




Понимание разделения баз данных

Понимание разделения баз данных
Современные веб-сайты и приложения в значительной степени полагаются на технологии баз данных для обработки запросов на чтение и запись от множества пользователей. Однако по мере роста популярности приложения количество пользователей увеличивается, и из-за частых сбоев базы данных становится сложно обеспечить оптимальный уровень обслуживания клиентов.
Как же разработчики могут увеличить масштаб своих баз данных, чтобы удовлетворить растущий спрос? Хотя ответ может зависеть от конкретного случая, одним из простых и экономически эффективных методов является шардинг баз данных. Он прост в реализации и обеспечивает значительное повышение производительности.
Несмотря на свою простоту, шардинг баз данных может быть запутанной концепцией. В этой статье мы объясним его значение, методы реализации, альтернативы, преимущества и проблемы, а также примеры использования, чтобы помочь вам понять, когда и как применять наиболее подходящий метод шардинга.
Что такое шардинг баз данных?
Шардинг баз данных разбивает обширную базу данных на более мелкие фрагменты, называемые шардами, и распределяет их между несколькими машинами. Каждая машина использует одну и ту же технологию, параллельно обрабатывая большие объемы данных.
Это один из многих методов, позволяющих ускорить обработку данных и обеспечить высокую доступность. Если одна машина или сервер базы данных выходят из строя из-за перегрузки запросов, другие серверы могут продолжать обрабатывать запросы на чтение и запись, обеспечивая бесперебойную работу пользователей.
Однако шардинг работает только до тех пор, пока данные доступны. Это позволяет разработчикам органично распределить рабочую нагрузку и уменьшить задержки.
Репликация и разбиение на разделы - другие методы предотвращения простоев. Эти методы больше подходят для небольших баз данных. Репликация предполагает копирование всей базы данных на несколько серверов, а разбиение на разделы разбивает базу данных и хранит ее на одной машине. В последующих разделах эти подходы будут описаны более подробно.
Как работает разделение баз данных?
Шардинг - это форма горизонтального масштабирования, при которой разработчики устанавливают дополнительные узлы или серверы для хранения нескольких разделов данных. Каждый раздел становится независимой таблицей, имеющей ту же схему, что и исходная база данных. Однако информация в каждом разделе уникальна, и разработчики хранят отдельные фрагменты на нескольких компьютерах, называемых узлами.
Например, в следующей таблице показана единая база данных, представляющая информацию о клиентах и приобретенных ими товарах.
| Идентификатор клиента | Имя | Приобретенный товар |
| 10001 | A | Рубашка |
| 10002 | B | Кепка |
| 10003 | C | Рубашка |
| 10004 | D | Обувь |
Разработчик может использовать разделение баз данных на более мелкие разделы, называемые логическими, на отдельных машинах или физических разделах.
Сервер 1
| Идентификатор клиента | Имя | Приобретенный товар |
| 10001 | A | Рубашка |
| 10002 | B | Кепка |
Сервер 2
| Идентификатор клиента | Имя | Приобретенный товар |
| 10003 | C | Рубашка |
| 10004 | D | Обувь |
Шардинг работает по архитектуре "разделяй-не разделяй", когда один узел в компьютерном кластере обрабатывает запросы пользователей независимо друг от друга. Когда пользователь пытается получить доступ к базе данных, только шард, содержащий информацию о пользователе, становится активным и обрабатывает входящий запрос.
Разработчики разделяют данные на логические шарды с помощью ключа шарда. Они могут выбрать ключ на основе столбца, который организует данные в группы, или создать новый. В следующих разделах мы расскажем, как работает ключ шарда, и поможем разработать группы данных для эффективного шардинга.
Методы шардинга
Разработчики могут применять различные методы шардинга в зависимости от сценария использования и характера данных, которые они хотят обрабатывать. К популярным методам относятся шардинг на основе диапазонов, хешированный шардинг, шардинг каталогов и гео-шардинг.
