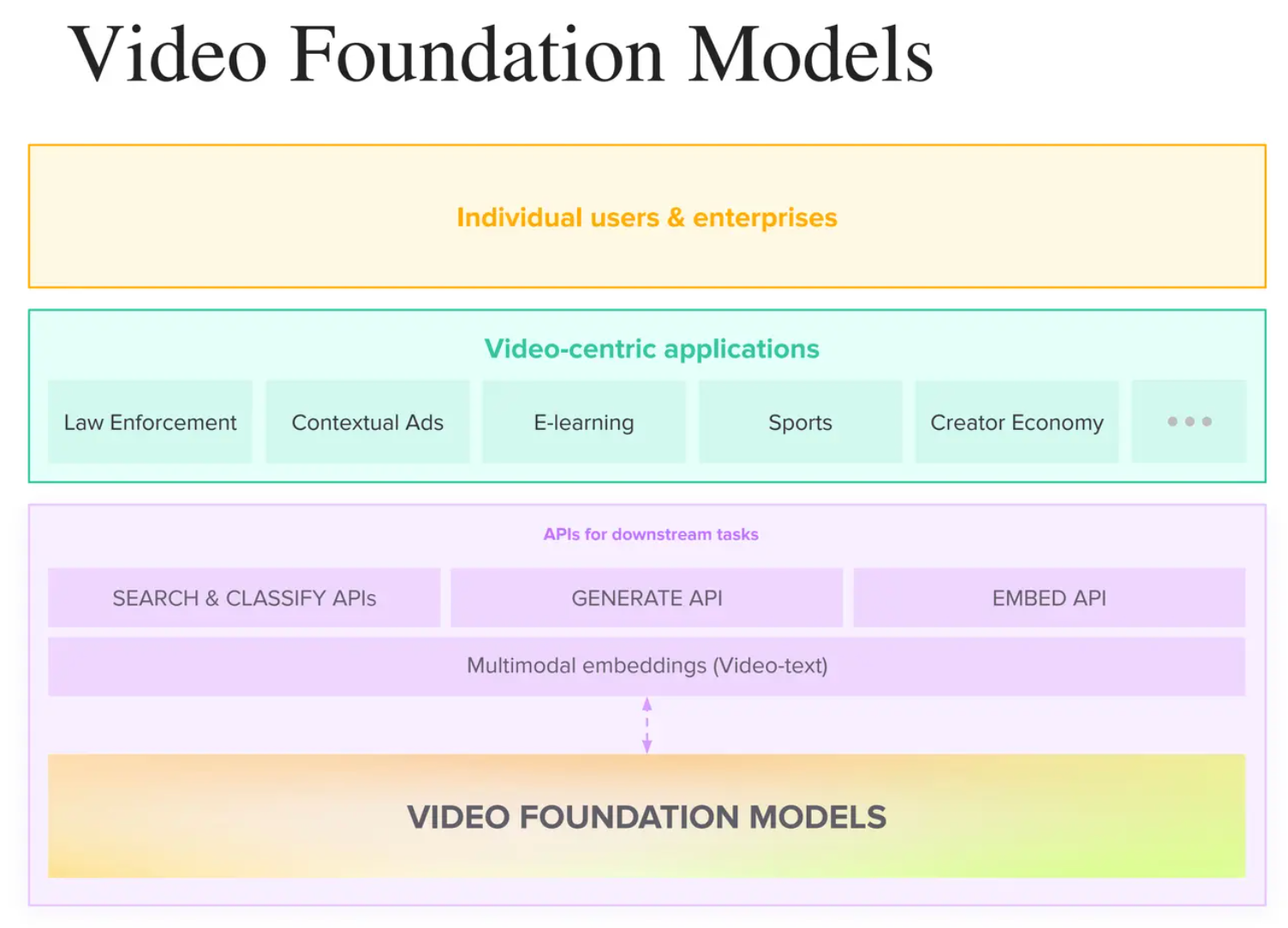
Embedding Generation: First, the foundation model will generate multimodal embeddings for the input data. These embeddings are numerical representations that store all conversational and visual semantic information from a video.
Downstream Tasks: The generated embeddings can be further used to create APIs for downstream tasks such as Search and Classify, Generate, and Embed.
Video-Centric Applications: The embedding-based gateway APIs can be further used to generate video-centric applications across various industries such as Law Enforcement, E-Learning, Sports, and Creator Economy.
