




**Что такое конволюционная нейронная сеть? Руководство для инженера**

Что такое конволюционная нейронная сеть? Руководство для инженера
Конволюционная нейронная сеть [https://zilliz.com/glossary/convolutional-neural-network] (CNN) - это модель глубокого обучения, предназначенная для работы с визуальными данными, такими как изображения, видео, а иногда и аудиофайлы.
CNN изменили такие области, как компьютерное зрение, анализ и обработка изображений, обнаружение объектов и даже обработка естественного языка (NLP).
Традиционные нейронные сети, такие как MLP (Multi-Layer Perceptron) или Fully Connected Networks, рассматривают данные изображений как плоские векторы, что может быть ограничено при работе с пространственной информацией, присутствующей в визуальных данных. Это может привести к низкой точности из-за неверных предположений (индуктивная предвзятость).
CNN решают эти проблемы, сохраняя структуру изображения, такую как локальная связность и содержание пикселей в данных изображения, что делает их эффективными в распознавании образов.
В этой заметке рассказывается о преимуществах CNN, объясняется их архитектура и приводится простой пример построения модели CNN.
Основные причины использования CNN
CNN отлично справляются с извлечением значимых признаков из необработанных визуальных данных, превосходя традиционные нейронные сети. Причины использования CNN включают:
Разделение параметров - CNN использует один и тот же набор параметров для разных областей входных данных, что помогает эффективно выявлять скрытые закономерности в высокоразмерных данных.
Уменьшение количества параметров-СНН используют технику объединения и свертки, что значительно сокращает количество параметров по сравнению с полносвязными сетями.
Иерархическое обучение признаков-СНН имитирует иерархическую структуру зрительной системы человека.
Современная производительность-СНН неизменно превосходят традиционные нейронные сети в таких задачах, как обнаружение объектов, обработка изображений, распознавание речи и сегментация изображений. Обратите внимание, что в последнее время в компьютерном зрении появились также конволюционные и неконволюционные трансформаторы.
Преимущества и недостатки конволюционных нейронных сетей
Хотя CNN изменили игру в компьютерном зрении, мы должны знать как плюсы, так и минусы. Давайте рассмотрим преимущества и недостатки CNN:
Преимущества конволюционной нейронной сети:
- Обнаружение образов и признаков: CNN отлично справляются с обнаружением паттернов и особенностей в изображениях, видео и аудиосигналах. Их иерархическая структура позволяет им изучать сложные характеристики на основе исходных данных.
- Инвариантность к преобразованиям: CNN инвариантны к переводу, повороту и масштабированию. Это означает, что они могут распознавать объекты, даже если они находятся в разных положениях, ориентации или размерах на изображении.
- Автоматическое извлечение признаков: CNN позволяют проводить обучение по принципу "от конца к концу", не требуя ручного извлечения признаков. Сеть учится находить нужные признаки непосредственно из исходных данных.
- Масштабируемость и точность: CNN могут обрабатывать большие объемы данных и точно решать сложные задачи. С увеличением количества данных их производительность обычно улучшается.
Недостатки конволюционных нейронных сетей:
Вычислительные затраты: Обучение CNN требует больших вычислительных затрат и большого объема памяти. Это может быть проблематично реализовать без специализированного оборудования, такого как графические процессоры.
Переоценка: При отсутствии достаточного количества данных или надлежащих [методов регуляризации] (https://zilliz.com/learn/understanding-regularization-in-nueral-networks) CNN могут перестраиваться. Это означает, что они будут хорошо работать на обучающих данных, но не смогут обобщить их на новые неизвестные данные.
Требования к данным: Для обучения CNN требуется большое количество помеченных данных. В тех областях, где помеченных данных мало или их дорого получить, это может стать серьезным ограничением.
Интерпретируемость: Сложно интерпретировать то, чему научилась CNN. Природа "черного ящика" моделей глубокого обучения затрудняет понимание причин, лежащих в основе их предсказаний, что может стать проблемой в чувствительных приложениях.
