




대규모 텍스트 임베딩 벤치마크(MTEB)
대규모 텍스트 임베딩 벤치마크(MTEB)
텍스트 임베딩은 종종 단 하나의 작업에서 나온 소수의 데이터셋으로만 테스트되는데, 이는 다른 작업에서 얼마나 잘 작동하는지 보여주지 못합니다. Semantic Textual Similarity(STS)에 가장 적합한 임베딩이 클러스터링이나 리랭킹 같은 작업에도 똑같이 잘 작동하는지는 명확하지 않습니다. 이 때문에 새로운 모델과 임베딩이 일관된 테스트 없이 흔히 평가되고 계속 제안되므로, 이 분야의 발전을 파악하기 어렵습니다.
이 문제를 해결하기 위해 연구자들은 대규모 텍스트 임베딩 벤치마크(Massive Text Embedding Benchmark, MTEB)를 만들었습니다. MTEB는 112개 언어의 58개 데이터셋에 걸쳐 8가지 임베딩 작업을 다룹니다. 연구자들은 MTEB에서 33개 모델을 대상으로 8가지 임베딩 작업을 테스트하여, 지금까지 텍스트 임베딩을 위한 가장 완전한 벤치마크로 만들었습니다.
그들은 모든 작업에서 가장 뛰어난 단일 임베딩 방법은 없다는 것을 발견했습니다. 이는 규모를 키우더라도 모든 임베딩 작업에서 가장 잘 작동하는 범용 텍스트 임베딩 방법이 아직 개발되지 않았음을 시사합니다. 또한 요구 사항에 가장 잘 맞는 임베딩 모델을 선택하기 위해 충분한 사전 검토를 수행하는 것이 중요하다는 점도 강조합니다.
MTEB는 오픈 소스 코드, 공개 리더보드, 그리고 어떤 모델이 더 나은 문서를 검색하는지, 더 나은 클러스터링을 수행하는지 등에 투표할 수 있는 재미있는 MTEB Arena를 제공하며, 둘 다 Hugging Face 웹사이트에 있습니다. 이 벤치마크는 커뮤니티가 새로운 방법을 일관되게 테스트하고 텍스트 임베딩 기술의 개선을 추적하는 데 도움이 될 것입니다.
배경과 동기
텍스트 임베딩은 많은 Natural Language Processing(NLP) 작업의 핵심 요소가 되었습니다. 이러한 임베딩은 단어, 문장 또는 문서를 그 의미를 포착하는 숫자 표현으로 변환합니다. 기계 번역, 개체명 인식, 질의응답, 감성 분석, 요약과 같은 다양한 애플리케이션에서 사용됩니다.
수년 동안 연구자들은 이러한 임베딩을 테스트하기 위해 많은 데이터셋과 벤치마크를 만들어 왔습니다. 잘 알려진 예로는 SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353, SimLex-999 등이 있습니다. 이들은 일반적으로 표준 및 문맥 기반 단어 임베딩을 평가하는 데 초점을 맞춥니다.
하지만 텍스트 임베딩을 평가하는 방식에는 여전히 몇 가지 공백이 있습니다:
단어 임베딩과 문장 임베딩을 모두 다루는 벤치마크는 거의 없습니다.
많은 평가는 임베딩이 텍스트의 전반적인 의미를 얼마나 잘 포착하는지가 아니라 특정 NLP 작업에 초점을 맞춥니다.
기존 벤치마크는 실제 애플리케이션에서 임베딩이 어떻게 사용될 수 있는지를 고려하지 않는 경우가 많습니다.
광범위한 텍스트 이해 작업을 평가할 수 있는 포괄적인 벤치마크가 필요합니다. 이 벤치마크는 NLP 연구자와 실용적인 애플리케이션을 개발하는 사람들 모두에게 유용해야 합니다. 대규모 텍스트 임베딩 벤치마크(MTEB)는 이러한 공백을 메우는 것을 목표로 합니다.
텍스트 임베딩
텍스트 임베딩은 텍스트를 숫자 목록으로 표현하는 방법입니다. 이러한 숫자는 하나의 단어, 하나의 문장, 또는 전체 문서를 나타낼 수 있습니다. 목록은 보통 수백 개의 숫자로 구성됩니다.
텍스트 임베딩은 많은 NLP 작업에서 사용됩니다. 단어의 경우 맞춤법 검사나 단어 관계 찾기 같은 것에 사용됩니다. 더 긴 텍스트의 경우 글의 감성을 파악하거나 새로운 텍스트를 생성하는 등의 작업에 사용됩니다.
텍스트 임베딩을 만드는 방법은 다양합니다. 인기 있는 방법으로는 다음이 있습니다:
ELMo와 같이 다양한 NLP 작업으로 학습된 방법
컴퓨터 비전 연구에서 자주 사용되는 word2vec 및 GloVe와 같은 단어 기반 방법
연구자들은 다양한 임베딩을 많이 만들어 왔으며, 비교할 수 있는 것만 해도 최소 165개가 있습니다. 또한 이러한 임베딩의 강점과 약점을 이해하는 데 도움이 되도록 15가지 다른 도구(예: 의사결정 트리 및 Random Forests)도 만들었습니다.
하지만 이러한 다양한 임베딩을 모두 비교할 수 있는 표준 방법은 없습니다. 이것이 Massive Text Embedding Benchmark (MTEB)가 해결하려는 문제입니다.
Massive Text Embedding Benchmark의 설계 및 구현
MTEB는 몇 가지 중요한 목표를 염두에 두고 설계되었습니다:
다양성: MTEB는 다양한 작업에서 임베딩 모델을 테스트합니다. 8가지 작업 유형이 포함되어 있으며, 각 유형마다 최대 15개의 데이터셋이 있습니다. 총 58개의 데이터셋 중 10개는 여러 언어를 지원하며, 전체적으로 112개 언어를 다룹니다. 이 벤치마크는 짧은 텍스트(문장 수준)와 긴 텍스트(문단 수준)를 모두 테스트하여 모델이 서로 다른 텍스트 길이에서 어떻게 수행되는지 확인합니다.
단순성: MTEB는 사용하기 쉽습니다. 텍스트 목록을 받아 숫자 표현(벡터) 목록을 생성할 수 있는 어떤 모델이든 테스트할 수 있습니다. 이는 다양한 유형의 모델을 비교할 수 있다는 뜻입니다.
확장성: MTEB에 새 데이터셋을 추가하는 것은 쉽습니다. 기존 작업의 경우 작업을 설명하고 Hugging Face에 데이터가 저장된 위치를 가리키는 파일만 추가하면 됩니다. 새로운 유형의 작업을 추가하려면 조금 더 작업이 필요하지만, MTEB는 성장에 도움이 되는 커뮤니티의 기여를 환영합니다.
재현성: MTEB는 실험을 반복하기 쉽게 만듭니다. 데이터셋과 소프트웨어의 다양한 버전을 추적합니다. MTEB 논문의 결과는 JSON 파일로 제공되므로 누구나 확인하거나 사용할 수 있습니다.
이러한 특징 덕분에 MTEB는 총체적으로 광범위한 작업과 언어를 포괄하는 작업 전반에서 text embedding models를 평가하기 위한 포괄적이고 유연한 도구가 됩니다.
Massive Text Embedding Benchmark의 작업 및 평가
Massive Text Embedding Benchmark에는 임베딩 모델을 테스트하기 위한 8가지 작업 유형이 포함되어 있습니다. 각 작업을 간단히 정리하면 다음과 같습니다:
Bitext Mining: 두 가지 다른 언어에서 일치하는 문장을 찾습니다. 주요 측정 지표는 F1 점수입니다.
Classification: 임베딩을 사용하여 텍스트를 범주로 분류합니다. 주요 측정 지표는 정확도입니다.
Clustering: 유사한 텍스트를 함께 그룹화합니다. 주요 측정 지표는 v-measure입니다.
Pair Classification: 두 텍스트가 유사한지 아닌지 결정합니다. 주요 측정 지표는 average precision입니다.
Reranking: 쿼리와 얼마나 잘 일치하는지에 따라 텍스트 목록의 순서를 정합니다. 주요 측정 지표는 MAP (Mean Average Precision)입니다.
Retrieval: 주어진 쿼리에 대해 관련 문서를 찾습니다. 주요 측정 지표는 nDCG@10입니다.
Semantic Textual Similarity (STS): 두 문장이 얼마나 유사한지 측정합니다. 주요 측정 지표는 Spearman correlation입니다.
Summarization: 기계가 생성한 요약을 사람이 작성한 요약과 비교해 점수를 매깁니다. 주요 측정 지표 역시 Spearman correlation입니다.
각 작업에서 MTEB는 임베딩 모델을 사용해 텍스트를 벡터 임베딩으로 변환합니다. 그런 다음 코사인 유사도나 로지스틱 회귀와 같은 방법을 사용해 작업을 수행하고 점수를 계산합니다.
MTEB에는 각 작업에 대해 다양한 언어와 텍스트 길이를 포괄하는 많은 데이터셋이 포함되어 있습니다. 이는 임베딩 모델이 다양한 상황에서 얼마나 잘 작동하는지 테스트하는 데 도움이 됩니다.
이러한 다양한 작업과 데이터셋을 사용함으로써 Massive Text Embedding Benchmark는 서로 다른 텍스트 임베딩 모델을 평가하고 비교할 수 있는 종합적인 방법을 제공합니다.
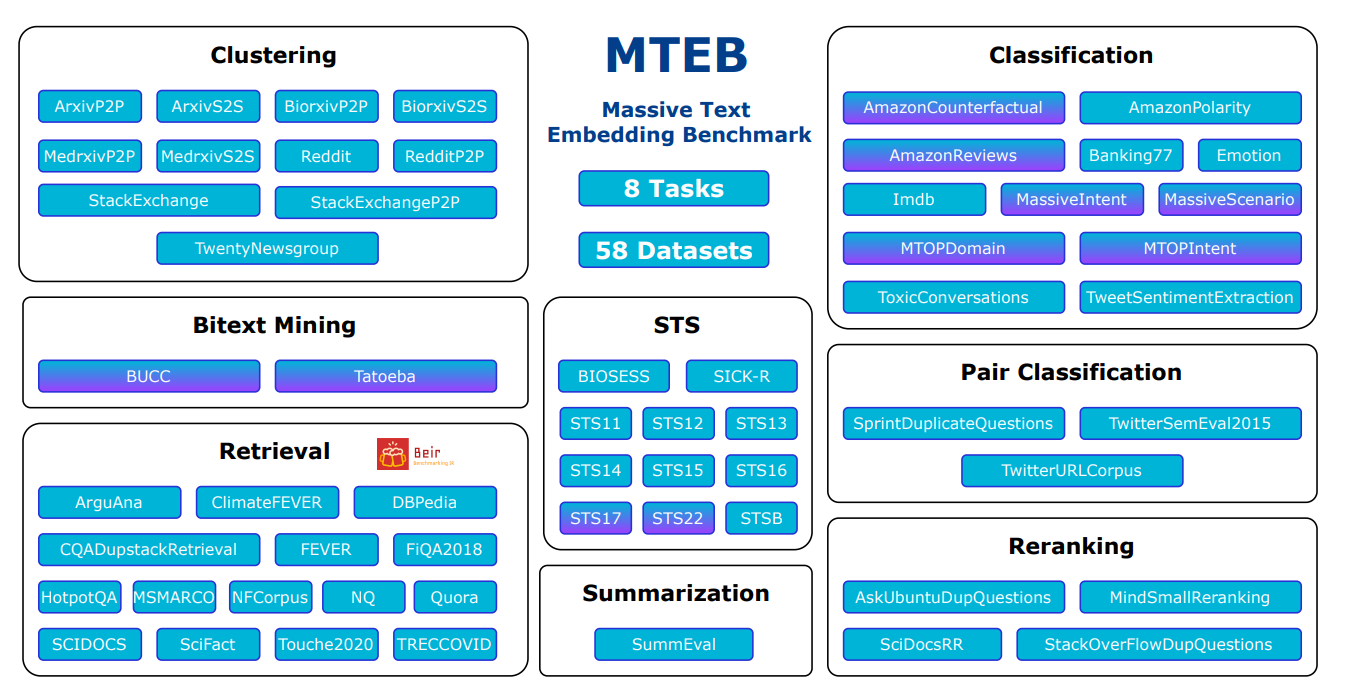 MTEB의 작업 및 데이터셋 개요
MTEB의 작업 및 데이터셋 개요
출처: MTEB: Massive Text Embedding Benchmark
Massive Text Embedding Benchmark의 데이터셋
Massive Text Embedding Benchmark는 특정 텍스트 임베딩 방법과 모델을 테스트하기 위해 다양한 데이터셋을 사용합니다. 이러한 데이터셋은 비교되는 텍스트의 길이에 따라 세 가지 주요 유형으로 분류됩니다:
Sentence to Sentence (S2S): 한 문장을 다른 문장과 비교하는 경우입니다. 예를 들어 Semantic Textual Similarity 작업에서는 두 문장이 얼마나 유사한지 파악하는 것이 목표입니다.
Paragraph to Paragraph (P2P): 더 긴 텍스트 조각을 비교하는 작업입니다. MTEB는 이 길이에 제한을 두지 않으며, 필요한 경우 모델이 더 긴 텍스트를 처리하도록 맡깁니다. 클러스터링과 같은 일부 작업은 S2S(제목만 비교)와 P2P(제목과 내용 비교) 모두로 수행됩니다.
Sentence to Paragraph (S2P): 일부 검색 작업에서 사용되며, 짧은 쿼리(문장)를 더 긴 문서(문단)와 비교합니다.
MTEB에는 56개의 서로 다른 데이터셋이 포함되어 있습니다. 이 데이터셋 중 일부는 서로 유사합니다:
일부는 동일한 기본 텍스트 데이터(예: ClimateFEVER 및 FEVER)를 사용합니다.
유사한 작업을 위한 데이터셋(예: CQADupstack 또는 STS의 서로 다른 버전)은 서로 비슷한 경향이 있습니다.
동일한 데이터셋의 S2S 및 P2P 버전은 종종 유사합니다.
유사한 주제(예: 과학 논문)에 관한 데이터셋은 서로 다른 작업을 위한 것이라도 비슷한 경향이 있습니다.
이처럼 폭넓은 데이터셋을 사용함으로써 MTEB는 임베딩 모델이 다양한 유형의 텍스트와 다양한 작업에서 얼마나 잘 작동하는지 테스트할 수 있습니다. 이는 각 모델의 강점과 약점을 더 완전하게 파악하는 데 도움이 됩니다.
Massive Text Embedding Benchmark의 초기 벤치마킹에 사용된 모델
MTEB를 사용한 첫 번째 테스트 라운드에서 연구자들은 최고라고 주장하는 모델과 Hugging Face Hub에서 인기 있는 모델을 살펴보았습니다. 이는 많은 transformer models를 테스트했다는 의미입니다. 연구자들은 사람들이 필요에 가장 적합한 모델을 선택할 수 있도록 모델을 세 가지 유형으로 분류했습니다:
가장 빠른 모델: Glove와 같은 모델은 매우 빠르지만 문맥을 잘 이해하지 못합니다. 이는 MTEB 전체에서 높은 점수를 받지 못한다는 의미입니다.
균형 잡힌 모델: all-mpnet-base-v2 또는 all-MiniLM-L6-v2와 같은 모델은 가장 빠른 모델보다 약간 느리지만 성능이 훨씬 뛰어납니다. 속도와 품질의 좋은 조합을 제공합니다.
최고 성능 모델: ST5-XXL, GTR-XXL 또는 SGPT-5.8B-msmarco와 같이 수십억 개의 매개변수를 가진 대형 모델은 MTEB에서 가장 좋은 성능을 보입니다. 하지만 더 느릴 수 있고 더 많은 저장 공간이 필요합니다. 예를 들어 SGPT-5.8B-msmarco는 4096개의 숫자로 이루어진 임베딩을 생성하므로 더 많은 공간을 차지합니다.
모델의 성능은 특정 작업과 데이터셋에 따라 크게 달라질 수 있다는 점에 유의해야 합니다. 연구자들은 단일 작업과 특정 요구 사항에 가장 적합한 모델을 확인하기 위해 MTEB leaderboard를 확인할 것을 제안합니다.
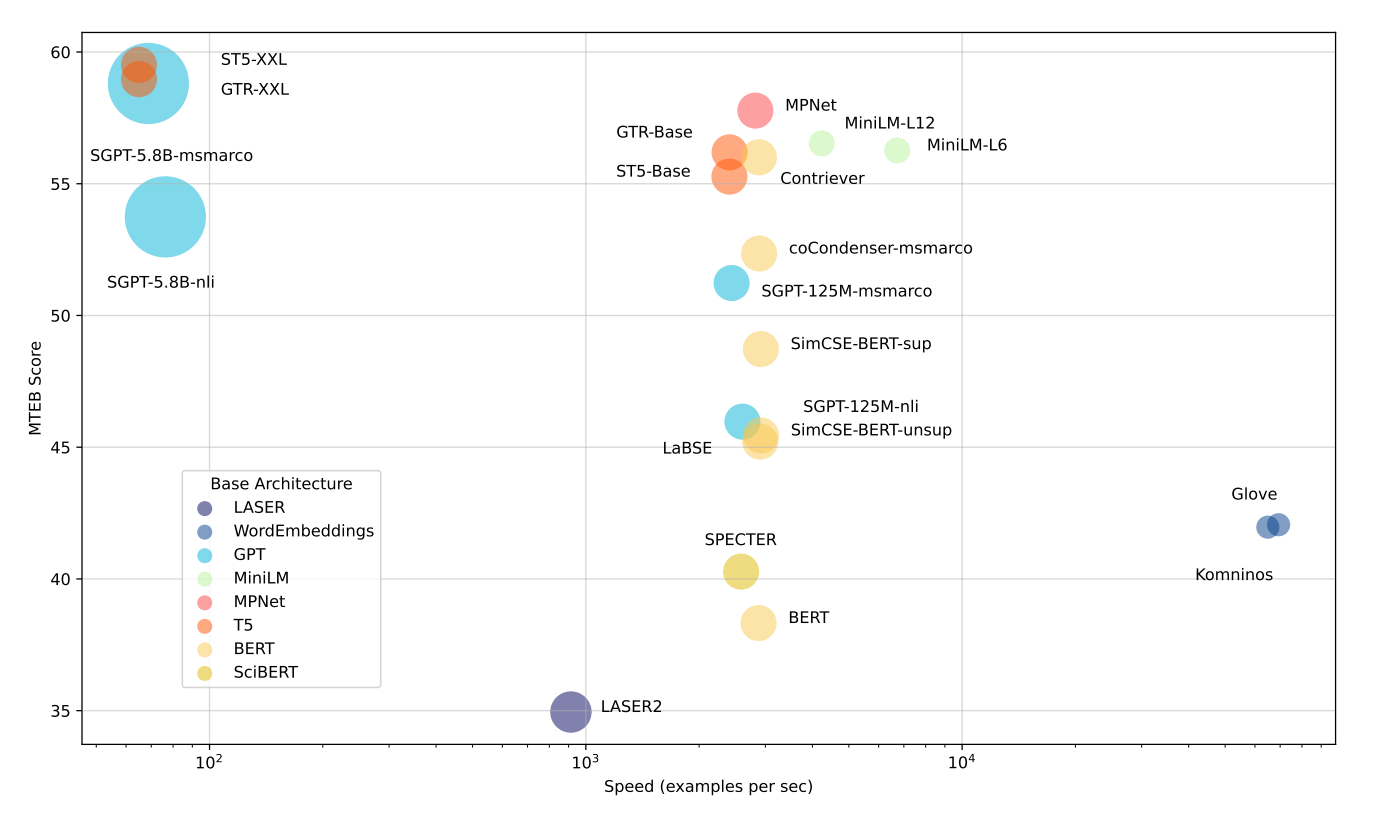 초기 테스트 벤치마크 결과
초기 테스트 벤치마크 결과
출처: MTEB: Massive Text Embedding Benchmark
이러한 테스트 접근 방식은 다양한 임베딩 모델에서 속도와 성능 간의 절충점을 명확하게 보여 주어, 사용자가 자신의 구체적인 요구 사항에 따라 정보에 기반한 결정을 내리는 데 도움을 줍니다. 직접 시도해 보고 싶다면, 벡터 임베딩을 생성하는 모든 모델을 벤치마킹하는 방법을 안내하는 Huggigng Face의 훌륭한 블로그가 있습니다.
Massive Text Embedding Benchmark를 사용해야 하는 경우
MTEB는 텍스트 임베딩 모델이 여러 다양한 작업에서 얼마나 잘 작동하는지 테스트하기 위한 도구입니다. 다음과 같은 여러 상황에서 유용합니다:
모델 테스트: 새로운 임베딩 모델을 만들었다면, MTEB를 사용해 다른 모델과 비교해 볼 수 있습니다. 결과를 공개 리더보드에 추가할 수 있으며, 이를 통해 자신의 모델이 다른 모델들과 비교해 어느 정도 수준인지 확인하는 데 도움이 됩니다.
적절한 모델 선택: 서로 다른 모델은 서로 다른 작업에 더 잘 작동합니다. MTEB의 리더보드는 다양한 작업에서 모델이 어떻게 성능을 내는지 보여 주어, 특정 요구 사항에 가장 적합한 모델을 선택하는 데 도움을 줍니다.
MTEB 개선 지원: MTEB는 오픈 소스이므로 누구나 기여할 수 있습니다. 새로운 작업, 데이터셋, 성능 측정 방법 또는 모델을 만들었다면 MTEB에 추가할 수 있습니다. 이는 벤치마크를 더욱 개선하는 데 도움이 됩니다.
연구: 텍스트 임베딩을 연구하고 있다면, MTEB는 모델을 철저하게 테스트할 수 있는 방법을 제공합니다. 현재 최고의 모델들이 무엇을 할 수 있는지, 그리고 개선의 여지가 어디에 있는지 보여 줄 수 있습니다.
여러 작업에서 모델을 테스트하는 표준 방식을 제공함으로써, MTEB는 연구자와 개발자가 텍스트 임베딩 기술을 이해하고 개선하는 데 도움을 줍니다. 텍스트 임베딩을 다루거나 연구하는 모든 사람에게 가치 있는 도구입니다.
Massive Text Embedding Benchmark 리더보드 사용 방법
무엇보다도, MTEB 점수에 현혹되지 마세요!
MTEB는 유용한 도구이지만, 그 한계를 이해하는 것이 중요합니다. 점수를 보여 주기는 하지만, 점수 간 차이가 의미 있는지 여부는 알려 주지 않습니다. 많은 상위 모델들은 매우 근접한 평균 점수를 가지고 있으며, 이러한 점수는 여러 다양한 작업에서 나온 것이지만, 이 점수들이 얼마나 변동하는지에 대한 정보는 없습니다. 최상위 모델이 더 좋아 보일 수 있지만, 그 차이가 중요하지 않을 수도 있습니다. 사용자는 원시 결과를 가져와 직접 확인할 수 있습니다. 일부 연구자들은 특정 언어 벤치마크에서 여러 상위 모델이 통계적으로 말해 실제로는 동등하게 우수하다는 사실을 발견했습니다. 단순히 평균 점수만 보는 대신, 의도한 사용 사례와 유사한 작업에서 모델이 어떻게 성능을 내는지에 집중하는 것이 더 좋습니다. 이는 전체 점수보다 특정 애플리케이션에서 모델이 어떻게 작동할지에 대해 더 많은 통찰을 제공할 수 있습니다. 데이터셋을 자세히 연구할 필요는 없지만, 어떤 종류의 텍스트가 포함되어 있는지 아는 것은 유익합니다. 이 정보는 일반적으로 데이터셋 설명과 몇 가지 예시를 간단히 살펴보면 확인할 수 있습니다. Massive Text Embedding Benchmark는 유용한 도구이지만 완벽하지는 않습니다. 결과에 대해 비판적으로 생각하고, 그것이 구체적인 요구 사항에 어떻게 적용되는지 고려하는 것이 중요합니다. 단순히 전체 점수가 가장 높은 모델을 선택하기보다는, 당면한 작업에 가장 적합한 모델을 찾기 위해 더 깊이 살펴보는 것이 좋습니다.
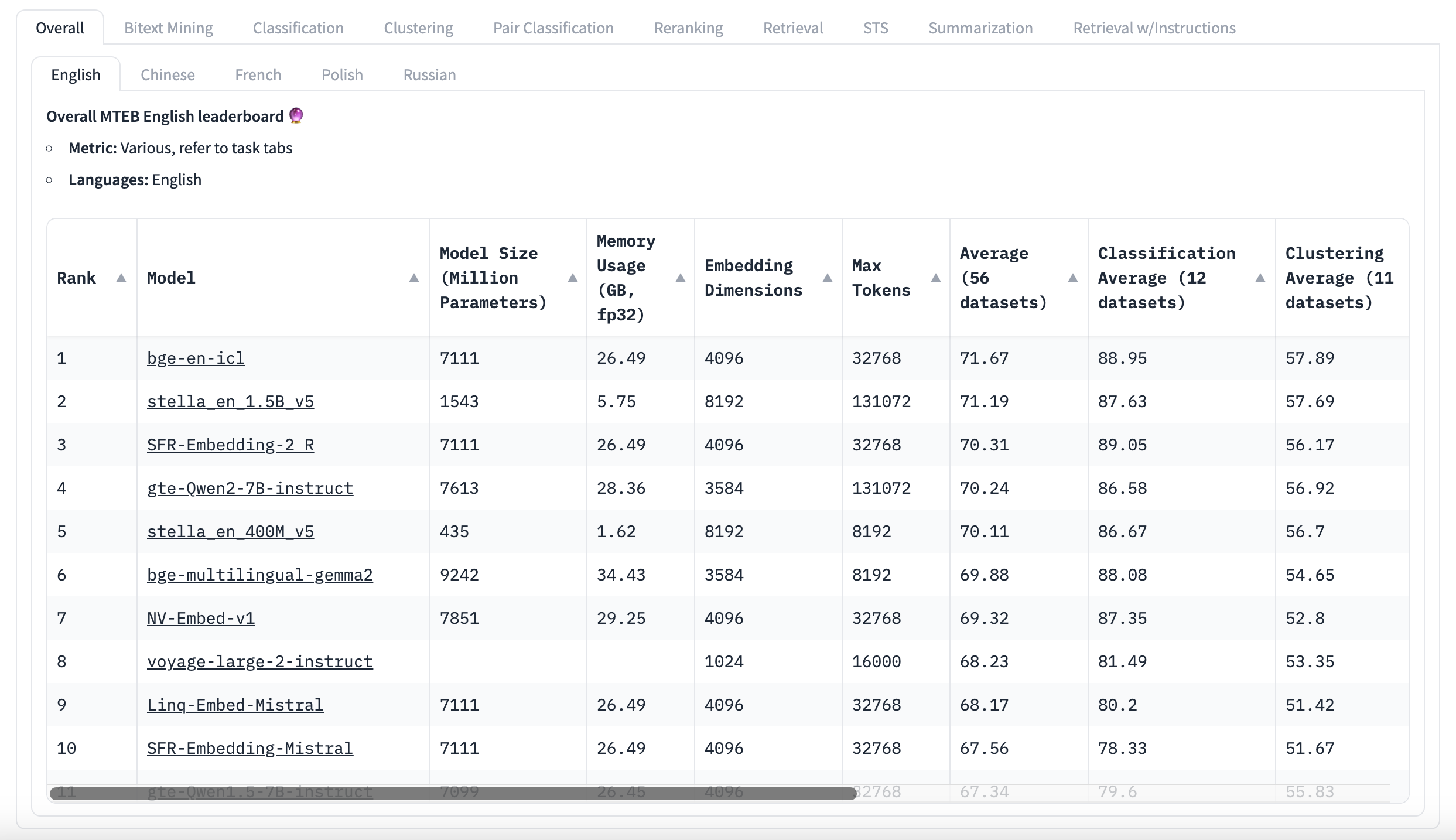 MTEB Leaderboard English
MTEB Leaderboard English
애플리케이션의 요구 사항을 고려하는 것을 잊지 마세요
모든 작업에 맞는 만능 모델은 없습니다. 바로 이것이 Massive Text Embedding Benchmark가 존재하는 이유입니다 - 특정 요구 사항에 맞는 적절한 모델을 선택하도록 돕기 위해서입니다. Massive Text Embedding Benchmark 리더보드를 볼 때는 애플리케이션이 무엇을 요구하는지 생각하는 것이 중요합니다. 고려해야 할 몇 가지 사항은 다음과 같습니다:
언어: 모델이 작업 중인 언어를 지원하나요?
전문 어휘: 금융 또는 법률 텍스트를 다룬다면, 해당 분야의 특정 용어를 이해하는 모델이 필요합니다.
모델 크기: 모델을 어디에서 실행할지 생각해 보세요. 노트북에 들어갈 수 있어야 할까요?
메모리 사용량: 모델에 할당할 수 있는 컴퓨터 메모리는 얼마나 되나요?
최대 입력 길이: 작업할 텍스트의 길이는 얼마나 되나요?
작업에 무엇이 중요한지 알게 되면, 이러한 기능을 기준으로 MTEB 리더보드에서 다양한 모델을 정렬할 수 있습니다. 이를 통해 성능이 좋을 뿐만 아니라 실제 요구 사항에도 맞는 모델을 더 쉽게 찾을 수 있습니다.
성능과 실제 필요 사항을 모두 고려하면, 특정 상황에 가장 적합한 모델을 선택할 수 있습니다.
Zilliz AI Model 리소스
이제 Massive Text Embedding Benchmark에서 텍스트 임베딩 모델을 선택했으니, 이를 활용하여 오픈 소스 Milvus 또는 Zilliz Cloud에 저장하고 검색할 텍스트 임베딩을 생성해 보겠습니다. Zilliz 웹사이트에서 더 인기 있는 멀티모달 및 텍스트 임베딩 모델 중 일부를 나열한 AI Models 페이지를 찾을 수 있습니다.
 Zilliz AI Model 페이지
Zilliz AI Model 페이지
이 페이지에서 모델을 선택하면, 다양한 SDK, PyMilvus 등을 사용하여 벡터 임베딩을 생성하는 방법에 대한 몇 가지 자세한 지침을 볼 수 있습니다.
결론
Massive Text Embedding Benchmark (MTEB)는 텍스트 임베딩 모델 평가에서 중요한 진전입니다. 다양한 작업, 언어, 텍스트 길이를 포괄함으로써 기존 벤치마크의 한계를 해결합니다. MTEB의 설계는 다양성, 단순성, 확장성, 재현성에 중점을 두어 자연어 처리 분야의 연구자와 실무자 모두에게 유용한 도구가 됩니다.
MTEB의 가장 포괄적인 벤치마크 접근 방식은 8가지 서로 다른 작업과 58개 데이터셋에서 모델을 테스트하여, 이전 벤치마크보다 모델의 역량에 대한 더 완전한 그림을 제공합니다. 이는 모든 작업에서 뛰어난 단일 임베딩 방법은 없다는 것을 보여 주며, 특정 애플리케이션에 적합한 모델을 선택하는 것이 중요함을 강조합니다.
MTEB를 사용할 때는 전체 점수만 보지 말고 애플리케이션의 구체적인 요구 사항을 고려하는 것이 중요합니다. 언어 지원, 전문 어휘, 모델 크기, 메모리 사용량, 최대 입력 길이와 같은 요소가 모두 의사 결정 과정에서 역할을 해야 합니다.
MTEB는 강력한 도구이지만, 비판적으로 사용하는 것이 중요합니다. 상위 모델 간 점수 차이가 항상 통계적으로 유의미하지 않을 수 있으며, 성능은 특정 작업과 데이터셋에 따라 크게 달라질 수 있습니다.
오픈 소스 프로젝트로서 MTEB는 커뮤니티의 기여를 환영하며, 이를 통해 분야의 진화하는 요구에 맞춰 성장하고 적응할 수 있습니다. 이러한 협업적 접근 방식은 MTEB가 텍스트 임베딩 기술을 평가하고 개선하는 데 계속해서 관련성 있고 가치 있는 리소스로 남도록 보장합니다.
MTEB는 다양한 작업과 언어 전반에서 텍스트 임베딩 모델을 평가하는 표준화된 방법을 제공함으로써 이 분야의 발전을 촉진하고 있으며, 궁극적으로 다양한 애플리케이션을 위한 더 우수하고 더 다재다능한 텍스트 임베딩 모델로 이어지고 있습니다.
참고 문헌
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "독일어 텍스트 임베딩 클러스터링 벤치마크" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR: 정보 검색 모델의 지시 따르기 평가 및 교육" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed: 긴 문맥 검색을 위한 임베딩 모델 확장" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "스칸디나비아 임베딩 벤치마크: 다국어 및 단일 언어 텍스트 임베딩의 포괄적 평가" arXiv 2024