




ファズテストの説明:ソフトウェアの隠れた欠陥を発見する

TL;DR:ファズテスト(またはファジング)は、バグ、クラッシュ、脆弱性を特定するために、大量のランダムな、または予期しないデータ(「ファズ」)をプログラムに入力するソフトウェアテスト技法である。予期しない状況下でシステムがどのように動作するかを明らかにすることで、ファズテストは、従来のテストでは見逃してしまうようなエッジケース、セキュリティ上の欠陥、弱点を発見するのに役立ちます。特に、ウェブサービス、ファイル・パーサー、APIのような複雑な入力を処理するシステムにおいて、ソフトウェアの信頼性とセキュリティを向上させるために一般的に使用されている。
ファズテストの説明:ソフトウェアの隠れた欠陥を発見する
ファズテストとは?
ファズ・テスト(Fuzz testing)とは、ソフトウェア・テストの手法の一つで、プログラムに予期しない、あるいはランダムなデータを送り込み、それがどのように反応するかを見ることで、隠れたバグを発見するものです。意図的に異常な、あるいは「ファジー」な状況を引き起こすことで、このテスト技法は、特に複雑でセキュリ ティに敏感なソフトウェアにおいて、通常のテストでは見逃してしまうような脆弱性を発見します。
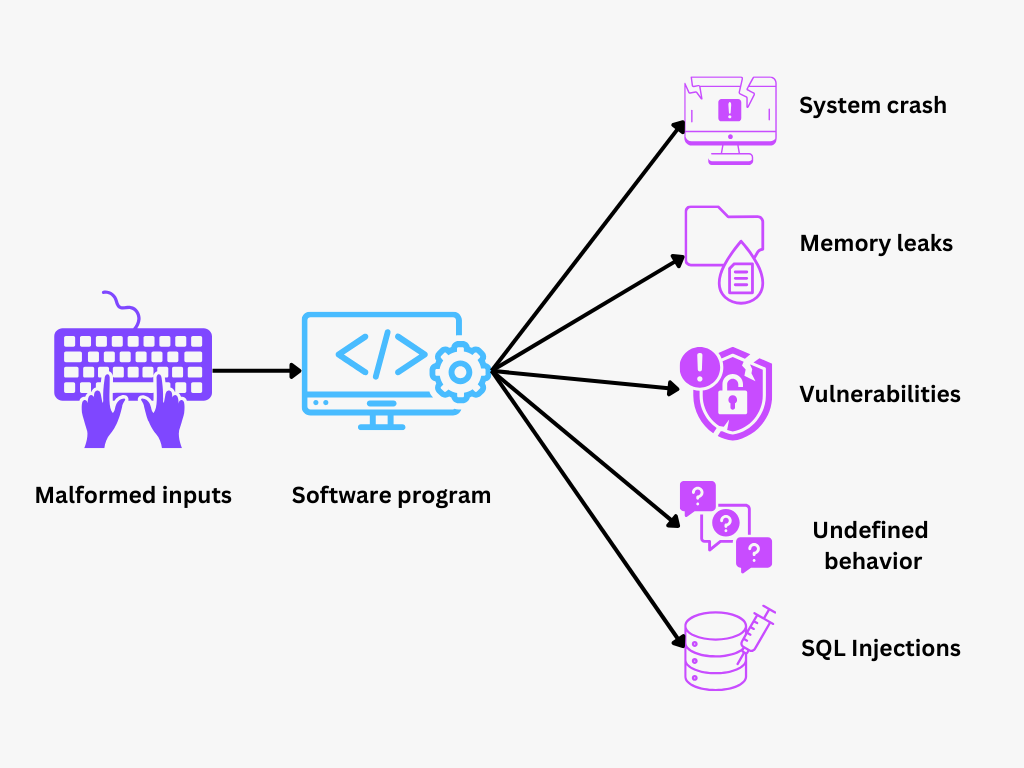 図- ファズテスト.png
図- ファズテスト.png
図:ファズ・テスト
ファズテストの歴史
ファズ・テストは1980年代後半に偶然発見されたことから始まった。ウィスコンシン大学のバートン・ミラー教授は、ネットワーク化されたコンピュータ・プログラムの実験中に、ランダムな入力ノイズによって予期せぬクラッシュが起こることに気づいた。これをきっかけに彼はさらに調査を進め、さまざまなプログラムに意図的にランダムなデータを送り込み、その反応を観察した。彼は多くのアプリケーションがこうしたランダム入力に対して脆弱であることを発見し、セキュリティ上の弱点や安定性の問題を明らかにした。ミラーの研究はファズ・テストの基礎を築き、ソフトウェアのバグや脆弱性を発見する効果的な方法として確立した。
ファズテストの仕組み
ファズテストは、ランダムな、予期しない、または無効なデータ(「ファズされた」入力)をプログラムに送り込み、その動作を評価し、潜在的なバグを発見します。このアプローチは、プログラムを予測不可能な状態に追い込み、従来のテストでは見逃されがちなバグや脆弱性を明らかにすることが多い。このアイデアは、予期せぬ入力によるストレスの下で、クラッシュしたり予期せぬ動作をしたりすることなく、健全なソフトウェアがどの程度持ちこたえられるかを確認することである。
ファズテストのフェーズ
ファズテストのプロセスは、ターゲットシステム内の問題を特定し、テストし、分析するためのステップで構成されています。
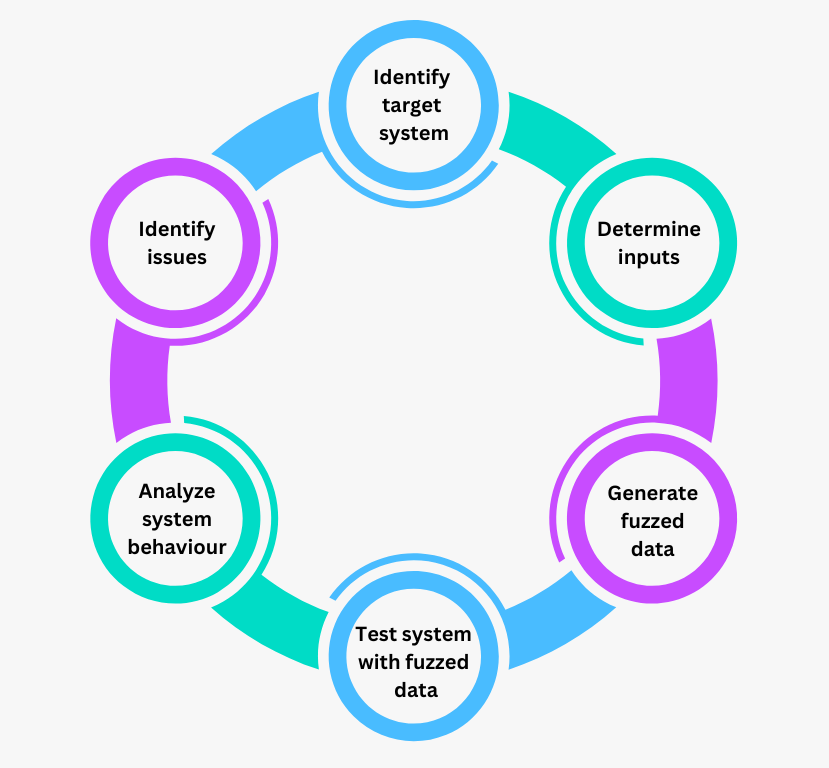 図- ファズテストのフェーズ.png
図- ファズテストのフェーズ.png
図:ファズテストのフェーズ
1.#### ターゲットシステムの特定
ファズテストの最初のステップは、テストしたいプログラムやコンポーネントを選択することです。これは、アプリケーションであったり、より広範なシステム内の関数であったり、あるいは特定の入力 フィールドであったりします。
2.#### 入力の決定
対象システムを特定したら、次のステップは、どのようなタイプの入力をテストするかを決定することである。これには、システムが通常扱うデータ形式や入力タイプを理解することが必要である。例えば、ターゲットシステムがネットワークパケットを処理する場合、入力は様々なパケット構造で構成されるかもしれません。テスターは、関連する入力を定義することで、関連するファジングデータを作成するための基盤を構築します。