End Users: The above steps will create a pipeline of intelligent video understanding which will be beneficial for the demand of individual users and enterprises.
Having understood the overall stack, let’s dive deeper into the technical nuances of video foundation models.
What are Video Embeddings?
Video embeddings are essentially representations of a video in a lower dimensional vector space in the form of a numerical vector. These embeddings capture the visual features and semantics of the video which allows the foundation models to understand the content of the videos. Traditionally, vector embeddings only belonged to a single modality such as image, text, or audio which would be processed independently. However, with the rise of multimedia content and the popularity of transformer architecture, there has been a shift towards developing embeddings that can capture visual, textual, and audible information in a shared latent space.
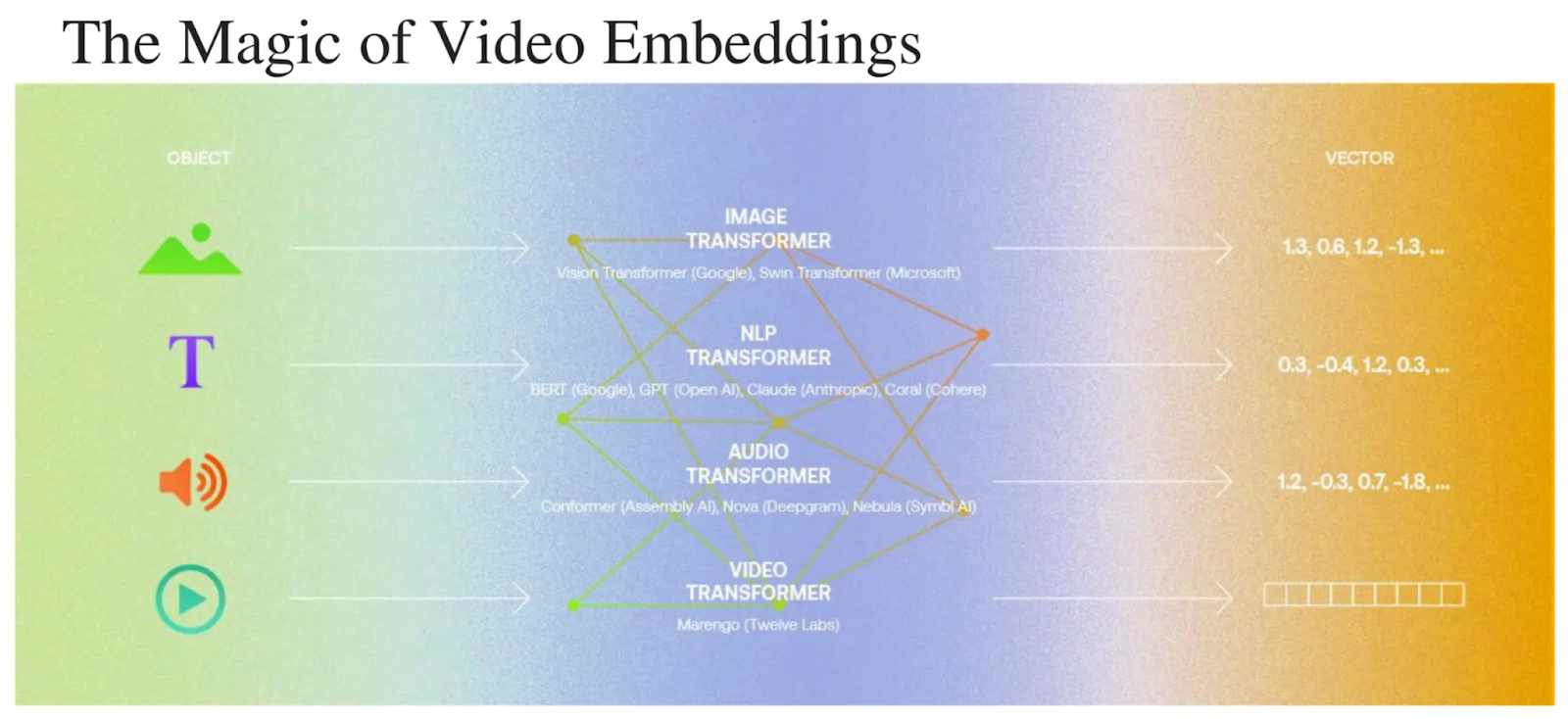 The magic of video embeddings
The magic of video embeddings
State-of-the-Art Video Foundation Model - Marengo 2.6
James Lee introduces the latest state-of-the-art video foundation model developed at Twelve Labs called Marengo 2.6. This model is capable of performing ‘any-to-any’ search tasks, meaning it can query video data using various input formats such as Text-To-Video, Text-To-Image, Text-To-Audio, Audio-To-Video, Image-To-Video, and more. This model is transformative in the video understanding domain as it significantly enhances video search efficiency and allows robust interactions across different modalities.