Понимание этих преимуществ и недостатков очень важно при принятии решения об использовании CNN для решения конкретной задачи, а также при разработке и реализации решений на основе CNN.
Распространенные методы регуляризации в CNN
Как мы уже упоминали в разделе "Недостатки", CNN могут быть склонны к чрезмерной подгонке, особенно при работе с ограниченными данными. Методы регуляризации используются для того, чтобы предотвратить перебор CNN с обучающими данными, чтобы модель лучше обобщала данные. Вот некоторые распространенные методы регуляризации, используемые в CNN:
Выпадение: Эта техника случайным образом "отбрасывает" (т. е. устанавливает на ноль) некоторые выходные характеристики слоя во время обучения. Выпадение заставляет сеть обучаться более надежным характеристикам, которые не зависят ни от одного нейрона. Таким образом, сеть становится менее чувствительной к конкретным весам нейронов, что, в свою очередь, приводит к лучшему обобщению. Во время тестирования используются все нейроны, но их выходы уменьшаются, чтобы компенсировать пропущенные во время обучения нейроны.
Регуляризация L1: Также известная как регуляризация Лассо, регуляризация L1 добавляет штрафной член к функции потерь, который пропорционален абсолютному значению весов. Эта техника поощряет разреженность модели, обращая некоторые веса в ноль. Регуляризация L1 полезна, когда вы хотите создать более простую модель, удалив менее важные признаки.
Регуляризация L2: Регуляризация L2, также известная как регуляризация Хребта, добавляет к функции потерь штрафной член, пропорциональный квадрату весов. Эта техника предотвращает появление больших весов и распределяет значения весов более равномерно. Регуляризация L2 не приводит к созданию разреженных моделей, как L1, но может помочь уменьшить влияние менее значимых признаков.
И L1, и L2 могут уменьшить количество весов и сделать сеть более эффективной. Выбор между L1 и L2 (или их комбинацией, известной как регуляризация Elastic Net) зависит от задачи и набора данных.
Эти методы регуляризации при правильном использовании решают одну из самых больших проблем в глубоком и машинном обучении в настоящее время.
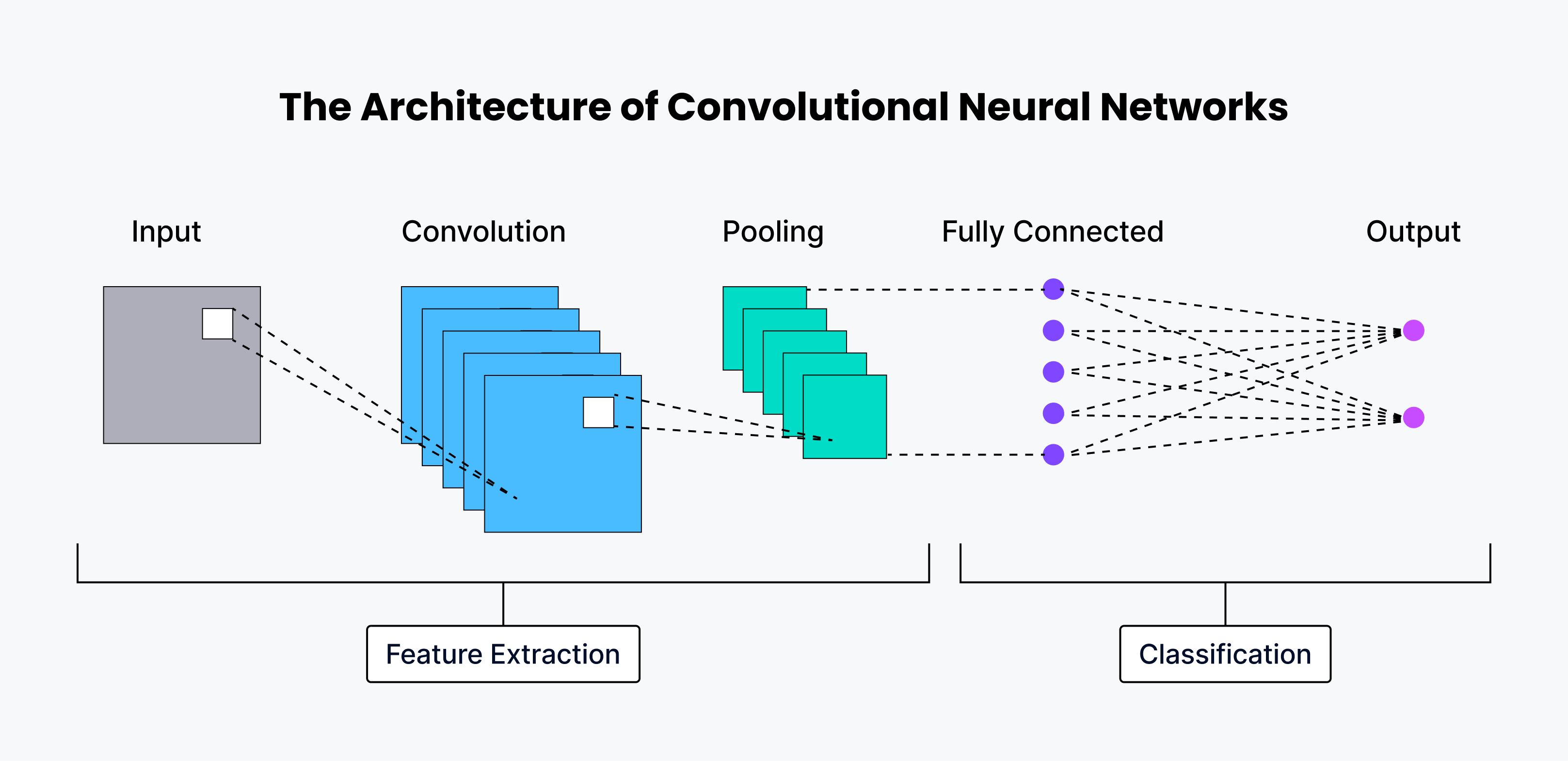
Архитектура ИНС и как она работает
CNN обладает огромными возможностями, что позволяет этим сетям находить скрытые закономерности и расшифровывать визуальные данные с исключительной точностью.
Нейронная система человека состоит из нескольких слоев, каждый из которых отвечает за выполнение уникальной функции. CNN имеют схожую архитектуру, при этом каждый слой извлекает из входного изображения различные характеристики. Ниже приведено подробное описание всех слоев, задействованных в архитектуре CNN.
Первые несколько слоев - это слои конволюции, которые отвечают за извлечение основных характеристик изображения, таких как края и форма.
Следующие несколько слоев - это слои объединения, которые являются выходным слоем, отвечающим за уменьшение размера [карт признаков] (https://www.baeldung.com/cs/cnn-feature-map).
Наконец, последний слой - это полностью связный (FC) слой, который отвечает за классификацию изображения в одну из заданных категорий.
Почти все современные чисто конволюционные архитектуры имеют только один глобальный объединяющий слой в конце, за которым следует один полностью связанный слой.
Сверточный слой
Слой свертки - это ядро CNN, предназначенное для поиска характерных закономерностей во входных данных. Он получает входное изображение и применяет набор фильтров, чтобы получить на выходе карту признаков. Фильтры представляют собой небольшие матрицы весов, которые сканируют входное изображение для выявления различных паттернов. Когда фильтр перемещается по изображению, он делает это с шагом, определяемым шагом (stride) - количеством пикселей, которые фильтр перемещает за каждый шаг. Иногда для управления размером выходного изображения используется подкладка, добавляющая дополнительные пиксели вокруг входного изображения. Существуют различные типы набивки, включая действительную, нулевую (без набивки), одинаковую (размер выхода равен размеру входа) и полную (которая увеличивает размер выхода). После операции свертки применяется нелинейная функция активации, обычно ReLU (Rectified Linear Unit), чтобы внести нелинейность в модель.
Больше сверточных слоев
Как мы уже говорили, после первого конволюционного слоя может быть еще один. Когда это происходит, CNN становится иерархической, поскольку последующие слои могут видеть пиксели, находящиеся в рецептивных полях предыдущих слоев. Такая иерархическая структура позволяет скрытому слою сети изучать более сложные характеристики по мере прохождения данных через слои.
Допустим, мы хотим распознать человеческое лицо на изображении. Лицо можно представить как композицию различных признаков. Это глаза, нос, рот, брови и так далее. Каждая отдельная черта лица - это паттерн более низкого уровня в нейронной сети, а комбинация этих черт - паттерн более высокого уровня, иерархия признаков в зрительной коре CNN.
В первом конволюционном слое сеть может научиться определять простые признаки, такие как края, кривые и базовые формы. Это могут быть очертания черт лица или контраст между различными частями лица.
Классификация изображений на втором слое может объединить эти базовые признаки для распознавания более сложных форм. Например, он может обнаружить круглые формы (возможно, глаза) или изогнутые линии (возможно, контур рта или бровей).
В последующих слоях сеть может начать распознавать целые черты лица, комбинируя шаблоны предыдущих слоев. Один нейрон может срабатывать при обнаружении структуры, похожей на глаз, другой - при обнаружении структуры, похожей на нос.
На последних слоях CNN объединит все эти черты лица, чтобы распознать полное лицо. На этом этапе сеть не просто обнаруживает отдельные черты, а понимает, как эти черты соотносятся друг с другом в контексте лица.
Наконец, конволюционные слои преобразуют изображение в числовые значения, чтобы нейронная сеть могла интерпретировать входные изображения и извлекать закономерности на разных уровнях абстракции. Такое иерархическое обучение признаков является одним из ключевых преимуществ CNN в задачах распознавания образов, позволяющих понимать сложные многокомпонентные объекты, такие как лица.
Пулинг-слой
После слоя свертки часто встречается слой объединения. Цель этого объединяющего слоя - уменьшить размер карты признаков, сохранив при этом наиболее важные признаки. Это помогает снизить вычислительную сложность и контролировать перебор. Существует две распространенные техники объединения: максимальное объединение, при котором берется максимальное значение из небольшой области карты признаков, и среднее объединение, при котором берется среднее значение из небольшой области.
**Полносвязный слой (FC)
Последний слой CNN обычно представляет собой полностью связанный слой, который классифицирует выход CNN. Этот слой похож на традиционный слой нейронной сети, соединяясь со всеми нейронами предыдущего слоя. Он использует высокоуровневые признаки, полученные конволюционными слоями, для выполнения конечной задачи классификации или регрессии.
 The-Architecture-of-Convolutional-Neural-Networks.png
The-Architecture-of-Convolutional-Neural-Networks.png
Основная терминология
При работе с CNN важно понимать некоторые основные термины. Эпоха - это один полный проход по всему обучающему набору данных. Dropout - это техника, используемая для предотвращения избыточной подгонки путем случайного отбрасывания нейронов в процессе обучения. Стохастическая глубина - еще один метод, который сокращает сеть в процессе обучения за счет случайного отбрасывания остаточных блоков.
Страйды - это размер шага, который фильтр делает во время свертки.
Padding-Padding в CNN - это добавление нулей по границам изображения для сохранения его пространственного размера после свертки. Это делается для того, чтобы предотвратить уменьшение изображения и предотвратить потерю информации после каждой операции свертки.
Эпоха-Один полный проход через весь обучающий набор данных.
Dropout (регуляризация) - технология предотвращения перебора путем случайного отбрасывания нейронов во время обучения, что заставляет сеть учиться, а не полагаться на большее количество нейронов.