3.#### ファジングデータの生成
この段階では、ファジングエンジンはさまざまな予期しない入力や無効な入力を作成します。これらの入力は、ランダムに生成されたもの、有効なデータを変異させたもの、またはエッジケースをシミュレートするために細工されたシーケンスである可能性があります。その目的は、予期しないデータの処理に弱点がないか、ターゲットシステムの境界に挑戦できる入力を生成することです。
4.#### ファジングされたデータによるテストシステム
さて、生成されたファジング・データはターゲット・システムに供給される。この段階では、システムは各入力と相互作用し、異常なデータや無効なデータに応答します。システムが多様な入力に繰り返しさらされるため、ファズテストによっ て、システムが正しく答えられなかったり、クラッシュしたりするポイントが明らかになります。
5.#### システムの動作の分析
システムが各入力を処理するとき、その動作は注意深く監視される。テスターは、クラッシュ、応答しない動作、予期しないエラーメッセージなど、異常動作の兆候を探します。この段階は、実際のシナリオで悪用される可能性のある脆弱性や潜在的な弱点を特定するのに役立ちます。
6.#### 問題の特定
最後に、テスト中に検出された異常が、本物の問題であるかどうかを判断するために、レビューが行われ る。テスターは、デバッギングツールを使用して、観察された動作を分析し、各不具合の根本原因を特定する。
ファズテストの種類
ファズテストには様々な形態があり、それぞれに明確な戦略と用途があります。ここでは、ファズテストの主な種類と分類の内訳を示します:
1.入力ベースのファジング
このタイプのファジングは、プログラムがさまざまなデータをどのように扱うかをテストするために、さまざまな入力を生成することに重点を置いています。これには2つの主要なアプローチがある:
突然変異ベースのファジング:**この方法は、ランダムに変更を加えることによって、既存のデータサンプルを変更します。例えば、突然変異ベースのファジングでは、入力がテキストファイルの場合、予期しない文字を追加したり、セクションを入れ替えたり、値を変更したりします。このアイデアは、既知の有効な入力を取り込み、新しい、わずかに「変異」したバージョンを作成することで、現実的なデータにある程度類似性を保ちながら、脆弱性を明らかにすることができる。
世代ベースのファジング:** 変異ベースのファジングとは異なり、世代ベースのファジングは入力をゼロから構築する。事前に定義されたルールと構造を使用して、特定のフォーマットやプロトコルを模倣した新しいデータを作成します。例えば、XMLパーサーをテストする場合、生成ベースのファジングは、様々な構造、タグ、属性値を持つXMLファイルを構築する可能性があります。
2.構造を考慮したファジング
構造認識ファジングは、テストされるデータの根本的な構造を理解します。ランダムなデータや変異したデータを供給する代わりに、内容を変化させながら正しいフォーマットやプロトコル構造を維持する。
- プロトコルファジング:** 構造認識ファジングの典型的なアプリケーションであるプロトコルファジングは、特定の通信標準(HTTPやTCP/IPなど)に準拠した入力を生成することによって、ネットワークプロトコルをテストするために使用されます。
3.カバレッジガイドファジング
カバレッジガイドファジングは、プログラムの実行からのフィードバックを使用して新しい入力を生成します。コード・カバレッジ・メトリクスを追跡して、各入力でコードのどの部分が実行されたかを特定し、テストされていないコード・パスをカバーすることを目的とした入力を作成する。このアプローチは、コードカバレッジを最大化し、隠れたバグや脆弱性を発見する可能性を高めるため、徹底的なテストを達成するために非常に効果的です。
4.ブラックボックス、ホワイトボックス、グレーボックスファジング
これらのカテゴリーは、テスターがターゲットソフトウェアについてどれだけの情報を持っているかによって異なります:
ブラックボックス・ファジング:*** ブラックボックス・ファジングでは、テスト者はプログラム内部の知識を持っていません。入力はランダムに生成され、プログラムの構造やコードを考慮することなくソフトウェアに供給されます。ブラックボックス・ファジングはセットアップが簡単で、ソースコードを必要としません。他の方法ほど多くの問題を発見できないかもしれませんが、クローズドソースのアプリケーションのテストに役立ちます。
ホワイトボックスファジング:*** ホワイトボックスファジングでは、テスターはプログラムのソースコードに完全にアクセスすることができます。これにより、ファジングプロセスは、静的解析や制御フロー追跡のようなテクニックを使用して、入力生成を導きながら、コードの特定の部分をターゲットにすることができます。ホワイトボックス・ファジングは、より正確で、複雑なバグを発見することができますが、詳細なコード知識が必要であり、より多くのリソースを必要とします。
グレーボックス・ファジング:*** グレーボックス・ファジングは、ブラックボックス・アプローチとホワイトボックス・アプローチの間のバランスを取る。テスターはプログラムの内部動作に部分的にアクセスすることができ、通常はコードカバレッジに関するフィードバックを提供するインスツルメンテーションを行います。このアプローチでは、ブラックボックス・ファジングの効率性とコード・カバレッジからの追加ガイダンスが得られます。
5.ハイブリッドファジング
ハイブリッドファジングは、複数のファジング戦略を組み合わせて、テストの深さと効率を向上させます。例えば、変異ベースのファジングとカバレッジガイドのテクニックを融合させることで、より幅広い入力バリエーションを探索しながらコードカバレッジを最大化することができます。したがって、テスターは、単一のファジング手法だけでは見逃される可能性のある脆弱性を見つけるために、より高い精度で複雑なソフトウェアをターゲットにすることができます。
ファズテストの使用例
ファズテストの用途は、特にセキュリティ、安定性、回復力が重要な業界において多岐にわたります。ここでは、ファズテストの主な使用例を紹介します:
1.セキュリティテスト
ファズ・テストの最も一般的な応用例の一つは、セキュリティ・テストである。プログラムにランダムな入力や不正な入力を与えることで、ファズテ ストは、バッファオーバーフロー、入力検証の欠陥、インジェクションの脆弱性など、ハッカーが悪用する可能性のある脆弱性 を明らかにすることができます。
2.ソフトウェアの堅牢性
ファズテストはまた、アプリケーションがクラッシュすることなく、予期せぬデータや不正なデータを優雅に扱えるようにすることで、ソフトウェアの堅牢性を向上させます。多くのプログラムは、特定の入力を想定して設計されていますが、実世界のデータは常に予測できるとは限りません。様々な予期しない入力でテストすることで、ファズテストは、特に予測不可能な環境で実行されるアプリケーションや、多様なデータを扱うアプリケーションにおいて、ソフトウェアがストレス下で失敗する可能性のある領域を明らかにすることができます。
3.プロトコルテスト
プロトコル・ファジングは、ネットワーク・プロトコルの回復力をテストするために広く使われている。ネットワークプロトコルは、デバイス間のデータ交換のルールを定義するものであり、これらのプロトコルに弱点があると、セキュリティ侵害や混乱につながる可能性があります。ネットワーク・プロトコルのファジング・テストを通じて、テスターはこれらのプロトコルが予期しないパケットや不正なパケットをどの程度処理できるかを評価し、データの完全性、セキュリティ、通信の信頼性に影響を及ぼす可能性のある脆弱性を特定することができます。
