




SelfQueryRetrieverとLangChainを使ってベクターデータベースをクエリする
LangChainは、大規模言語モデル(LLM)とのインタラクションをオーケストレーションすることで知られている。最近、LangChainはセルフクエリを実行する方法を導入し、ユーザ入力クエリを使って "チェーン "やモジュール自身にクエリを実行できるようになりました。この投稿では、世界で最も人気のあるベクトルデータベースであるMilvusにセルフクエリを行う方法を紹介します。ユーザーのクエリを解釈することで、システムはベクターストア内の検索を絞り込み、検索結果を向上させることができる。この例のコードはCoLab hereにあります。
LangChainを使ってMilvusにセルフクエリを設定してみましょう。このプロセスは4つの論理ステップで構成されています。
1.LangChainとMilvusの基本を設定する。
2.必要なデータを入手または作成する。
3.期待されるデータ形式をモデルに知らせる。
4.セルフクエリを実演し、その仕組みを説明する。
セルフクエリ入門
セルフクエリは、自然言語処理(NLP)や情報検索で使用される強力なテクニックである。ユーザーの入力したクエリをシステムが自らクエリすることで、より正確で関連性の高い結果を得ることができます。LangChainの文脈では、セルフクエリはベクトルストア(文書やデータポイントを表すベクトルを格納するデータベース)から情報を検索するために使用されます。セルフクエリ・リトリーバはLangChainフレームワークの重要なコンポーネントであり、自然言語を使った複雑なクエリの作成と検索を可能にします。
セルフクエリを活用することで、LangChainはユーザのクエリをベクトルストアが理解できる構造化フォーマットに分解することができます。このプロセスにより、検索されたドキュメントはユーザのクエリとの関連性が高くなり、必要な情報を見つけやすくなります。会話型AIモデルを構築している場合でも、検索エンジンを構築している場合でも、セルフクエリによって結果の精度と関連性を大幅に高めることができる。
LangChainとMilvusのセットアップ
最初のステップは、必要なライブラリをセットアップすることだ。pip install openai langchain milvus python-dotenv を使って必要なライブラリをインストールできます。以前のチュートリアルを見てくれている人なら、環境変数を扱うのに私が好んで使っているライブラリである python-dotenv にはもう慣れていると思います。GPTにアクセスするためにOpenAIライブラリをLangChainと一緒に使い、ベクターストアとしてMilvusを利用します。
OpenAI APIキーに接続したら、必要なLangChainモジュールをインポートする。以下の6つのモジュールが必要です:
Document`:データを保存するための LangChain データ型。
OpenAI
とOpenAIEmbeddings`:OpenAI とそのエンベッディングにアクセスするための2つの機能。Milvus`:LangChain から Milvus にアクセスするためのモジュール。
SelfQueryRetriever`:リトリーバモジュール。
AttributeInfo`:属性情報モジュール:LangChain のデータ構造を定義するモジュール。
モジュールをインポートした後、変数 embeddings に OpenAI Embeddings のデフォルト関数を設定する。セットアップの最後のステップは milvus ライブラリを使って、ノートブックで Milvus Lite のインスタンスを立ち上げることだ。
さて、データを見てみよう。
import os
from dotenv import load_dotenv
load_dotenv()
インポート openai
openai.api_key = os.getenv("OPENAI_API_KEY")
from langchain.schema import ドキュメント
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Milvus
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
embeddings = OpenAIEmbeddings()
from milvus import default_server
default_server.start()
データを集めてみよう。データをスクレイピングしてもよいし、提供されたデータをそのまま使ってもよいし、テンプレートとして使ってデータを作成してもよい。この例では、ジュラシック・パーク、トイ・ストーリー、ファインディング・ニモ、The Unbearable Weight of Massive Talent、ロード・オブ・ウォー、ゴーストライダーなど、映画に関するドキュメントのリストを用意しました。タイトルはデータには含めないが、どの映画を参照しているかを知ってもらいたい。
それぞれの映画をLangChain Documentオブジェクトとして保存します。これは文字列に対応するpage_contentキーを含んでいます。また、年、評価、映画のジャンルなどのメタデータも含まれています。
docs = [
# ジュラシック・パーク
Document(page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose"、
metadata={"year":1993, "rating": 7.77.7, "genre":「アクション"})、
# トイ・ストーリー
Document(page_content="Toys come alive and have a blast doing so"、
metadata={"year":1995年, "genre": "ジャンル":"animated", "rating":9.3 }),
# ニモを見つける
Document(page_content="お父さんが知的障害者のパートナーと組んで、息子を救うために歯科医のオフィスに侵入する。"、
metadata={"year":2003, "genre":ジャンル": "animated", "rating":8.2 }),
# 巨大な才能の耐え難い重さ
Document(page_content="Nicholas Cage plays Nicholas Cage in this movie about Nicholas Cage."、
metadata={"year":2022, "genre": "コメディ":"コメディ", "rating":7.0 }),
# ロード・オブ・ウォー
Document(page_content="ニコラス・ケイジは、好きなモデルと結婚できるだけのお金ができるまで銃を売る。そしてまた銃を売る、
metadata={"year":2005, "genre": "コメディ":「コメディ", "rating":7.6 }),
# ゴーストライダー
Document(page_content="ニコラス・ケイジは皮膚を失い、頭蓋骨に火をつける。そしてバイクに乗る、
metadata={"year":2007, "genre":"アクション", "評価":5.3 }),
]
LangChainとMilvusのためのセルフクエリーメタデータとセルフクエリーリトリーバーの定義
パズルの最初の2つのステップが終わった。
まず、インジェスト用のベクターデータベースをセットアップしよう。LangChainのMilvus実装を使って文書を取り込み、既存の文書に基づいてベクターデータベースを作成します。このステップでは、前回作成したembeddings変数を使った埋め込み関数が活躍します。比較ステートメントでは、データ検索プロセスを導くフィルター条件を作成するために必要な特定のフォーマットやガイドラインを考慮します。
connection_argsパラメータはMilvusに接続するために必要な唯一のパラメータである。このチュートリアルでは、collection_nameパラメータも使用して、データを格納するコレクションに名前を割り当てます。Milvusの各コレクションには名前が必要です。デフォルトでは、LangChainはLangChainCollection` を使用します。
vector_store = Milvus.from_documents(
docs、
embedding=embeddings、
connection_args={"host":"localhost", "port": default_server.listen_port}、
コレクション名="映画"
)
次に、AttributeInfo機能を使ってメタデータ情報を定義し、LangChainが何を期待されているかを知るようにします。ここではデータの属性情報のリストを作成します。各属性の名前、説明、データ型を指定します。ここで論理条件文がクエリ構築プロセスにおける比較や論理演算に不可欠となります。
metadata_field_info = [
属性情報(
name="genre"、
description="映画のジャンル"、
type="文字列"、
),
属性情報(
name="年"、
description="映画が公開された年"、
type="整数",)、
),
属性情報(
name="評価"、
description="映画の1~10の評価"、
type="float"
),
]
最後に、ドキュメントの記述、LLMの初期化、セルフ・クエリー・リトリーバーの定義を行う。from_llm'メソッドを呼び出すことで、セルフクエリーリトリーバーを定義する。このメソッドを使って、LLM、ベクターストア、ドキュメントの内容記述、メタデータフィールド情報を接続しなければならない。この例では、'verbose = True' を設定して、このセルフクエリーリトリーバーの冗長出力を有効にしています。クエリー文字列には、ドキュメントの内容にマッチする関連テキストのみを含めるようにし、フィルター内の条件は明確に分離され、クエリー文字列自体に含まれないようにします。
document_content_description = "映画の簡単な要約"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm, vector_store, document_content_description, metadata_field_info, verbose=True
)
セルフクエリの結果
セルフ・クエリー・リトリーバーのセットアップは終わった。では、実際にどのように動作するか見てみましょう。この例では、ニコラス・ケイジに関連する3つの映画の説明を使いました。ニコラス・ケイジに関する映画は?
# この例では関連するクエリのみを指定しています
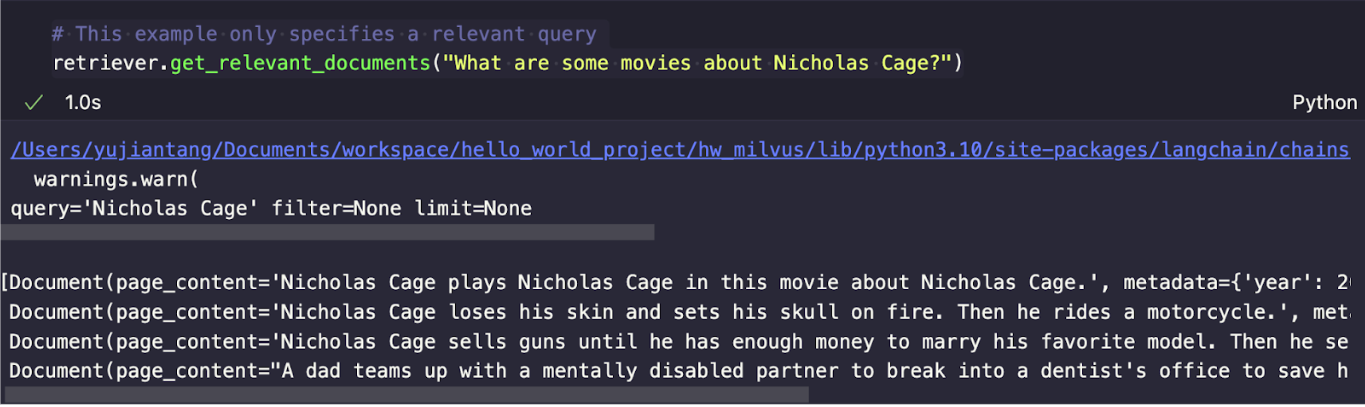
retriever.get_relevant_documents("ニコラス・ケイジについての映画は?")
以下のような出力が得られるはずです。
!langchain-query-vector-database.png
verbose=Trueを設定することで、クエリ、フィルタ、制限を見ることができます。LLMはクエリを "What are some movies about Nicholas Cage? "から "Nicholas Cage "に変換します。結果を見ると、上位3つの結果はすべてニコラス・ケイジが出演している映画であることがわかる。しかし、4番目の結果である「ファインディング・ニモ」は、4つの結果を取得するようにパラメータが設定されているため、無関係です。
このコード・ウォークスルーで、ベクトル・データベースのセルフ・クエリのコンセプトが理解できたと思います。LangChainのウェブサイトでは、セルフクエリとはLLMがベクターストアを利用して自分自身をクエリする方法と説明されています。つまり、LangChainは、CVPフレームワークの中に、セルフクエリ機能を含むシンプルな検索拡張生成(RAG)アプリを開発しているのです。
このチュートリアルでは、基礎となるベクトルストアとしてMilvusを使い、LangChainのセルフクエリ機能を探りました。セルフクエリを使うと、LLMとベクトルデータベースを組み合わせてシンプルなRAGアプリを作ることができます。LLMは自然言語クエリを文字列に分解し、クエリ用にベクトル化します。
この例では、映画に関するサンプルデータを生成しました。この例を発展させる1つの方法は、データを収集することです。セルフクエリ・リトリーバを定義する際には、ベクターストアとメタデータの両方の記述を忘れないようにしましょう。
LangChainのセルフクエリ機能を試してみたい方は、colab notebookを参照してください。
論理演算文によるベクターストアへの問い合わせ
ベクターストアに問い合わせをするとき、論理演算文を使って文書をフィルタリングする条件を指定します。論理演算文はop(statement1, statement2, ...)の形をとり、opはAND、OR、NOTなどの論理演算子です。compはEQ、LT、GTなどのコンパレータで、attrとvalはそれぞれ比較される属性と値です。
例えば、論理演算文は次のようになります:AND(EQ(language, "English"), GT(rating, 4))。論理演算文を使うことで、複数の条件を組み合わせた複雑なクエリを作成することができ、ベクターストアのドキュメントをより正確にフィルタリングすることができます。
ユーザーのクエリを処理する
ユーザがクエリを入力すると、セルフ・クエリ・リトリーバはクエリ・コンストラクタを使用して構造化クエリを生成します。構造化クエリはベクトルストア・クエリに変換され、ベクトルストア上で実行されて関連ドキュメントを取得します。クエリコンストラクタは、プロンプトと出力パーサを使用して、ユーザが指定したフィルタを取り込んだ構造化クエリを生成する。
例えば、ユーザが "Find movies with a rating greater than 4 and a runtime less than 2 hours "というクエリを入力した場合、クエリコンストラクタは次のような構造化クエリを生成します:AND(GT(rating, 4), LT(runtime, 120)).この構造化クエリは、ベクトルストア・クエリに変換され、ベクトルストア上で実行され、関連ドキュメントを検索する。このようにユーザーのクエリを処理することで、セルフ・クエリ・リトリーバは、ユーザーの特定の要求に合わせた結果を保証する。
ベストプラクティスと結論
セルフ・クエリー・レトリバーを使用する際には、正確で適切な結果を得るためにベスト・プラクティスに従うことが重要です。以下はそのヒントです:
クエリーを入力する際は、具体的かつ簡潔な言葉を使用すること。
文書をフィルタリングする条件を指定するには、論理演算文を使用します。
属性と値を比較するために比較文を使用する。
完全一致を指定するにはEQコンパレータを使用してください。
LT および GT コンパレータを使用して範囲クエリを指定します。
AND および OR 論理演算子を使用して条件を組み合わせます。
結論として、セルフ・クエリー・リトリーバーは、様々なソースから情報を取得して処理できる会話AIモデルを構築するための強力なツールである。論理演算ステートメントと比較ステートメントを使用することで、ユーザーは複雑なクエリを指定し、ベクトルストアから関連ドキュメントを取得することができる。ベスト・プラクティスに従い、セルフ・クエリ・リトリーバを効果的に使用することで、開発者はユーザーの幅広いクエリに対応できる、より正確で関連性の高いAIモデルを構築することができる。

{kind=link}
読み続けて

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.