




AIを使ってセレブ・スタイリストを探す(前編)
この記事は【AIアクセラレーター・インスティテュート】(https://www.aiacceleratorinstitute.com/using-ai-to-find-your-celebrity-stylist/)のウェブサイトに掲載されたもので、許可を得てここに再掲載している。
私は講演中にピンクのパンツをはくのが大好きで、それが私のシグネチャールックのひとつになっている。何本も持っているので、ファッションやスタイルについて多くの議論を巻き起こしてきた。最近、私は "ファッションAI "と呼ばれるプロジェクトに参加している。そして、ラベル付けされた各記事を切り出し、画像を同じサイズにリサイズする。最後に、これらの画像から生成された埋め込みをMilvusに保存します。Milvusは、オープンソースのベクトルデータベースで、何十億ものベクトル埋め込みを保存し、クエリすることができます。
私たちのデータベースで最も一致する記事を見つけるために、同じベクトルに沿って画像とクエリに同じ変換を適用する。それぞれのクエリに対して、このプロジェクトは3つの結果を返します。あなたは自分の好みに基づいて結果を解釈することができます。また、どの有名人があなたに最も近いか判断することもできます。最も一般的な1位、最も低い集計距離、または全体的に最も一般的なものを選ぶことができます。
画像はこちらから](https://drive.google.com/file/d/1pBO02iLgToBSCOyMJ58zWHQf4ZRkP5AY/view?usp=drive_link)。画像に加えて、アップグレードされた Python のバージョンと pip install milvus pymilvus torch torchvision matplotlib が必要です。画像セグメンテーションと埋め込みには、Hugging FaceのMateusz Dziemianのclothing segmenter modelと、PyTorchのNvidiaのResNet50モデルを使います。
この投稿では、ファッションアイテムの画像セグメンテーションを生成し、画像データをMilvusに追加し、あなたのドレスがどの有名人に最も似ているかを調べる方法について説明します。
ファッションアイテムの画像セグメンテーション
画像セグメンテーションを行うために、Hugging Faceで3つのモデルを見つけました。
Mateusz Dziemian](https://huggingface.co/mattmdjaga)によるsegformer_b2_clothes。
Valentina Feruere](https://huggingface.co/valentinafeve)によるYOLOS-Fashionpedia
Patrick John Chia](https://huggingface.co/patrickjohncyh)によるFashion-CLIPモデル。
私は最終的に「segformer」モデルを選んだ。これは、さまざまな衣服の正確なセグメンテーションを提供し、18種類の "オブジェクト "を識別する。例えば、あらゆる種類のトップスの「上着」、「ドレス」、「左の靴」、「右の靴」、「帽子」、その他多くの衣類を検出する。さらに、"顔"、"髪"、"右足"、"左足 "なども検出できる。18種類のオブジェクト・タイプの完全なセットはこちらでご覧いただけます。
このプロジェクトでは、画像操作に必要なパッケージをインポートすることから始める。特徴抽出のための torch、transformers の segformer オブジェクト、matplotlib、そして Resize、masks_to_boxes、crop などの torchvision インポートが含まれる。
インポートトーチ
from torch import nn, tensor
from transformers import AutoFeatureExtractor, SegformerForSemanticSegmentation
import matplotlib.pyplot as plt
from torchvision.transforms import Resize
import torchvision.transforms as T
from torchvision.ops import masks_to_boxes
from torchvision.transforms.functional import crop
Hugging Faceでセグメンテーションマスクを生成する
画像のセグメンテーションには、使用するモデルや検出するものによって、さまざまなアプローチがあります。この例では、モデルは、背景を含む各オブジェクトタイプに対して1つずつ、18レイヤーの画像を返します。最初に書くべき関数は、この画像を生成する関数です。
get_segmentation`関数は、特徴抽出器、モデル、画像の3つのパラメータを必要とする。まず、画像と抽出器を用いて入力特徴を生成します。次に、モデルの出力を取得し、ロジットに変換する。その後、PyTorchのバイリニア補間によりロジットをアップサンプリングします。最後に、この関数は、セグメンテーションマスクを作成するために、アップサンプリングされたサンプルの各ピクセルの最大予測値のみを取り出します。
def get_segmentation(extractor, model, image):
入力 = extractor(images=image, return_tensors="pt")
出力 = model(**inputs)
logits = outputs.logits.cpu()
upsampled_logits = nn.functional.interpolate(
logits、
size=image.size[::-1]、
mode="bilinear"、
align_corners=False、
)
pred_seg = upsampled_logits.argmax(dim=1)[0].
