




Zilliz×ガリレオ:ベクトル埋め込み
非構造化データはどこにでもある。IDCは、2025年までに175ゼタバイト(ゼロが21個)を超えるデータが存在すると見積もっている。そのうちの80%が非構造化データだ。非構造化データとは、あらかじめ決められたフォーマットに当てはまらないデータのことで、あらかじめ設定されたデータモデルやスキーマに従っていない。一般的にはテキスト、画像、音声、動画の形をとるが、他にも様々な条件を扱うことができる。
ベクトル埋め込みとは?
最も基本的なレベルでは、ベクトル埋め込みは数値データ表現です。ベクトル埋め込み](https://zilliz.com/glossary/vector-embeddings)は通常、数百から数千の浮動小数点数から構成されます。高次元のベクトル埋め込みは、画像、音声、テキストなどの複雑なデータを格納することができます。 学習された機械学習モデルからベクトル埋め込みを抽出することができます。生産現場で使用されるほとんどのニューラルネットワークは、それぞれが数百のニューロンを持つ多くの層を持っています。データポイントをニューラルネットワークのフィードフォワード関数に通すと、各層が出力を生成する。通常、これらのネットワークは、ネットワークの最終層によって作成された分類を行う。データを表すベクトル埋め込みは、最後の隠れ層の出力であり、通常は最後から2番目の層を指す。
ベクトル埋め込みはどのように扱えるのか?
ベクトル埋め込みは、非構造化データを扱うための事実上の方法です。もし比較したいデータがあれば、ベクトル埋め込みを使うことをお勧めします。ベクトル埋め込みは、ニューラルネットワークの最後から2番目の層の出力を、入力のベクトル埋め込みとして使用することで、ニューラルネットワークから生成されます。 埋め込みベクトルを生成する際には、考慮すべきいくつかの要素があります。主な考慮点は、埋め込みベクトルのサイズ、モデル学習用のデータ、そしてデータの質です。埋め込みベクトルは、意味のあるサイズでなければなりません。
学習データのデバッグにベクトル埋め込みを使う
データのエラーを見つける
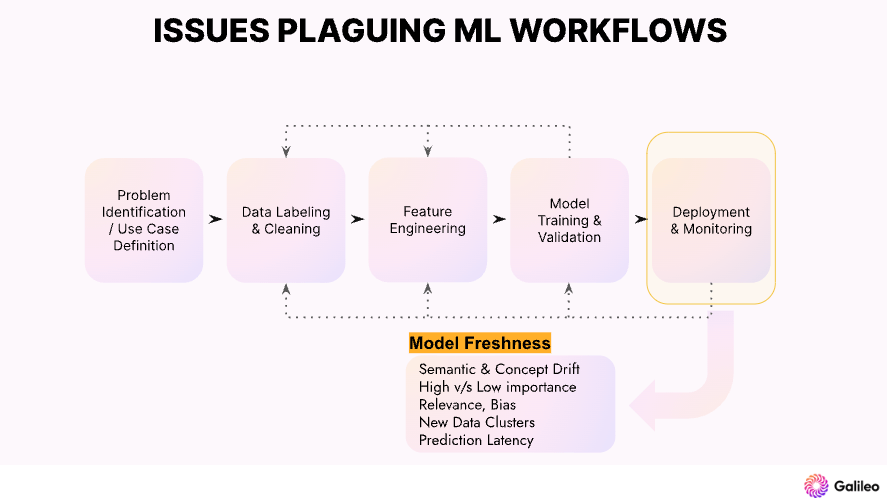
モデル開発の初期段階は、主に「データキュレーション」の課題に取り組むことに関係する。この段階での主な目的は、モデルの学習と評価に最適なデータセットを構築することです。企業向けのアルゴリズムLLM OpsプラットフォームであるGalileoは、クラスタリングを通じてデータエラーを検出するためにエンベッディングを採用しています。
ガリレオ](https://assets.zilliz.com/issues_plaguing_ML_workflows_1_0241f7240a.png)
Galileoは、Data Error Potential (DEP)と呼ばれるスコアでエラーを表示するユニークな機能を持っています。DEPは、モデルのエラーを掘り下げる際に、最も困難で探索する価値のあるデータを素早くソートし、バブルアップするツールを提供します。
データエラーのデバッグに関しては、2種類の解決策があります。
トレーニングデータに存在しないサンプルを見つける
モデルがデプロイされ、実世界のデータと相互作用すると、トラフィックパターンに変化が生じます。Galileoは、MLモデルのパフォーマンスを継続的に監視するためにエンベッディングを活用することで、モデルのドリフトを検出することができます。ドリフトしたサンプルに注釈を付け、トレーニングデータに追加することで、よりロバストなパフォーマンスを得ることができます。
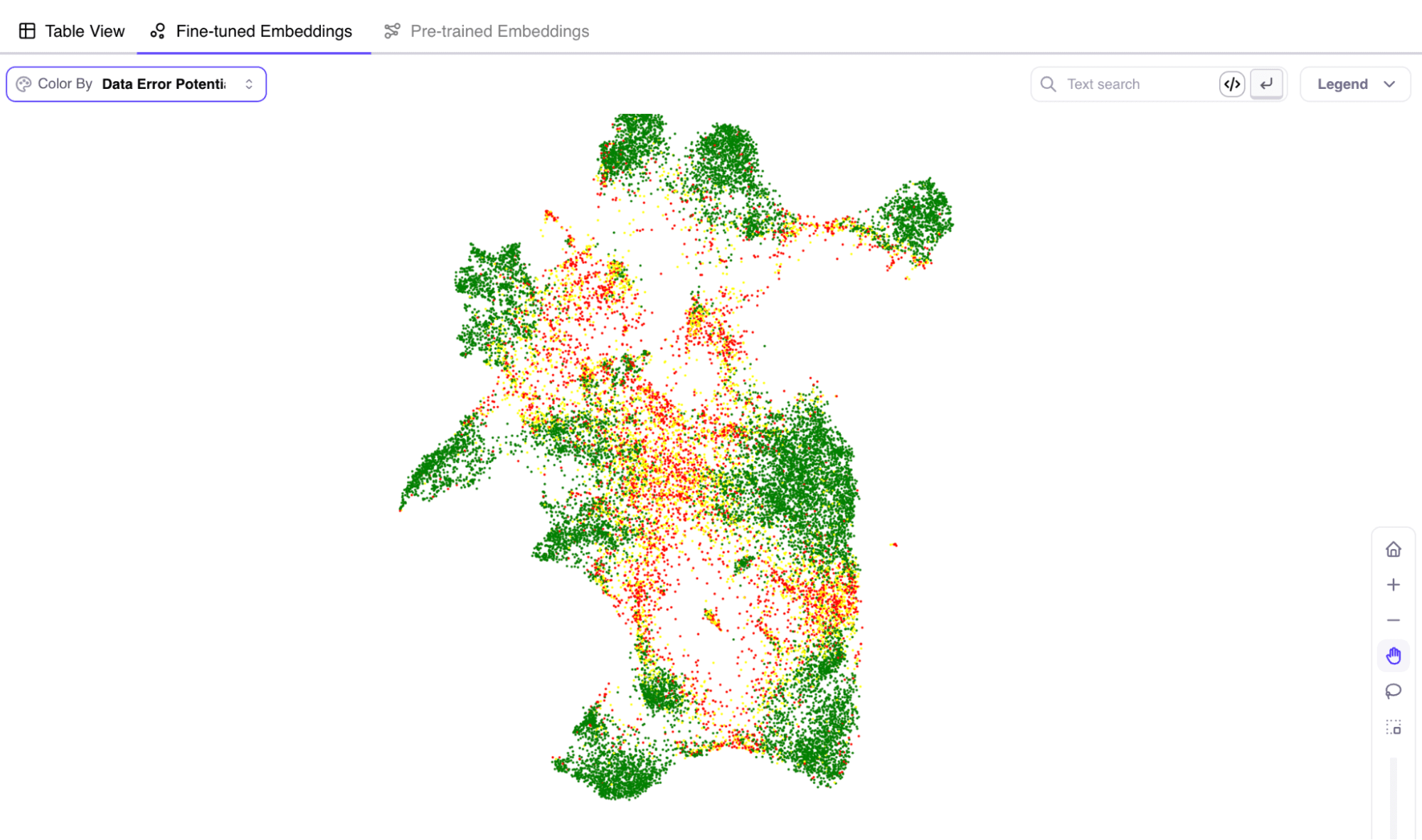
データから幻覚を見つける
AIの幻覚とは、AIが、もっともらしく聞こえるかもしれないが、正しくない、あるいは文脈と無関係な情報を生成する状況を指す。この問題は通常、AIの設計バイアス、現実世界の不十分な理解、または不完全な学習データによって発生する。
この問題に対処するため、ガリレオはAIの幻覚の事例を特定するための埋め込みベースの技術に積極的に取り組んでいる。このアプローチは、データの誤りを明らかにし、より正確で信頼性の高いAIモデルの訓練に貢献します。
検索拡張世代でエラーを見つける
(RAG)検索拡張生成(RAG)は、質問応答システムやチャットボットを開発するための一般的な手法である。しかし、この手法の一般的な問題は、検索不良の発生であり、その結果、誤った回答を提供することになる。Galileoは、この問題に取り組むために、埋め込みベースの技術を用いて間違ったコンテキストを検出するためのコンテキスト関連性スコアを構築している。関連性が正しくても、生成に幻覚が含まれることがある。Galileoは、モデルの応答がコンテキストウィンドウでモデルに与えられた情報に基づいているかどうかを測定する、根拠スコアを提供します。
 Galileoの強力なアルゴリズムはトークン・レベルのエラーを表示することができ、アプリケーションが幻覚を見るのを止めるのに役立ちます。
Galileoの強力なアルゴリズムはトークン・レベルのエラーを表示することができ、アプリケーションが幻覚を見るのを止めるのに役立ちます。

ベクトル埋め込みをインデックス、保存、クエリする
埋め込みベクトルを持つことは素晴らしいことですが、それを利用できなければなりません。ベクトルをインデックス化し、保存し、問い合わせることができるものがあれば最高です。それがベクトルデータベースの要点です。ベクトル・データベースは、ベクトル・データの索引付け、保存、問い合わせのために作られたものです。 索引を付け、格納し、問い合わせることができるため、ベクターデータベースはLLMアプリケーションで使用する有力な候補となります。文書やクエリの意味論的な保存や、FAQのキャッシュとしても最適である。LLMアプリケーションでベクトル埋め込みを使用する方法の完璧な例は、OSSChatです。これは、オープンソースソフトウェアのドキュメントと「チャット」できるアプリケーションです。
OSSChat](https://assets.zilliz.com/oss_chat_application_1d20e28823.png)
実用的なQ/Aアプリケーションを持つ上で最も重要なことの一つは、適切なベクトル埋め込みを使うことです。文書に問い合わせをするためには、問い合わせの潜在ベクトル空間が必要です。ChatGPTのようなLLMを使って、文書集合から質問を生成します。そして、ユーザが質問したときに、その質問を問い合わせるために、それらの埋め込みにインデックスを付けて保存します。
ベクトル埋込みの威力のまとめ
非構造化データは世界で最も一般的なデータです。従来、非構造化データは決められた構造に適合しないため、扱うのは困難だった。ディープラーニングがより強力になり普及したことで、非構造化データをベクトル化することで、非構造化データを扱うソリューションが生まれた。
ベクトル埋め込みは、数字として始まらないものに対して計算を行うことを可能にする。この記事では、ベクトル埋め込みとその扱い方、そして現在の機械学習パラダイムにおけるベクトルの4つの具体的な使い方を紹介しました。ベクトル埋め込みを使って、データの誤りを見つけたり、学習データに存在しないサンプルを見つけたり、幻覚を見つけたり、検索拡張生成の誤りを修正したりすることができます。
ベクトル埋込みの威力は、このような幅広いユースケースからも見て取れます。これらを扱う最も効果的な方法は、MilvusやZilliz Cloudのようなベクトルデータベースを使用して、ベクトルの保存、インデックス付け、クエリを行うことです。
Galileoをホスティングするウェビナーに参加する
10月12日、GalileoのVikram ChatterjiとZillizのYujian TangによるRAGとLLM管理のディープダイブにご参加ください。このウェビナーでは、LLMパイプラインとアウトプットの質を向上させるための実用的な洞察と方法をお伝えします。RAGとLLMのパフォーマンスを最適化するフレームワークやツールを探しているデータサイエンティストや機械学習エンジニアにとって、有益なセッションとなることをお約束します。

{kind=link}
読み続けて

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.