




MilvusとAirbyteを使用してすべてのデータの類似性検索を行う
Milvusは人気のあるオープンソースのベクトルデータベースです。ベクトルは数値の高次元配列です。大規模言語モデル(Large Language Models: LLM)を扱う場合、「埋め込み」は特に、変換ベースのディープ・ニューラル・ネットワークのエンコーダー・コンポーネント内の最後の隠れ層を指す。この埋め込み層は、単語やピクセル(テキストや画像)の意味的な意味を表すベクトルの集合である。
訓練されたLLMの埋め込み層に豊富な情報があることを考えると、ベクトルの効率的な保存と検索が重要になってくる。Milvusは、高次元ベクトルデータの格納、インデックス付け、効率的な検索を目的としたベクトルデータベースです。ベクトルデータベースは通常、非構造化データ全体の類似性検索に使用され、ジェネレーティブチャットレスポンス、製品レコメンデーション、その他のアプリケーションの改善を可能にします。
Airbyte](https://airbyte.com/)を使用することで、様々なソースからMilvusにデータを転送し、その過程でテキストのベクトル埋め込みを計算することができます。
embeddings](https://zilliz.com/glossary/vector-embeddings)の威力は、たとえ似たような概念が異なる言い回しであったとしても、関連する情報の断片を検索できることです。この記事では、この機能を使って、関連する情報をその場で検索することで、ウェブサイトのサポートフォームをよりスマートにします。これは、すでに処理された類似のチケットについてユーザーに通知し、サポートエージェントの助けを借りずに問題を解決するのに役立つ関連するナレッジベースの記事をハイライトするために使用されます。
