




間違った段階のためにAIデータインフラを構築するのはやめましょう
AIインフラに関する意思決定のほとんどは最初の1週間で行われ、2年目に振り返ったときに後悔されます。
問題はほとんどの場合モデルではなく、アプリケーションロジックであることもまれです。結局は同じことに戻ります。データインフラは、チームがいる段階に合わせて構築されるべきだということです。
どの段階でも、失敗のパターンは両方向に作用します。早すぎる過剰設計は自分たちのスピードを落とします。過小評価すれば、プレッシャーの中で作り直すことになります。どちらも同じ結果を生みます。複利的に積み上がるイテレーションのオーバーヘッドです。
ステージ1: プロトタイプ — とにかく動かす
最初の段階では、データインフラよりもスピードのほうがはるかに重要です — というより、実際にはいわゆる「データインフラ」自体がまったく必要ありません。
目標はスケーラビリティではありません。目標はガバナンスではありません。目標は最適化ではありません。
目標は、単純にアプリケーションを動かすことです。
この段階で最もよくある間違いは、高度さを品質と取り違えることです。 チームは取り込むドキュメントもないうちからストリーミング取り込みパイプラインを追加します。実ユーザーが一人もいないうちから本番グレードのレプリケーションを設定します。一貫性が問題になるほどのデータもないうちから、複数システム間のデータ整合性を心配します。
その結果、単純なアイデア変更として出荷できたはずのものに、数週間のインフラ作業を費やすことになります。
話題の「ベクトルデータベース」について言えば、ほとんど重要ではありません。Milvus、Elasticsearch、pgvector、あるいは軽量な検索ライブラリでさえ — どれでも十分に役割を果たします。選択肢間の検索品質の差は、動くプロトタイプがあるかないかの差に比べれば無視できるほど小さいものです。

この段階で実際に必要なもの:
- ローカルファイルシステム
- 任意の軽量データベースまたは検索ライブラリ
ステージ2: プロダクトマーケットフィット — データベースが増えるほど、問題は悪化する
実際のユーザーがシステムとやり取りし始めると、焦点はデモを作ることからプロダクトを継続的に改善することへ移りますが、別の罠が現れます。
その誤解はもっともらしく聞こえます: より専門化されたデータベースタイプを増やせば、検索品質が向上する。
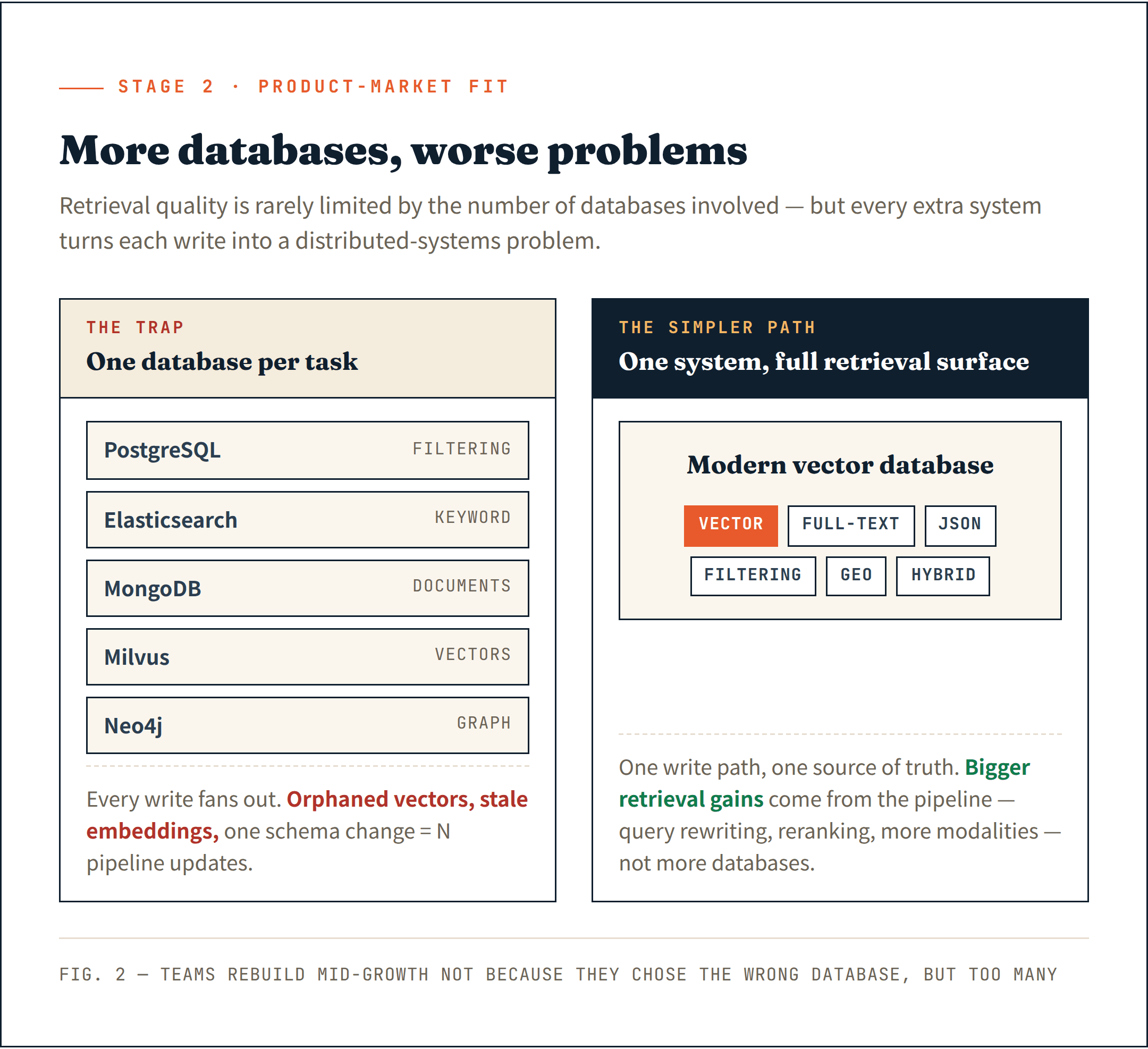
一部のチームは、検索タスクごとに1つのシステムを組み立て始めます — フィルタリングにはPostgreSQL、キーワード検索にはElasticsearch、ドキュメントにはMongoDB、ベクトルにはMilvus、グラフ関係にはNeo4j。検索スタックはプロダクト自体よりも速く成長します。
そして同期の問題がやってきます。
ドキュメントはあるシステムにあります。埋め込みは別のシステムにあります。メタデータは3つ目のシステムにあります。すべての書き込み操作が分散システムの問題になります。削除の失敗は孤立したベクトルを残します。部分的な挿入は古い埋め込みを生みます。スキーマ変更には、複数のパイプラインを同時に更新する必要があります。