Шардинг на основе диапазона
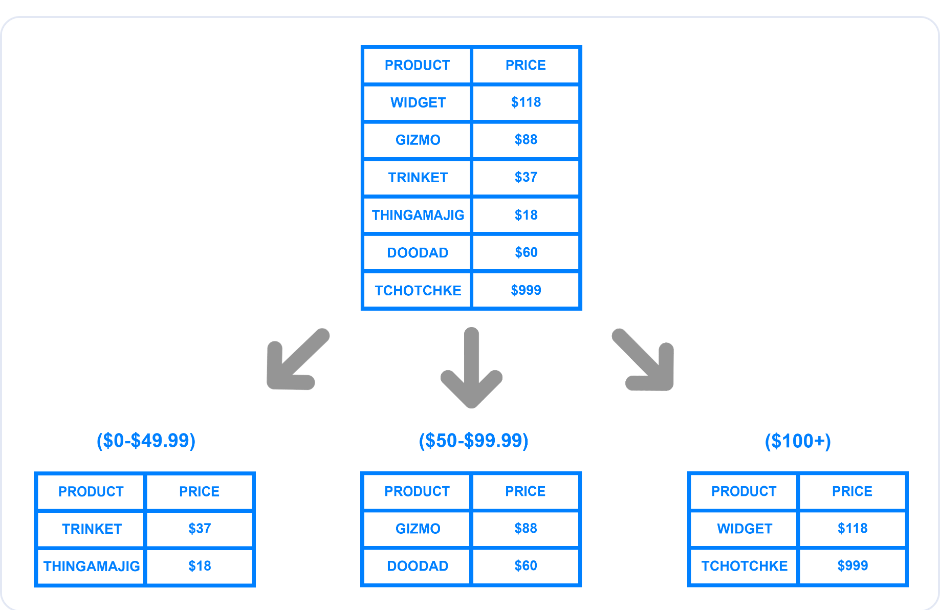
Разделение на основе диапазона или динамическое разделение разделяет базу данных на части на основе определенного диапазона значений. На диаграмме ниже показано, как разработчик может разделить таблицу на сегменты с помощью диапазона цен.
 Range-based sharding based on price.png
Range-based sharding based on price.png
Разделение на основе диапазона цен
В примере показаны три логических шарда, созданных с использованием диапазонов цен. Разработчик может назначить каждому чанку уникальный ключ шарда и хранить их на отдельных физических шардах или машинах. При записи записи в базу данных система определит соответствующий шард, к которому относятся данные, на основе ценового диапазона и обновит их соответствующим образом.
Несмотря на простоту реализации динамического разделения, оно может перегрузить конкретный шард, если он содержит больше записей, чем другие. В приведенном выше примере, если больше клиентов приобретают товары по цене свыше 100 долларов, объем данных в третьем шарде будет больше, чем в остальных.
Неравномерное распределение может нарушить цель шардинга, поскольку только один шард будет содержать большую часть данных, что приведет к замедлению работы системы. Кроме того, этот метод требует наличия таблицы поиска, в которой хранится уникальный ключ шарда и соответствующие диапазоны.