私たちは、ベクトルストアとしてZilliz Cloudを、データの抽出とロードにAirbyteを、エンベッディングの計算にOpenAIのエンベッディングAPIを、関連データを表示するスマートな送信フォームを構築するためにStreamlitを使用します。
必要なもの
Zendesk アカウント (または同期したい他のデータソース)
Airbyte アカウントまたはローカルインスタンス
OpenAI API キー
Zilliz CloudアカウントまたはローカルのMilvusクラスタ
ローカルにインストールされたPython 3.10
ステップ1: Milvusクラスタのセットアップ
cloud.zilliz.comでは、エンベッディング類似検索のためのベクトルを保存するためのクラスタを無料で登録することができます。アカウントを作成したら、新しいクラスタを設定します。
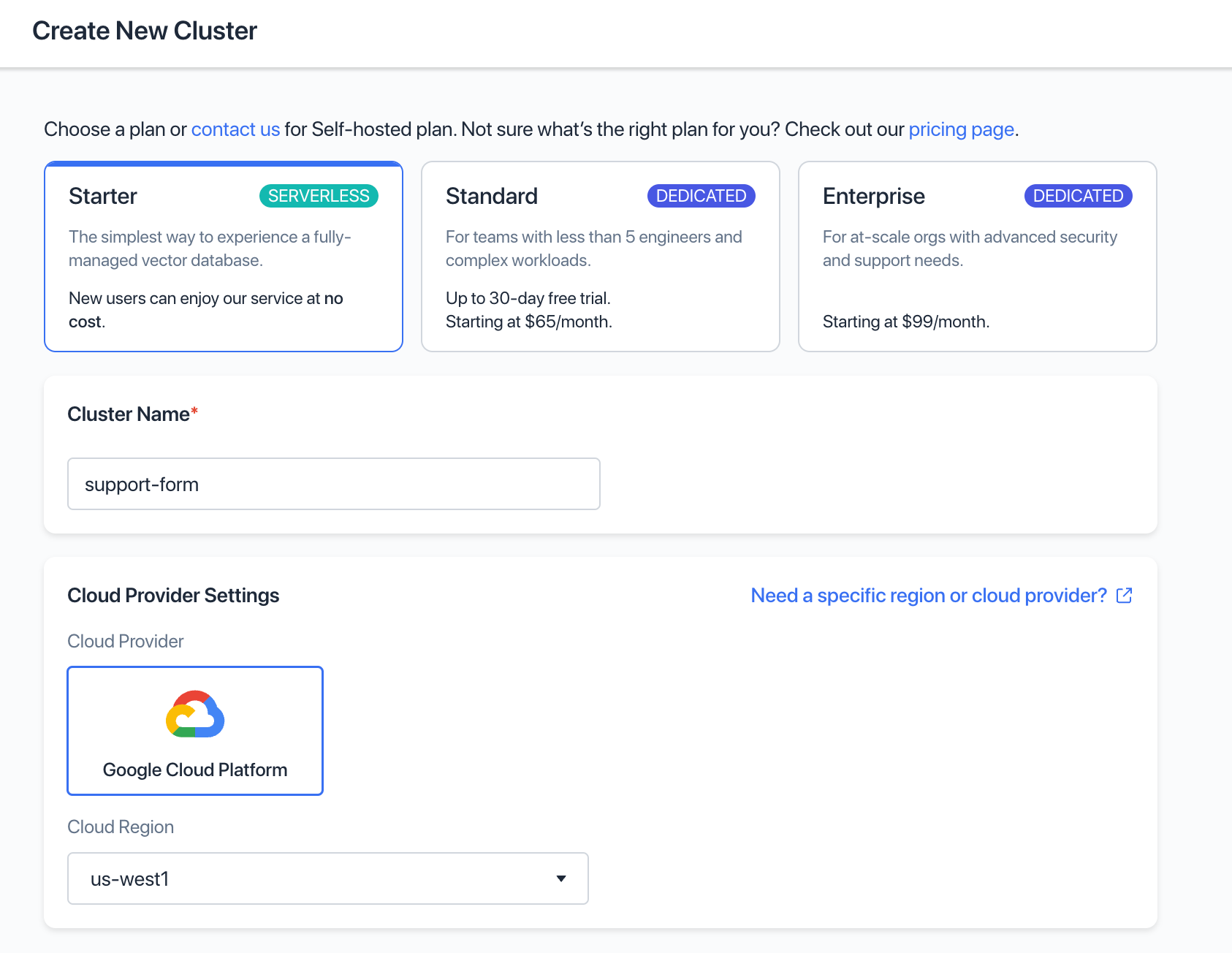
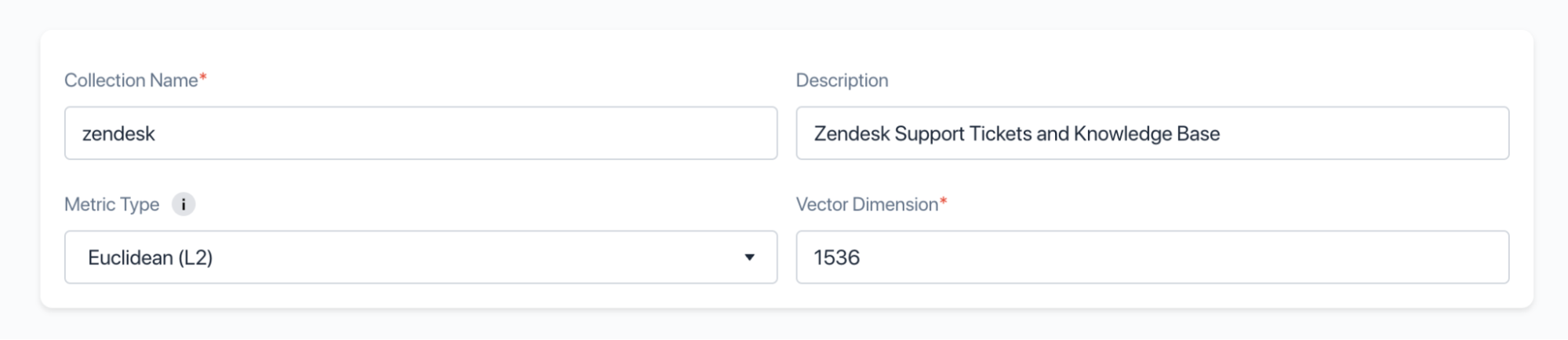
個々のエンティティ(我々の場合、サポートチケットとナレッジベースの記事)は、"コレクション "に保存されます - クラスタがセットアップされたら、コレクションを作成する必要があります。適切な名前を選び、OpenAIの埋め込みサービスによって生成されるベクトルの次元数に合わせて、Dimensionを1536に設定します:
作成後、ZillizはエンドポイントとAPIキーを表示します - 次のステップで必要になるので、これらを控えておいてください。
ステップ2: Airbyteで接続を設定する
データベースの準備ができたので、データを移行してみよう!そのためには、Airbyteで接続を設定する必要があります。cloud.airbyte.com](https://cloud.airbyte.com/)でAirbyteのクラウドアカウントにサインアップするか、ドキュメントの説明に従ってローカルインスタンスを立ち上げてください。
