




データベースのシャーディングを理解する

データベースのシャーディングを理解する
最新のウェブサイトやアプリケーションは、複数のユーザーからの読み取りや書き込みのリクエストを処理するために、データベーステクノロジーに大きく依存しています。しかし、アプリケーションの人気が高まるにつれ、ユーザー数は増加し、データベースの頻繁なクラッシュにより、最適な顧客体験を提供することが困難になります。
では、需要の増加に対応するために、開発者はどのようにデータベースを拡張すればよいのでしょうか?その答えはユースケースによって異なりますが、データベース・シャーディングは簡単で費用対効果の高い方法の1つです。実装が簡単で、パフォーマンスが大幅に向上します。
そのシンプルさにもかかわらず、データベース・シャーディングは分かりにくい概念かもしれません。この記事では、最適なシャーディング手法を適用するタイミングと方法を理解するのに役立つように、その意味、実装テクニック、代替案、利点と課題、ユースケースについて説明します。
データベース・シャーディングとは?
データベース・シャーディングは、大規模なデータベースをシャードと呼ばれる小さな塊に分解し、複数のマシンに分散させます。各マシンは同じテクノロジーを使用し、並行して大量のデータを処理します。
これは、データ処理を高速化し、高可用性を確保するための多くの手法の一つです。リクエストの過負荷により1台のマシンやデータベース・サーバーに障害が発生しても、他のサーバーが読み込みや書き込みのリクエストを処理できるため、スムーズなユーザー・エクスペリエンスを維持できる。
しかし、シャーディングが機能するのは、データが利用可能でアクセスできる限りにおいてのみである。これにより、開発者は作業負荷を有機的に分散し、待ち時間を短縮することができる。
レプリケーションとパーティショニングは、ダウンタイムを防ぐための他のテクニックである。これらの方法は、より小規模なデータベースに適している。レプリケーションではデータベース全体を複数のサーバーにコピーし、パーティショニングではデータベースを分解して1台のマシンに格納する。後のセクションで、これらのアプローチについて詳しく説明します。
データベース・シャーディングの仕組み
シャーディングは水平スケーリングの一形態で、開発者は複数のデータ・パーティションを格納するために追加のノードやサーバーを設置します。各パーティションは、元のデータベースと同じスキーマを共有する独立したテーブルになります。しかし、各シャードの情報は一意であり、開発者はノードと呼ばれる複数のコンピュータに個々のチャンクを保存します。
たとえば、次の表は、顧客とその顧客が購入した商品に関する情報を表す単一のデータベースを示しています。
| 顧客ID** | 名前 | 購入した商品 | 10001 |
| 10001|A|シャツ | |||
| 10002|B|キャップ | |||
| 10003|C|シャツ | |||
| 10004|D|シューズ |
開発者はデータベースのシャーディングを使用して、データベースを別々のマシンまたは物理的なシャード上の論理的なシャードと呼ばれる小さなパーティションに分割することができます。
サーバー 1
| 顧客ID** | 名前 | 購入アイテム |
| 10001|A|シャツ | ||
| 10002|B|キャップ |
サーバー 2