return pred_seg
参考までに、upsampled_logits の画像は以下のようになる:
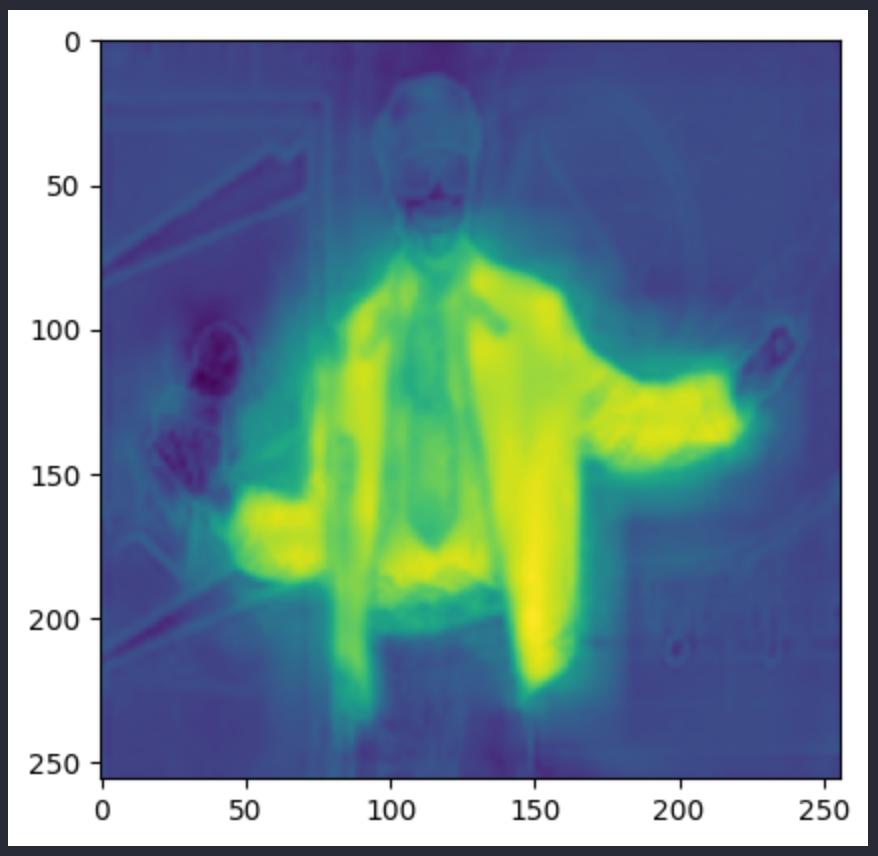
一方、pred_seg画像は次のようになる:(これらは2つの異なる画像だが、どちらもアンドレ3000の画像である)。
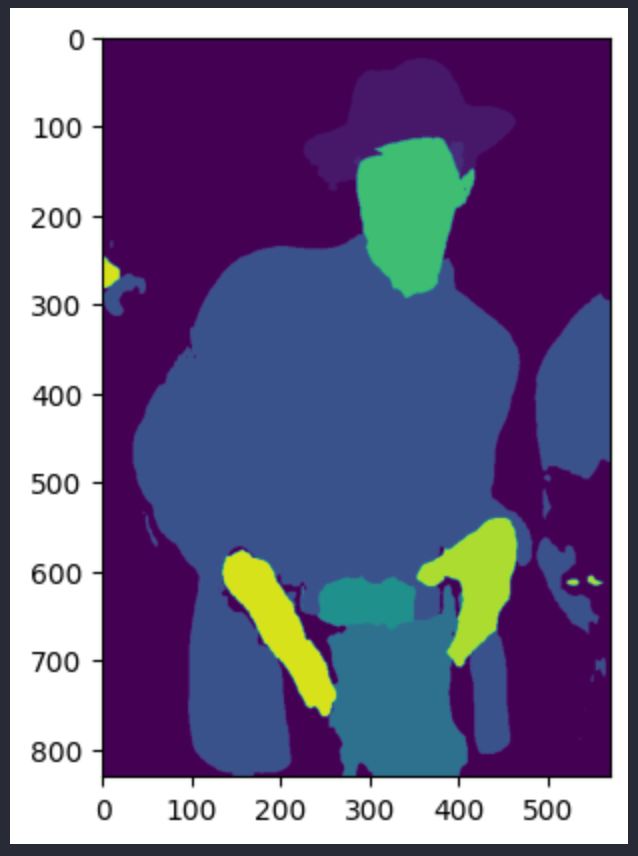
セグメンテーションマスクの取得は、ここからは簡単である。セグメンテーションのユニークな値をすべて取得する。背景を表す最初のエントリーは破棄する。マスクを作成するために、セグメンテーションの中からオブジェクト ID と同じ値を持つピクセルを抽出する。この関数は、マスクと ID の両方を返すようにして、両方を追跡できるようにしている。
# masks (tensor) と obj_ids (int) の2つのリストを返す。
# "mattmdjaga/segformer_b2_clothes" from hugging face
def get_masks(segmentation):
obj_ids = torch.unique(segmentation)
obj_ids = obj_ids[1:].
