




From Vector Database to Vector Lakebase
Today, we're launching the public preview of Zilliz Vector Lakebase — the next chapter for Zilliz Cloud. Vector Lakebase is the next step beyond vector databases. It is a semantic-centric data platform where open storage and elastic compute converge for AI workloads.
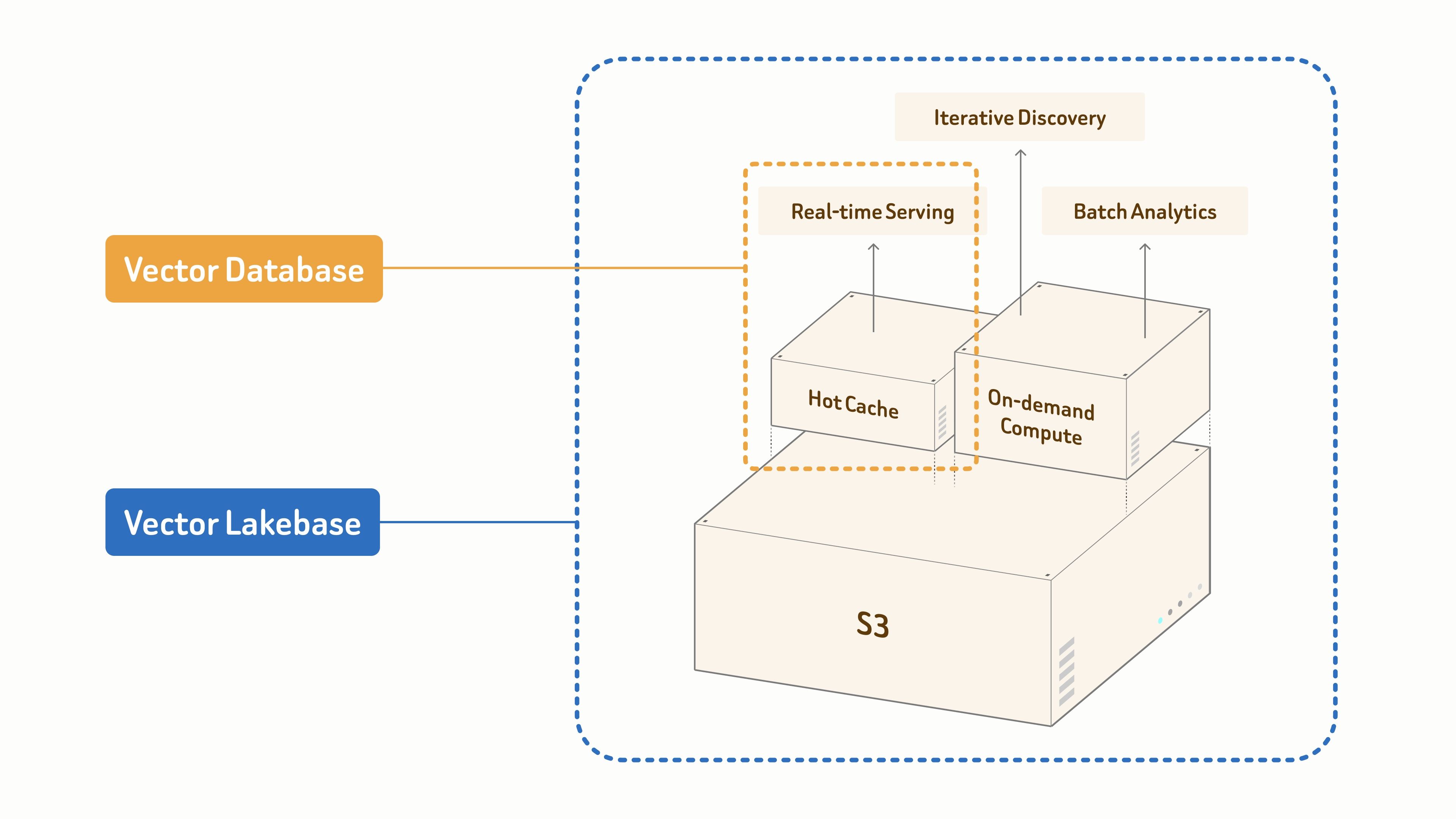
- Vector Databases are purpose-built for real-time serving.
- Vector Lakebase builds on an S3-based unified data foundation to power AI and agents across three workload modes:
- real-time retrieval for latency-critical production serving,
- iterative discovery for interactive and multi-step exploration,
- batch analytics for offline mining and dataset optimization.
All scaling from gigabytes to petabytes.