| --------------- | -------- | ------------------ | | 顧客ID | 名前 | 購入品目 | | 10003|C|シャツ | 10004|D|シューズ
シャーディングはシェアードナッシングアーキテクチャで動作し、コンピュータクラスタ内の1つのノードが独立してユーザーリクエストを処理します。ユーザーがデータベースにアクセスしようとすると、そのユーザーの情報を含むシャードのみがアクティブになり、入力されたリクエストを処理します。
開発者はシャード・キーを使ってデータを論理的なシャードに分割する。開発者は、データをグループに編成する列に基づいてキーを選択するか、新しいキーを作成することができます。以下のセクションでは、シャード・キーがどのように動作するかを説明し、効率的なシャーディングのためのデータ・グループの開発を支援します。
シャーディングの方法
開発者は、ユースケースや処理したいデータの性質に応じて、複数のシャーディング手法を実装することができます。一般的な手法としては、レンジベース・シャーディング、ハッシュド・シャーディング、ディレクトリ・シャーディング、ジオ・シャーディングなどがある。
範囲ベースのシャーディング
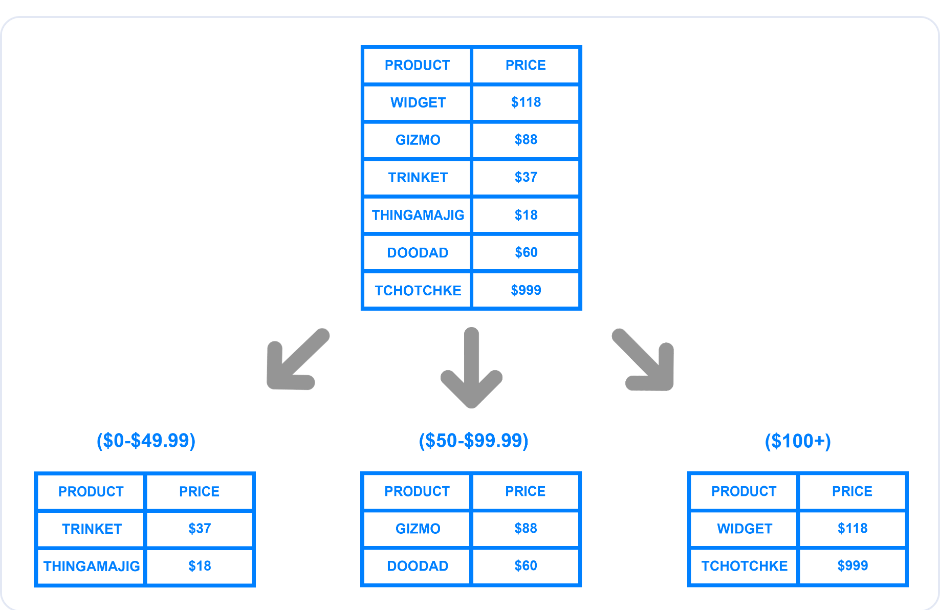
レンジベース・シャーディングまたはダイナミック・シャーディングは、特定の値域に基づいてデータベースをシャー ドに分割します。以下の図は、開発者が価格範囲を使ってテーブルをシャー ドに分割する方法を示しています。
 価格に基づく範囲ベースのシャーディング.png
価格に基づく範囲ベースのシャーディング.png
価格ベースの範囲ベースのシャーディング
この例では、価格範囲を使って作成された3つの論理シャーディングを示しています。開発者は各チャンクに一意のシャードキーを割り当て、別々の物理シャードまたはマシンに格納することができます。データベースにレコードを書き込むとき、システムは価格範囲に基づいてデータが属する適切なシャードを決定し、それに応じて更新します。
動的シャーディングの実装は簡単ですが、特定のシャードに他よりも多くのレコードが含まれる場合、過負荷になる可能性があります。上記の例では、100ドル以上の商品を購入する顧客が増えると、3番目のシャードのデータ量が他のシャードのデータ量よりも多くなります。
このような不均等な分散は、シャーディングの目的を達成できなくなる可能性がある。また、この方法では、一意のシャード・キーと対応する範囲を格納するルックアップ・テーブルが必要になる。
ハッシュド・シャーディング
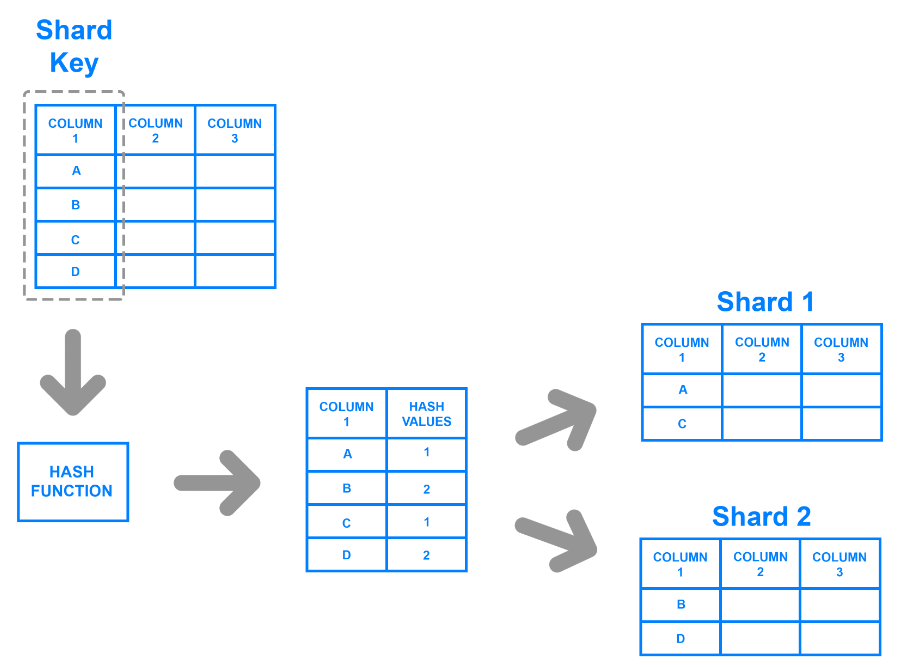
ハッシュド・シャーディングは、特定のカラムに基づいて各レコードにハッシュ・キーを割り当てます。開発者は、カラムの値を入力とするハッシュ関数を使用してハッシュキーを生成する。開発者は、対応するキーまたはハッシュ値に属するレコードを決定することで、データを分割することができる。
例えば、開発者はカラムを選択し、その値を使ってハッシュ値を生成することができる。これらの値は各チャンクのシャード・キーとなり、開発者はそれらを異なるマシンに保存することができる。下図はそのプロセスを示している。
 ハッシュ化シャーディング.png
ハッシュ化シャーディング.png