masks = segmentation == obj_ids[:, None, None].
return masks, obj_ids
この関数は、次のようなマスクを作成します(髪と上半身の服のマスクを示しています):

Pytorch 変換を使って画像を切り抜き、リサイズする
これで get_masks 関数のマスクとオブジェクトのアイデア、および元の画像を使用して、検出されたオブジェクトごとに新しい画像を作成できるようになりました。次に、先ほど torchvision.ops からインポートした masks_to_boxes 関数を呼び出して、作成したマスクをバウンディングボックスに変換します。
次に、切り抜くボックスのリストを作成し、ボックスの座標系を crop 座標系に変換する。ボックスは (x1, x2, y1, y2) 形式の値として返される。一方、 crop 関数は (top, left, height, width) という形式の入力を期待する。
画像を切り抜く前に、前処理関数も定義する。各画像のサイズを256x256に変更し、PyTorchテンソル(現在はPIL Images)に変換します。次は画像を切り抜く番です。クロップボックスをループし、先ほど取得した値を使って crop 関数を呼び出します。そして、セグメンテーションIDのキーに対応する値として、前処理済みの画像を辞書に追加します。関数の最後に、この辞書を返します。
def crop_images(masks, obj_ids, img):
boxes = masks_to_boxes(masks)
crop_boxes = [].
for box in boxes:
crop_box = tensor([box[0], box[1], box[2]-box[0], box[3]-box[1])
crop_boxes.append(crop_box)
preprocess = T.Compose([)
T.Resize(size=(256, 256))、
T.ToTensor()
])
cropped_images = {}.
for i in range(len(crop_boxes)):
crop_box = crop_boxes[i].
cropped = crop(img, crop_box[1].item(), crop_box[0].item(), crop_box[3].item(), crop_box[2].item())
cropped_images[obj_ids[i].item()] = preprocess(cropped)
return cropped_images
以下は、火出力でDrakeを使用するために切り抜き、別々の画像を作成するボックスの例です。

画像データをベクターデータベースに追加する
さて、すべての画像の分割とトリミングが終わったので、それらをベクトルデータベースであるMilvusに追加してみましょう。Milvusをすぐに使い始めるために、この例ではMilvusの軽量版であるMilvus Liteを使ってノートブック上でMilvusのインスタンスを実行します。そして、Milvus Liteが提供するデフォルトのサーバに接続するために pymilvus を使用する。
また、このセクションでいくつかの定数を設定する。ベクトルの次元数(Nvidia ResNet50モデルから)、バッチサイズ、コレクションの名前、返す結果の数を定義する。最後に ssl 関数を実行して、PyTorch からモデルを取得するための検証されていないコンテキストを作成します。
from milvus import default_server
from pymilvus import utility, connections
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
ディメンション = 2048
バッチサイズ = 128
COLLECTION_NAME = "ファッション"
TOP_K = 3
# SSL証明書のURLErrorが発生した場合は、resnet50モデルをインポートする前にこれを実行してください。
インポートssl
ssl._create_default_https_context = ssl._create_unverified_context
ベクターデータベースにメタデータを格納するためのスキーマの定義
ステップ1:スキーマを定義する。スキーマはベクターデータベースに保存されたデータを整理するために使用されます。id`フィールドはSQLやNoSQLデータベースにおける通常のキーIDであり、他のフィールドはデータ型(int64、varchar、floatなど)にSQLライクな定義がある。
この例では、ファイルパス、有名人の名前、セグメンテーション ID をメタデータとして保存します。将来的には、バウンディングボックスやマスクの位置など、さらにフィールドを追加する可能性がある。FieldSchemaを定義したら、CollectionSchemaを定義し、与えられたスキーマとコレクション名に基づいてMilvusでコレクションを作成する。
コレクションができたので、インデックスを定義しよう。インデックスパラメータは基本的なものである。ここではIVF Flatを使用し、セントロイドは128個、距離メトリックはL2を使用します。コレクションにインデックスを作成し、embeddingフィールドを操作するフィールドに指定する。そして、コレクションをメモリにロードして、操作できるようにする。
from pymilvus import FieldSchema, CollectionSchema, Collection, DataType
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True)、
FieldSchema(name='filepath',dtype=DataType.VARCHAR,max_length=200)、
FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=200)、
FieldSchema(name="seg_id", dtype=DataType.INT64)、
FieldSchema(name='embedding',dtype=DataType.FLOAT_VECTOR,dim=DIMENSION))。
]
schema = CollectionSchema(fields=fields)
コレクション = コレクション(name=COLLECTION_NAME, schema=schema)
index_params = { {インデックス・タイプ
「index_type":"IVF_FLAT"、
"metric_type":"L2",
「params":params": {"nlist":128},
}
collection.create_index(field_name="embedding", index_params=index_params)
コレクション.load()
NvidiaのResNet50からベクトル埋め込みを取得する
このセクションの最初のステップはモデルのロードです。NvidiaのResNet50モデルをPyTorchから読み込み、出力層を切り離します。ベクトル埋め込みは、モデルの最後から2番目の層の出力です。
# 最後の層を取り除いた埋め込みモデルを読み込む
embeddings_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_resnet50', pretrained=True)
embeddings_model = torch.nn.Sequential(*(list(embeddings_model.children())[:-1]))
embeddings_model.eval()
この関数はベクトルの埋め込みを受け取り、Milvusにデータを挿入します。この関数はデータ、コレクションオブジェクト、モデル(この場合は埋め込みモデル)の3つのパラメータを受け取ります。データをベクターデータベースに追加する際に、データがどのように操作されているかを追跡するために、いくつかのprint文を追加しました。
デバッグデータを表示することに加えて、data[0]のすべての値を1つのテンソルにスタックし、squeeze関数を使って出力からサイズ1の次元を削除する。次に、元のデータバッチの最後の3つのエントリと、リストに変換された出力テンソルからなる新しいリストを挿入する。これらはファイルのパス、名前、セグメンテーションID、2048次元の埋め込みに対応する。
def embed_insert(data, collection, model):
with torch.no_grad():
print(len(data[0]))
print(data[0][0].size())
出力 = model(torch.stack(data[0])).squeeze()
print(type(output))
print(len(output))
print(len(output[0]))
print(output[0])
collection.insert([data[1], data[2], data[3], output.tolist()])
印刷されたデータは下図のようになる。各データバッチのサイズは最後まで128で、各エントリのサイズは3x256x256です。出力は長さ128のPyTorchテンソルであり、出力の各エントリは長さ2048である。出力されるテンソルは、データバッチの最初のエントリからの出力です。
画像データをベクターデータベースに保存する
先ほど説明した抽出器とセグメンテーションモデルを覚えていますか?ここでそれらを使います。Hugging Faceのpre-trained segformerモデルを使います。モデルをロードした後、すべてのファイルパスをリストに入れてループさせます。
extractor = AutoFeatureExtractor.from_pretrained("mattmdjaga/segformer_b2_clothes")
model = SegformerForSemanticSegmentation.from_pretrained("mattmdjaga/segformer_b2_clothes")
import os
image_paths = [].
