




LlamaIndex
LlamaIndex Integration | Build Retrieval-Augmented Generation applications with Zilliz Cloud and Milvus Vector Database
無料でこの統合を利用しましょうLlamaIndexの統合、Zilliz Cloudで検索-拡張世代のアプリケーションを構築
LlamaIndex(旧GPT Index)は、大規模言語モデル(Large Language Models:LLM)アプリケーション用に調整されたデータフレームワークで、プライベートデータやドメイン固有データの取り込み、構造化、アクセスを容易にします。LLMは、人間の言語と推論データ(構造化データ、非構造化データ)の橋渡しをします。広く利用されているLLMは、一般に公開されている膨大なデータセットで事前に訓練されていますが、重要なデータが欠落していることが多く、その結果、LLMから生成される答えは幻覚や不正解となります。
LlamaIndex はベクトルデータベースと統合されている:
1.内部インデックスの使用法:LlamaIndexはベクトルストアを使用したインデックスとして機能します。従来のインデックスと同様に、このLlamaIndexベースのインデックスはドキュメントを保存し、クエリに効果的に応答することができます。 2.外部データ統合:LlamaIndexはベクトルストアからデータを取得することができ、従来のデータコネクターのように動作します。一度取得されたデータは、LlamaIndexのデータ構造にシームレスに統合され、さらなる処理と利用が可能です。これはしばしば Retrieval-Augmented Generated または RAG と呼ばれます。
LlamaIndexとZilliz Cloudの統合の仕組み
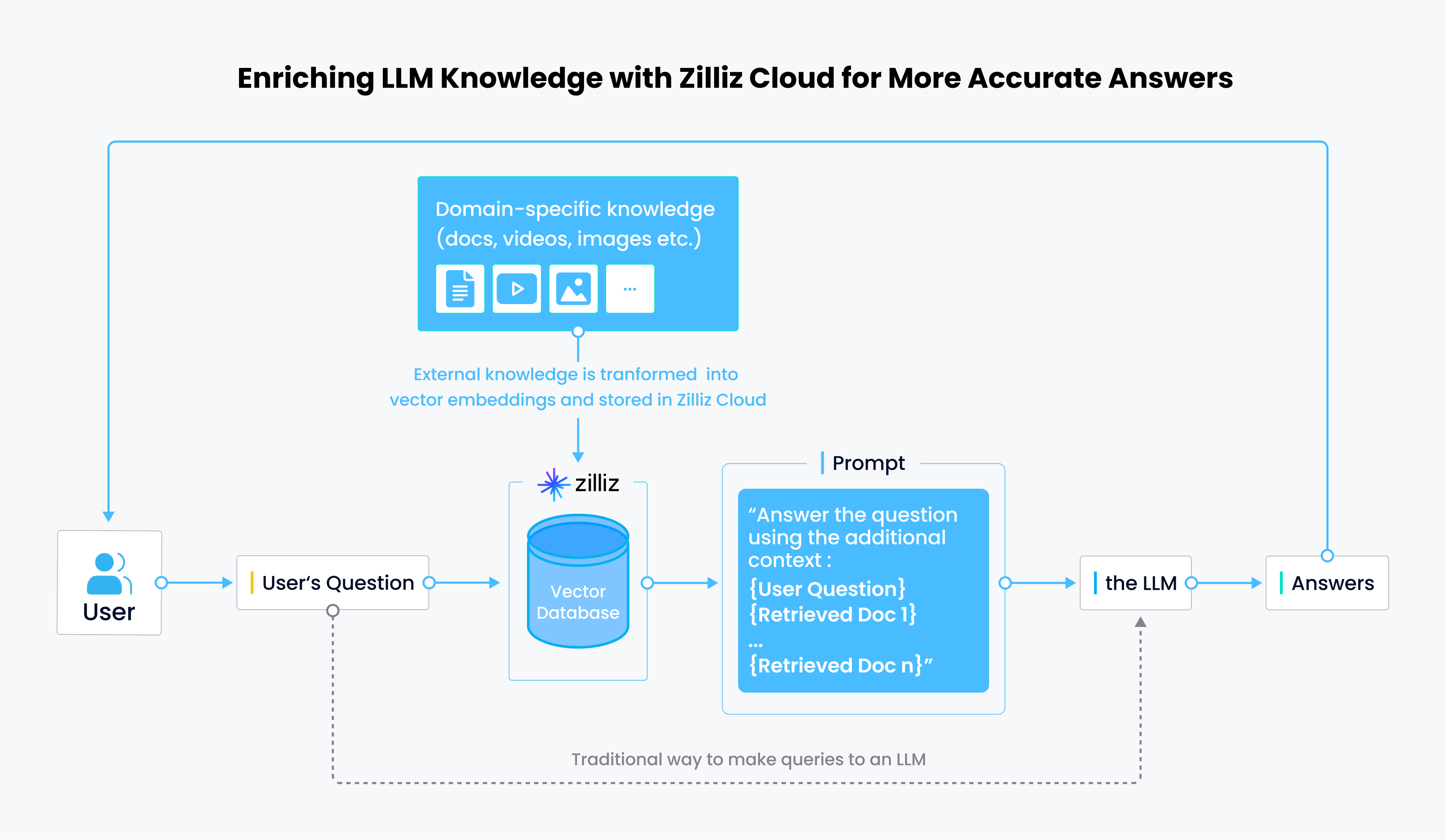
ラマの使い方についてもっと知る
- チュートリアル|LlamaIndexを始めよう**](https://zilliz.com/blog/getting-started-with-llamaindex)
- Docs | Zilliz CloudとLlamaIndexを使ったドキュメントQA
- Video Shorts with Yujian Tang | LlamaIndexによる永続的なベクトルストレージ
- LlamaIndex CEO Jerry Liu氏とのビデオ|LlamaIndexを使用したプライベートデータでLLMを向上させる
- Zillizクラウド、LlamaIndex、LangChainを使ったチャットボットの構築 パート1
- GPTCacheを使った100倍高速なレスポンスと大幅なコスト削減を実現するLLMアプリの構築