Hashed Sharding
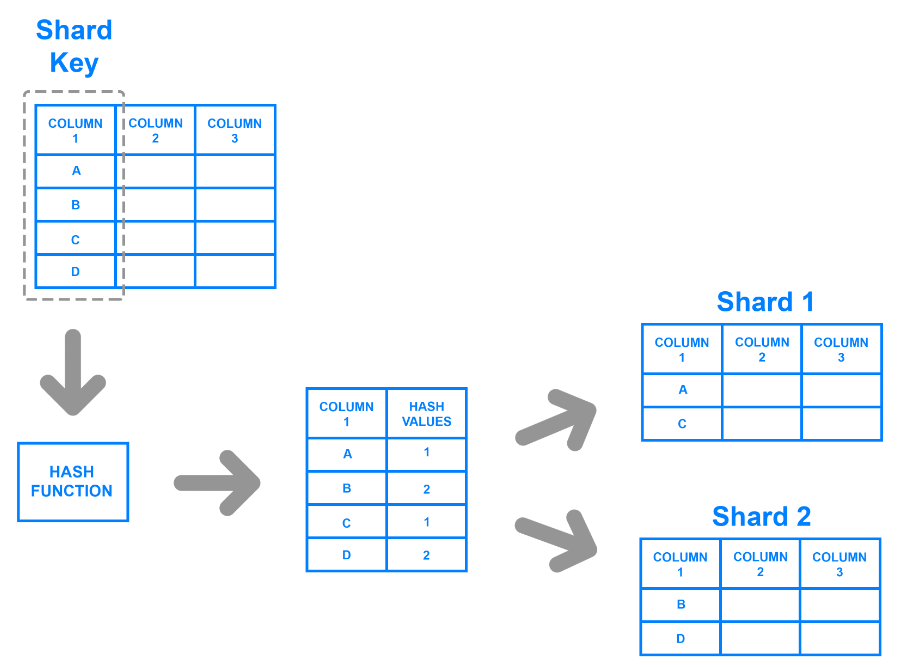
Хешированный шардинг назначает хеш-ключ каждой записи на основе определенного столбца. Разработчики генерируют хэш-ключи с помощью хэш-функции, которая принимает значения в столбце в качестве входных данных. Они могут разделить данные, определив записи, которые относятся к соответствующему ключу или хэш-значению.
Например, разработчики могут выбрать столбец и использовать его значения для генерации хэш-значений. Эти значения могут служить ключом шарда для каждого чанка, и разработчики могут хранить их на разных машинах. Диаграмма ниже иллюстрирует этот процесс.
 Hashed sharding.png
Hashed sharding.png
Хеширование решает проблему неравномерного распределения, поскольку функции или алгоритму хеширования не требуется определяемый пользователем ключ для разделения данных на шарды. Однако становится сложно запрашивать данные из отдельных шардов, поскольку ключи не группируют данные по каким-либо значимым критериям. Алгоритм случайным образом генерирует хэш-значения и делит данные на части.
Например, при шардинге на основе диапазонов ключи отражают диапазоны определенных значений в таблице и более осмысленно соотносятся со структурой данных. Запрос шардов на основе диапазонов значений выполняется быстрее, чем запрос данных на основе хэш-ключей.
Кроме того, добавление новых шардов или модернизация систем требует от разработчика повторного запуска алгоритма хеширования для всех записей. Этот процесс необходим для балансировки объема данных на разных машинах, но может потребовать значительного времени простоя и вычислительных ресурсов.
Шардинг каталогов
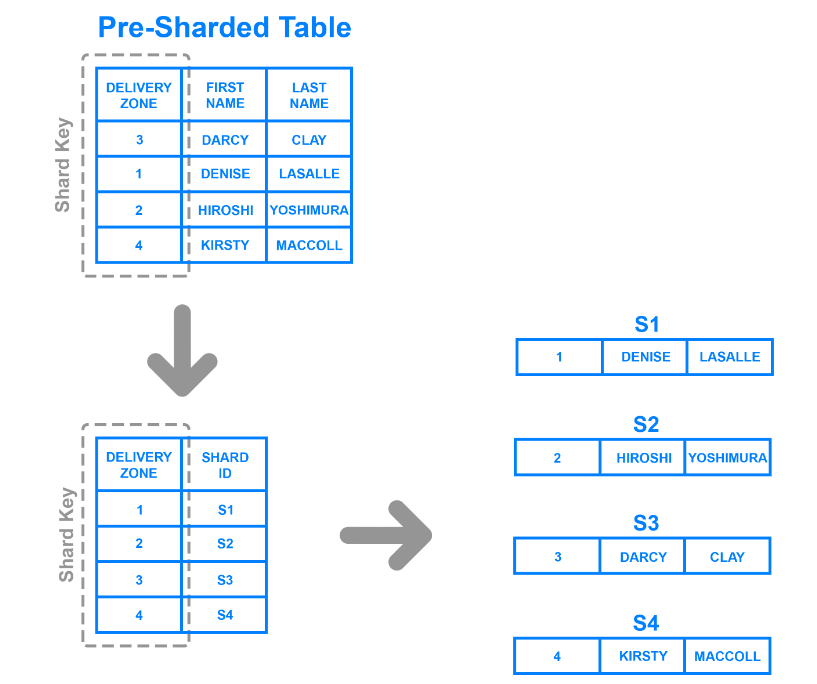
Разделение каталогов является более гибким, чем рассмотренные выше методы. Он разделяет данные на основе значений определенного столбца и использует таблицу поиска, чтобы определить, к какому хранилищу относится запись.