As mentioned in the blog ‘Introducing Marengo 2.6’, the basic concept of the architecture is about ‘Gated Modality Experts’ which allows the processing of multimodal inputs through specialized encoders before combining them into a comprehensive multimodal representation. There are three main modules in the architecture
Visual Expert - It processes visual information to capture appearance, motion, and temporal changes within the video.
Audio Expert - It processes auditory information to capture both verbal and non-verbal audio signals related to the video.
Gated Fusion Module - It assesses the contribution of each expert for videos and merges them into a unified multimodal representation for any-to-any retrieval.
Additionally, Marengo 2.6 excels in fine-tuning, allowing users to customize the model to suit specific content needs or domains. The model’s infrastructure supports handling vast video datasets, making it adaptable for organizations with large video libraries. This model can be further used for downstream tasks such as improved search, classification, and content management with the help of seamless API integrations.
Downstream Tasks with Twelve Labs APIs
Video Search API
Imagine being able to find the exact scenes in a video of a grand slam tennis tournament when Roger Federer gains a point while smashing the opponent, simply by describing these visuals in natural language. Sounds too good to be true right? This is called a video search.
As shown in the figure below, video search works by first creating embeddings of the videos by a video foundation model. Next, the search API takes input from natural language query which is also converted into embeddings. Finally, the query embeddings are searched with respect to video embeddings to deliver the video scenes with timings.
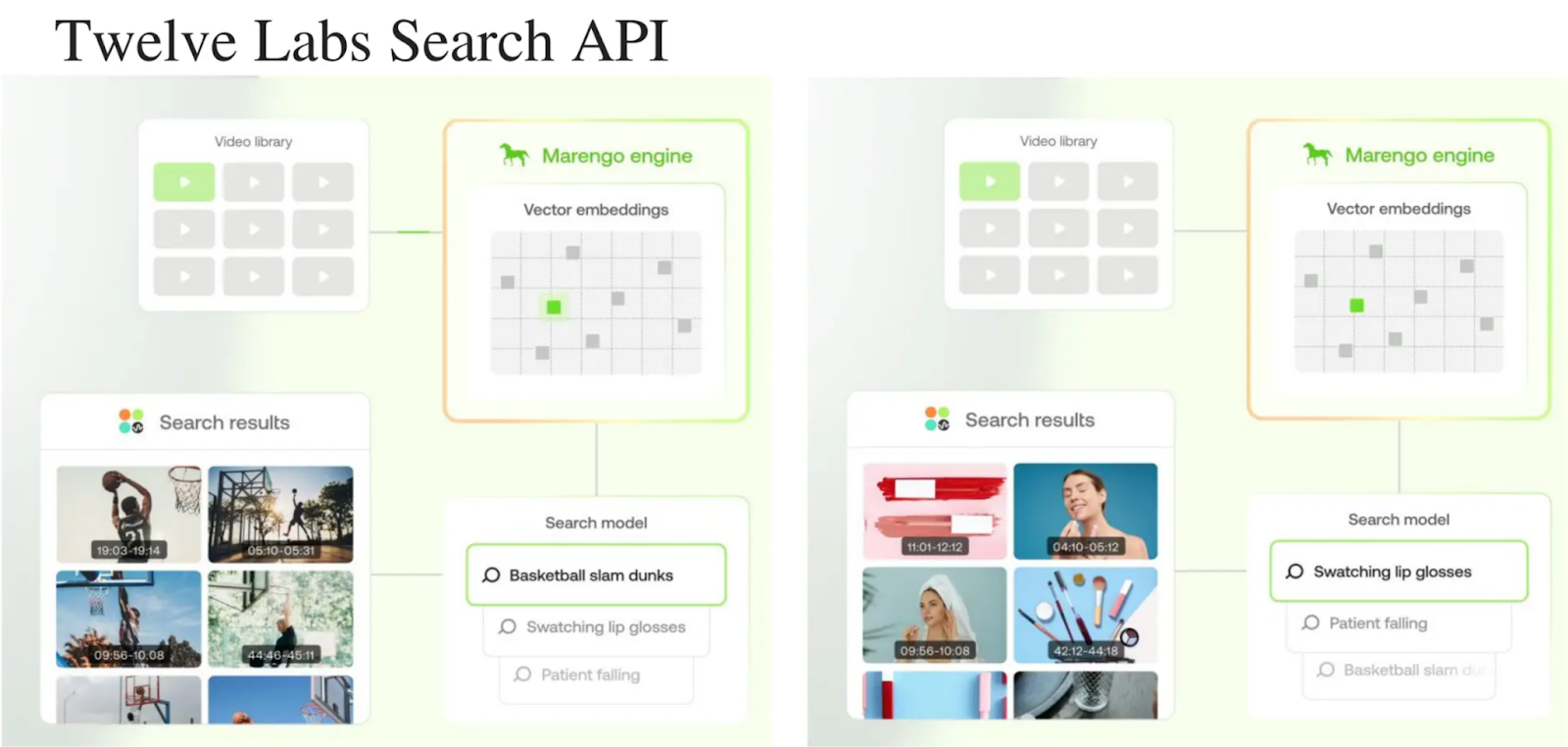 Twelve Labs Search API
Twelve Labs Search API
Traditional video search, on the other hand, had severe limitations in its approach and execution as it primarily relied on keyword matching to index and retrieve videos. However, with multimodal