4.自動車およびIoTテスト
自動車システムでは、ファズ・テストによって自動車のサブシステム間の通信の脆弱性を明らかにし、運用と安全性を維持できるようにします。同様に、IoTデバイスのファズテストは、これらのデバイスが機能やセキュリティを損なうことなく、さまざまなネットワーク条件やデータ入力を処理できることを確認する上で不可欠です。
ファズテストの利点
1.隠れたバグや脆弱性の早期発見: ファズテストは、従来のテスト手法では見逃してしまうようなバグ、特に稀な入力シナリオや予期せぬ入力シナリオによって引き起こされるバグを発見します。
2.**ソフトウェアの堅牢性と信頼性を向上させます: **不正なデータや予期しないデータを含む様々な入力にソフトウェアをさらすことで、ファズテストは開発者が弱点を特定し、現実の状況に対してソフトウェアを強化するのに役立ちます。
3.**ファズテストは、バッファオーバーフロー、メモリリーク、インジェクションの欠陥など、攻撃に悪用される可能性のある脆弱性を発見します。したがって、セキュリティチームがこれらの弱点に積極的に対処し、潜在的なサイバー攻撃や不正アクセスからソフトウェアを保護することができます。
4.コードカバレッジの向上: カバレッジガイド型ファジングは、コードの使用頻度の低い部分まで確実にテストし、めったに実行されないパスのバグを発見します。この広範なテストアプローチは、他の方法では無視されるかもしれないコードパスを探索することにより、ソフトウェアの全体的な品質と安定性を向上させます。
ファズテストの課題と限界
1.複雑なデータを扱う際の複雑さ: ファズテストは、複雑なデータ形式に依存する複雑でステートフルなプログラムと格闘する。例えば、プロトコルやファイルフォーマットのテストでは、ファジングには構造の知識が必要であり、これが複雑さを増し、高度なファジング技術を必要とします。
2.リソースと時間の制約:大規模なファジングは、多大な処理能力とメモリを消費する可能性があり、リソースを大量に消費します。意味のある結果を得るためには、特に複雑なアプリケーションの場合、長い実行時間が必要になることが多く、テストと開発プロセスを遅らせる可能性があります。
3.ランダム入力生成の限界: ファズテストは、ランダムまたは半ランダム入力に依存しており、特に複雑なロジックや依存関係を持つ複雑なプログラムでは、必ずしもコードの深い部分に到達するとは限りません。さらに、純粋にランダムなファジングは、特定の脆弱性をターゲットにするために必要な集中力を欠いているため、特定のコードパスのバグは検出されないままであるかもしれません。
4.問題を再現することの難しさ:ファジング・テストでは、不明瞭なバグを発見することができますが、これらのバグを誘発した正確な条件を再現することは困難です。問題を引き起こした特定の入力や一連のイベントが簡単に再現できない場合、デバッグはより複雑になります。
5.偽陽性と結果のノイズ: ファズテストは大量のデータを生み出す可能性があり、偽陽性として知られる、実際の脆弱性ではない問題を示す結果もあります。偽陽性をフィルタリングし、本物の脆弱性に焦点を当てることは、時間がかかり、専門知識を必要とします。
6.継続的なモニタリングと分析:ファジング・テストは1回限りのプロセスではなく、継続的なモニタリングが必要です。さらに、効果的なファジングを行うには、広範なログと結果を解釈する必要があり、検出された問題を分析し対処するために熟練した人材が必要となります。
ファズテストのツールとフレームワーク
1.AFL (American Fuzzy Lop)**: 変異ベースのファジングの効率性で知られるAFLは、インテリジェントな入力変異とコードカバレッジフィードバックを組み合わせて脆弱性を発見します。
2.libFuzzer**:ライブラリとアプリケーションのために設計されたカバレッジガイドファザーであるlibFuzzerは、複雑なソフトウェアの隠れたバグを発見するためのコードカバレッジを目的とした入力を生成します。
3.OSS-Fuzz**: オープンソースプロジェクトに特化した大規模ファジングプラットフォームであるOSS-Fuzzは、広く利用されているオープンソースソフトウェアのセキュリティと安定性を向上させるための継続的な自動ファジングテストを提供します。
4.Peach**: 複雑なソフトウェアや通信プロトコルをテストするための、さまざまなプロトコルやデータ形式をサポートする包括的なファジングフレームワークで、世代や突然変異ベースのテストを含みます。
5.Sulley**: 主にネットワークプロトコルのファジングに使用されるSulleyは、多種多様なネットワーク入力をシミュレートする能力が評価され、セキュリティ研究でよく使用されます。
6.Radamsa**: 軽量な突然変異ベースのファザーで、使い方が簡単で、ソフトウェアの回復力と堅牢性をテストするために予期しない入力を生成するのに有効です。
ベクターデータベースとAIアプリケーションのためのファズテスト
Milvus](https://zilliz.com/what-is-milvus)(Zillizによって作成された)のようなベクトルデータベースやGenAIアプリケーションにおいて、ファズテストは非常に重要である。Retrieval-Augmented Generation(RAG)やその他の機械学習モデルのようなAI駆動型ソリューションでは、ファズテストは、特に非構造化データを扱う場合、データの整合性、システムの安定性、およびセキュリティを維持するために不可欠です。ここでは、ファズテストがどのように有益であるかを説明する:
ベクターデータベースにおけるロバストデータハンドリングの保証:** ベクターデータベースは複雑なクエリやフィルタリングをサポートすることが多いため、ファズテストはクエリ入力のエッジケースをどれだけうまく処理できるかを明らかにすることができる。したがって、インデックス作成と検索における潜在的な障害や非効率性を特定することができます。
RAG のような AI を利用したアプリケーションにおけるレジリエンスのテスト:** RAG や類似の AI モデルは、応答を生成したり特定のタスクを実行したりするために、外部データベースから関連情報 を取得することに依存している。これらのモデルは、検索されたデータの品質と構造に敏感です。ファズテストでは、破損したデータや予期しないデータの入力をシミュレートし、通常とは異なる検索に対してモデルがどのように反応するかを確認することができます。
潜在的な攻撃に対するベクターデータベースとAIパイプラインの保護:**ファズテストは、AIモデルの動作を操作するように設計された敵対的な例のような、敵対的なデータ入力をシミュレートすることができます。これにより、攻撃者が悪用する可能性のある弱点を特定し、開発者はセキュリティを強化することができます。
Improving Reliability in Distributed AI Architectures: 多くのAIアプリケーション、特に**Large Language Models (LLMs) **や画像認識システムを搭載したものは、複数のノードやシステムに分散されています。ファズテストは、分散ベクトルデータベースのノード間のデータ同期プロセスの問題を明らかにし、データベースのすべてのインスタンスが一貫性のない入力や予期しない入力をスムーズに処理できるかどうかをチェックすることができます。