 Directory sharding based on delivery zone.png
Directory sharding based on delivery zone.png
Directory sharding based on delivery zone
Например, на рисунке показано, как использовать столбец Delivery Zone в качестве ключа шарда и разделить данные в соответствии с зонами, к которым относится клиент. Этот метод создал четыре разных шарда, поскольку таблица имеет четыре зоны.
В отличие от шардинга на основе диапазонов, разделы данных более универсальны, так как они не должны придерживаться строгих диапазонов значений. Кроме того, это позволяет разработчикам быстрее обновлять разделы, поскольку им не нужно алгоритмически генерировать ключи для всех значений в конкретном столбце.
Однако эта техника требует наличия таблицы поиска для обработки входящих запросов, что замедляет скорость обработки. Кроме того, выбор столбца, который приводит к большому количеству шардов, может значительно увеличить размер таблицы поиска и задержку.
Выбор ключа шарда
Эффективное разделение баз данных требует от разработчиков определения подходящего ключа разделения для обеспечения равномерного распределения данных по шардам. При неравномерном распределении определенные шарды могут стать "горячими точками", содержащими больше данных, чем другие.
Ключ шардинга также должен упрощать процесс запроса, чтобы увеличить скорость обработки и предотвратить простои. Кроме того, определение подходящего ключа шарда зависит от выбора правильного столбца.
В приведенном ниже списке указаны три важных фактора, которые разработчики могут учитывать при выборе наиболее подходящего столбца для генерации ключа шарда.
- Кардинальность: Кардинальность определяет максимальное количество шардов, которые разработчик может создать на основе разных значений в столбце. Например, при выборе столбца, содержащего три разных значения, будет создано три шарда. Шардинг на основе каталогов полезен, когда кардинальность столбца невелика.
- Частота: Частота - это процент данных, принадлежащих определенному ключу шарда. Например, при разделении на основе диапазонов цен определенные диапазоны цен могут содержать около 80 % всех записей, что приведет к образованию "горячей точки" данных.
- Динамические шарды: Объем данных в динамических шардах меняется по мере изменения спроса на приложение. Например, по мере того как приложение становится популярным, демографические характеристики пользователей могут меняться, и число подписчиков из возрастной группы 20-25 лет может увеличиваться. Разделение на основе диапазона по возрасту может привести к образованию "горячей точки" данных, поскольку в хранилище, соответствующем возрастному диапазону 20-25 лет, будет находиться больше данных.
Чтобы обеспечить эффективное разделение баз данных, разработчики должны учитывать кардинальность и частоту ключей разделения и определять, приведет ли это к динамическому разделению.
Сравнение с альтернативами
Разделение баз данных - это один из методов масштабирования баз данных. Другие методы включают вертикальное масштабирование, репликацию и разделение. Понимание того, чем они отличаются от шардинга, поможет разработчикам использовать правильный метод масштабирования для конкретных сценариев.
Вертикальное масштабирование
Вертикальное масштабирование подразумевает увеличение мощности существующего сервера. Разработчики могут установить дополнительные процессоры, жесткие диски и другое программное обеспечение для повышения производительности.
Этот метод помогает в тех случаях, когда одной машины достаточно для обработки запросов пользователей, и для повышения производительности необходимы лишь постепенные улучшения.
Хотя этот метод менее затратный, чем шардинг, он увеличивает мощность сервера лишь в ограниченной степени, поскольку для обработки пользовательских запросов доступна только одна машина.
Репликация
При репликации разработчики создают копии одной и той же базы данных и хранят их на нескольких компьютерах. Как и шардинг, этот метод обеспечивает высокую доступность, поскольку при отказе одного компьютера другие остаются активными.
Шардинг и репликация похожи тем, что распределяют обработку данных между несколькими машинами. Однако при шардинге данные разбиваются на различные фрагменты, в то время как при репликации данные копируются целиком, без разбивки на части.
Шардинг больше подходит для больших баз данных, так как для репликации требуются серверы с большим объемом памяти. Поддерживать и обновлять каждую реплику на разных машинах дорого и долго.
Разбиение на разделы
Разбиение базы данных на несколько групп и хранение их на одной машине. Этот метод подходит, когда необходимо повысить производительность запросов, а размер базы данных не настолько велик, чтобы хранить разделы на разных машинах.
Он может помочь оптимизировать архивирование данных, позволяя разработчикам разбивать данные по дате и времени. Они могут перемещать определенные записи с временными метками старше определенного порога в архивную таблицу, а для хранения последних записей использовать другую таблицу.
Преимущества разделения баз данных
Разделение баз данных - ценная стратегия для эффективного управления данными. Предприятия, работающие с обширными данными для своих веб-сайтов, приложений и другого программного обеспечения, основанного на данных, должны внедрить шардинг, чтобы максимально использовать преимущества технологии баз данных.
В приведенном ниже списке более подробно описаны некоторые преимущества шардинга, которые он дает организациям.
Масштабируемость: Разделяя данные между несколькими машинами, шардинг позволяет предприятиям более эффективно масштабировать свои системы баз данных для поддержки растущих рабочих нагрузок.
Минимальное время простоя: Шардинг обеспечивает высокую доступность, работая по архитектуре "общий доступ - ничего". Эта стратегия позволяет улучшить работу пользователей, поскольку отказ одной машины не повлияет на производительность других.
Простота обновления: Внедрение обновлений производительности более эффективно, поскольку разработчики могут отдельно обновлять отдельные машины, не останавливая работу всей системы.
Проблемы разделения баз данных
Несмотря на то что шардинг дает значительные преимущества, разработчики могут столкнуться с рядом проблем, которые повышают сложность реализации. В приведенном ниже списке указаны эти проблемы и возможные стратегии их решения.
Неравномерное распределение: Неопределенность в отношении объема и разнообразия данных может привести к появлению "горячих точек". Несмотря на наличие эффективного ключа шарда, характер данных может измениться, что потребует от разработчиков выбора или создания нового ключа. Разработчики должны тщательно оценить пригодность шардинга баз данных в конкретных сценариях. Возможно, в разных ситуациях репликация или вертикальное масштабирование окажутся более практичными, чем шардинг.
Сложность управления: Управление несколькими машинами является сложной задачей, поскольку разработчики должны постоянно следить за состоянием каждого узла, чтобы быстро выявлять и устранять проблемы. Надежные системы мониторинга с механизмами оповещения в реальном времени могут помочь смягчить эти проблемы, уведомляя соответствующие команды в случае сбоев в работе сервера.
Затраты на обслуживание: Обслуживание нескольких локальных серверов обходится дорого и требует привлечения дополнительного персонала с соответствующим опытом для решения проблем во время обслуживания. Организации могут перейти на облачную инфраструктуру для размещения различных шардов и поручить поставщику облака проводить регулярное обслуживание за кулисами.
Примеры использования шардинга баз данных
Хотя в вышеприведенных разделах вкратце описаны случаи использования шардинга, приведенный ниже список классифицирует и объясняет эти сценарии более подробно.
Крупномасштабные веб-приложения:** Сайты электронной коммерции с обширной пользовательской базой, платформы социальных сетей, приложения по доставке автомобилей и игровые сайты - идеальные кандидаты для шардинга баз данных. Шардинг поможет администраторам таких сайтов более эффективно балансировать нагрузку и предотвращать простои в часы пик.
Аналитика больших данных: Для пользователей, анализирующих большие данные, шардинг поможет повысить скорость обработки за счет распределения нагрузки на несколько серверов.
Сети доставки контента (CDN): CDN - это группа серверов, распределенных по разным точкам для обработки запросов от пользователей из близлежащих географических точек. Разработчики могут разделять базы данных в соответствии с местоположением пользователей и распределять данные по этим серверам для ускорения отклика.
Часто задаваемые вопросы о шардинге баз данных
- **В чем разница между шардингом и разделением?
В то время как шардинг и партиционирование разбивают данные на более мелкие фрагменты, шардинг распределяет каждый фрагмент по разным машинам или узлам. В отличие от этого, разделение хранит каждый фрагмент на одной машине.
- **В чем разница между шардингом и репликацией?
Репликация копирует всю базу данных и хранит ее на разных машинах. По сравнению с разделением, при котором база данных разбивается на строки и каждый фрагмент хранится на нескольких серверах, репликация обеспечивает более высокую доступность, но требует больше вычислительных ресурсов и объема памяти.
- **Как выбрать правильный ключ шардинга?
Выбор подходящего ключа шарда требует от разработчиков определения подходящего столбца для разделения данных. Осколочный ключ должен иметь низкую кардинальность и равную частоту.
Под кардинальностью понимается максимальное количество осколков, возможных в соответствии со значениями столбцов. Например, если выбрать столбец, содержащий четыре разных значения, получится четыре осколка. Частота - это доля данных, которую содержит каждый осколок.
Также следует выбирать или создавать шарды, которые остаются статичными на протяжении всего жизненного цикла приложения. Осколки, объем данных в которых может меняться, могут привести к образованию "горячих точек", когда некоторые из них будут занимать больше места, чем другие.
- **Каковы основные проблемы разделения баз данных?
Разделение баз данных увеличивает нагрузку на запросы, поскольку разработчикам приходится писать запросы для доступа к данным с нескольких машин для выполнения анализа.
Это также увеличивает затраты на инфраструктуру, поскольку организации должны поддерживать несколько серверов и следить за их состоянием, чтобы предотвратить сбои.
Кроме того, обновление и ребалансировка шардов усложняется при увеличении объема и разнообразия данных. Техника шардинга, подходящая в одной ситуации, может оказаться непрактичной в других.
- **Подходит ли шардинг баз данных для небольших приложений?
Хотя разделение баз данных - ценная техника для повышения скорости обработки и пропускной способности, она не подходит для небольших приложений. Ее целесообразно применять только тогда, когда объем данных достигает такого уровня, что поддерживать одну базу данных на одном сервере становится нецелесообразно.
Связанные ресурсы
Хотя разработчики обычно применяют шардинг к структурированным наборам данных, следующие ресурсы помогут вам понять концепцию в контексте неструктурированных данных и векторных баз данных:
- Что такое шардинг баз данных?
- Как работает разделение баз данных?
- Методы шардинга
- Выбор ключа шарда
- Сравнение с альтернативами
- Преимущества разделения баз данных
- Проблемы разделения баз данных
- Примеры использования шардинга баз данных
- Часто задаваемые вопросы о шардинге баз данных
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно