




DiDi食品はどのようにMilvusとラテンアメリカの食料品検索を変革したか

19%削減
Milvusのセマンティック・ベクトル検索を使った無結果クエリにおける
4%増
Milvusを利用したセマンティック商品マッチングによるカート内コンバージョン
クエリーの15
従来のテキスト検索を補完するベクトル検索の利点
サブ秒ベクトル検索
Milvus IVF_FLAT インデクシングと内積類似度による
ディディ・フードについて
DiDiは、世界で8億人以上のユーザーを持つライドヘイリングのグローバルリーダーであり、メキシコ、コロンビア、コスタリカを含むラテンアメリカの主要12都市で、食料品宅配サービスであるDiDi Foodを開始した。既存のロジスティクス・ネットワークとリアルタイムの最適化機能を活用し、わずか6ヶ月で月間アクティブユーザー数200万人、1日の注文件数50万件、2025年第1四半期のGMV1億2000万ドル以上という目覚ましい成長を達成した。
このプラットフォームは、生鮮食品や生活必需品を30~45分で配達し、提携店舗はそれぞれ最大3,000万SKUを提供している。多言語でのやりとり、ダイナミックな価格設定、リアルタイムの在庫管理など、多様な市場で事業を展開するDiDi Foodは、素晴らしいビジネス基盤を築いた。しかし、その規模が大きくなるにつれ、何百万人もの顧客が膨大な商品カタログの中から必要なものを的確に見つけられるようにすることの複雑さも増していきました。そこで、Milvusのベクトルデータベースが同社の検索機能を変革し、言語を超えて機能する意味理解を可能にし、人々が実際にどのように検索するかという現実世界の混乱を処理することができるようになったのです。
##検索の課題:キーワードベースのElasticsearchが壊れるとき
DiDiのエンジニアリングチームは、キーワードベースのElasticsearchデータベースを悩ませる限界に直面していました。単純なスペルミスやコードの入れ替え、型にはまった説明文は、しばしば空の結果ページを引き起こし、ショッピング体験に摩擦を生じさせていました。
結果なし」率の高さ:隠れた収益の損失
DiDi Foodは、あまりにも多くの顧客の検索結果がゼロであり、ショッピングセッションが放棄され、収益が失われているという重大な問題に直面していました。DiDiの検索データから得られた実例から、これらの失敗を引き起こす3つの主な原因が明らかになった。
タイポとスペルミス**が最も一般的な原因でした。ユーザーは、"Jengibre"(生姜)を検索するときに "Genjibr "と入力したり、"HELADO"(アイスクリーム)の代わりに "hedaho "と入力したり、"Kellongs "を "Kelloggs "と入力したりした。Elasticsearchを利用した既存のキーワード検索システムでは、このような小さいながらも重要なスペルギャップを埋めることはできませんでした。
入力方法のアーティファクト**は、もう一つの障壁を作り出しました。モバイルキーボードや異なる入力システムは、"wine "の代わりに "𝑤𝑖𝑛𝑒"、"banana "の代わりに "ᵄ𝑛ᵄ"、"chocolates "の代わりに "𝑐ℎᵅ𝑐𝑎𝑅𝑡𝑒𝑠 "のような珍しいUnicodeのバリエーションを生成しました。このような技術的なエンコーディングの問題により、顧客は明らかに在庫のある商品を見つけることができなかった。