ファズテストのベストプラクティス
ファズテストの効果的な実施には、慎重な計画とベストプラクティスの遵守が必要です。ここでは、ファズテストを最適化するために不可欠なヒントをいくつか紹介します:
1.### 入力生成の最適化
変異ベースと生成ベースのファジングを使用して、一般的なエッジケースとまれなエッジケースをカバーする幅広い入力を確保します。
無関係なエラーを回避し、意味のある問題に焦点を当てるために、ターゲット・ソフトウェアが期待するデータ形式またはプロトコルに一致するように入力生成を調整する。
複雑なデータ型に対しては、構造を意識したファジングまたはカバレッジガイドを使用して、コードカバレッジを最大化し、より深いバグを見つけます。
2.### 包括的なモニタリングとフィードバックの設定
クラッシュ、メモリリーク、異常出力など、テスト中のプログラムの動作を詳細にログに記録する。
Prometheus のような監視ツールを使用して、メモリ使用量、CPU 負荷、および実行パスを追跡し、ファジッ ク入力下でのソフトウェアのパフォーマンスに関する洞察を得ることができます。
クラッシュ・レポートとデバッグ・ツールを有効にして、検出された問題の根本原因を追跡し、バグの再現と修正を容易にします。
3.### 正しいツールの選択
プロジェクトの特定の要件に基づいてファジングツールを選択します。たとえば、AFLは突然変異ベースのファジングに、libFuzzerはライブラリに、OSS-Fuzzはオープンソースプロジェクトに使用できます。
ツールが開発およびテスト環境にうまく統合され、CI/CDパイプラインにシームレスに組み込むことができることを確認してください。
複数のツールで実験し、異なるファジング戦略を組み合わせることで、より良いカバレッジと結果を得ることができる。
4.### 効果的なテスト環境の設計
偶発的な損傷やデータ損失を防ぐために、ファジングしたソフトウェアを重要なシステムから隔離する制御されたテスト環境を構築する。
ファズテストはリソースを大量に消費する可能性があるため、十分なコンピューティングリソースを割り当てます。リソースの割り当てを効率的に管理するために、仮想マシンまたはコンテナでテストを実行することを検討します。
古いコンポーネントは意図しない問題を引き起こす可能性があるため、定期的にテスト環境を更新し、最新の依存関係とパッチを含める。
5.### よくある落とし穴を避ける
落とし穴:*** 特定の領域をターゲットとせずに、ランダムな入力だけに頼ること。 解決策:* カバレッジガイドまたは構造認識ファジングを使用して、最も重要なコードパスにテストを向ける。
ピットフォール:**偽陽性を無視する。 解決策:定期的に結果をレビューし、出力を分類するためのツールやスクリプトを使用して、真の問題に焦点を当てるためにフィルタリングします。
落とし穴:**ファズテスト中に見つかった問題の再現に失敗する。 解決策:検出された問題を正確に再現して修正できるように、ファジングしたすべての入力と実行パスをログに記録します。
6.### ファズテストを継続的に行う
新しいコード変更が潜在的な脆弱性について一貫してテストされるように、ファズテストを CI/CD パイプラインに統合します。
特に重要なソフトウェアコンポーネントについては、継続的な開発プロセスの一環として、定期的なファズテストを予定してください。ファジングを継続的に行うことで、問題を早期に発見できる可能性が高まります。
結論
要約すると、ファズテストは、ベクターデータベースやAIシステムなど、様々なソフトウェアアプリケーションの隠れたバグや脆弱性を発見するための強力な手法である。ファズテストは、ランダムな入力や不正な入力をプログラムに与えることで、堅牢性、セキュリティ、信頼性を向上させるのに役立つ。ファズテストには課題が伴いますが、ベストプラクティスを採用し、適切なツールを使用することで、その効果を最大化することができます。
ファズ・テストに関するFAQ
- ファズテストとは何ですか?
ファズテストは、バグや脆弱性を発見するために、ランダムなデータや予期しないデータをプログラムに入力するソフトウェアテスト手法です。従来のテスト手法では見逃してしまうような問題を発見することで、ソフトウェアのセキュリ ティ、堅牢性、信頼性を向上させます。
- ファズ・テストは実際にどのように機能するのか?
ファズテストにはいくつかの段階があります:ターゲットシステムを特定し、テストする入力のタイプを決定し、ファズデータを生成し、このデータでプログラムを実行し、プログラムの動作を分析し、問題を特定します。このプロセスによって、ソフトウェアが予期しない入力や不正な入力をどの程度うまく処理できるかが明らかになります。
- ファズテストの一般的な種類は何ですか?
一般的なタイプには、突然変異ベースのファジング(既存のデータを変更する)、世代ベースのファジング(ゼロから入力を作成する)、カバレッジガイドファジング(コードカバレッジを最大化する)、およびプロトコルファジング(特定のデータ形式または通信規格をテストする)が含まれます。
- ファズ・テストはAIアプリケーションやベクター・データベースに適用できるか?
はい、ファズ・テストはAIやベクター・データベースに大いに関係があります。特にRAG(Retrieval-Augmented Generation)やAIパイプラインでの複雑なデータ処理のようなアプリケーションでは、これらのシステムが予測不可能な入力を処理し、データの整合性を向上させ、セキュリティを維持するのに役立ちます。
- ファズテストの主な課題は何ですか?
主な課題には、複雑なデータ構造の取り扱い、大規模ファジングのリソース集約的な性質、ランダム入力生成の限界、問題の再現の難しさなどがあります。ベストプラクティスに従い、適切なツールを選択することで、これらの課題に対処することができます。
関連リソース
RAGアプリケーションの評価方法](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
RAGアプリケーションの最適化:信頼性向上のための方法論、評価基準、評価ツールのガイド](https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications)
Zillizクラウドにおける包括的なモニタリングと観測可能性の紹介](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
Prometheus Metrics: アプリのパフォーマンスを監視する](https://zilliz.com/glossary/prometheus-metrics)
Observability:モニタリングを超えたトラッキング](https://zilliz.com/glossary/observability)
GrafanaとLokiによるMilvusのモニタリング](https://zilliz.com/blog/monitoring-in-milvus-with-grafana-and-loki)
ベクターデータベースにおける検索パフォーマンスのボトルネックを発見する方法](https://zilliz.com/learn/how-to-spot-search-performance-bottleneck-in-vector-databases)