インスタンスを起動したら、接続を設定します。[新規接続]をクリックし、ソースとして "Zendesk Support "コネクタを選択します。
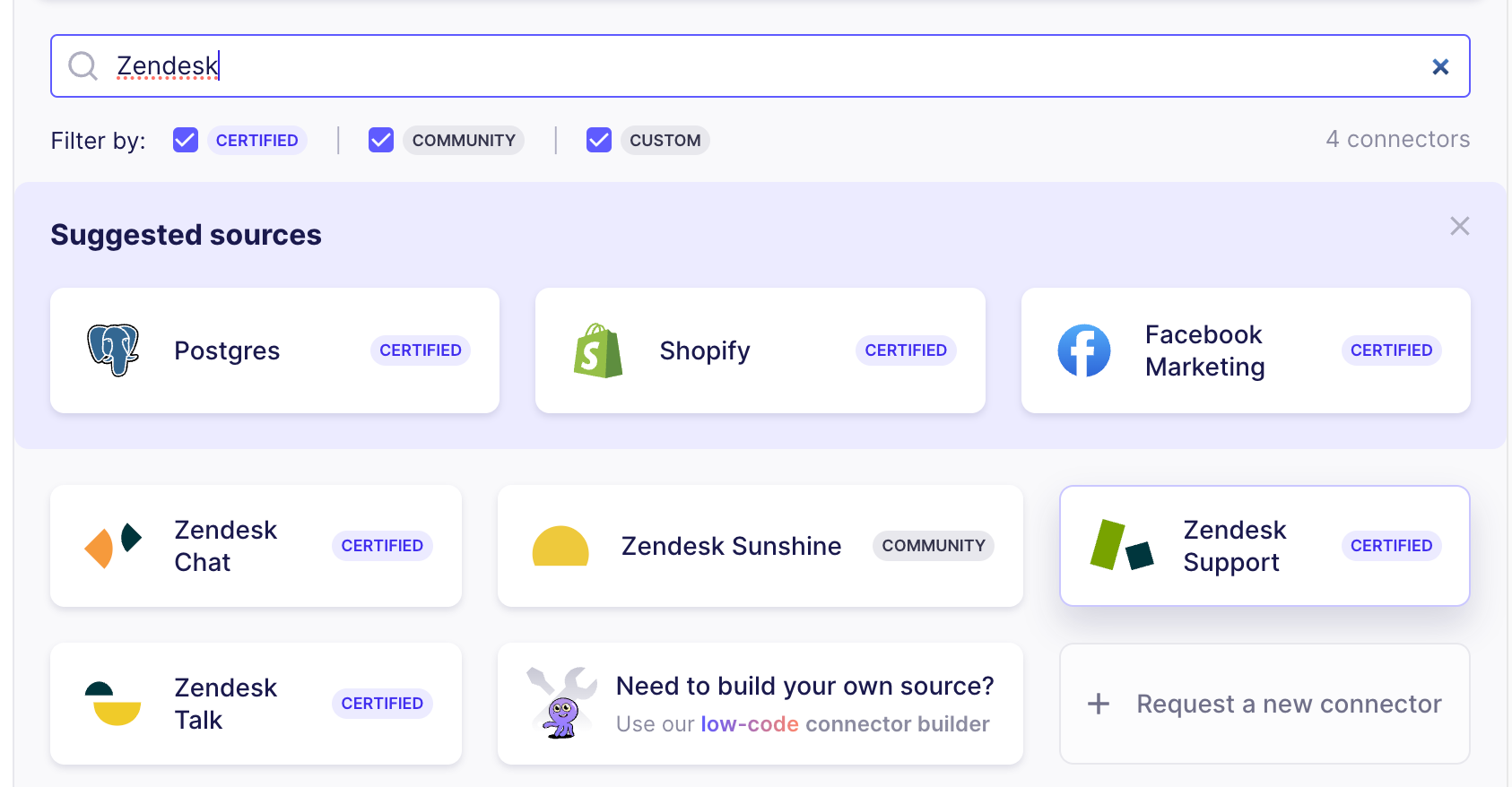
Airbyteクラウドでは、認証ボタンをクリックすることで簡単に認証ができます。ローカルのAirbyteインスタンスを使用する場合は、ドキュメントページの指示に従ってください。
情報::
他のデータソースを使用したい場合 - この記事の残りの部分は、あらゆる種類のテキストベースのソースに適用できます。
::
Test and Save "ボタンをクリックすると、Airbyteは接続が確立できるかどうかをチェックします。すべてが正常に動作していれば、次はデータの移動先を設定します。ここでは「Milvus」コネクタを選択します。
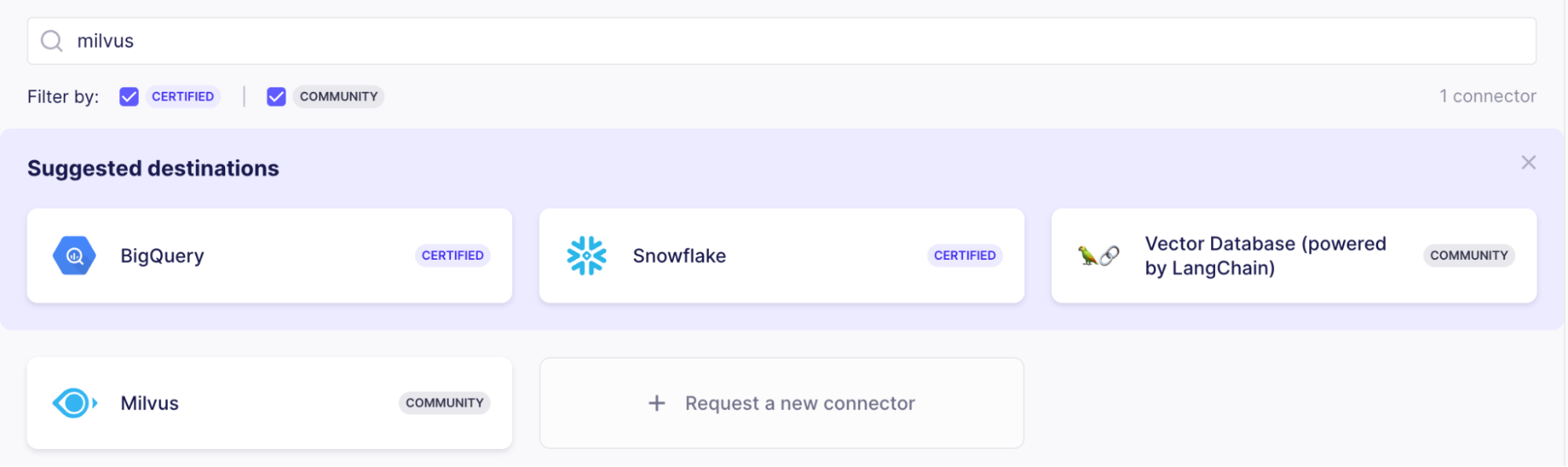
Milvusのコネクターには3つの役割がある:
チャンキングとフォーマット** - Zendesk レコードをテキストとメタデータに分割します。テキストが指定されたチャンクサイズより大きい場合、レコードは複数の部分に分割され、個別にコレクションにロードされます。テキストの分割(またはチャンキング)は、たとえば大規模なサポートチケットやナレッジ記事の場合に発生します。テキストを分割することで、検索が常に有用な結果をもたらすようにすることができます。
チャンクサイズを 1000 トークンとし、テキストフィールドを body、title、description、subject とします。
埋め込み** - 機械学習モデルを使用して、処理部で生成されたテキストチャンクをベクトルの埋め込みに変換します。埋め込みを作成するには、OpenAIのAPIキーを提供する必要があります。Airbyteは各チャンクをOpenAIに送信し、結果のベクトルをMilvusクラスタにロードされたエンティティに追加します。
インデックス作成** - チャンクをベクトル化したら、データベースにロードすることができます。これを行うには、Zillizクラウドでクラスタとコレクションをセットアップする際に得た情報を挿入します。
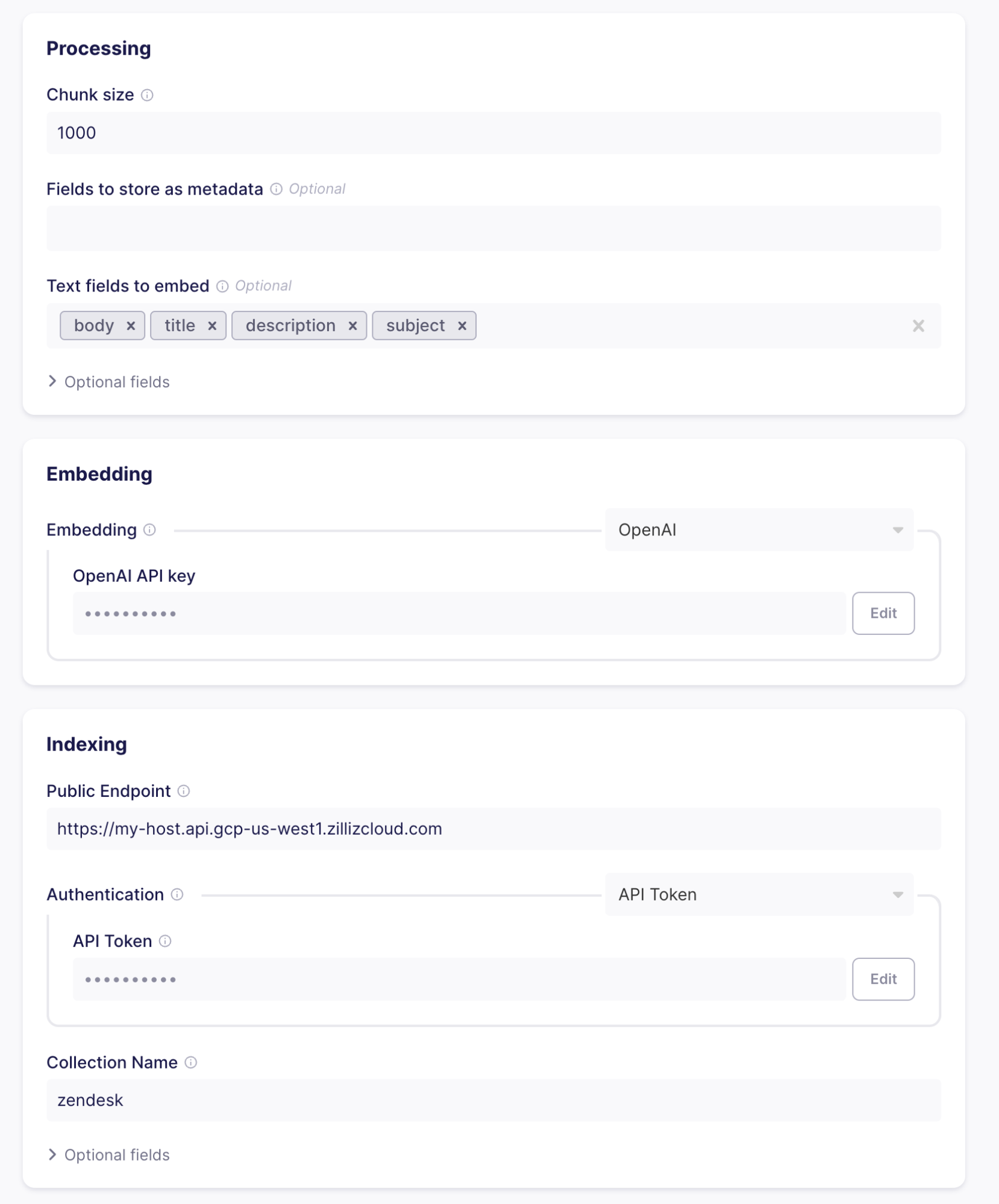
Test and save "をクリックすると、すべてが正しく並んでいるかどうかがチェックされます(有効な認証情報、コレクションが存在し、設定された埋め込みと同じベクトル次元を持っている、など)。
データを流す準備ができる前の最後のステップは、同期する "ストリーム "を選択することである。ストリームとは、ソース内のレコードの集まりです。Zendesk は、今回のユースケースには関係のない多数のストリームをサポートしているので、帯域幅を節約し、関連する情報だけが検索に表示されるようにするために、「チケット」と「記事」だけを選択し、他はすべて無効にしましょう:
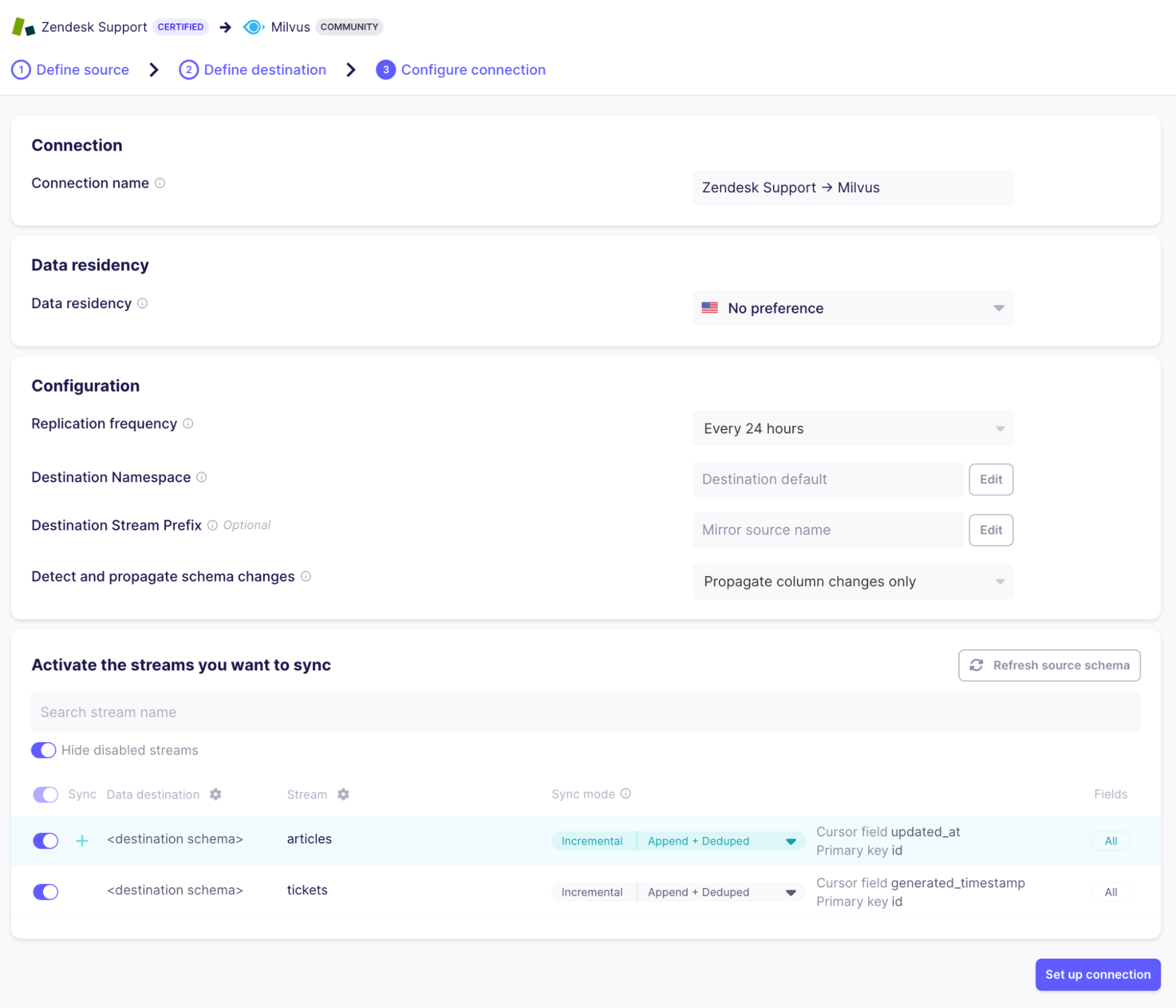
ストリーム名をクリックすることで、ソースから抽出するフィールドを選択できます。Incremental|Append+Deduped "同期モードは、ZendeskとMilvusが最小限のデータ(前回の実行以降に変更されたアーティクルとチケットのみ)を転送しながら同期を保つことを意味します。
接続が設定されるとすぐに、Airbyteはデータの同期を開始します。Milvusコレクションに表示されるまで数分かかる場合があります。
レプリケーションの頻度を選択した場合、Airbyteは定期的に実行され、Zendeskアーティクルの変更や新しく作成された課題に合わせてMilvusコレクションを最新の状態に保ちます。
ZillizのクラウドUIで、プレイグラウンドに移動し、"_ab_stream == "tickets" にフィルタを設定した "Query Data" クエリを実行することで、コレクション内のデータがどのような構造になっているかを確認できます。
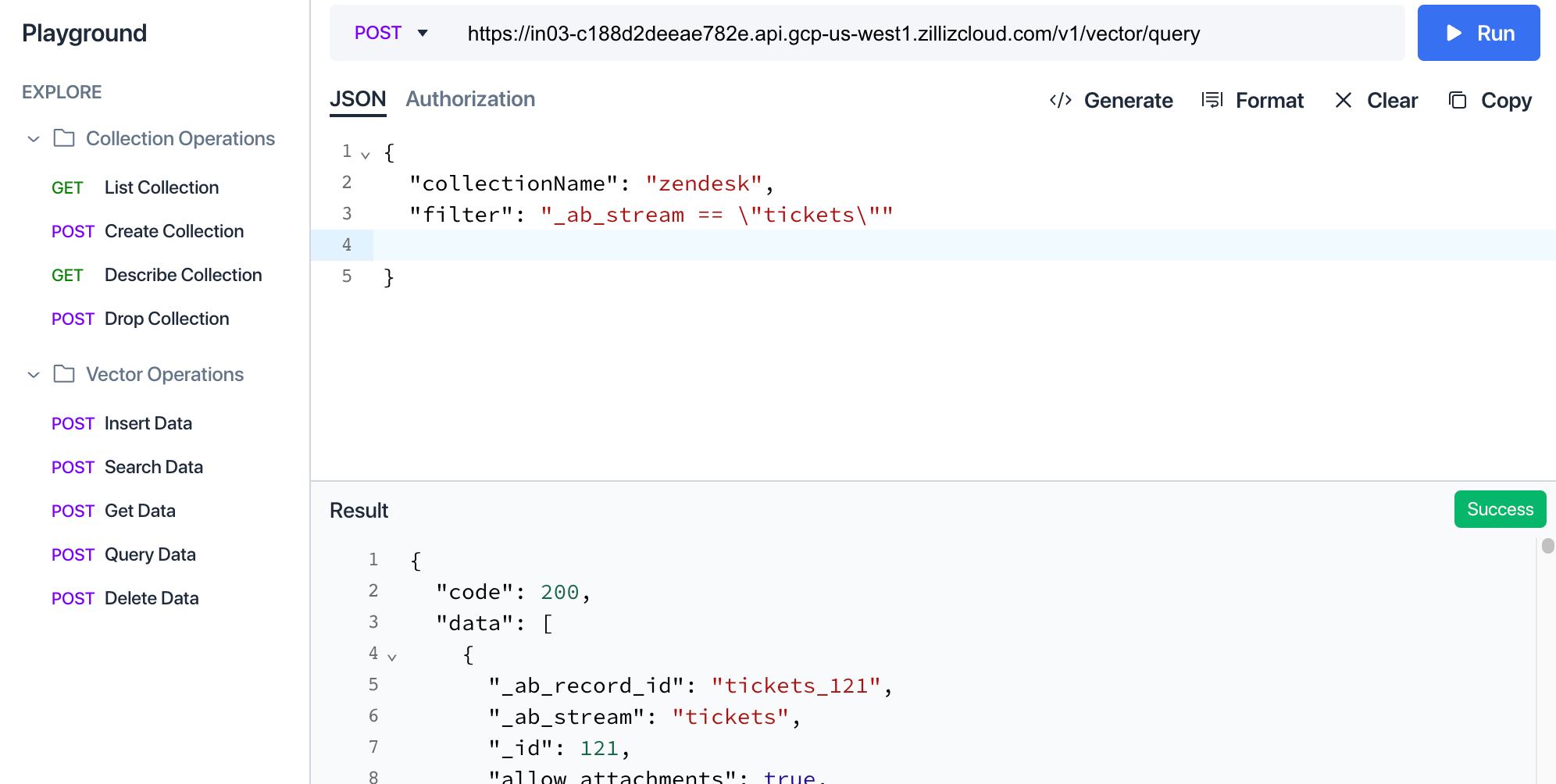
結果ビューを見るとわかるように、Zendeskから送られてきた各レコードは、指定されたすべてのメタデータとともにMilvusに個別のエンティティとして保存されています。埋め込みのベースとなったテキストチャンクは "text" プロパティとして表示されます。
ステップ3:コレクションを検索するStreamlitアプリのビルド
データの準備は整いました - 次はそれを使うアプリケーションを構築する必要があります。この場合、アプリケーションはユーザーがサポートケースを送信するためのシンプルなサポートフォームになります。ユーザーが送信をクリックすると、2つのことを行います:
同じ組織のユーザーによって提出された類似のチケットを検索します。
ユーザーに関連する可能性のあるナレッジベースの記事を検索します。
どちらの場合も、OpenAIの埋め込みを使ったセマンティック検索を活用する。そのために、ユーザが入力した問題の説明も埋め込まれ、Milvusクラスタから類似エンティティを検索するために使用される。関連する結果があれば、フォームの下に表示されます。
アプリケーションの実装にはStreamlitを使用するため、ローカルのPythonが必要です。
まず、Streamlit、Milvusクライアントライブラリ、OpenAIクライアントライブラリをローカルにインストールします:
pip install streamlit pymilvus openai
基本的なサポートフォームをレンダリングするために、python ファイル app.py を作成します:
stとしてstreamlitをインポートする
st.form("my_form"):
st.write("Submit a support case")
text_val = st.text_area("Describe your problem")
submitted = st.form_submit_button("送信")
if submitted:
# TODO 関連するサポートケースと記事をチェックする
st.write("Submitted!")
アプリケーションを実行するには、Streamlit runを使います:
streamlit run app.py
これで基本的なフォームがレンダリングされます:
この例のコードはGitHubにもあります。
次に、関連するかもしれない既存のオープンチケットをチェックしてみましょう。これを行うために、OpenAIを使ってユーザが入力したテキストを埋め込み、それからコレクションで類似検索を行い、まだオープンなチケットをフィルタリングします。もし、入力されたチケットと既存のチケットの間の距離が非常に低いものがあれば、ユーザに知らせて送信しないようにします:
インポート os
インポート pymilvus
インポート openai
org_id = 360033549136 # TODO 顧客のログインデータから読み込む
pymilvus.connections.connect(uri=os.environ["MILVUS_URL"], token=os.environ["MILVUS_TOKEN"])
コレクション=pymilvus.Collection("zendesk")
embedding = openai.Embedding.create(input=text_val, model="text-embedding-ada-002")['data'][0]['embedding'].
results = collection.search(data=[embedding], anns_field="vector", param={}, limit=5, output_fields=["_id", "subject", "description"], expr=f'ステータス == "new" and organization_id == {org_id}')
st.write(results[0]) # とりあえずデバッグ出力
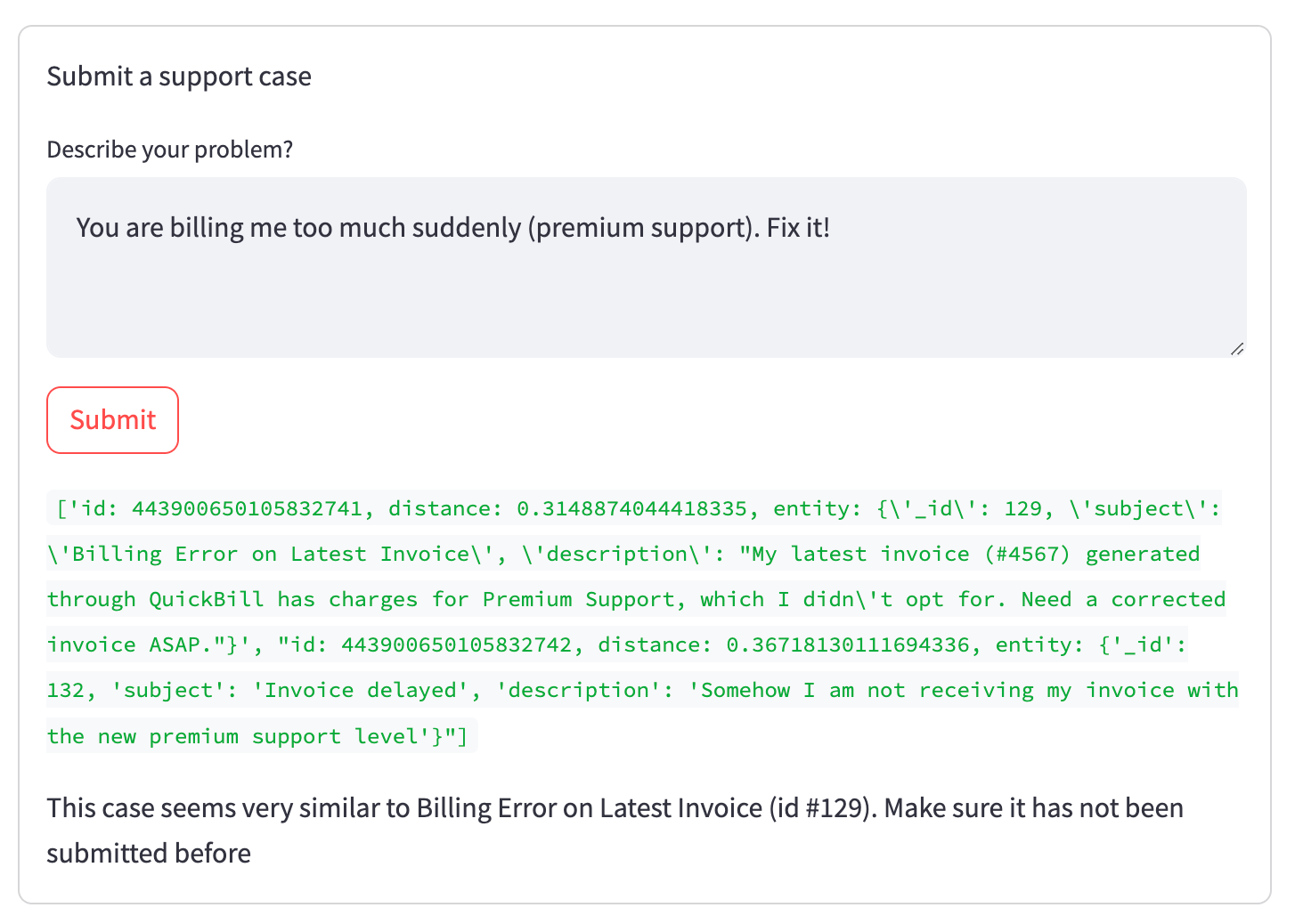
if len(results[0]) > 0 and results[0].distances[0] < 0.35:
matching_ticket = results[0][0].entity
st.write(f "このケースは{matching_ticket.get('subject')}(id #{matching_ticket.get('_id')})に非常に似ているようです。以前に提出されていないか確認してください")
else:
st.write("Submitted!")
ここでいくつかのことが起こっている:
Milvusクラスタへの接続がセットアップされている。
OpenAIサービスが、ユーザーが入力した説明文の埋め込みを生成するために使用されます。
類似検索が実行され、チケットのステータスと組織 ID によって結果がフィルタリングされます(同じ組織のオープンチケットのみが関連するため)。
結果があり、既存のチケットと新しく入力されたテキストの埋め込みベクトル間の距離がある閾値以下であれば、この事実を呼び出します。
新しいアプリを実行するには、まずOpenAIとMilvusの環境変数を設定する必要があります:
export MILVUS_TOKEN=...
export MILVUS_URL=https://...
export OPENAI_API_KEY=sk-...
streamlit run app.py
既に存在するチケットを投稿しようとすると、このようになります:
この例のコードはGitHubにもある。
最終バージョンに隠された緑色のデバッグ出力でわかるように、2つのチケットが検索にマッチしました(ステータスが新しく、現在の組織からで、埋め込みベクトルに近い)。しかし、最初のチケット(関連)は2番目のチケット(この状況では無関係)より上位にランクされ、それは低い距離値に反映されています。この関係は、通常の全文検索のように直接単語をマッチングさせることなく、埋め込みベクトルに取り込まれる。
最後に、チケットの提出後に役立つ情報を表示して、ユーザにできるだけ多くの関連情報を前もって与えましょう。
そのために、チケットが送信された後に2回目の検索を行い、上位にマッチするナレッジベースの記事を取得します:
article_results = collection.search(data=[embedding], anns_field="vector", param={}, limit=5, output_fields=["title", "html_url"], expr=f'_ab_stream == "articles"')
st.write(article_results[0])
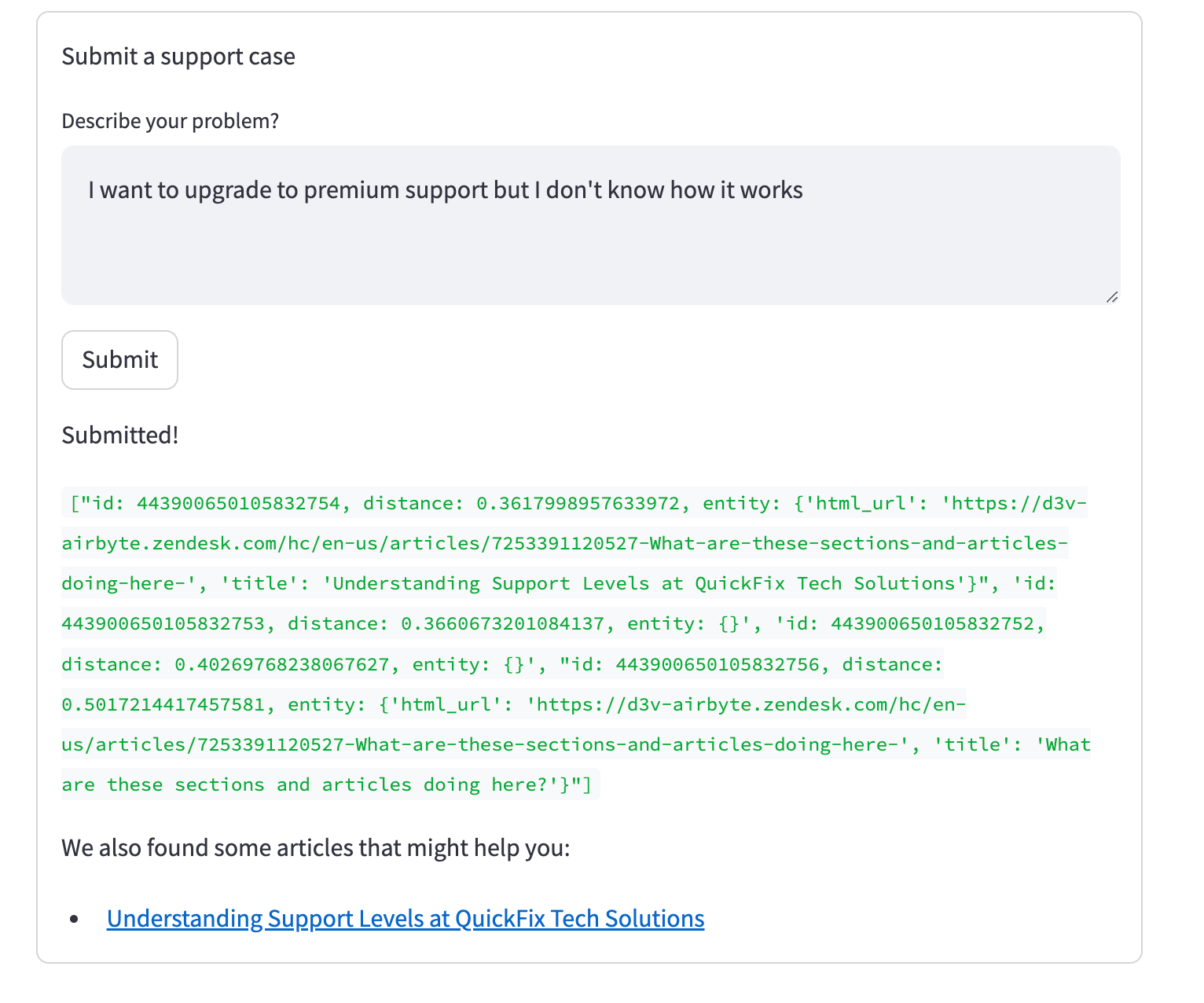
if len(article_results[0]) > 0:
st.write("We also found some articles that might help you:")
for hit in article_results[0]:
st.write(f "* [{hit.entity.get('title')}]({hit.entity.get('html_url')})")
類似度の高い未解決のサポートチケットがない場合、新しいチケットが送信され、関連するナレッジ記事が以下に表示されます:
この例のコードはGithubにもあります。
ここに示したUIは実際のサポートフォームではなく、ユースケースを説明するための一例ですが、AirbyteとMilvusの組み合わせは非常に強力なものです - さまざまなソース(PostgresのようなデータベースからZendeskやGitHubのようなAPI、AirbyteのSDKやビジュアルコネクタビルダーを使用して構築された完全なカスタムソースまで)からテキストを簡単に読み込み、Milvusに埋め込まれた形でインデックスを作成します。
AirbyteとMilvusはオープンソースであり、お客様のインフラストラクチャ上で完全に無料で使用することができます。
この記事で説明した古典的なセマンティック検索の使用例以外にも、一般的なセットアップは、RAGメソッド(Retrieval Augmented Generation)を使用した質問応答チャットボット、レコメンダーシステム、または広告をより適切かつ効率的にするための構築にも使用できる。

読み続けて

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.