Стохастическая глубина - сокращает сеть во время обучения за счет случайного отбрасывания остаточных блоков и обхода их преобразований с помощью пропущенных связей. При этом во время тестирования для прогнозирования используется вся сеть. Это приводит к улучшению ошибки тестирования и значительному сокращению времени обучения.
Типы конволюционных нейронных сетей
История и развитие сверточных нейронных сетей насчитывает несколько десятилетий, и многие исследователи внесли в нее свой вклад. Понимание этой истории поможет вам понять современное состояние CNN.
Историческая основа
Кунихико Фукусима заложил основы CNN в 1980 году, работая над "Неокогнитроном", иерархической, многослойной искусственной нейронной сетью. Эта ранняя модель могла обучаться надежному распознаванию визуальных образов.
Ян ЛеКун внес еще один важный вклад в 1989 году, представив работу "Backpropagation Applied to Handwritten Zip Code Recognition". ЛеКун применил метод обратного распространения для обучения нейронных сетей распознаванию паттернов в рукописных почтовых индексах. Это был большой шаг к практическому применению нейронных сетей.
LeNet-5: оригинальная архитектура CNN
ЛеКун и его команда продолжали работать над ней на протяжении 1990-х годов и, наконец, в 1998 году создали LeNet-5. LeNet-5 применила принципы предыдущих работ к распознаванию документов. Она считается оригинальной архитектурой CNN и основой для всех последующих работ.
Эволюция архитектур CNN
Со времен LeNet-5 было разработано множество вариантов архитектур CNN. Большинство инноваций было создано благодаря новым наборам данных, таким как MNIST и CIFAR-10, а также конкурсам, таким как ImageNet Large Scale Visual Recognition Challenge (ILSVRC). К числу известных архитектур CNN, которые были разработаны, относятся:
AlexNet: Разработанная Алексом Крижевским, Ильей Суцкевером и Джеффри Хинтоном, AlexNet победила в ILSVRC 2012 года. Она была глубже и шире, чем предыдущие CNN, использовала активации ReLU и отсев для регуляризации.
VGGNet: Разработанная группой Visual Geometry Group в Оксфорде, VGGNet известна своей простотой и глубиной. В ней используются небольшие конволюционные фильтры 3x3 по всей сети.
GoogLeNet (Inception): Разработанная компанией Google, она представила модуль "Inception", который позволяет проводить более эффективные вычисления и создавать более глубокие сети.
ResNet: Разработанная Microsoft Research, сеть ResNet ввела пропускные соединения и позволила обучать гораздо более глубокие сети (до 152 слоев в оригинальной статье).
ZFNet: Улучшенная по сравнению с AlexNet, сеть ZFNet (названная в честь ее создателей Зейлера и Фергюса) победила в ILSVRC 2013 благодаря настройке гиперпараметров архитектуры.
Каждая из этих архитектур привнесла инновации, которые раздвинули границы возможного в CNN, улучшив производительность в различных задачах компьютерного зрения.
Как спроектировать конволюционную нейронную сеть
При проектировании CNN необходимо принять несколько ключевых решений. К ним относятся выбор размера входного сигнала, определение количества слоев свертки, выбор размера и количества фильтров на входной слой, выбор метода объединения, выбор количества полностью связанных слоев и выбор функций активации. Каждый из этих вариантов может существенно повлиять на производительность и эффективность сети.
Выбор размера входаРазмер входа представляет собой размер изображения, на котором будет обучаться CNN. Размер входного сигнала должен быть достаточно большим, чтобы сеть могла извлечь все признаки объекта, который она собирается классифицировать.
Выберите количество слоев свертки - от этого зависит, сколько признаков сможет изучить сеть. Большее количество слоев свертки позволяет изучать более сложные признаки, но при этом увеличивается время вычислений.
Выбор размера фильтра-Размер фильтра вместе с шагом свертки определяют размер признаков, которые будут извлечены из изображений. Фильтр большей размерности будет извлекать большее количество признаков.
Выберите количество фильтров на слой - это определяет количество различных признаков, которые можно извлечь из изображения.
Выберите метод объединения - двумя распространенными методами объединения являются максимальное и среднее объединение. При максимальном объединении берется максимальное значение из небольшой области карты признаков, а при среднем объединении берется среднее значение из небольшой области карты признаков.
Выберите количество полностью связанных слоев - это определяет количество классов, которые может классифицировать сеть.
Выберите функцию активации - функция активации позволяет изучать более сложные паттерны из набора данных изображений. Для бинарной классификации обычно используется сигмоидальная функция. При постановке задачи многоклассовой классификации в слое FC используется функция активации softmax. Для внесения нелинейности в данные в настоящее время чаще всего используют GeLU или Swish функции активации.
Ниже приведен простой пример реализации CNN на Python, который классифицирует дорожные знаки. Найдите набор данных на сайте Kaggle.
Простая реализация CNN с помощью PyTorch
Для реализации CNN-модели на Python используйте такие фреймворки, как PyTorch, TensorFlow, Keras и др. Эти фреймворки обеспечивают реализацию всех слоев, необходимых для CNN.
Процесс начинается с импорта необходимых модулей, как показано ниже:
# зависимости для вычислений
import pandas as pd
import numpy as np
# зависимости для чтения и отображения изображений
from cv2 import resize
from skimage.io import imread
import matplotlib.pyplot as plt
%matplotlib inline
# зависимость для создания валидационного набора
from sklearn.model_selection import train_test_split
# зависимость для оценки модели
from sklearn.metrics import accuracy_score
from tqdm import tqdm
# библиотеки и модули PyTorch
import torch
from torch.autograd import Variable
from torch.nn import (Linear, ReLU, CrossEntropyLoss,
Sequential, Conv2d, MaxPool2d, Module,
Softmax, BatchNorm2d, Dropout)
из torch.optim import Adam, SGD
После этого загрузите набор данных и изображения с помощью следующего кода:
# загрузка набора данных
train = pd.read_csv('Data/train.csv')
# загрузка обучающих изображений
train_img = []
for img_name in tqdm(train['Path']):
# определение пути к изображениям
image_path = 'Data/' + str(img_name)
# чтение изображения
img = imread(image_path, as_gray=True)
# изменение размера изображения
img = resize(img, (28, 28))
# нормализация значений пикселей
img /= 255.0
# преобразование типа пикселя в float 32
img = img.astype('float32')
# добавляем изображение в список
train_img.append(img)
# преобразование списка в массив numpy
train_x = np.array(train_img)
# определение цели
train_y = train['ClassId'].values
train_x.shape
После загрузки обучающих данных вам нужно будет создать обучающий и проверочный наборы данных с помощью метода train_test_split() из sklearn.
# создать проверочный набор
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1)
# Проверьте формы обучающего и проверочного наборов
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
Вам также потребуется изменить форму данных для модели Torch следующим образом:
# преобразование обучающих изображений в формат Torch
train_x = train_x.reshape(-1, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# преобразование целевого изображения в формат torch
train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y)
# преобразование изображений для проверки в формат torch
val_x = val_x.reshape(-1, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# преобразование целевого изображения в формат torch
val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y)
Затем определите различные слои CNN следующим образом:
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# Определение двумерного слоя свертки
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Определение еще одного двумерного сверточного слоя
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
# финальный плотный слой для предсказания
self.linear_layers = Sequential(
Linear(4 * 7 * 7, 43)
)
# Определение прямого прохода
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
возвращать x
Приведенная выше сеть CNN состоит из двух слоев свертки, за которыми следует слой максимального объединения с пространственными размерами 2 на 2.
Слой сглаживания помогает классифицировать скрытые слои в изображении знака на соответствующие классы.
Далее определимся с оптимизатором и функцией потерь, а также определим процедуру обучения.