中南米市場では、混合言語のクエリが最大の課題となった。顧客は当然、英語とスペイン語を組み合わせて「apple juice orgánico」や「leche sin lactosa」を検索する。メキシコ、コロンビア、コスタリカでは、同じ商品でも呼び名が異なることがある。
検索に失敗するたびに、顧客は不満を募らせ、直接的な収益が失われていった。1日50万件の注文を処理するプラットフォームでは、検索結果が得られないクエリがわずかな割合であっても、ビジネスに大きな影響を及ぼします。
スケーラビリティと多言語の複雑性
DiDiは、個々の検索の失敗だけでなく、スケーラビリティを脅かすシステム的な課題にも直面していた。何千万もの異なるSKU名のテキストインデックスを作成することは、ストレージコストを増大させ、商品カタログが複数の国にまたがって拡大するにつれて、クエリのパフォーマンスを低下させました。
多言語の複雑さは、言語が混在するクエリよりも深刻でした。メキシコ、コロンビア、コスタリカ、その他の中南米市場で事業を展開していたため、同じ製品でも地域によって名前がまったく異なることがありました。ある国では "Palta"、別の国では "aguacate "と、どちらもアボカドを指しています。Elasticsearchを使った従来のキーワードシステムでは、各地域のバリエーションごとに別々のインデックスを管理する必要があり、ストレージ要件が増大し、メンテナンスも複雑になっていました。
文化的、言語的なニュアンスも、さらなる障壁となりました。地域のスラング、ブランド名のバリエーション、さらには異なる測定システム(メートル法とインペリアル法)などが、検索の失敗の原因となっていた。キーワードベースのアプローチでは、何千もの地域バリエーションを手作業でマッピングする必要があり、DiDiの規模では不可能な作業だった。
DiDiのエンジニアリングチームは、これらの課題を克服し、言語や地域、顧客のニーズの表現方法に関係なく、ユーザーのクエリの背後にある意図を理解できるソリューションを緊急に必要としていました。
解決策Milvusによるセマンティック検索エンジンの構築
Elasticsearchを搭載したシステムは、単語を意味のある概念としてではなく、個別のトークンとして扱うため、言語の多様性やユーザー入力の多様性に苦戦しています。しかし、ベクターデータベースはベクター埋め込みによってユーザーのクエリの意味と意図を理解し、言語やスペルミスに関係なく、より正確で関連性の高い結果を返すことができる。
DiDiのエンジニアリングチームは、多言語埋め込みモデルとベクトルデータベースを活用することで、セマンティック検索エンジンを構築することにした。埋め込みモデルは、商品名や説明文、ユーザーからの問い合わせを、高次元空間における意味的な意味を表すベクトル埋め込みに変換し、ベクトルデータベースはこれらの埋め込みを保存し、問い合わせベクトルと商品ベクトル間の距離を計算することで意味検索を実行する。
慎重な評価の結果、彼らはjina-embeddings-v3を主要な埋め込みモデルとして選んだ。つまり、"苹果"(中国語)、"apple"(英語)、"manzana"(スペイン語)のクエリはほぼ同じベクトルを生成し、複雑な翻訳システムを必要とせずに正確なクロスリンガルマッチングを可能にする。スペルミスや音声的に類似した入力でも、正しい用語に近いベクトルが得られます。
DiDiがベクトルデータベースとしてMilvusを選択した理由は、オープンソースの成熟度、数十億ベクトルまで水平に拡張できる能力、ミリ秒のレイテンシ、実証済みの高スループットアーキテクチャ、豊富な機能セットです。
データアーキテクチャと最適化戦略
DiDiのエンジニアは、3,000万SKUを超える低レイテンシーのベクトル検索を、店舗レベルの関連付けを維持しながらサポートするために、いくつかの重要な最適化を実施しました。
SKUと店舗の組み合わせごとに個別のベクトルを格納するのではなく、同一の商品名を単一のベクトルエントリに統合し、対応する店舗IDを配列に格納しました。このアプローチにより、ベクターライブラリが3,000万エントリーから20万ユニークベクターに削減され、完全な商品カバレッジを維持しながらメモリ使用量を劇的に削減することができました。
チームは圧縮の複雑さよりも検索精度を優先し、Milvusの
IVF_FLATインデックス構成を選択した。ユーザーがシステムに問い合わせると、Milvusは集約されたインデックスから最も類似している上位k個のベクトルを返し、その後、買い物客の現在地で入手可能な商品を分離するための迅速な店舗IDフィルタが続く。データの鮮度を保つため、DiDiはT+1夜間更新サイクルを採用している。新規および更新されたSKUは毎日バッチ処理され、GPUクラスタを使用して再エンベッドされ、Milvusコレクションを更新するためにプッシュされる。この戦略により、膨大な製品カタログ全体にわたって、データの最新性と計算効率のバランスが保たれている。
Milvusスキーマ設計
コレクションスキーマは、柔軟性とパフォーマンスのバランスをとりながら、DiDiの食料品検索に対する特定の要件を反映しています:
item_name = FieldSchema(
name="item_name"、
dtype=DataType.VARCHAR、
is_primary=True、
max_length=1000
)
vector = FieldSchema(
name="vector"、
dtype=DataType.FLOAT_VECTOR、
dim=1024
)
shop_info = FieldSchema(
name='shop_info'、
dtype=DataType.ARRAY、
element_type=DataType.INT64、
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info]、
description="jina-embeddings-v3を使った埋め込み"、
enable_dynamic_field=True
)
prop = {"shards_num":1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop、
dimension=1024)
except CollectionNotExistException:
return False
index_params = { {インデックス・パラメータ
"metric_type":"IP"、
「index_type":"IVF_FLAT"、
「params":params": {"nlist":1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
コレクションを返す
GPU アクセラレーションによる埋め込み生成
jina-embeddings-v3`モデルによるCPUベースのエンベッディング生成の初期段階では、1レコードあたり5秒という許容できない待ち時間が発生しました。リアルタイム性能を達成するために、DiDiは同社のLubanプラットフォームにGPUインスタンスを導入し、埋め込み時間をクエリあたり約50ミリ秒に短縮した:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = [].
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
ハイブリッド・サーチ・パイプライン・アーキテクチャ
DiDiは既存のインフラを完全に置き換えるのではなく、確立されたElasticsearchシステムのインテリジェントな補完としてMilvusを導入した。デュアルパイプライン設計により、Elasticsearchは標準的なキーワードクエリを処理し、Milvusは複雑なケースのためのセマンティックな理解を提供します。
検索フローは以下のステップで動作する:
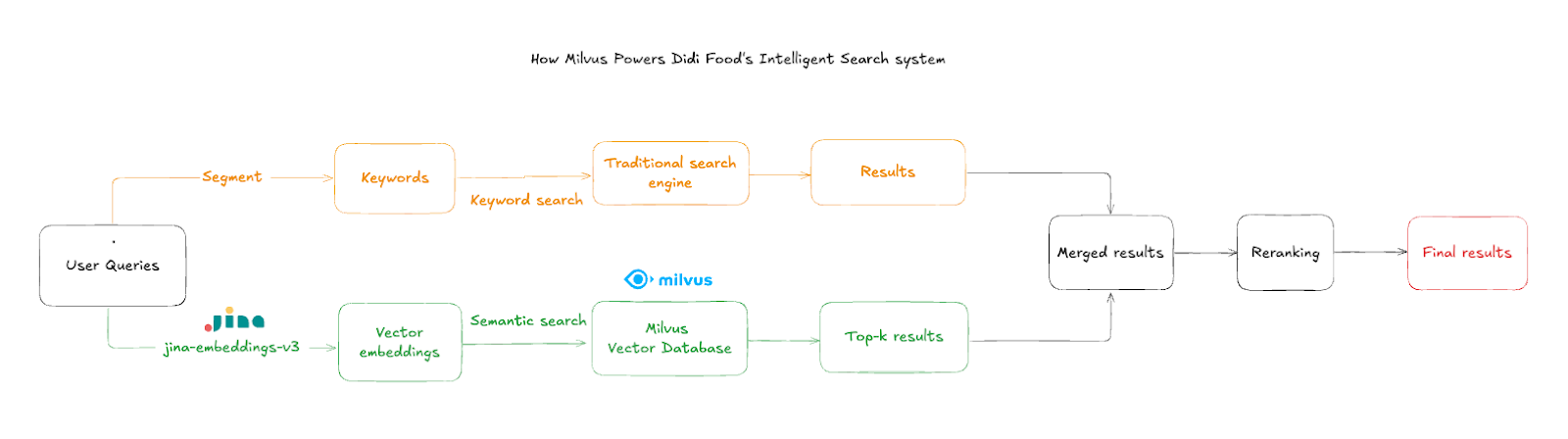
1.ユーザークエリー入力:顧客は商品名や説明を入力する。多くの場合、タイプミスや言語が混在している。
2.テキストの埋め込み:システムはjina-embeddings-v3を使用し、入力を高次元の意味ベクトルに変換する。
3.類似検索:Milvusは集約された積ベクトルを照会し、最も近い意味的一致を見つける。
4.店舗フィルタリング:結果は店舗IDでフィルタリングされ、現在の店舗に在庫のある商品のみが表示されます。
5.結果のマージ:従来の検索では満足のいく結果が得られなかった場合、ベクターの検索結果をElasticsearchの検索結果と組み合わせることで、より豊かで完全な検索体験を提供します。
ユーザーエクスペリエンスにとって重要なのは、店舗レベルのフィルタリングであり、これは買い物客の現在のロケーションコンテキストに属する結果を保証します。Elasticsearchの検索結果が満足のいくものでなかった場合、Milvusのセマンティックに関連するアイテムが検索結果を補足します。
パフォーマンス結果と実世界への影響
DiDiのMilvus導入により、重要なビジネス指標において具体的な改善が見られました。
このシステムにより、検索結果が表示されないクエリが19%減少しました。これは、以前は検索に失敗していたほぼ5件に1件が関連商品を返すようになったことを意味し、失われた収益機会を直接回復することができます。毎日50万件の注文を処理するプラットフォームにとって、この回復率は重要なビジネス価値に相当します。
ベクター検索は、クエリ全体の15%をトリガーし、従来のテキスト検索を補完することで、コアクエリパイプラインを圧迫することなく、セマンティックな理解が付加価値を生む。最も重要なことは、ベクター検索で呼び出されたアイテムに接触したユーザーは、カート追加コンバージョンが4%増加し、検索結果の関連性の向上が、測定可能な購買行動につながることを示していることです。
システムは現在、英語、スペイン語、中国語、韓国語、日本語を含む多言語のクエリに対応しており、特にスペイン語の精度が顕著に向上しています。リキッドファンデーション "の検索は、英語の "Liquid Foundation "でも、中国語の "液体妆前乳 "でも、スペイン語の "Base de maquillaje líquida "でも同じように機能します。このシステムは、従来のキーワードアプローチでは完全に躓いてしまうような言語のギャップを埋めている。
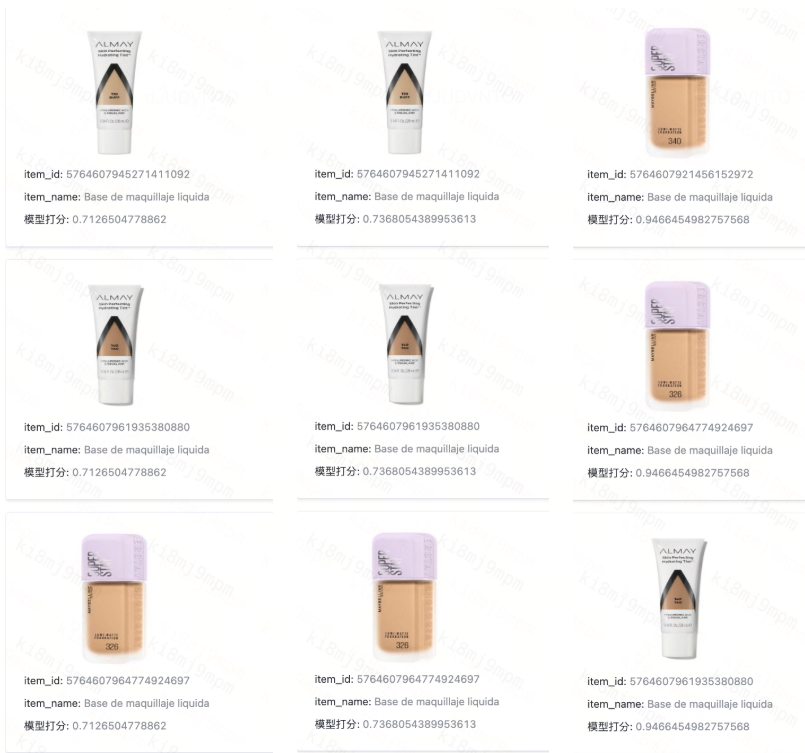
図:リキッドファンデーション "の検索は、英語の "Liquid Foundation "でも、中国語の "液体妆前乳 "でも、スペイン語の "Base de maquillaje líquida "でも同じように機能する。
**ユーザーが "Redac PalancaPara WC Blanca"(白いトイレの水洗レバー)を検索すると、従来の検索では複数単語の製品説明が解析できなかったのに対し、ベクトルシステムは複合的な専門用語にもかかわらず、クエリを正確にマッチさせる。
これらの利点は、よりスムーズなショッピング体験、より高い顧客満足度、生鮮食料品のeコマース市場における決定的な競争上の優位性につながります。
将来のロードマップ次世代検索機能
この強固な基盤の上に、DiDiとMilvusは次の開発段階に向けていくつかの先進的な機能を共同で開発している。
リアルタイムのカタログ同期は、ストリーミング更新によって在庫変更と検索可能なデータ間の待ち時間を短縮し、ユーザーが実際に利用できない商品を見ることがないようにする。行動シグナル統合は、ベクトルの類似性をユーザーの履歴、嗜好、文脈的シグナルと統合し、時間の経過とともに改善される超パーソナライズされたレコメンデーションを提供する。
高度なハイブリッド検索とリランキングは、おそらく最もエキサイティングな開発だ。このシステムは、価格、評価、プロモーション、在庫レベルなどのビジネス指標と、セマンティックな関連性を融合させ、個々の買い物客にとって本当に最適なレコメンデーションを表示する。
多言語サポートの強化は、DiDiが新たな市場に参入する際に、対応言語を拡大し、地域の方言への対応を改善する。動的な埋め込み最適化により、継続的な学習メカニズムが実装され、実際のユーザーインタラクションパターンに基づいて埋め込み品質を向上させることで、使うほどに賢くなる検索システムを実現します。
DiDiは、継続的なイノベーションにより、食料品検索体験を再定義し、すべての買い物客がいつでも必要なものを正確に見つけられるようにしています。
結論
DiDi FoodのMilvusとの旅は、セマンティック検索が技術的なアップグレード以上のものであることを示している。熟考されたデータアーキテクチャ、適切なテクノロジーの選択、そしてユーザーエクスペリエンスへの揺るぎないフォーカスを組み合わせることで、彼らは言語や文化を超えて真に意図を理解する検索システムを作り上げたのです。
その結果、イライラするユーザーが減り、購入が成功し、顧客がどのようにニーズを表現するかに関係なくショッピング体験が得られるようになった。DiDiの月間200万人のユーザーにとって、これは、必要なものを、必要なときに、必要な言語で、最も自然に感じられる方法で、一貫して見つけることを意味する。
このサクセス・ストーリーは、革新的な企業がセマンティックな理解を大規模に取り入れることで何が可能になるかを示している。DiDiがラテンアメリカ全域で拡大を続ける中、Milvusを利用した検索アーキテクチャは、継続的なイノベーションとユーザー満足のための強固な基盤を提供しています。テクノロジーは機能し、ビジネス上の成果は明確で、ユーザーエクスペリエンスの向上は目に見えるものです。