Why do the unified data foundation and three workload modes really matter?
In short: because AI systems are no longer just a single-query retrieval problem. They operate as a continuous loop of serving, learning, and improving.
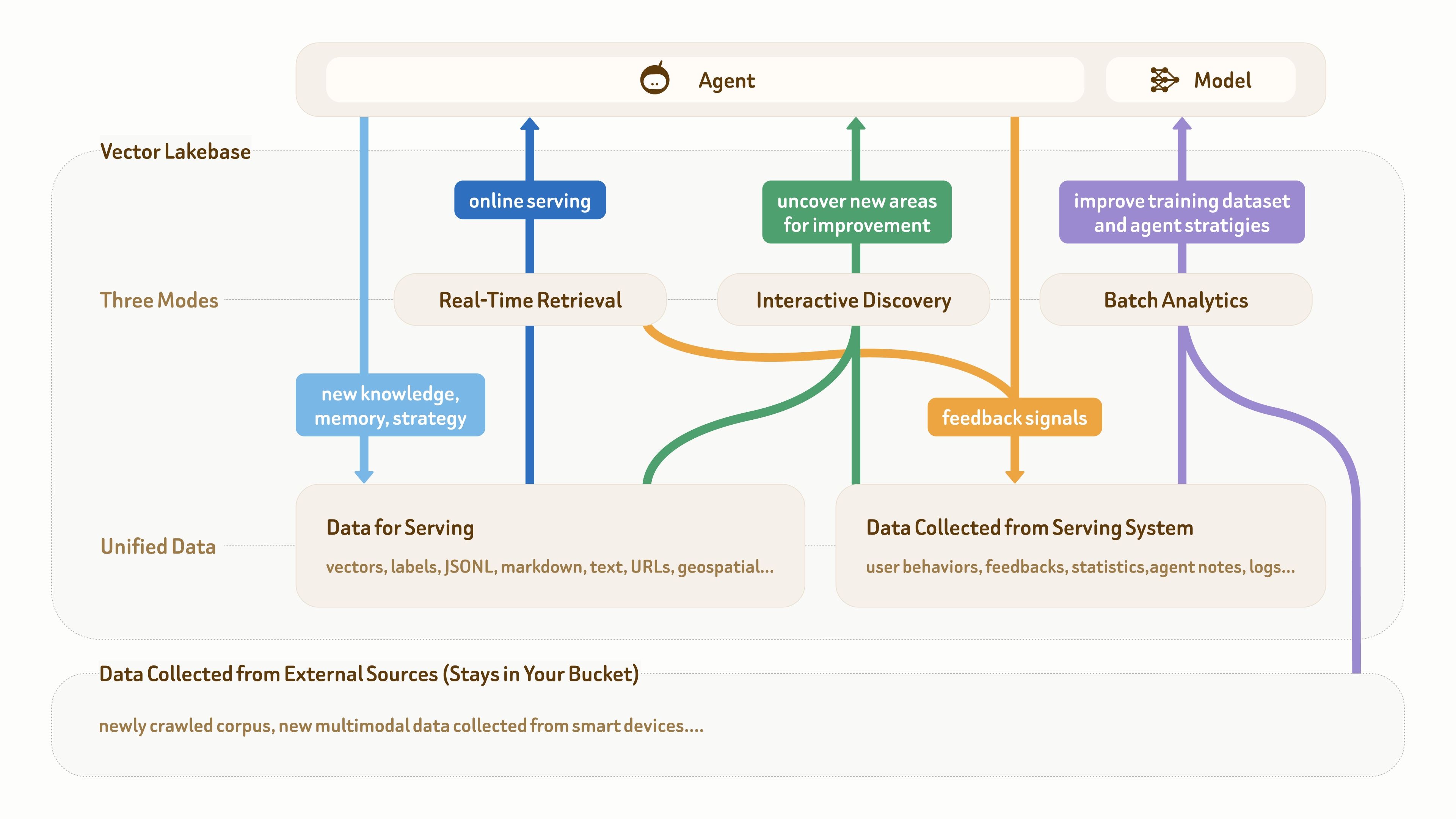
As this figure shows, the data foundation for AI and agent applications usually has three parts: raw multimodal data at the bottom, semantic data for online serving (such as text, vectors, and labels), and feedback data collected from production systems (such as user behavior, logs, agent notes, and statistics).
Many mature agent applications already have this kind of data foundation. The real pain point is that these different types of data are often scattered across multiple pipelines and systems, without a unified and structured data plane to support the workflow loop:
online serving (dark blue) → knowledge and feedback accumulation (light blue and orange) → insight discovery (green) → dataset and strategy improvement (purple) → better online serving.
As the picture also shows, a vector database alone is no longer enough, because it mainly supports real-time retrieval and serving-oriented data writes (the two blue paths). In this loop, the other two access modes — interactive discovery and batch analytics — are just as important.
For example, AI developers (either manually or through agentic systems) often need to explore feedback data and the underlying corpus to understand why serving quality is poor. They may also run large-scale semantic deduplication and clustering on newly crawled data, then mine edge clusters to discover new training data candidates.
These workloads are very different from traditional big data processing. The core computation is semantic rather than numerical. The data mainly consists of vectors, text, labels, and semantic metadata, while the core operations include vector search, full-text search, reranking, semantic clustering, and related semantic retrieval tasks.
Because of this, interactive discovery and batch analytics are naturally aligned with vector databases at both the data and compute layers. In many cases, online serving and offline processing even share the same underlying data foundation.
For example, teams may cluster and analyze high-value user tasks offline while simultaneously checking whether the supporting knowledge or strategies in the serving system show sparsity or quality issues.
Overall, any fragmented data architecture or isolated infrastructure islands slow down this loop — which can be fatal in the rapidly evolving race for AI capabilities. Vector Lakebase accelerates this loop through a straightforward but efficient approach: providing a zero-copy semantic data plane that can be efficiently accessed by all three workload modes — real-time retrieval, interactive discovery, and batch analytics.
The Key Vector Lakebase Features
Zilliz Vector Lakebase supports this workflow loop through five core capabilities:
- Tiered Serving Solutions
Flexible serving tiers optimized for different real-time workloads — delivering ultra-high performance, balanced efficiency, and cost-effective scaling across massive datasets. - On-Demand Search
Designed for large-scale workloads where latency is less critical and compute remains idle most of the time — including infrequent search, data exploration, and batch analytics. - External Data Lake Search
Add state-of-the-art indexing and large-scale search capabilities directly to your existing lake data. - Full-Spectrum Search From vector and text to JSON and geospatial—combined with hybrid retrieval, filtering, and reranking for expressive multi-modal queries.
- Unified Lake-Native Storage
Unified storage for both serving and analytics, built on Vortex — an open next-generation format providing faster and cheaper random reads than Lance and Parquet, plus per-column format flexibility and broader data modeling capabilities.
Tiered Real-Time Serving Solutions
Zilliz Cloud's Tiered Serving Solutions provide three serving tiers: Performance-Optimized, Capacity-Optimized, and Tiered-Storage. Each tier is built with dedicated indexing algorithms and data placement strategies across the storage hierarchy, offering a wide range of performance–cost tradeoffs.