厳しい教訓はこれです: 検索品質が、関与するデータベースの数によって制限されることはめったにありません。
より大きな改善は、検索パイプラインそのものから生まれます — 動的なクエリ書き換え、反復検索、段階的開示、より優れたリランキングです。データ側では、別の専門データベースを追加するよりも、別の埋め込みフィールドや別のモダリティを追加するほうが、検索品質を改善することがよくあります。
現代のベクトルデータベースは、ひそかにベクトルの範囲をはるかに超えて拡張してきました。全文検索、JSONフィルタリング、地理空間検索、ハイブリッド検索 — 成熟したシステムの多くは、今ではこれらをネイティブにサポートしています。タスクごとに専門データベースを使うという前提は、ますます時代遅れになっています。
検索領域全体を扱える単一のシステムは、運用がよりシンプルで、次に来るものに向けたよりクリーンな基盤を提供します。
成長の途中でデータインフラの再構築を余儀なくされたチームを、私はあまりにも多く見てきました — 間違ったデータベースを選んだからではなく、選びすぎたからです。
この段階で実際に必要なもの:
- マネージドデータベースサービス — あなたがプロダクトに集中している間、信頼性はベンダーに任せる
- 幅広いセマンティックサポートを備えた単一のシステム: ベクトル、全文検索、JSON、フィルタリング、ハイブリッド — タスクごとに1つのデータベースではない
- 再構築せずに次の桁の規模へ成長できるだけの十分な余裕
ステージ3: 大規模成長 — すべてのワークロードが同じコンピュートを共有すべきではない
これは、コスト圧力が否定できなくなる段階です。理由は単純です。データは常に収益よりも速く増えるからです。
最もよくある間違い: ここまで連れてきてくれた従来型のデータベースソリューションが、さらに先へ進ませてくれると想定すること。
ステージ2とは異なり、この時点では再構築する余地は簡単にはありません。成長圧力の下での大規模なインフラ移行は、非常に高額か、非常にリスクが高いか、あるいはその両方です。
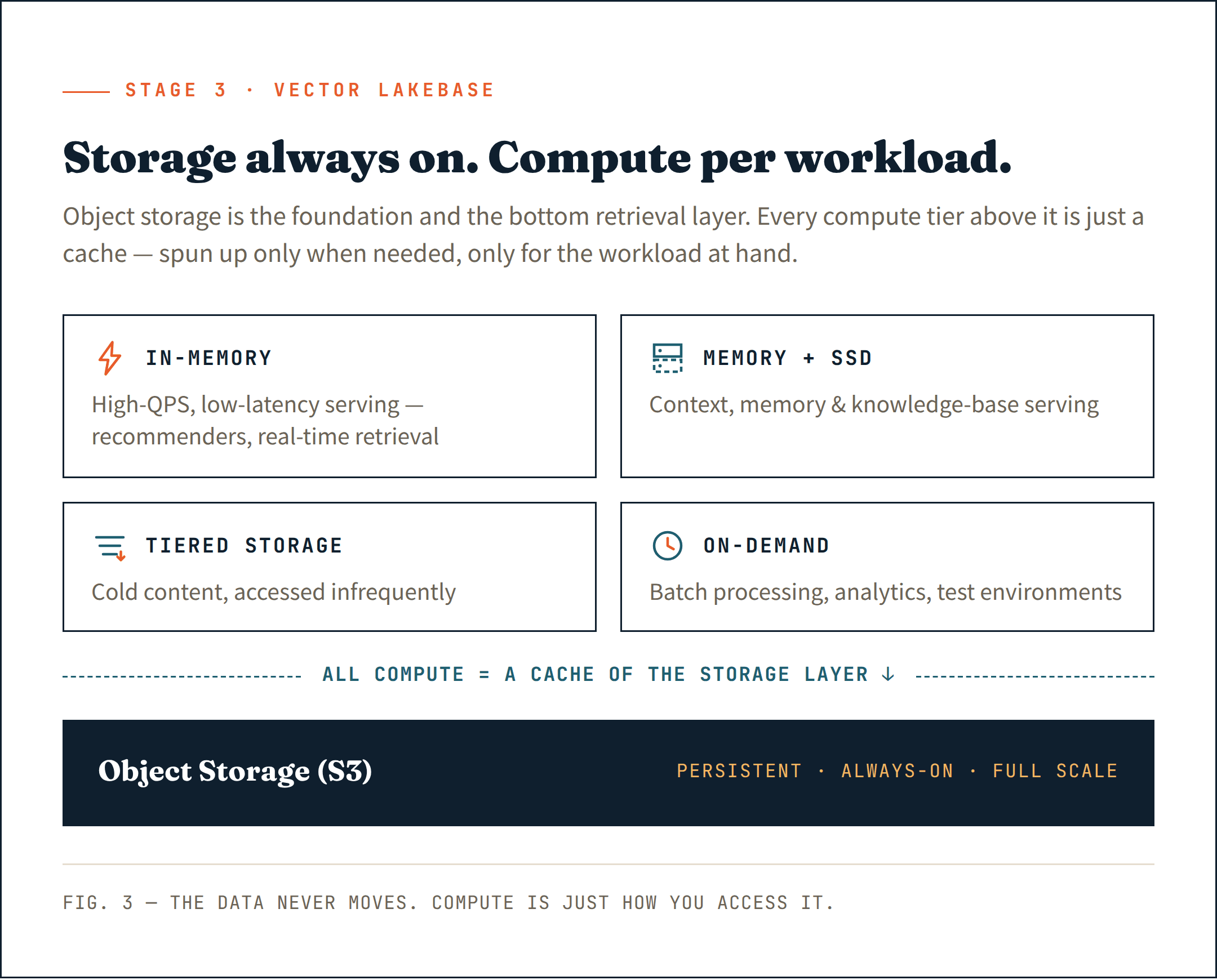
正しい一手は、すべてをオブジェクトストレージ(S3など)上に置くことです — 永続ストアとしてだけでなく、検索アーキテクチャのベースレイヤーとしてです。これは存在する中で最も安価で、最も耐久性が高く、最もスケーラブルな選択肢です。後付けではなく、基盤として扱ってください。
そのレイヤーの上では、実際に必要な場所にだけコンピュートを導入します。レイテンシに敏感なサービス提供には長時間稼働するクラスター。取り込みとインデックス作成には一時的なコンピュートリソース。分析やバッチジョブにはオンデマンドコンピュート。各ワークロードは必要なコンピュートを得ます — それ以上は何もありません。
これがVector Lakebaseの本質です: 常にフルスケールで稼働しているストレージと、そうではないコンピュート — 必要なときにだけ、目の前のワークロードのためだけに起動されるもの。
最も重要なのは、すべてのコンピュート — 長時間稼働であれオンデマンドであれ — がオブジェクトストレージレイヤーのキャッシュとして機能することです。データは常にストレージに存在します。コンピュートは、それにアクセスするための手段にすぎません。
各ワークロードを適切なコンピュート階層に合わせます:
- インメモリ は高QPS・低レイテンシのワークロード向け — AIレコメンダーシステム、リアルタイム検索
- メモリ + SSD はコンテキスト、メモリ、ナレッジベースの提供向け
- 階層型ストレージ はアクセス頻度の低いコールドコンテンツ向け
- オンデマンドコンピュート はバッチ処理、社内分析、テスト環境向け
正しく行えば、このアプローチは統合設計と比較してインフラコストを50%以上削減しながら、各ワークロードに対してはるかに優れたサービス品質を提供します。
サーバーレスソリューションは、この段階ではしばしば破綻します — 技術的にではなく、経済的にです。データがテラバイトに達すると、挿入とストレージのコストが支配的になり始めます。理由は構造的です。サーバーレスアーキテクチャは、プーリングのオーバーヘッド、インデックス作成、永続データのコストを、書き込みとストレージの上乗せ料金に組み込んでいます。もはや使った分に対して支払っているのではありません。抽象化に対して支払っているのです。
この段階のデータインフラにおける第一原則は明快です。基盤はデータに逆らうのではなく、データとともにスケールする必要があります。1つのアーキテクチャにすべてのワークロードを等しくうまく処理させようとすると、結局どれもうまく処理できません — そして、その妥協のコストは、追加するギガバイトごとに複利的に膨らみます。
この段階で実際に必要なもの:
- 基盤であり最下層の検索レイヤーでもあるオブジェクトストレージ(S3) — 永続的で、常にフルスケールで稼働し、すべてのコンピュートが読み取るレイヤー
- Vector Lakebase: 動かないデータと、ワークロードごとに必要最小限だけ起動するコンピュート
- ワークロードタイプごとに適切なコンピュート階層
ステージ4: エンタープライズ規模 — 信頼がプロダクトの一部になる
この段階になると、ほとんどのチームは難しい部分は終わったと考えます。そうではありません。
よくある間違い: チームがいまだに問題は技術的なものだと考えていること。
彼らはインフラを最適化しました。コストを管理しました。エンタープライズへスケールすることは、キャパシティを追加してセキュリティ項目にチェックを入れるだけの問題だと思い込んでいます。
そうではありません。
エンタープライズ案件を妨げる質問は、パフォーマンスとは何の関係もありません:
私たちのデータは他の顧客からどのように隔離されていますか?
誰が何にアクセスでき、その証明はできますか?
私たちの地域でサービスを提供できますか?
これを自社のクラウドアカウント内にデプロイできますか?
しかし、個別の商談要件は問題の一部にすぎません。ステージ3では、不均一性は技術的なものでした — 異なるワークロード、異なるコンピュート階層。この段階では、それは構造的なものです。つまり、顧客基盤に対応するには、プラットフォームレベルのデータインフラが必要になります。
コスト効率の高い共有型の提供を必要とする無料ユーザーがいます。より高い可用性を期待する有料の個人顧客がいます。完全なデータ隔離、専用コンピュート、そしてすべてを監査できる能力を必要とするエンタープライズ顧客がいます。同じアーキテクチャからこの3者すべてに対応するということは、無料ティアに過剰投資しているか、エンタープライズ顧客に十分なサービスを提供できていないか、あるいはその両方であることを意味します。
正しい答えは、各顧客セグメントに合わせた階層型インフラです。
- 共有クラスター:無料ユーザーおよび個人ユーザー向け — プール化され、コスト最適化されたもの
- 隔離クラスター:エンタープライズ顧客ごと — 専用コンピュート、専用ストレージ、専用アクセス制御
- BYOC:自社のクラウドアカウント内へのデプロイを必要とする顧客向け

BYOCの点で、ほとんどのチームが重大な間違いを犯します。SaaSとBYOCは2つの製品のように見えます。もしアーキテクチャレベルで分岐させてしまうと、2つのコードベース、2つのデプロイメントパイプライン、2つの運用ランブックを、無期限に維持することになります。これを正しく行ったチームは、BYOCを別製品ではなくデプロイメントモデルとして扱いました。同じデータプレーン、同じ制御インターフェース、異なるデプロイ先です。
グローバルな信頼性も、長く先送りされがちなもう一つの要素です。エンタープライズ規模では、マルチリージョンはプレミアム機能ではなく、基本的な期待事項です。異なる地域にまたがるエンタープライズ顧客は、単一リージョンのデプロイを容認しませんし、あなたのSLAコミットメントも受け入れません。クラウドやリージョンをまたいだ統一されたデータインフラインターフェースがなければ、環境ごとに異なるデータレイヤーを運用することになり、リアルタイムのデータ同期はそれ自体が分散システム上の問題となり、新しいリージョンを追加するたびに運用の複雑性が増大します。
本格的なエンタープライズ商談に到達した、私が話を聞いたチームは、同じ痛みを伴う発見を語っていました。これらのどれも、最初から設計に組み込まれていなかったのです。ライブの営業サイクルからの圧力の下で、後から継ぎ足されたものでした。あるチームは、そのために構築されていなかったアーキテクチャにデータレベルの隔離を後付けするのに4か月を費やしました。彼らはそれをリリースしました。しかし、それがなぜ脆いのかを正確に理解していました。
エンタープライズ対応はチェックリストではありません。それは、はるか以前に行われたアーキテクチャ上の意思決定の結果です。
この段階で実際に必要なもの:
- 統一されたデータインフラインターフェース — クラウド間で一貫し、リージョン間でも一貫しているもの
- 高い信頼性とマルチリージョンでの提供を前提に設計されたグローバルクラスター
- 階層型の提供:無料ユーザー向けの共有クラスター、エンタープライズ顧客ごとの隔離クラスター
- 同じアーキテクチャ上のSaaSとBYOC — 1つのデータプレーン、異なるデプロイ先
- 基盤におけるオープン標準とオープンソース — エンタープライズ規模でのベンダーロックインなし
うまくスケールしたチームに共通すること
そのパターンは一貫しています。
各ステージでは、まったく異なる種類の問題が生じます。ステージ1はスピードの問題です。ステージ2は複雑性の問題です。ステージ3はコストとアーキテクチャの問題です。ステージ4は信頼とプラットフォームの問題です。

苦痛を伴う再構築なしに各ステージを乗り越えたチームは、早い段階でこれを理解していました。彼らは「今どのデータベースが必要か?」と問うのをやめ、「次のステージでは何が必要になるのか — そして現在の意思決定はその道を閉ざしていないか?」と問い始めたのです。
ステージ1では、ベクトルデータベースはまさに適切なツールです。私は何の留保もなくそう言います。
ステージ3以降で必要になるのは、性質の異なるもの — Vector Lakebase です。ストレージは常にフルスケールで稼働。コンピュートは各ワークロードに合わせて調整。同じアーキテクチャから、無料ユーザー、有料顧客、エンタープライズアカウントに、分岐させることなくサービスを提供できるプラットフォームです。
そこへより早く到達したチームは、より賢かったわけでも、より多くの資金を得ていたわけでもありません。
彼らはただ、インフラストラクチャの決定が一時的な選択ではないことを、より早く理解していただけです。
それは、その後のすべてが築かれる基盤でした。
Zilliz Vector Lakebase はパブリックプレビューで利用可能です
Zilliz Vector Lakebase のパブリックプレビューを開始しました — これは Zilliz Cloud の大きな進化であり、マネージドベクトルデータベースから、本番用ベクトルデータベースと共有されたレイクネイティブなデータ基盤を組み合わせた、統合セマンティックデータプラットフォームへの進化です。
Zilliz Vector Lakebase の主な機能:
- さまざまなリアルタイムの性能とコストのトレードオフに最適化された階層型サービング
- 常時稼働のコンピュートなしで、大規模または探索的ワークロードに対応するオンデマンド検索
- 外部データレイク検索 — 既存のレイクデータ上で直接インデックス作成と検索を実行
- ハイブリッド検索とリランキングにより、ベクトル、テキスト、JSON、地理空間データを横断するフルスペクトラム検索
- Vortex 上に構築された統合レイクネイティブストレージ。Lance や Parquet よりも高速かつ低コストなランダム読み取りを実現するオープンフォーマット
現在のスタックでサービングとディスカバリーを別々のシステムに分けているなら、Vector Lakebase は検討する価値があるかもしれません。Zilliz Cloud でお試しください — 新しい仕事用メールでのサインアップには $100 の無料クレジットが付与されます — または、ユースケースについてお問い合わせください。
Vector Lakebase についてさらに学ぶ

読み続けて

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.