AI video understanding, it is possible to capture the complex relationships between all modalities simultaneously and provide a more human-like interpretation of the video.
Video Classify API
AI-powered video understanding allows for the automatic categorization of video into predefined classes. Using a zero-shot approach, it’s also possible to get the classes on the fly without predefining them. With the Classify API of Twelve Labs, you can organize videos into sports, news, entertainment, or documentaries, by analyzing semantic features, objects, actions, and other elements of the content.
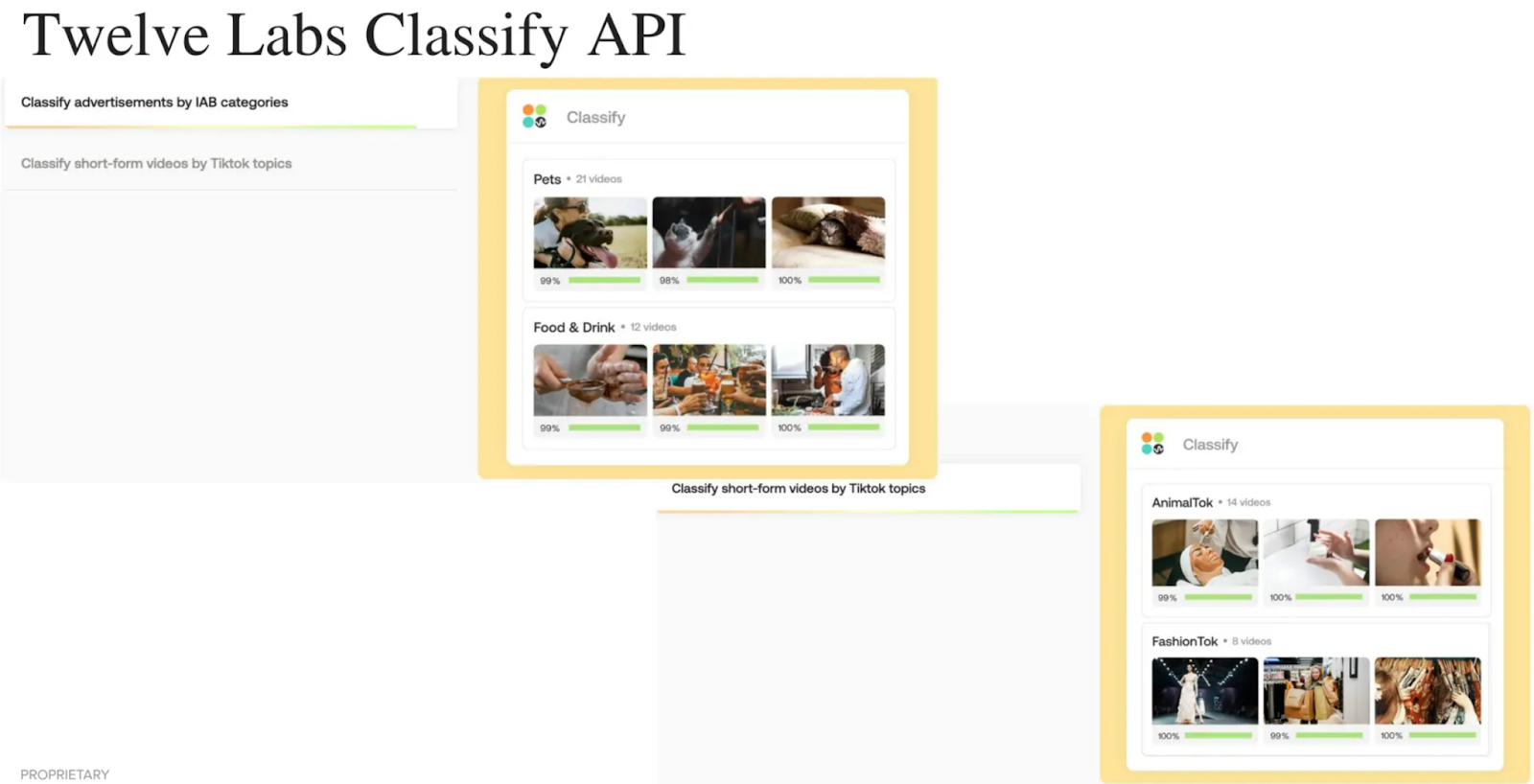 Twelve Labs Classify API
Twelve Labs Classify API
Video Embed API
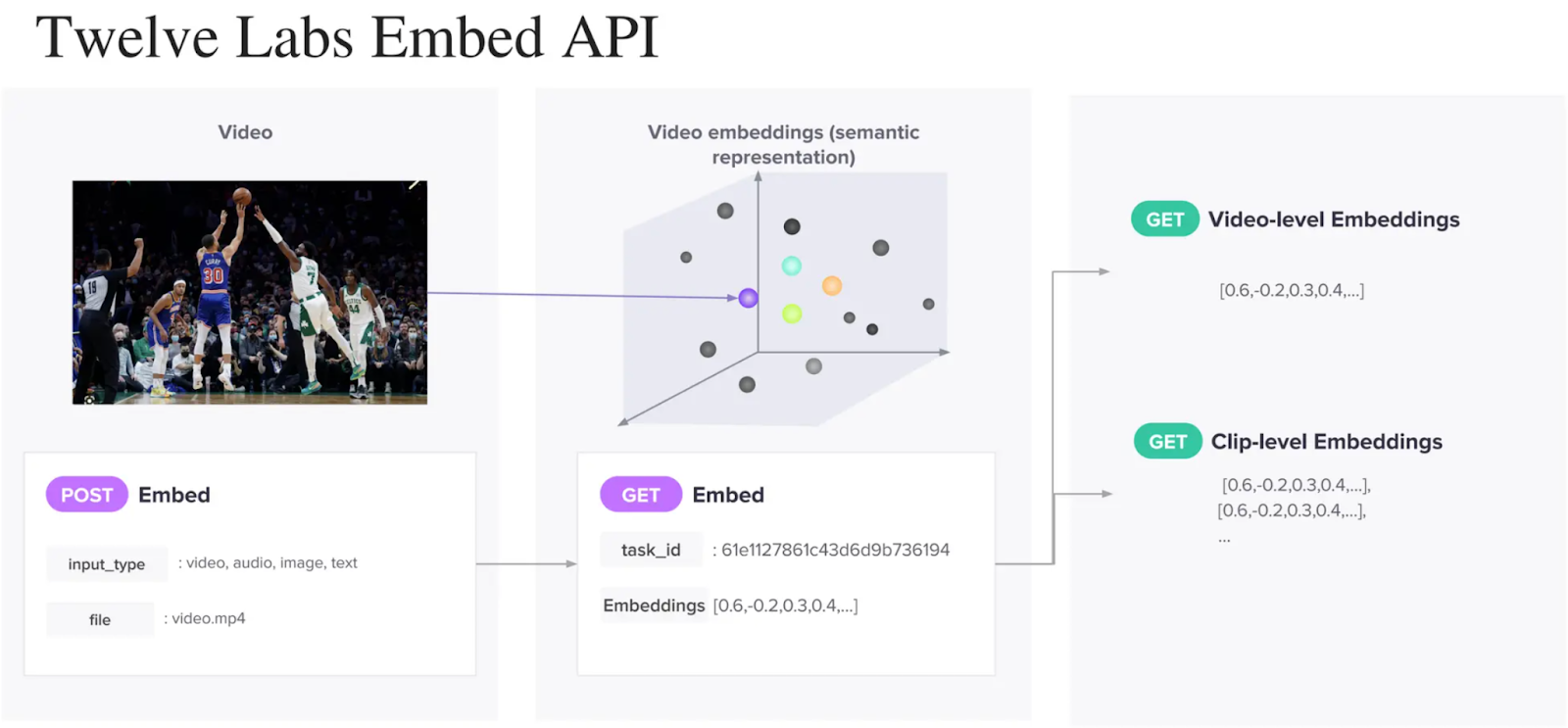 Twelve Labs Embed API
Twelve Labs Embed API
Twelve Labs have also released an Embed API in private beta for developers. The Search and Classify APIs were end-to-end but this API is for someone who wants to experiment at the embedding layer by either adding their metadata or doing some additional math.
