




10 estruturas LLM de código aberto que os programadores não podem ignorar em 2025
2024 foi um ano marcante para grandes modelos de linguagem (LLMs)) e, à medida que entramos em 2025, a dinâmica não mostra sinais de abrandamento. Do GPT-4 e Gemini recursos multimodais aos sistemas de IA adaptativos em tempo real, os LLMs não são mais apenas de ponta - eles são essenciais. Estão a alimentar chatbots, motores de busca, ferramentas de criação de conteúdos e até a automatizar fluxos de trabalho que outrora pensávamos que só os humanos conseguiriam gerir.
Mas o problema é o seguinte: ter um LLM poderoso é apenas metade da batalha. Criar aplicações LLM escaláveis, eficientes e prontas para produção pode ser um desafio - é aí que entram as estruturas LLM. Elas simplificam os fluxos de trabalho, melhoram o desempenho e se integram perfeitamente aos sistemas existentes, ajudando os desenvolvedores a liberar todo o potencial desses modelos com menos esforço.
Nesta postagem, destacaremos 10 estruturas LLM de código aberto que os desenvolvedores de IA não podem ignorar em direção a 2025. Essas estruturas são as armas secretas que ajudam os desenvolvedores a escalar, otimizar e inovar mais rápido do que nunca. Se você está pronto para aumentar o nível de seus projetos de IA, vamos mergulhar!
LangChain: Potencializando fluxos de trabalho de IA de várias etapas e com reconhecimento de contexto
A [LangChain] (https://github.com/langchain-ai/langchain) é uma estrutura de código aberto concebida para simplificar o desenvolvimento de aplicações alimentadas por modelos de linguagem de grande dimensão (LLMs). Simplifica a criação de fluxos de trabalho que combinam LLMs com fontes de dados externas, APIs ou lógica computacional, permitindo aos programadores criar sistemas dinâmicos e sensíveis ao contexto para tarefas como agentes de conversação, análise de documentos e resumo.
Principais capacidades
Pipelines compostáveis**: O LangChain facilita o encadeamento de várias chamadas LLM e funções externas, permitindo fluxos de trabalho complexos em várias etapas.
Cadeias prontas para uso**: O LangChain oferece cadeias pré-configuradas, conjuntos organizados de componentes projetados para realizar tarefas específicas de nível superior. Estas cadeias prontas a usar simplificam o início de projectos.
Utilitários de engenharia de prompts**: Inclui ferramentas para criar, gerir e otimizar prompts adaptados a tarefas específicas.
Gerenciamento de memória**: Oferece capacidades integradas para reter o contexto de conversação entre interações, permitindo aplicações mais personalizadas.
A LangChain ligou-se a APIs de terceiros, bases de dados vectoriais, LLMs e várias fontes de dados. Em particular, a integração da LangChain com bases de dados vectoriais como a Milvus e a Zilliz Cloud aumenta ainda mais o seu potencial. O Milvus é uma base de dados vetorial de alto desempenho e de código aberto para gerir e consultar vectores de incorporação à escala de milhares de milhões. Complementa as capacidades da LangChain, permitindo a recuperação rápida e exacta de dados relevantes. Os programadores podem tirar partido desta integração para criar sistemas escaláveis Retrieval-Augmented Generation (RAG) em que o Milvus recupera documentos contextualmente relevantes. A LangChain utiliza um modelo generativo para produzir resultados precisos e perspicazes. Para mais informações, consulte os recursos abaixo:
Como construir um RAG multilingue com Milvus, LangChain e OpenAI
Geração Aumentada de Recuperação em Documentos de Noção via LangChain
LlamaIndex: Conectando LLMs a diversas fontes de dados
O [LlamaIndex] (https://github.com/run-llama/llama_index) é uma estrutura de código aberto que permite que modelos de linguagem de grande porte (LLMs) acessem e aproveitem eficientemente diversas fontes de dados. Simplifica a ingestão, a estruturação e a consulta de dados não estruturados, facilitando a criação de aplicações avançadas de IA, como a recuperação de documentos, o resumo e os chatbots baseados no conhecimento.
Principais capacidades
Conectores de dados**: Fornece um conjunto robusto de conectores para a ingestão de dados estruturados e não estruturados de diversas fontes, como PDFs, bases de dados SQL, APIs e armazenamentos vectoriais.
Ferramentas de indexação**: Permite que os programadores criem índices personalizados, incluindo estruturas baseadas em árvores, listas e gráficos, para otimizar a consulta e a recuperação de dados.
Otimização de consultas**: Oferece mecanismos de consulta avançados que permitem respostas precisas e contextualmente relevantes.
Extensibilidade**: Altamente modular, o que facilita a integração com bibliotecas e ferramentas externas para melhorar a funcionalidade.
Estrutura optimizada para LLM**: Concebida para trabalhar com LLMs, garantindo uma utilização eficiente dos recursos computacionais para tarefas de grande escala.
O LlamaIndex foi integrado em várias bases de dados vectoriais criadas para o efeito, como o Milvus e o Zilliz Cloud, para suportar fluxos de trabalho RAG escaláveis e eficientes. Nesta configuração, o Milvus actua como um backend de alto desempenho para armazenar e consultar vectores de incorporação, enquanto o LlamaIndex estrutura e organiza os dados recuperados para serem processados pelos LLMs. Essa combinação permite que os desenvolvedores recuperem os pontos de dados mais relevantes e possibilita que as LLMs forneçam resultados mais precisos e conscientes do contexto. Para mais informações, consulte os recursos abaixo:
Docs | Controlo de qualidade da documentação utilizando o Zilliz Cloud e o LlamaIndex
Vídeo com Jerry Liu, CEO da LlamaIndex | Impulsione o seu LLM com dados privados utilizando a LlamaIndex](https://zilliz.com/event/boost-your-llm-with-private-data-using-llamaindex)
Haystack: Simplificando os pipelines RAG para aplicativos de IA prontos para produção
Haystack é uma estrutura Python de código aberto concebida para facilitar o desenvolvimento de aplicações alimentadas por LLM. Ele permite que os desenvolvedores criem soluções de IA de ponta a ponta, integrando LLMs com várias fontes de dados e componentes, tornando-o adequado para tarefas como RAG, pesquisa de documentos, resposta a perguntas e geração de respostas.
Principais capacidades
Pipelines flexíveis**: O Haystack permite a criação de pipelines modulares para tarefas como recuperação de documentos, resposta a perguntas e resumo. Os programadores podem combinar diferentes componentes para adaptar os fluxos de trabalho às suas necessidades específicas.
Arquitetura Recuperador-Leitor**: Combina recuperadores para filtragem eficiente de documentos com leitores (por exemplo, LLMs) para gerar respostas precisas e contextualmente conscientes.
Agnóstico de backend**: Suporta vários backends de bases de dados vectoriais, incluindo Milvus e FAISS, garantindo flexibilidade na implementação.
Integração com o LLM**: Fornece integração perfeita com modelos de linguagem, permitindo que os desenvolvedores aproveitem modelos pré-treinados e ajustados para várias tarefas.
Escalabilidade e desempenho**: Optimizado para lidar com conjuntos de dados de grande escala e consultas de alto rendimento, adequado para aplicações empresariais.