# определение модели
model = Net()
# определение оптимизатора
optimizer = Adam(model.parameters(), lr=0.07)
# определение функции потерь
criterion = CrossEntropyLoss()
# проверка доступности GPU
if torch.cuda.is_available():
model = model.cuda()
критерий = criterion.cuda()
print(model)
def train(epoch):
model.train()
tr_loss = 0
# получение обучающего набора
x_train, y_train = Variable(train_x), Variable(train_y)
# получение валидационного набора
x_val, y_val = Variable(val_x), Variable(val_y)
# преобразование данных в формат GPU
if torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# очистите градиенты параметров модели
optimizer.zeroo_grad()
# прогнозирование для обучающего и проверочного множества
output_train = model(x_train)
output_val = model(x_val)
# вычисление потерь при обучении и проверке
loss_train = criterion(output_train, y_train)
loss_val = criterion(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# обратное распространение и обновление параметров модели
loss_train.backward()
optimizer.step()
tr_loss = loss_train.item()
if epoch%2 == 0:
# печать валидационных потерь
print('Epoch : ',epoch+1, '\t', 'loss :', loss_val)
Наконец, обучите модель в течение 25 эпох на обучающих данных следующим образом:
# определение количества эпох
n_epochs = 25
# пустой список для хранения потерь при обучении
train_losses = []
# пустой список для хранения потерь при проверке
val_losses = []
# обучение модели
for epoch in range(n_epochs):
train(epoch)
В итоге каждая модель будет делать предсказания на тестовых данных. Чтобы узнать больше подробностей, обратитесь к этому блогу как написать CNN с нуля в PyTorch.
FAQs
В чем разница между CNN и Deep Neural Networks?
CNN - это тип нейронной сети, которая может обрабатывать визуальные данные, такие как изображения, речь, видео и т.д., а глубокие нейронные сети (DNNs) - это тип искусственной нейронной сети, которая может изучать сложные паттерны из данных.
Ниже перечислены ключевые различия между CNN и DNN.
CNN имеет особую архитектуру для обработки изображений. С другой стороны, DNN не имеет какой-либо конкретной архитектуры и может работать для решения различных задач.
CNN изучает особенности изображений с помощью слоев свертки, в то время как DNN изучает особенности с помощью различных [типов слоев] (https://www.geeksforgeeks.org/deep-neural-network-with-l-layers/).
CNN сложнее обучать, она требует больше данных и требует больших вычислительных затрат по сравнению с DNN.
Каковы три слоя CNN?
Три слоя CNN - это слой активации, слой свертки, слой объединения и полностью связанный слой.
Слой свертки - этот слой отвечает за извлечение признаков из изображений. Он работает путем сканирования изображений с помощью фильтра, который представляет собой небольшую матрицу весов. Фильтр перемещается по изображению, а веса умножаются на значения пикселей на изображении. В итоге получается карта признаков, содержащая извлеченные признаки.
Слой объединения-Слой объединения уменьшает размер карт признаков. Для этого используются два распространенных метода объединения - максимальное объединение и среднее объединение.
Полностью связанный слой - это то же самое, что и традиционные нейронные сети, которые классифицируют выход CNN. Нейроны в полностью связанных слоях классифицируют изображение на множество классов.
**Что такое конволюционная нейронная сеть в глубоком обучении?
Конволюционная нейронная сеть - это тип глубокой нейронной сети, которая обрабатывает изображения, речи и видео, чтобы вы могли использовать их для реальных прогнозов на основе структурированных/неструктурированных данных в растущем цифровом мире.
CNN помогает легко и эффективно предсказывать человеческие эмоции, поведение, интересы, симпатии, антипатии и т. д.
- **Основные причины использования CNN**
- Преимущества и недостатки конволюционных нейронных сетей
- Распространенные методы регуляризации в CNN
- **Архитектура ИНС и как она работает**
- Типы конволюционных нейронных сетей
- **Как спроектировать конволюционную нейронную сеть**
- **Простая реализация CNN с помощью PyTorch**
- **FAQs**
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно