




VIPSHOP Builds a 10x Faster Personalized Recommender System Using Milvus

10x Faster Query Speed
than the previous Elasticsearch solution
<30ms Response Time
for searching on millions of vectors
Optimized User Experience
with more accurate recommendations based on users’ purchase behaviors
Milvus-powered vector search has been running steadily in our recommendation systems, providing high performance and allowing us more flexibility in selecting models and algorithms.
VIPSHOP Search Service Team
About VIPSHOP
VIPSHOP is a renowned NYSE-listed online retailer headquartered in China, specializing in providing popular branded products to consumers with significant discounts. Its diverse product range includes fashion, apparel, accessories, beauty products, home goods, and electronics. Boasting a staggering customer base of over 52 million and facilitating nearly 270 million orders annually, VIPSHOP has earned its place as the 115th entry in Fortune's prestigious China 500 listing.
Challenges: High Latency and Spiking Maintenance Costs Using Elasticsearch
With the rapid growth of its business, VIPSHOP faced a common dilemma: as its product portfolio expanded, so did the complexity of helping users discover what they were looking for. To address this issue, VIPSHOP created a personalized recommendation system based on user query keywords and users’ purchase bahaviors.
Previously, the VIPSHOP team utilized the Cosine Similarity(7.x) capabilities of Elasticsearch to power the recommendation system. However, this approach was inefficient for two reasons:
High latency in vector searching: Averaging around 300 ms for retrieving Top-K results from millions of vectors, resulting in seconds for the system’s overall response time.
High costs of maintaining Elasticsearch indexes: Vectors derived from products, consumers’ purchase behaviors, and all other data shared the same set of indexes, making the index construction, operation, and maintenance much more complicated.
VIPSHOP attempted to enhance Elasticsearch's performance by developing a locality sensitive hashing plugin. However, it only improved throughput and failed to reduce the vector search time to below 100 ms. Therefore, the team was still in urgent need of a new vector searching stack to improve their system performance.
The Milvus Solution
After extensive research, the VIPSHOP team opted for Milvus, an open-source vector database capable of handling billions of vector embeddings and delivering lightning-fast responses. Milvus also offers rich features such as distributed deployment, multi-language SDKs, and read/write separation, making it a superior choice to Elasticsearch and many other vector search solutions like FAISS.
The Architecture of VIPSHOP Recommendation System Using Milvus
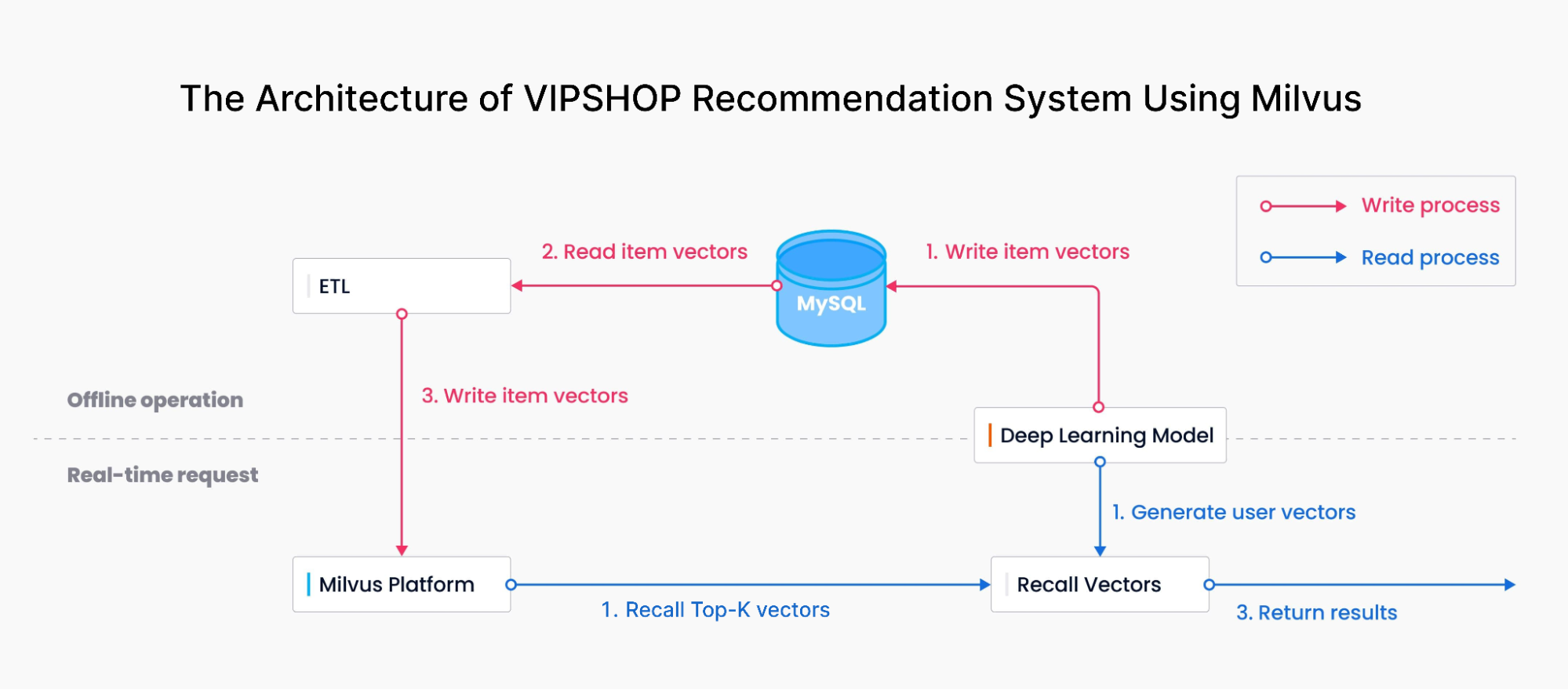
The diagram above demonstrates the architecture of VIPSHOP’s recommendation system with Milvus. It consists of two core parts:
Write process: the VIPSHOP team used a deep learning model to transform each product’s features into vector embeddings and then imported them into Milvus through MySQL and an ETL tool.
Read process: the team used the deep learning model to transform consumers’ queries and purchase behaviors into vectors and then retrieved similar results in Milvus. Milvus performed a similarity search and returned the Top-K most relevant results to consumers.
Milvus Implementation Details: Data Update and Recall
Data update and recall are the most essential processes for the Milvus-powered recommendation system.
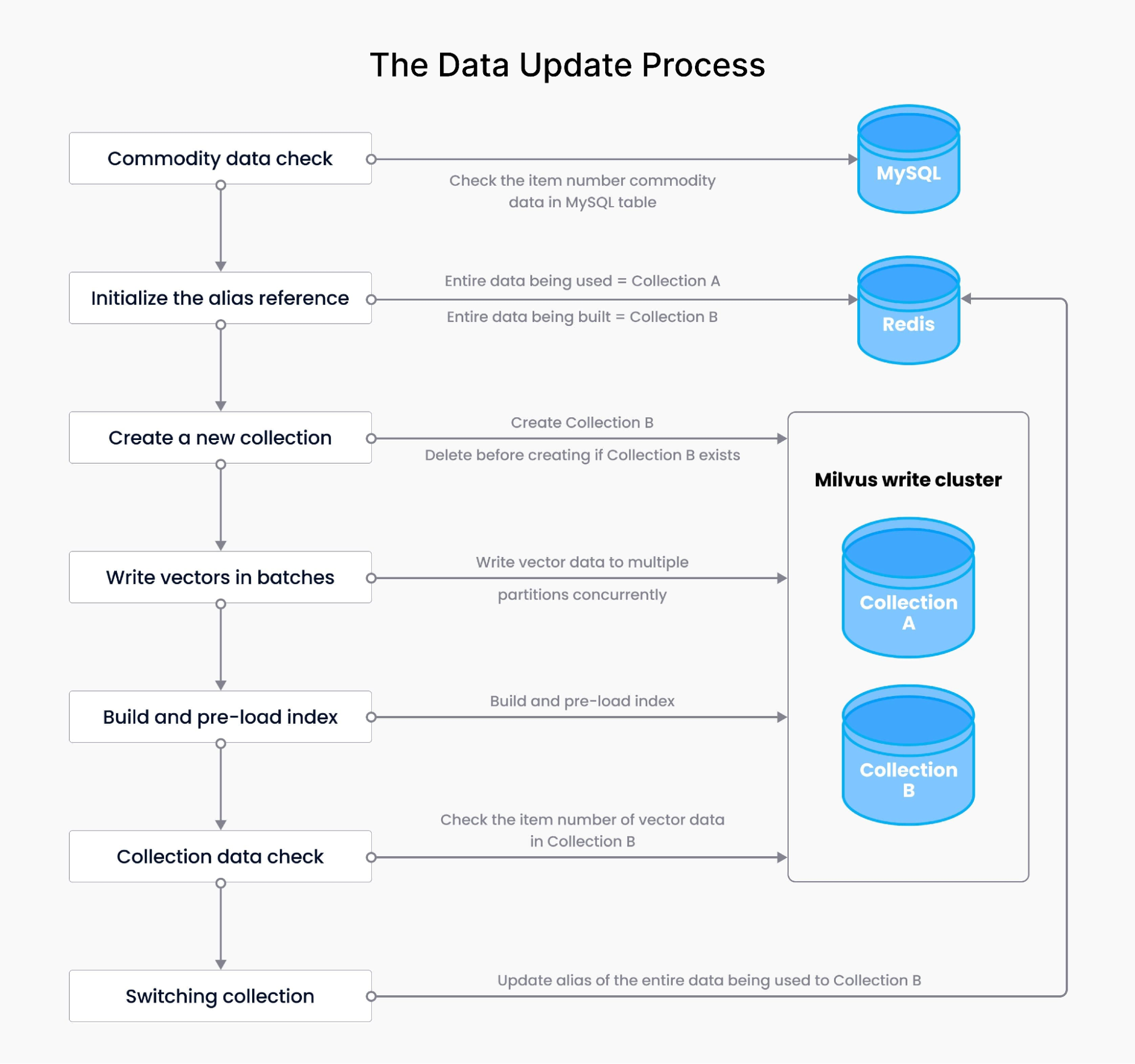
The data update procedure ensures data synchronization, encompassing tasks such as writing vector data, detecting vector data volumes, index construction, index pre-loading, and alias management. It begins with commodity data checks, ensuring the quantity in MySQL aligns with existing data. The entire data-building process follows, including alias initialization in Redis, creating new collections, writing vectors in batches, and pre-loading the index in Milvus. After verifying the new collection's data, the system seamlessly switches aliases between multiple data collections.
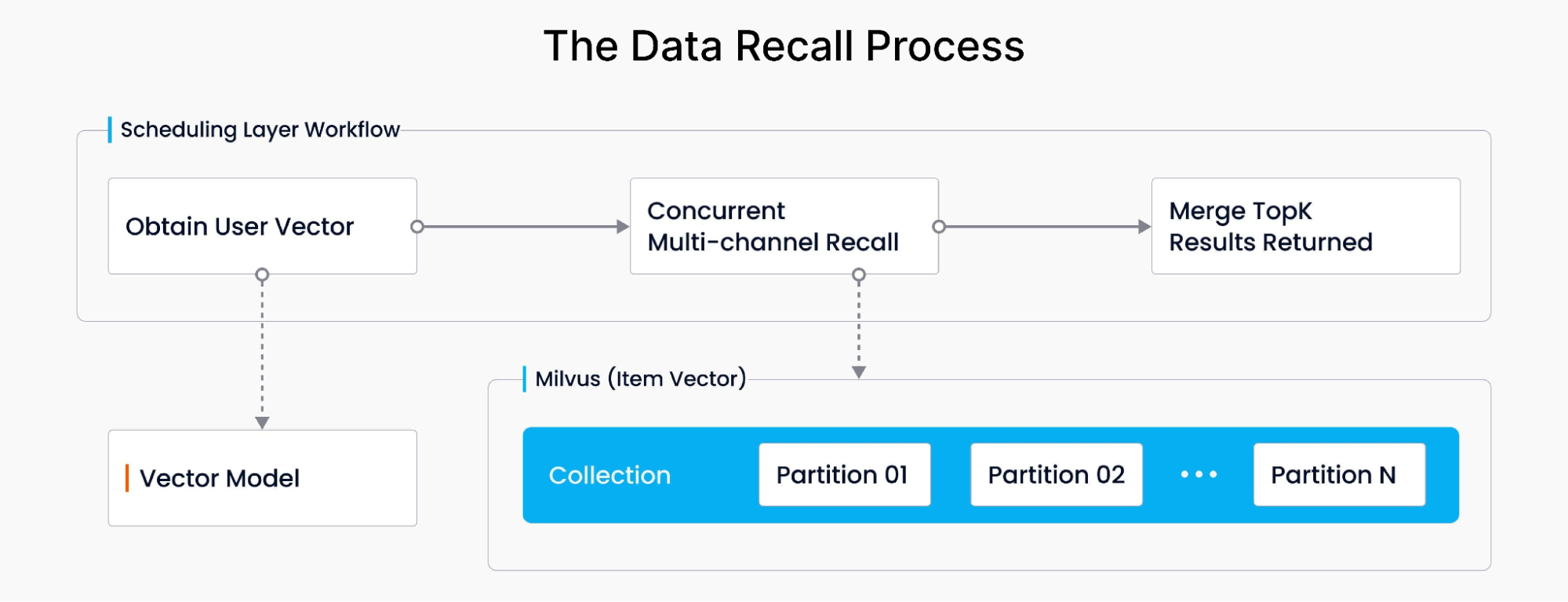
The recall process, crucial for recommending products, involves acquiring vectors related to consumers’ queries and purchase behaviors, calculating their distance, and merging results. Utilizing Milvus, the system concurrently and asynchronously retrieves data in different Milvus partitions, calculates vector similarities, and ranks the top results based on similarity distance. Then, after multiple calls to Milvus partition data, it presents the final recommendation results to users. The overall workflow is as follows:
The following table shows the performance of three primary Milvus services. As shown in the table, the average latency for recalling Top-K results is around 10ms.
| Service | Role | Input Parameters | Output parameters | Response latency |
|---|---|---|---|---|
| User vectors acquisition | Obtain user vector | user info + query | user vector | 10 ms |
| Milvus Search | Calculate the vector similarity and return Top-K results | user vector | item vector | 10 ms |
| Scheduling Logic | Concurrent result recalling and merging | Multi-channel recalled item vectors and the similarity score | Top-K items | 10 ms |
Results: Better System Performance and Optimal User Experience
The adoption of Milvus in VIPSHOP's recommender system significantly improved the overall system performance, including:
10x Faster Query Speed
Using Milvus, the system query and response time has been reduced to below 30ms, 10x faster than the previous Elasticsearch solution.
Improved System Scalability
Milvus's distributed deployment and support for horizontal scaling enable the recommendation system to handle rapidly increasing data volumes and user queries effortlessly without compromising performance.
Enhanced User Experience
Milvus optimizes the recommendation process to provide tailored product suggestions based on user preferences and search intent, improving user satisfaction and engagement.
Reduced Maintenance Costs
Milvus efficiently handles vector data and streamlines querying mechanisms, reducing overall maintenance costs for the recommender system.
Lessons Learned and Recommended Practices
In their journey with Milvus, the VIPSHOP team learned some lessons and gained several crucial insights for optimal system performance and user experience:
In situations where read operations take precedence, adopting a read-write separation deployment strategy can enhance the overall system performance.
The Milvus Java client lacks a built-in reconnection mechanism due to its in-memory residency in the recall service. The VIPSHOP team built their own connection pool to ensure consistent connectivity between the Java client and the server through a heartbeat test.
Slow queries occasionally occur in Milvus due to the insufficient warm-up of new collections. To address this issue, the VIPSHOP team simulated queries on the new collection.
To strike the right balance between retrieval performance and accuracy, the VIPSHOP team recommends conducting rigorous pressure testing experiments tailored to your specific business scenario and setting a reasonable threshold value to optimize these parameters.
In scenarios involving static data, it is more efficient to import all data into the collection first and build indexes later.