Em março de 2024, o Haystack lançou o Haystack 2.0, introduzindo uma arquitetura mais flexível e personalizável. Essa atualização permite a criação de pipelines complexos com recursos como ramificação paralela e looping, aprimorando o suporte para LLMs e comportamento agêntico. O novo design enfatiza uma interface comum para armazenar dados, fornecendo integrações com vários bancos de dados e armazenamentos vetoriais, incluindo Milvus e Zilliz Cloud. Essa flexibilidade garante que os dados possam ser facilmente acessados e gerenciados dentro dos pipelines Haystack, apoiando o desenvolvimento de aplicativos de IA escaláveis e de alto desempenho. Para mais informações, consulte os recursos abaixo:
Haystack GitHub: https://github.com/deepset-ai/haystack
Integração: Haystack e Milvus
Tutorial: Retrieval-Augmented Generation (RAG) com Milvus e Haystack
Tutorial: Construir um pipeline RAG com Milvus e Haystack 2.0
Dify: Simplificando o Desenvolvimento de Aplicações com LLM
A [Dify] (https://github.com/langgenius/dify) é uma plataforma de código aberto para a criação de aplicações de IA. Ele combina Backend-as-a-Service com LLMOps, suportando modelos de linguagem convencionais e oferecendo uma interface de orquestração de prompt intuitiva. A Dify fornece motores RAG de alta qualidade, uma estrutura de agente de IA flexível e um fluxo de trabalho intuitivo de baixo código, permitindo que tanto os programadores como os utilizadores não técnicos criem soluções de IA inovadoras.
Principais capacidades
Backend-as-a-Service para LLMs**: Trata da infraestrutura de backend, permitindo que os programadores se concentrem na criação de aplicações em vez de gerir servidores.
Orquestração de prompts**: Simplifica a criação, teste e gestão de prompts adaptados a tarefas específicas.
Análise em tempo real**: Fornece informações sobre o desempenho do modelo, as interações do utilizador e o comportamento da aplicação para otimizar os fluxos de trabalho.
Opções de integração extensivas**: Conecta-se com APIs de terceiros, ferramentas externas e LLMs populares, oferecendo flexibilidade para fluxos de trabalho personalizados.
A Dify integra-se bem com bases de dados vectoriais como o Milvus, aumentando a sua capacidade de lidar com tarefas complexas de recuperação de dados em grande escala. Ao emparelhar a Dify com o Milvus, os programadores podem criar sistemas que armazenam, recuperam e processam eficientemente os embeddings para tarefas como o RAG.
Letta (Anteriormente MemGPT): Construindo Agentes RAG com Janela de Contexto LLM Estendida
Letta é uma estrutura de código aberto projetada para melhorar os LLMs, equipando-os com memória de longo prazo. Ao contrário dos LLMs tradicionais que processam entradas de forma estática, o Letta permite que o modelo se lembre e faça referência a interações passadas, permitindo aplicações mais dinâmicas, contextualmente conscientes e personalizadas. Integra técnicas de gestão de memória para armazenar, recuperar e atualizar informações ao longo do tempo, tornando-o ideal para criar agentes inteligentes e sistemas de conversação que evoluem com as interações do utilizador.
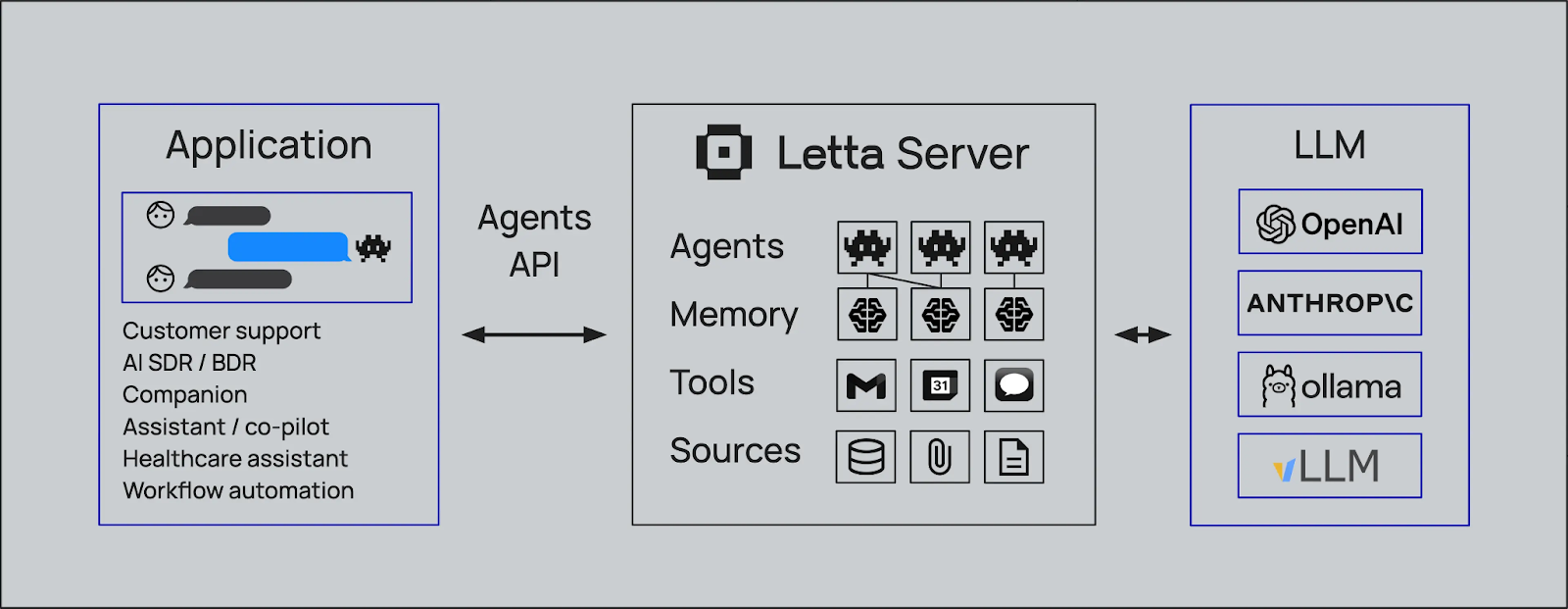 Figura - Como o Letta funciona com várias ferramentas de IA
Figura - Como o Letta funciona com várias ferramentas de IA
Principais capacidades
Memória de auto-edição:** Letta introduz a memória de auto-edição, permitindo que os agentes actualizem autonomamente a sua base de conhecimentos, aprendam com as interações e se adaptem ao longo do tempo.
Ambiente de desenvolvimento de agente (ADE): Fornece uma interface gráfica para criar, implantar, interagir e observar agentes de IA, simplificando o processo de desenvolvimento e depuração.
Persistência e gestão do estado:** Assegura que os agentes mantêm a continuidade entre sessões através da persistência do seu estado, incluindo memórias e interações, permitindo respostas mais coerentes e contextualmente relevantes.
Integração de ferramentas:** Suporta a incorporação de ferramentas e fontes de dados personalizadas, permitindo que os agentes executem uma ampla gama de tarefas e acedam a informações externas conforme necessário
Arquitetura agnóstica de modelos:** Concebida para funcionar com vários LLM e sistemas RAG, proporcionando flexibilidade na escolha e integração de diferentes fornecedores de modelos
O Letta foi integrado nas principais bases de dados vectoriais para melhorar as suas capacidades de memória e recuperação para fluxos de trabalho RAG avançados. Ao tirar partido do armazenamento vetorial escalável e da pesquisa eficiente de semelhanças, o Letta permite que os agentes de IA acedam e retenham conhecimentos contextuais a longo prazo, garantindo uma recuperação de dados rápida e precisa. Esta integração permite que os programadores criem aplicações mais inteligentes e sensíveis ao contexto, adaptadas a domínios específicos, como o apoio ao cliente ou recomendações personalizadas, mantendo a memória persistente e escalável. Consulte os recursos abaixo para obter mais informações.
- Tutorial | MemGPT com integração Milvus
Vanna: Permitindo a geração de SQL com IA
Vanna é uma estrutura Python de código aberto concebida para simplificar a geração de consultas SQL através de entradas de linguagem natural. Ao tirar partido das técnicas RAG, o Vanna permite aos utilizadores treinar modelos nos seus dados específicos, permitindo-lhes colocar questões e receber consultas SQL precisas adaptadas às suas bases de dados. Esta abordagem simplifica o processo de interação com as bases de dados, tornando-o mais acessível aos utilizadores sem grandes conhecimentos de SQL.
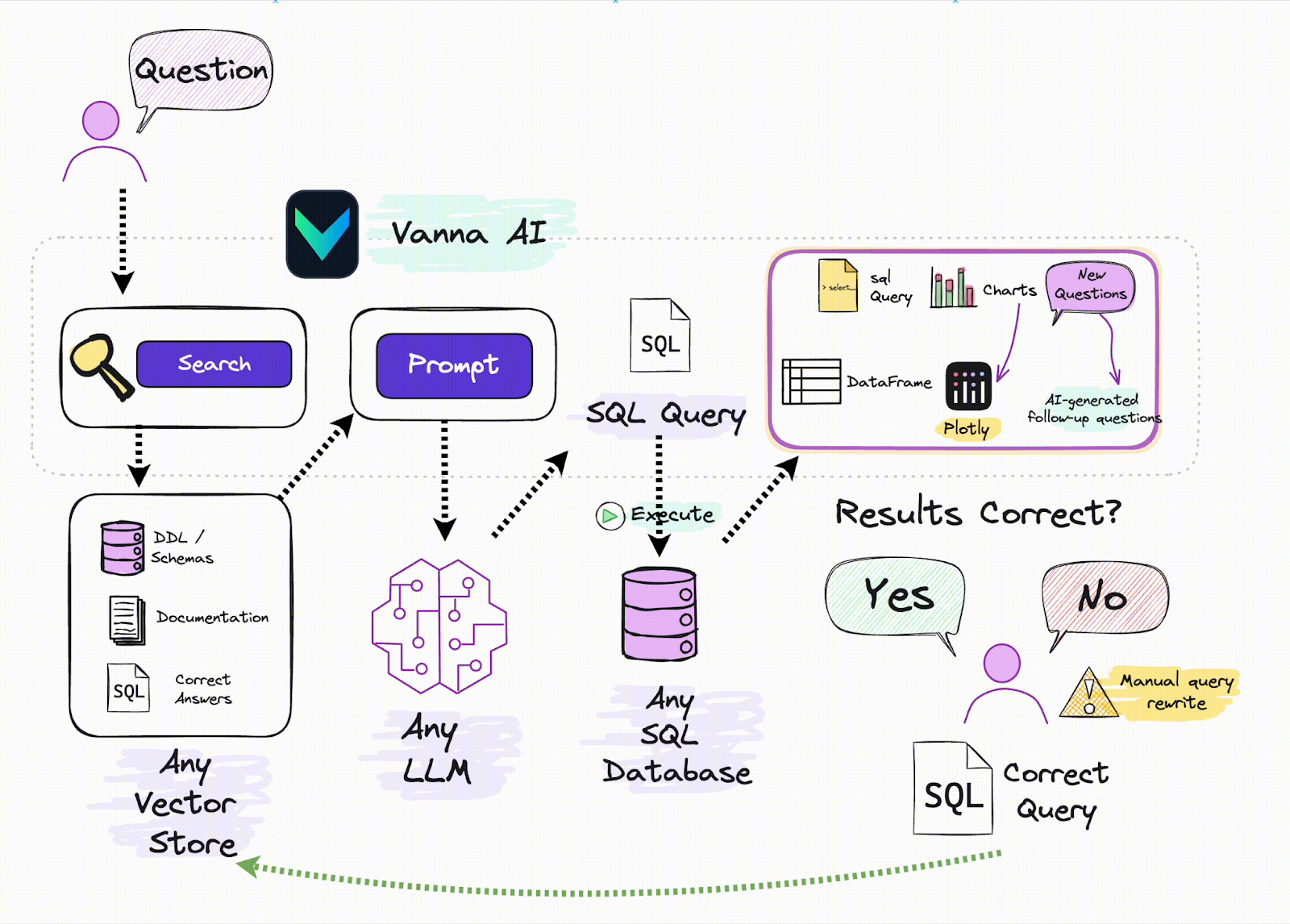 Vanna
Vanna
Principais capacidades
Conversão de linguagem natural para SQL**: O Vanna permite que os utilizadores introduzam perguntas em linguagem natural, que depois converte em consultas SQL precisas executáveis na base de dados ligada.
Suporte para várias bases de dados**: A estrutura oferece suporte pronto para uso para vários bancos de dados, incluindo Snowflake, BigQuery, Postgres e muito mais. Também permite uma fácil integração com qualquer base de dados através de conectores personalizados.
Flexibilidade da interface do utilizador**: O Vanna oferece várias opções de interface de utilizador, tais como Jupyter Notebooks, Slackbot, aplicações Web e aplicações Streamlit, permitindo aos utilizadores escolher o front end que melhor se adapta ao seu fluxo de trabalho.
O Vanna e as bases de dados vectoriais são uma excelente combinação para criar sistemas RAG eficazes. Quando um utilizador introduz uma consulta em linguagem natural, o Vanna utiliza uma base de dados vetorial para obter dados relevantes com base em incorporações vectoriais pré-armazenadas. Estes dados são depois utilizados para ajudar o Vanna a gerar uma consulta SQL precisa, facilitando a obtenção de dados estruturados a partir de uma base de dados relacional. Ao combinar o poder da pesquisa vetorial com a geração de SQL, o Vanna simplifica o trabalho com dados não estruturados e permite aos utilizadores interagir com conjuntos de dados complexos sem necessitar de conhecimentos avançados de SQL. Para mais informações, consulte os recursos abaixo:
Kotaemon: Construindo QA de documentos com IA
O Kotaemon é uma IU RAG personalizável e de código aberto para conversar com os seus documentos. O kotaemon oferece um pipeline RAG híbrido com capacidades de recuperação de texto integral e vetorial, permitindo o QA multimodal para documentos com figuras e tabelas.
Concebido tanto para utilizadores finais como para programadores, o kotaemon suporta métodos de raciocínio complexos como o ReAct e o ReWOO. Inclui citações avançadas com pré-visualizações de documentos, definições configuráveis para recuperação e geração, e uma estrutura extensível para a criação de pipelines RAG personalizados.
 Kotaemon
Kotaemon
Capacidades chave
Fácil implantação**: O Kotaemon oferece interfaces simples para implantar LLMs em produção com configuração mínima, permitindo escalonamento e integração rápidos.
Pipelines personalizáveis**: Permite que os programadores personalizem facilmente os fluxos de trabalho de IA, combinando LLMs com APIs externas, bases de dados e outras ferramentas.
Prompting avançado**: Inclui ferramentas integradas para engenharia e otimização de prompts, facilitando o ajuste fino dos resultados do modelo para tarefas específicas.
Otimização do desempenho**: Concebido para operações de elevado desempenho, o Kotaemon assegura respostas de baixa latência e uma utilização eficiente dos recursos.
Suporte a vários modelos**: A estrutura suporta várias arquiteturas LLM, dando aos desenvolvedores a flexibilidade de escolher o melhor modelo para seu caso de uso específico.
O Kotaemon integra-se com bases de dados vectoriais como o Milvus, permitindo a rápida recuperação de dados relevantes para tarefas como a Retrieval-Augmented Generation (RAG). Ao tirar partido das capacidades eficientes de pesquisa vetorial do Milvus, o Kotaemon pode melhorar o contexto e a relevância dos resultados gerados pela IA. Esta integração permite aos programadores criar sistemas de IA que geram conteúdos e recuperam informações relevantes de grandes conjuntos de dados, melhorando o desempenho e a precisão globais.
vLLM: Inferência LLM de alto desempenho para aplicações de IA em tempo real
A vLLM é uma biblioteca de código aberto desenvolvida pelo SkyLab da UC Berkeley, concebida para otimizar a inferência e o serviço LLM. Com foco no desempenho e na escalabilidade, a vLLM apresenta inovações como PagedAttention, que aumenta a velocidade de veiculação em até 24x e reduz o uso de memória da GPU pela metade em comparação com as abordagens tradicionais. Isso o torna um divisor de águas para os desenvolvedores que criam aplicativos de IA exigentes que requerem a utilização eficiente de recursos de hardware.
Principais recursos:
Tecnologia PagedAttention: Melhora o gerenciamento de memória ao permitir o armazenamento não contíguo de chaves e valores de atenção, reduzindo o desperdício de memória e melhorando o rendimento em até 24x.
Agregação contínua: agrega solicitações recebidas em tempo real, maximizando a utilização da GPU e minimizando o tempo ocioso, resultando em maior rendimento e menor latência.
Saídas de streaming:** Fornece geração de token em tempo real, permitindo que os aplicativos forneçam resultados parciais imediatamente - ideal para interações de usuário em tempo real, como chatbots.
Ampla compatibilidade de modelos:** Suporta arquiteturas LLM populares como GPT e LLaMA, garantindo flexibilidade para muitos casos de uso e integração perfeita com fluxos de trabalho existentes.
Servidor de API compatível com OpenAI:** Oferece uma interface de API que espelha a do OpenAI, simplificando a implantação e a integração em sistemas existentes para desenvolvedores familiarizados com as APIs do OpenAI.
O vLLM torna-se uma pedra angular para a criação de sistemas RAG de alto desempenho quando combinado com bancos de dados vetoriais como o Milvus. Os bancos de dados vetoriais armazenam e recuperam eficientemente embeddings de alta dimensão, essenciais para a recuperação de informações contextualmente relevantes. O vLLM complementa isso fornecendo inferência LLM otimizada, garantindo que as informações recuperadas sejam processadas sem problemas em respostas precisas e conscientes do contexto. Essa integração melhora o desempenho do aplicativo e aborda desafios como alucinações de IA, fundamentando os resultados nos dados recuperados. Confira os recursos abaixo para obter mais informações.
Não estruturados: Tornando dados não estruturados acessíveis para GenAI
A Unstructured é uma biblioteca de código aberto que simplifica a ingestão e o pré-processamento de dados não estruturados de diversos formatos de dados, incluindo PDFs, HTML, documentos do Word e imagens. Oferece funções modulares para particionar, limpar, extrair, preparar e fragmentar documentos, facilitando a transformação de dados não estruturados em formatos estruturados. Este conjunto de ferramentas é benéfico para a otimização de fluxos de trabalho de dados em aplicações de Modelo de Linguagem Grande (LLM).
A integração da Unstructured com uma base de dados vetorial como a Milvus cria uma solução poderosa e escalável para gerir e tirar partido de dados não estruturados em aplicações de IA. A plataforma Unstructured ingere, processa e transforma dados não estruturados de vários tipos de arquivo em [embeddings vetoriais] prontos para IA (https://zilliz.com/glossary/vetor-embeddings). Esses embeddings são cruciais para fluxos de trabalho avançados de IA, mas armazená-los, indexá-los e consultá-los com eficiência requer um banco de dados vetorial especializado. A sinergia entre o Unstructured e o Milvus (ou o Zilliz Cloud) permite um pipeline simplificado de ponta a ponta, o que é particularmente valioso para o Retrieval-Augmented Generation (RAG) e outras aplicações orientadas para a IA, como chatbots inteligentes e sistemas de recomendação personalizados.
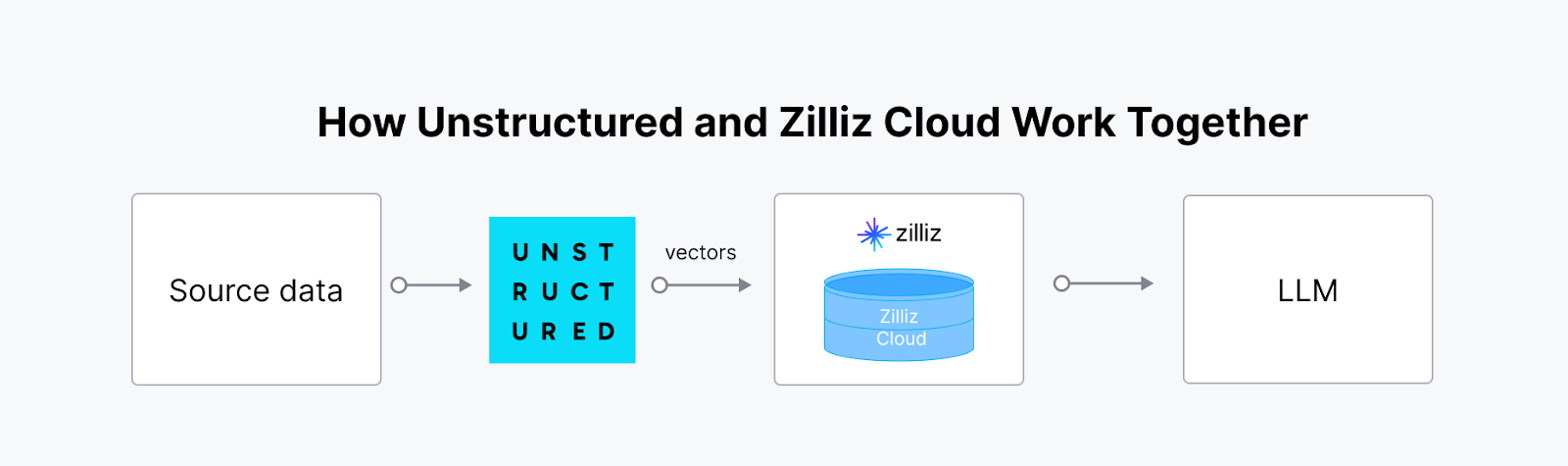 Não estruturado
Não estruturado
Tutorial | Construir um RAG com Milvus e Unstructured
Blogue | Vectorização e consulta de conteúdo EPUB com o Unstructured e o Milvus
Langfuse: melhor observabilidade e análise para aplicações LLM
Langfuse é uma plataforma de engenharia LLM de código aberto que ajuda as equipas a depurar, analisar e iterar de forma colaborativa as suas aplicações LLM. Oferece funcionalidades como observabilidade, gestão de pedidos, avaliações e métricas, todas nativamente integradas para acelerar o fluxo de trabalho de desenvolvimento.
Principais recursos
Observabilidade de ponta a ponta**: Rastreia as interações LLM, incluindo avisos, respostas e métricas de desempenho, para garantir transparência e fiabilidade.
Gerenciamento de prompts**: Oferece ferramentas para versionar, otimizar e testar prompts, simplificando o desenvolvimento de aplicações de IA robustas.
Integração flexível**: Funciona sem problemas com estruturas populares como LangChain e LlamaIndex, suportando uma ampla gama de arquitecturas LLM.
Depuração em tempo real**: Fornece informações úteis sobre erros e gargalos, permitindo que os desenvolvedores façam iterações rapidamente.
A integração do Langfuse com bases de dados vectoriais melhora os fluxos de trabalho RAG, proporcionando observabilidade na qualidade e relevância da incorporação. Esta integração permite que os programadores monitorizem e optimizem o desempenho e a precisão da pesquisa de vectores através de análises detalhadas, assegurando que os processos de recuperação estão bem afinados e alinhados com as necessidades dos utilizadores. Para começar, consulte o seguinte tutorial.
Conclusão
Com o início de 2025, fica claro que os frameworks de código aberto não são mais apenas complementos úteis - eles são fundamentais para a construção de aplicações LLM robustas. Frameworks como LangChain e LlamaIndex transformaram a forma como integramos e consultamos dados, enquanto vLLM e Haystack estão estabelecendo novos padrões de velocidade e escalabilidade. Estruturas emergentes como Langfuse e Letta trazem pontos fortes únicos em observabilidade e memória, abrindo portas para sistemas de IA mais inteligentes e responsivos.
Estas estruturas permitem que os programadores enfrentem desafios complexos, experimentem ideias arrojadas e ultrapassem os limites do que é possível. Com estas estruturas na ponta dos dedos, 2025 é o seu ano para criar aplicações GenAI mais inteligentes, mais rápidas e mais impactantes.

Continue lendo

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.