for celeb in os.listdir("./photos"):
for image in os.listdir(f"./photos/{celeb}/"):
# print(image)
image_paths.append(f"./photos/{celeb}/{image}")
Milvusは入力としてリストのリストを期待する。この例では、画像、ファイルパス、名前、セグメンテーションIDに対応する4つのリストを使用します。embed_insert`関数では、画像をベクトル埋め込みに変換する。次に、画像のファイルパスをループし、セグメンテーションマスクを収集し、画像を切り出します。最後に、画像をメタデータとともにデータバッチに追加する。
128枚ごとに画像を埋め込み、Milvusに挿入し、データバッチを消去する。ループの最後に、残りのデータバッチをMilvusに埋め込んで挿入し、それをフラッシュしてインデックス作成を完了する。16GBのRAMを搭載したM1 2021 Macでは、この処理に約8分かかる。
from PIL import Image
data_batch = [[], [], [], []]。
for path in image_paths:
image = Image.open(パス)
path_split = path.split("/")
name = ".join(path_split[2].split("_"))
セグメンテーション = get_segmentation(extractor, model, image)
masks, ids = get_masks(segmentation)
cropped_images = crop_images(masks, ids, image)
for key, image in cropped_images.items():
data_batch[0].append(image)
data_batch[1].append(path)
data_batch[2].append(name)
data_batch[3].append(key)
if len(data_batch[0]) % BATCH_SIZE == 0:
embed_insert(data_batch, collection, embeddings_model)
data_batch = [[], [], [], []]。
if len(data_batch[0]) != 0:
embed_insert(data_batch, collection, embeddings_model)
collection.flush()
どの有名人に一番似ているか調べてみよう
このセットアップでできることはたくさんある。あなたのファッションの選択をマッチングし、評価するための追加の方法は、次の作品で紹介する予定です。この例では、セグメント化された各服飾品に基づいて上位3枚の写真を取得する。テイラー・スウィフトの例をいくつか使い、完璧な想起を得る。
入力画像に対する埋め込みを生成する
画像をデータベースに読み込む方法と同様に、入力画像を処理する必要があります。検索画像を埋め込む関数は、データと(埋め込み)モデルの2つのパラメータをとります。埋め込みモデルを用いて埋め込み画像を取得し、クエリされた画像の数に応じて平坦化または圧縮し、リストに変換して返します。
def embed_search_images(data, model):
with torch.no_grad():
print(len(data[0]))
print(data[0][0].size())
出力 = model(torch.stack(data))
print(type(output))
print(len(output))
print(len(output[0]))
print(output[0])
if len(output) > 1:
return output.squeeze().tolist()
それ以外の場合
return torch.flatten(output, start_dim=1).tolist()
embed_insert関数と同様に、ここではデータを追跡するためにいくつかのprint文を追加した。以下に示すように、embed_insert関数と比較して、この関数に渡されるdataは基本的にdata[0]`オブジェクトである。
データベースに問い合わせるために必要なのは、Milvusに画像を追加したときと同じような方法で得られる埋め込みベクトルだけです。しかし、後で比較しやすくするために、これらの他の変数をメモリ上に保持しておくと便利です。
# data_batch[0] はテンソルのリストである。
# data_batch[1] は画像のファイルパス(文字列)のリストである。
data_batch[2] は画像に写っている人物の名前のリスト(文字列) # data_batch[3] はテンソルのリストである。
# data_batch[3]はセグメンテーションキーのリスト (int)
data_batch = [[], [], [], []]。
search_paths = ["./photos/Taylor_Swift/Taylor_Swift_3.jpg", "./photos/Taylor_Swift/Taylor_Swift_8.jpg"].
for path in search_paths:
image = Image.open(パス)
path_split = path.split("/")
name = ".join(path_split[2].split("_"))
セグメンテーション = get_segmentation(extractor, model, image)
masks, ids = get_masks(segmentation)
cropped_images = crop_images(masks, ids, image)
for key, image in cropped_images.items():
data_batch[0].append(image)
data_batch[1].append(path)
data_batch[2].append(name)
data_batch[3].append(key)
embeds = embed_search_images(data_batch[0], embeddings_model)
ベクターデータベースに問い合わせる
埋め込みができたので、データベースにクエリをかけることができる。面白半分に、クエリにかかる時間を追跡するために time モジュールを追加します。この例では、2048次元のベクトル23個に対するクエリ時間を計測しています。Milvusに問い合わせるには、上記で生成した埋め込みデータを使って search 関数を使うだけです。
import time
start = time.time()
res = collection.search(embeds、
anns_field='embedding'、
param={"metric_type":"L2",
「params":params: {"nprobe":10}},
limit=TOP_K、
output_fields=['filepath'])
finish = time.time()
print(finish - start)
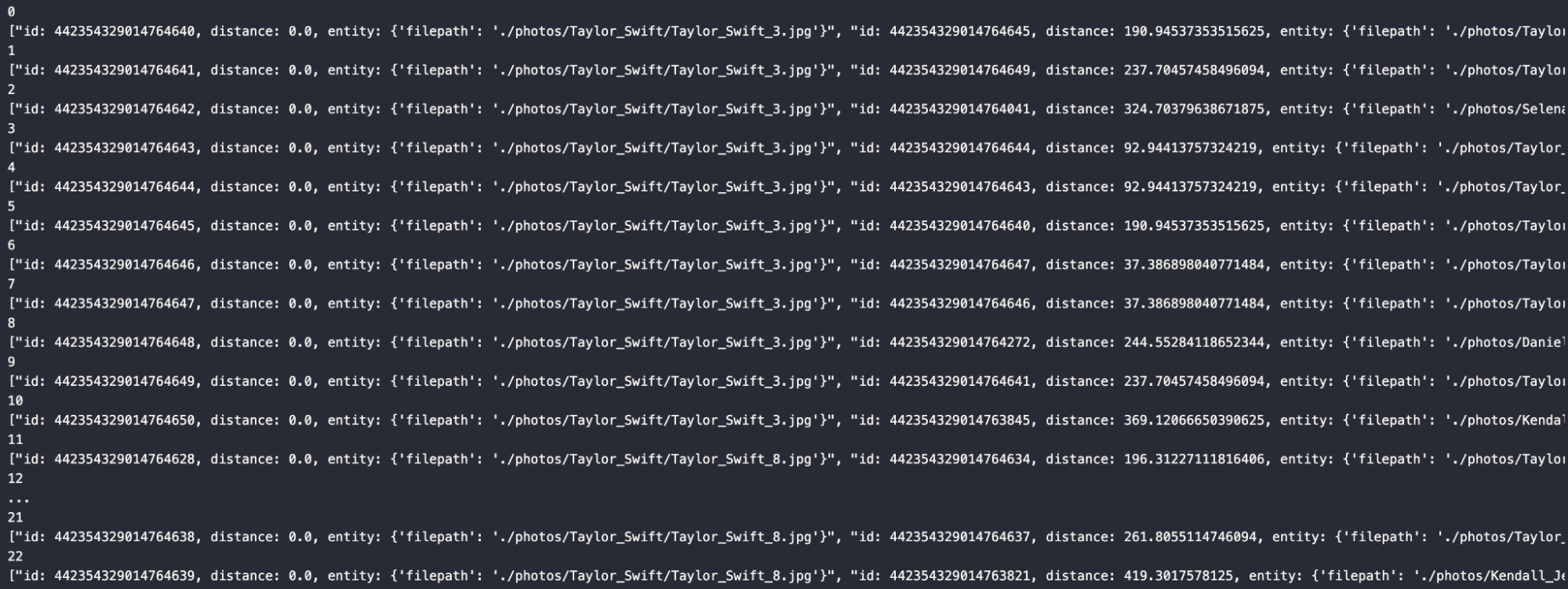
結果をループした後、生成されたレスポンスを見ることができる。
for index, result in enumerate(res):
print(index)
print(result)
要約
このセクションは以上です。これで、自分自身や友達(許可を得て!)の画像を、テイラー・スウィフト、ドレイク、アンドレ3000などの有名人と比較する準備が整いました。これを行うには、Hugging Faceで見つけたモデルを使用して、画像内の衣服のセグメンテーションを取得することから始めます。
セグメンテーションを手に入れたら、画像からそれぞれのユニークなセグメンテーションを取り出し、別々の画像に切り抜く。切り出した画像をベクトルデータベースに入れる前に、リサイズしてテンソルにします。そして、NvidiaのResNet50埋め込みモデルを通して、保存するベクトル埋め込みを得る。
クエリーは、ベクトルの読み込みと同様の手順で行う。この例では、クエリー結果を取得するところまでしか行っていない。さらに進めるには、バウンディングボックスまたはマスクをベクターデータベースに保存し、特定のマッチングを表示するためにそれらを引き出す。あるいは、入力画像をもう一度モデルに通し、同じことをする。すべてローカルで行うので、ローカルメモリを使うことができる。
いかがでしたか?お気軽にconnect with meまでご連絡ください。また、どの有名人に一番似ているか教えてください!
このシリーズのパート2](https://zilliz.com/blog/use-ai-find-your-celebrity-style-two)もお忘れなく!

読み続けて

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.