ハッシュド・シャーディングは、ハッシュ関数やアルゴリズムがデータを分割するためにユーザー定義のシャード・キーを必要としないため、不均等な分布の問題を克服する。しかし、キーが意味のある基準に基づいてデータをグループ化しないため、個々のシャードからデータを照会するのは困難になる。アルゴリズムはランダムにハッシュ値を生成し、その場限りの方法でデータを分割する。
例えば、範囲ベースのシャーディングでは、キーはテーブル内の特定の値の範囲を反映し、より意味のあるデータ構造に関連する。値の範囲に基づくクエリシャーディングは、ハッシュキーに基づくデータクエリよりも速い。
さらに、シャードを追加したりシステムをアップグレードしたりする場合、開発者はすべてのレコードに対してハッシュアルゴリズム全体を再実行する必要がある。このプロセスはマシン間のデータ量のバランスを取るために必要だが、多大なダウンタイムとコンピューティング・リソースを伴う可能性がある。
ディレクトリ・シャーディング
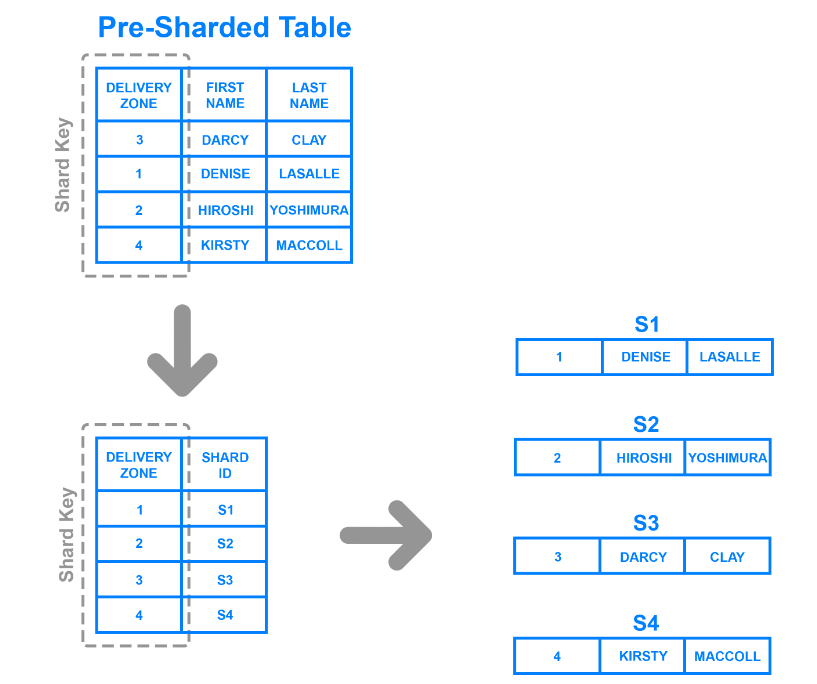
ディレクトリ・シャーディングは、上述の方法よりも柔軟性が高い。特定のカラムの値に基づいてデータを分割し、ルックアップテーブルを使用してレコードがどのシャードに属するかを決定する。
 配信ゾーンに基づくディレクトリ・シャーディング.png
配信ゾーンに基づくディレクトリ・シャーディング.png
例えば、この図では、Delivery Zoneカラムをシャードのキーとして使用し、顧客が属するゾーンに従ってデータを分割する方法を示しています。この方法では、テーブルに4つのゾーンがあるため、4つの異なるシャードが作成されます。
範囲ベースのシャーディングとは異なり、データパーティションは厳密な値の範囲に準拠する必要がないため、より汎用的です。また、特定のカラムのすべての値に対してアルゴリズムを使用してキーを生成する必要がないため、開発者はより迅速にシャードを更新することができる。
しかし、この手法では、入ってくるリクエストに対応するためにルックアップテーブルが必要となり、処理速度が低下する。また、シャードの数が膨大になるようなカラムを選択すると、ルックアップテーブルのサイズとレイテンシが大幅に増加します。
シャードキーの選択
効率的なデータベースのシャーディングを行うには、開発者が適切なシャーディングキーを決定し、シャード間で均等にデータが分散されるようにする必要があります。不均等な分散では、特定のシャー ドが他よりも多くのデータを含むデータ・ホットスポットになる可能性があります。
また、シャード・キーはクエリ・プロセスを簡素化し、処理速度を向上させ、ダウンタイムを防止する必要があります。さらに、適切なシャード・キーを決定するには、適切なカラムを選択する必要があります。
以下のリストでは、開発者がシャード・キーを生成するために最適なカラムを選択する際に考慮できる3つの重要な要素を紹介しています。
- カーディナリティ:** カーディナリティは、開発者がカラム内の明確な値に基づいて作成できるシャードの最大数を指定します。例えば、3つの異なる値を含むカラムを選択すると、3つのシャードが生成されます。ディレクトリベースのシャーディングは、カラムのカーディナリティが低い場合に役立ちます。
- 頻度:**頻度とは、特定のシャード・キーに属するデータの割合を指します。例えば、価格に基づく範囲ベースのシャーディングでは、特定の価格帯が全レコードの約80%を占めることがあり、データのホットスポットになります。
- 動的シャード:***動的シャードのデータ量は、アプリケーションの需要の変化に応じて変化する。例えば、アプリケーションの人気が高まると、ユーザーの属性が変化し、20~25歳の顧客からの申し込みが増加する可能性があります。年齢に基づく範囲ベースのシャーディングでは、20~25歳の年齢層に対応するシャードにより多くのデータが存在するため、データ・ホットスポットが発生する可能性があります。
データベースの効果的なシャーディングを確保するために、開発者はシャード・キーのカーディナリティと頻度を考慮し、動的なシャーディングになるかどうかを判断する必要があります。
代替案との比較
データベース・シャーディングは、データベースを拡張する方法の一つである。その他の方法には、垂直スケーリング、レプリケーション、パーティショニングなどがある。これらがシャーディングとどのように異なるかを理解することは、開発者が特定のシナリオに適したスケーリング方法を使用するのに役立ちます。
垂直スケーリング
垂直スケーリングでは、既存のサーバーの容量をアップグレードします。開発者は、パフォーマンスを向上させるために、CPU、ハードディスク、その他のソフトウェアを追加インストールすることができます。
この方法は、1台のマシンでユーザーのリクエストを処理するのに十分であり、パフォーマンスを向上させるために必要なのは漸進的な改善だけである場合に役立ちます。
シャーディングよりもコストは低いが、ユーザーリクエストを処理できるのは1台のマシンだけなので、サーバーの容量は限られた程度しか増加しない。
レプリケーション
レプリケーションは、開発者が同じデータベースのコピーを作成し、複数のコンピュータにまたがって保存する場合に発生する。シャーディングと同様に、この方法は高可用性を保証する。
シャーディングとレプリケーションは、複数のマシンに処理を分散する点で似ている。しかし、シャーディングはデータをさまざまなチャンクに分割するのに対し、レプリケーションはデータを分割せずに全体をコピーする。
レプリケーションには大容量のストレージを持つサーバーが必要になるため、シャーディングは大規模なデータベースに適している。各レプリカを異なるマシンで維持・更新するのはコストと時間がかかる。
パーティショニング
パーティショニングはデータベースを複数のグループに分割し、1 台のマシンに格納します。この方法は、クエリ・パフォーマンスを向上させたいが、データベース・サイズが異なるマシンにまたがってパーティションを保存するほど大きくない場合に適しています。
開発者が日付と時間に従ってデータをパーティショニングできるようにすることで、データ・アーカイブの最適化に役立てることができる。ある閾値より古いタイムスタンプを持つ特定のレコードをアーカイブテーブルに移動し、別のテーブルを使用して最新のレコードを格納することができる。
データベース・シャーディングの利点
データベース・シャーディングは、効率的なデータ管理のための貴重な戦略である。Webサイト、アプリケーション、その他のデータ駆動型ソフトウェアを運用するために膨大なデータに依存している企業は、データベース技術の利点を最大限に活用するためにシャーディングを採用する必要があります。
以下のリストでは、シャーディングが組織に提供するいくつかのメリットについて詳しく説明します。
スケーラビリティ:**複数のマシンにデータを分割することで、シャーディングは、増加するワークロードをサポートするために、より効率的にデータベースシステムを拡張することができます。
最小限のダウンタイム:** シャーディングは、シェアード・ナッシング・アーキテクチャーで動作することで、高い可用性を保証します。この戦略により、1台のマシンの障害が他のマシンのパフォーマンスに影響しないため、ユーザー・エクスペリエンスが向上します。
開発者はシステム全体をシャットダウンすることなく、個々のマシンを個別にアップデートできるため、パフォーマンス・アップグレードの実装がより効率的になります。
データベース・シャーディングの課題
シャーディングは大きなメリットをもたらしますが、開発者は実装の複雑さを増すいくつかの課題に直面する可能性があります。以下のリストでは、これらの問題を潜在的な緩和策とともに紹介します。
不均一な分散: **データ量と種類の不確実性により、ホットスポットが発生する可能性がある。効果的なシャード・キーがあるにもかかわらず、データの性質が変わる可能性があり、開発者は新しいキーを選択または作成する必要がある。開発者は、特定のシナリオにおけるデータベース・シャーディングの適合性を慎重に評価する必要がある。状況によっては、シャーディングよりもレプリケーションやバーティカル・スケーリングの方が実用的な場合もある。
複数のマシンを管理するのは複雑で、開発者は各ノードの健全性を常に監視し、問題を迅速に特定・解決しなければならない。リアルタイムのアラートメカニズムを備えた堅牢な監視システムは、サーバー障害が発生した場合に関連チームに通知することで、これらの問題を軽減するのに役立ちます。
メンテナンス・コスト:*** 複数のオンプレミス・サーバーを維持するのはコストがかかり、メンテナンス中に問題を解決するために、関連する専門知識を持つスタッフを追加する必要があります。組織はクラウドインフラストラクチャに移行して様々なシャードをホストし、クラウドベンダーに裏で定期的なメンテナンスチェックを実施してもらうことができる。
データベース・シャーディングの使用例
上記のセクションでは、シャーディングが有益なユースケースを簡単に紹介したが、以下のリストではこれらのシナリオを分類し、より詳細に説明する。
大規模ウェブ・アプリケーション:** 広範なユーザーベースを持つEコマース・サイト、ソーシャル・メディア・プラットフォーム、自動車配車アプリ、およびゲーム・ウェブサイトは、データベース・シャーディングの理想的な候補です。シャーディングは、このようなサイトの管理者がより効果的に負荷分散を行い、ピーク時のダウンタイムを防ぐのに役立ちます。
ビッグデータ分析:**ビッグデータを分析するユーザーにとって、シャーディングは複数のサーバーに負荷を分散することで処理速度を向上させるのに役立ちます。
コンテンツ・デリバリー・ネットワーク(CDN):** CDNは、地理的に近い場所にいるユーザーからのリクエストを処理するために、異なる場所に分散されたサーバーのグループです。開発者は、ユーザーのロケーションに応じてデータベースをシャードし、これらのサーバーにデータを分散させることで、応答時間を短縮することができます。
データベースのシャーディングに関するFAQ
1.**シャーディングとパーティショニングの違いは何ですか?
シャーディングとパーティショニングはデータをより小さなチャンクに分割しますが、シャーディングは各チャンクを異なるマシンやノードに分散します。対照的に、パーティショニングは各チャンクを1つのマシン内に保存します。
2.**シャーディングとレプリケーションの違いは何ですか?
レプリケーションはデータベース全体をコピーし、異なるマシンに保存します。データベースを行ごとに分割し、各チャンクを複数のサーバーに保存するシャーディングに比べ、レプリケーションは可用性が高いが、より多くのコンピューティング・リソースとストレージ容量を必要とする。
3.**正しいシャード・キーはどのように選択しますか?
適切なシャード・キーを選択するには、データを分割するための適切なカラムを決定する必要があります。シャード・キーは、カーディナリティが低く、頻度が等しくなければならない。
カーディナリティとは、カラムの値によって可能なシャードの最大数のことです。例えば、4つの異なる値を含む列を選択すると、4つのシャードになります。頻度とは、各シャードが含むデータの割合のことです。
また、アプリケーションのライフサイクルを通じて静的なシャードを選択または作成します。データ量が変化する可能性のあるシャードは、ホットスポットになる可能性があります。
4.**データベース・シャーディングの主な課題は何ですか?
データベースのシャーディングは、開発者が分析を行うために複数のマシンからデータにアクセスするクエリーを書かなければならないため、クエリーのオーバーヘッドを増加させる。
また、組織が複数のサーバーを維持し、機能停止を防ぐためにその健全性を監視しなければならないため、インフラ・コストも増加する。
また、データ量と種類が増えると、シャードの更新とリバランシングが複雑になる。ある状況に適したシャーディング技術が、他の状況では実用的でなくなる可能性もある。
5.**データベース・シャーディングは小規模なアプリケーションに適しているか?
データベース・シャーディングは処理速度とスループットを向上させる貴重な技術ですが、小規模なアプリケーションには不適切です。データベース・シャーディングは、処理速度とスループットを向上させる貴重な技法ですが、小規模なアプリケーションには不適切です。
関連リソース
開発者は通常、構造化データセットにシャーディングを適用しますが、以下のリソースは、非構造化データやベクトルデータベースの文脈でこの概念を理解するのに役立ちます:
Sharding、Partitioning、Segments - Getting the Most From Your Database](https://zilliz.com/blog/sharding-partitioning-segments-get-most-from-your-database)
動的スキーマとは](https://zilliz.com/blog/what-is-dynamic-schema)
マルチクラウド環境におけるベクターデータベースの展開](https://zilliz.com/learn/Deploying-Vector-Databases-in-Multi-Cloud-Environments)
クラウドネイティブ・ベクターデータベース管理システムの解剖](https://zilliz.com/blog/anatomy-of-a-cloud-native-vector-database-management-system)
ベクターデータベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
RAGとは】(https://zilliz.com/learn/Retrieval-Augmented-Generation)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル ](https://zilliz.com/ai-models)