




A interrupção da AWS foi um alerta para a recuperação de desastres entre regiões de bancos de dados vetoriais
Regiões de nuvem falham. Não é uma questão de se — é uma questão de quando e quão grave.
Na semana passada, duas regiões da AWS no Oriente Médio ficaram offline devido a danos físicos à infraestrutura dos data centers. Duas das três zonas de disponibilidade na região dos EAU da AWS (ME-CENTRAL-1) foram derrubadas, e uma instalação no Bahrein (ME-SOUTH-1) foi danificada. Mais de 60 serviços da AWS foram impactados, incluindo Lambda, EKS, VPC, S3 e CloudWatch. A Careem, a maior plataforma de transporte por aplicativo da região, perdeu o serviço. A Alaan, uma provedora líder de pagamentos, ficou fora do ar. A AWS aconselhou os clientes a transferir cargas de trabalho para outras regiões — mas este não foi um incidente de reiniciar e recuperar. Com substituição de hardware e reparo das instalações, a recuperação pode levar semanas.
E danos físicos são apenas um modo de falha. Nos últimos 12 meses, uma alteração de configuração defeituosa derrubou a região Central US do Azure por 14,5 horas. Um bug no Google Cloud derrubou Cloud Run, GKE e Firebase simultaneamente por 8 horas. Uma atualização de software problemática da CrowdStrike — nem sequer um problema de provedor de nuvem — se propagou pela infraestrutura hospedada no Azure, custando às empresas da Fortune 500 uma estimativa de US$ 5,4 bilhões.
O relatório de 2025 do Uptime Institute coloca o custo mediano de uma interrupção de alto impacto em US$ 2 milhões por hora, aproximadamente o dobro do valor de três anos atrás. Ainda assim, o Data Protection Trends Report 2024 da Veeam descobriu que apenas 13% das organizações conseguem realmente orquestrar a recuperação durante um desastre real.
Esses números já eram alarmantes. Então a IA elevou os riscos.
Quando a IA Sai do Ar, as Equipes Não Desaceleram — Elas Param
Cinco anos atrás, uma falha regional de nuvem afetava principalmente aplicativos voltados para clientes. Doloroso, mas a maioria das equipes ainda conseguia funcionar internamente. Hoje, a IA absorveu trabalho que abrange departamentos inteiros — revisão de código, documentação, triagem de suporte e até análises rotineiras. Com quase 60% dos funcionários usando IA em fluxos de trabalho diários, interrupções não causam uma desaceleração gradual. A produtividade despenca.
Já vimos isso acontecer — ChatGPT e Claude sofreram interrupções significativas no início de 2026, deixando milhões de usuários e equipes corporativas sem as ferramentas de IA em torno das quais haviam construído seus fluxos de trabalho.
Mas aqui está o que a maioria das equipes não percebe. Interrupções de modelos são disruptivas, mas os modelos são em grande parte sem estado: os provedores muitas vezes conseguem redirecionar o tráfego de inferência para regiões saudáveis relativamente rápido. O problema mais difícil é a camada de dados por baixo — os bancos de dados, armazenamentos de objetos e índices vetoriais que fornecem memória e contexto. Essa camada tem estado, é vinculada a uma região e é muito mais difícil de recuperar. Quando ela sai do ar, seu LLM ainda pode gerar texto — mas sem o contexto correto, ele recorre a saídas genéricas e propensas a alucinações. A IA não fica apenas offline. Ela se torna não confiável.
O Banco de Dados Vetorial é a Memória de Longo Prazo da Sua IA — e Provavelmente Está em uma Única Região
Bancos de dados vetoriais se tornaram a espinha dorsal da IA corporativa. Pipelines de RAG e agentes de IA recuperam contexto deles. Mecanismos de recomendação os consultam. A busca semântica roda sobre eles. Quando essa camada está indisponível, todas as aplicações construídas sobre ela quebram — não parcialmente, mas completamente.
E, diferentemente de serviços sem estado, a recuperação não é simples:
- Reconstruções de índice são lentas. A busca vetorial depende de estruturas de índice como grafos HNSW, em que o tempo de reconstrução escala de forma não linear com o tamanho do conjunto de dados. Reconstruir um índice com mais de 100 milhões de vetores pode levar mais de 18 horas em computação padrão.
- Strings de conexão estão por toda parte. Toda aplicação que se conectava ao cluster antigo precisa ter seu endpoint atualizado — em configurações, variáveis de ambiente, pipelines de CI/CD, muitas vezes gerenciados por equipes diferentes.
- Deriva do modelo de embedding. Se você não conseguir localizar a versão exata do modelo de embedding que gerou seus vetores atuais, talvez precise re-embedar todo o seu conjunto de dados.
Para uma interrupção de software, você espera por uma reinicialização. Mas, quando um data center é fisicamente danificado, a recuperação leva semanas. A única estratégia viável é já ter uma réplica ativa, indexada e pronta para consultas servindo a partir de outra região — com redirecionamento de tráfego que exige zero alterações de código.
Zilliz Cloud: O primeiro banco de dados vetorial do mundo com recuperação de desastres nativa entre regiões
O Zilliz Cloud é o primeiro banco de dados vetorial do mundo a oferecer recuperação de desastres nativa entre regiões — com failover automatizado, replicação em tempo real e um endpoint global que exige zero alterações na aplicação durante transições de região.
Fornecemos dois recursos complementares: Global Cluster para failover em tempo real e Cross-Region Backup para recuperação de desastres econômica.
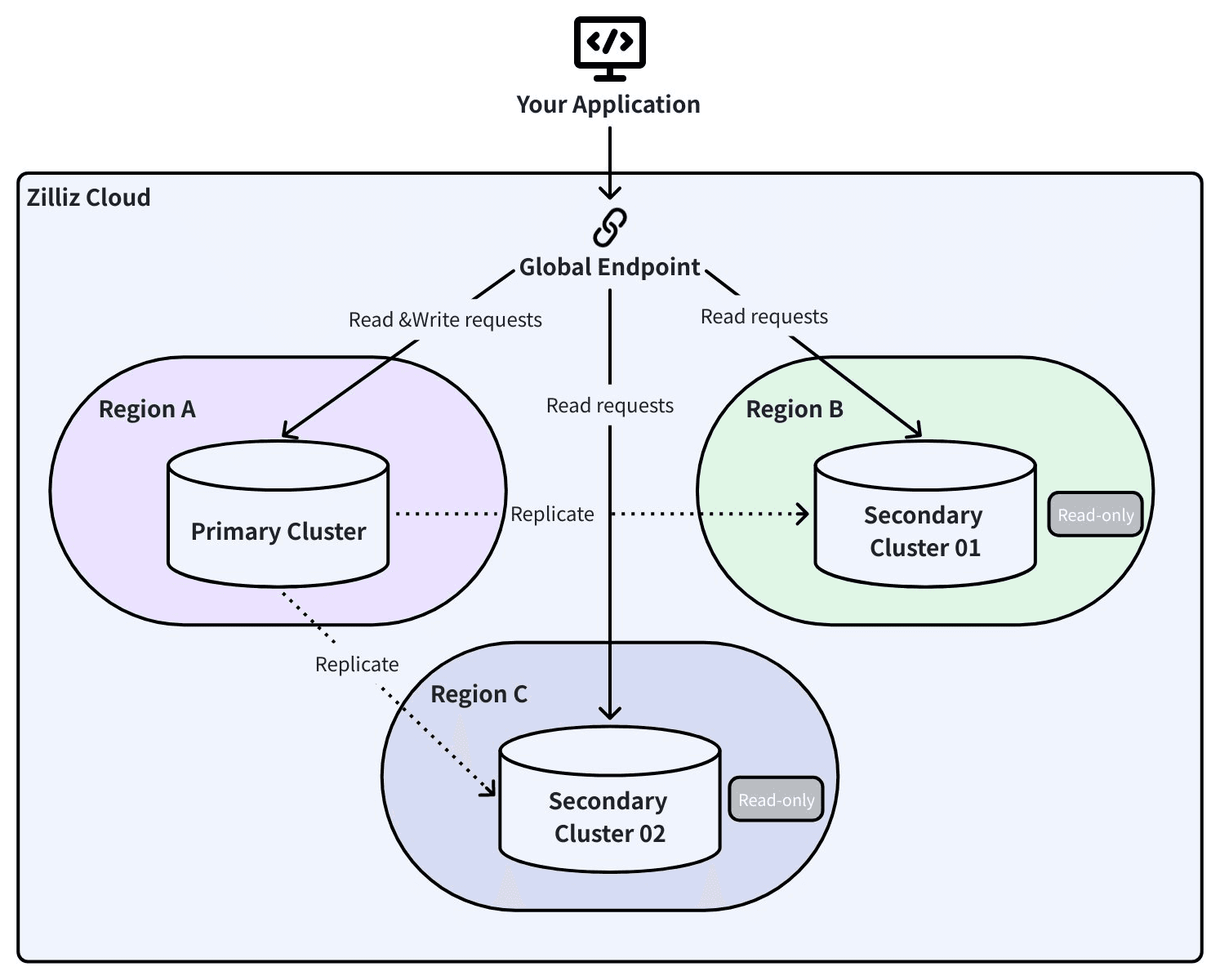
Global Cluster: Replicação ativa com failover automático
O Global Cluster usa Change Data Capture (CDC) para replicar dados continuamente entre um cluster primário e um secundário em uma região diferente. Não são snapshots periódicos — cada inserção, atualização e exclusão se propaga em tempo real.
- Switchover planejado (manutenção, migração, conformidade): O sistema esvazia as mensagens CDC em trânsito, confirma a sincronização completa e, então, troca as funções. O RPO é zero. O RTO é inferior a 30 segundos.
- Failover automático (falha regional inesperada): O secundário se promove automaticamente. O RPO equivale ao atraso do CDC no momento da falha — normalmente alguns segundos. O RTO é inferior a 60 segundos.
Um recurso exclusivo: após um failover, o primário antigo não simplesmente desaparece. Ele vai para uma lixeira com retenção de 7 dias, e uma API de streaming chamada DumpMessages permite que você recupere quaisquer gravações que tenham chegado ao primário antigo, mas ainda não tivessem sido replicadas. Em vez de aceitar a perda de dados, você ganha uma janela para recuperá-los.
Global Endpoint: Uma conexão, todas as regiões
É aqui que a arquitetura compensa em um cenário de desastre físico.
Sua aplicação se conecta a um único endpoint global. Por trás dele, registros DNS SRV rastreiam qual cluster é primário e qual é secundário. Quando ocorre um failover, o SDK detecta a mudança de topologia e redireciona o tráfego automaticamente. Sem atualizações de string de conexão. Sem reinicializações da aplicação. Sem alterações de código.
Pense no que isso significa durante uma interrupção regional prolongada. Sem um endpoint global, a recuperação exige que alguém encontre um runbook, reconfigure clientes manualmente, atualize strings de conexão e coordene entre equipes — às 3 da manhã, sob pressão. Seu RTO não é medido em segundos; é medido em quanto tempo leva para acionar o engenheiro certo.
Com o Global Endpoint, seu pipeline RAG consulta a réplica em outra região em até 60 segundos, sem alterar uma única linha de código.
Cross-Region Backup: Resiliência sem o custo de uma réplica ativa
Nem toda carga de trabalho justifica executar um cluster secundário. O Cross-Region Backup replica dados de backup para uma ou mais regiões de destino, cada uma com sua própria política de retenção. Quando ocorre uma falha em nível regional, você ativa um novo cluster a partir de qualquer ponto de backup na região de destino — sem necessidade de transferência de dados entre regiões durante a crise, porque os dados já estão lá.
A compensação:
- Global Cluster → RPO em segundos, RTO inferior a 60 segundos. Para cargas de trabalho que não podem tolerar nenhuma indisponibilidade.
- Cross-Region Backup → RPO e RTO em horas. Para cargas de trabalho em que a sobrevivência dos dados é mais importante do que a recuperação instantânea.
Muitas equipes começam com o Cross-Region Backup pela garantia crítica — seus dados sobrevivem a uma falha regional — e fazem upgrade para o Global Cluster à medida que suas cargas de trabalho de IA se tornam essenciais para a missão.
Como outros bancos de dados vetoriais lidam com DR entre regiões
A maioria dos bancos de dados vetoriais oferece alta disponibilidade dentro de uma única região por meio de conjuntos de réplicas e redundância de nós. Isso lida com falhas de nós — não com falhas de região. O Zilliz Cloud é o único banco de dados vetorial que oferece failover automatizado nativo entre regiões com um cluster global e endpoint global — transições de região sem tempo de inatividade e sem alterações de código.
| Capacidade | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| Replicação entre regiões | ✅ Baseada em CDC, em tempo real | ❌ | ❌ | ❌ | ❌ |
| Failover não planejado | ✅ RPO ≈ segundos, RTO<= 30s | ❌ | ❌ | ❌ | ❌ |
| Switchover planejado | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| Salvamento de dados pós-failover | ✅ Salvamento automático dos dados que não foram sincronizados. | ❌ | ❌ | ❌ | ❌ |
| Endpoint Global | ✅ Um endpoint Global, redirecionamento automático sem alterações de código | ❌ | ❌ | ❌ | ❌ |
| Falha regional RPO/RTO | ✅ RPO ≈ segundos, RTO < 30s | ❌ | ❌ | ❌ | ❌ |
| Backup automático entre regiões | ✅ QUALQUER região com retenção por região | ❌ | ❌ | ❌ | ❌ |
Além da Recuperação de Desastres
As equipes também usam o Global Cluster para cenários operacionais que não têm nada a ver com interrupções:
- Otimização de latência: Adicione uma região secundária mais próxima dos seus usuários para tempos de resposta de consulta abaixo de 100 ms.
- Migração de região: Mova cargas de trabalho entre regiões sem tempo de inatividade durante a consolidação da infraestrutura.
- Conformidade com residência de dados: Mantenha os dados dentro de limites geográficos específicos para atender aos requisitos regulatórios.
O mesmo pipeline de CDC que protege contra interrupções também oferece uma réplica com capacidade de leitura mais próxima dos seus usuários — capacidade de DR como efeito colateral da otimização de desempenho.
Como Começar
Global Cluster e Cross-Region Backup estão disponíveis no Zilliz Cloud para clusters dedicados.
- Se você já tem uma conta do Zilliz Cloud, basta entrar e começar a usar os novos recursos imediatamente—sem necessidade de upgrades ou migrações.
- Novo no Zilliz Cloud? Cadastre-se gratuitamente e ganhe \$100 em créditos para experimentar o banco de dados vetorial gerenciado líder mundial.
- Tem dúvidas sobre alguma das atualizações? Confira a documentação mais recente ou entre em contato com o Suporte da Zilliz—estamos aqui para ajudar.
Crie Sem Limites: Uma Análise Mais Detalhada dos Recursos Prontos para Empresas do Zilliz Cloud
O Global Cluster é uma parte de uma plataforma mais ampla criada para IA em escala de produção. O Zilliz Cloud também oferece:
- Escalabilidade elástica e eficiência de custos – Implantação com um clique, autoscaling serverless e preços pay-as-you-go.
- Busca avançada com IA – Busca vetorial, de texto completo e híbrida (esparsa + densa) com filtragem por metadados, esquema dinâmico e multilocação.
- Segurança de nível empresarial – SLA de 99,95%, certificações SOC 2 Type II e ISO 27001, conformidade com GDPR, preparação para HIPAA, RBAC, BYOC e logs de auditoria. Veja nosso trust center para saber mais.
- Disponibilidade global – Implantações na AWS, GCP e Azure com latência abaixo de 100 ms em todo o mundo.
- Migração perfeita – Ferramentas integradas para migrar de Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate ou Milvus on-prem.
- Consultas em linguagem natural – Suporte a servidor MCP para consultas intuitivas sem APIs complexas.
- E muito mais!

Continue lendo

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.