This API creates multimodal embeddings on video-level and clip-level which can be used for various custom downstream tasks including but not limited to anomaly detection, diversity sorting, sentiment analysis, recommendations and to construct Retrieval Augmented Generation (RAG) systems.
Twelve Labs Meets Milvus
 Twelve Labs Meets Milvus
Twelve Labs Meets Milvus
In August 2024, Twelve Labs and Milvus (vector database by Zilliz) joined hands to create powerful video search applications. Milvus is a scalable and efficient vector database for managing, querying, and retrieving vector embeddings. It is specifically designed to create high performance AI applications. By harnessing the power of Twelve Labs’ advanced multimodal embeddings and integrating it with Milvus, developers can unlock new possibilities in video content analysis by creating applications such as search engines, recommendation systems, and content-based video retrieval.
Semantic Retrieval using Twelve Labs and Milvus
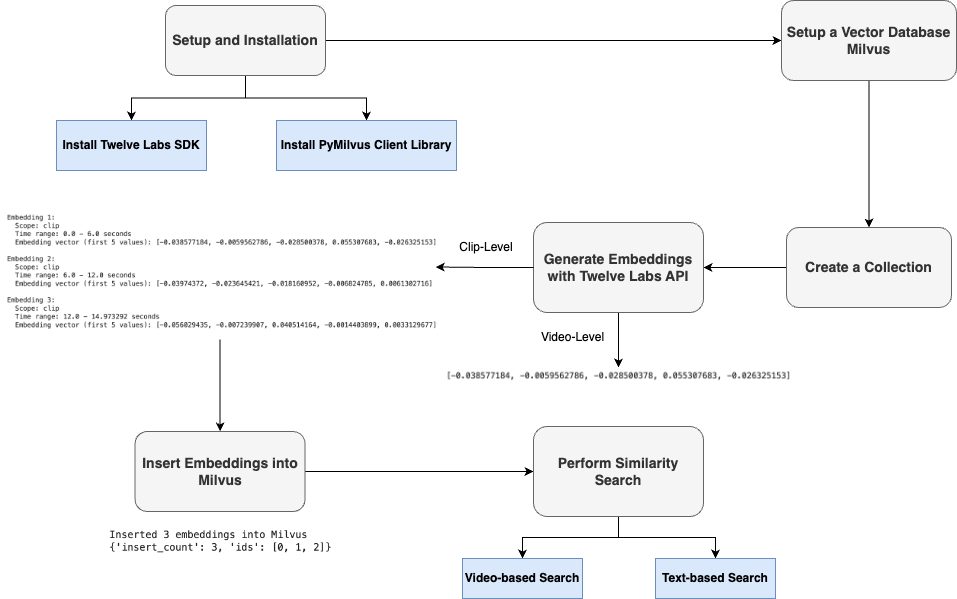
In order to perform semantic retrieval, the first step is to choose and setup the necessary SDKs and libraries of the vector database and API to generate embeddings. Next, with the help of Embed API by Twelve Labs, multimodal embeddings of the videos are generated either based on clip-level or video-level. For clip-level, one can define the lengths of clips which the video should be broken down to. For example, if the overall video is of 18 seconds and clip length is chosen to be 6 seconds then we get 3 clip-level embeddings. The embeddings are then inserted into the vector database and finally similarity search can be performed. When a user submits a query (video or text), it is also converted into a vector using the same embedding model. The system then compares this query vector with the vectors stored in the database to retrieve the most semantically similar results.
Developer Resources
Keep Reading

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.