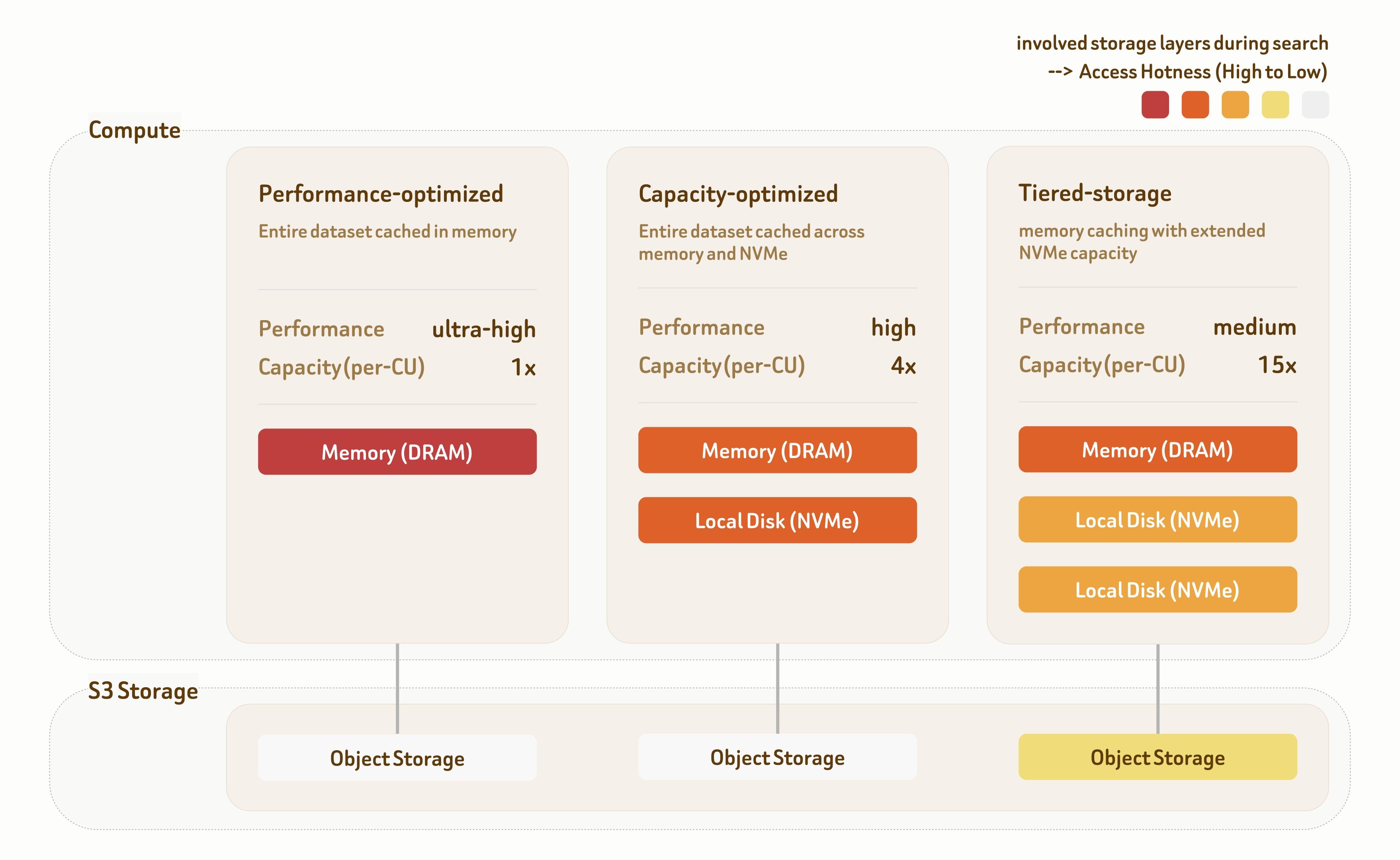
The Performance-Optimized tier targets ultra-high-performance scenarios. All data is served directly from memory, delivering 1000+ QPS with single-digit millisecond latency. Throughput further scales linearly with multi-replica deployment.
The Capacity-Optimized tier combines memory and local NVMe storage to balance performance and capacity. It delivers 100~500 QPS with sub-100 ms latency, making it suitable for most retrieval workloads.
The Tiered-Storage tier spans memory, local NVMe, and object storage. With highly optimized prefetching and caching strategies, over 95% of data access still hits memory or local disk, providing 10~50 QPS with around 100 ms latency at significantly lower infrastructure cost.
All three tiers deliver 95%–98% recall by default, with flexible tuning across indexing and search—supporting 90% to 99%+ recall based on workload requirements.
These serving architectures are battle-tested in some of the world’s most demanding large-scale AI and internet workloads, including:
- internet-scale multi-tenant AI platforms,
- differentiated service tiers for both premium enterprise users and large-scale free-user pools,
- high-performance agent knowledge bases,
- ultra-high-throughput recommendation systems,
- web-scale AI search engines,
- second-level dynamic hot/cold data scheduling across storage tiers,
- autonomous driving data mining pipelines at 100B+ scale under extreme cost constraints.
For online serving, Zilliz Cloud also provides Global Cluster capabilities for cross-region high availability and disaster recovery, backed by a 99.99% uptime SLA.
On-Demand Search
Interactive discovery and batch analytics often operate on data volumes one to three orders of magnitude larger than online serving, especially when including feedback data, agent-generated notes, logs, and crawled corpora. These datasets can easily reach TB or even PB scale. But using hundreds or even thousands of vector database nodes to serve them is often hard to justify from a cost–benefit perspective.

More importantly, these workloads are usually task-driven. Unlike the online serving layer of agent applications, they do not require 24/7 active infrastructure. Compute resources are heavily used only during active processing tasks, while remaining idle most of the time, often with over 97% idle time.
Serverless serving solutions may seem appealing, but they often become much more expensive for these workloads.
At the compute layer, both serverless systems and On-Demand Search follow a pay-as-you-go model. Despite differences in detailed pricing models, the underlying compute cost is often similar. However, in serverless architecture, pooling overhead, indexing, and persistent data costs are embedded into additional write and storage markups, rather than directly reflecting the true cost of underlying resources.
In contrast, Zilliz On-Demand Search charges directly for object storage and on-demand compute — similar to AWS Lambda, where pricing is primarily based on allocated resource size and execution time, while storage cost remains close to the underlying S3 cost. This avoids hidden infrastructure overhead and black-box pricing models.
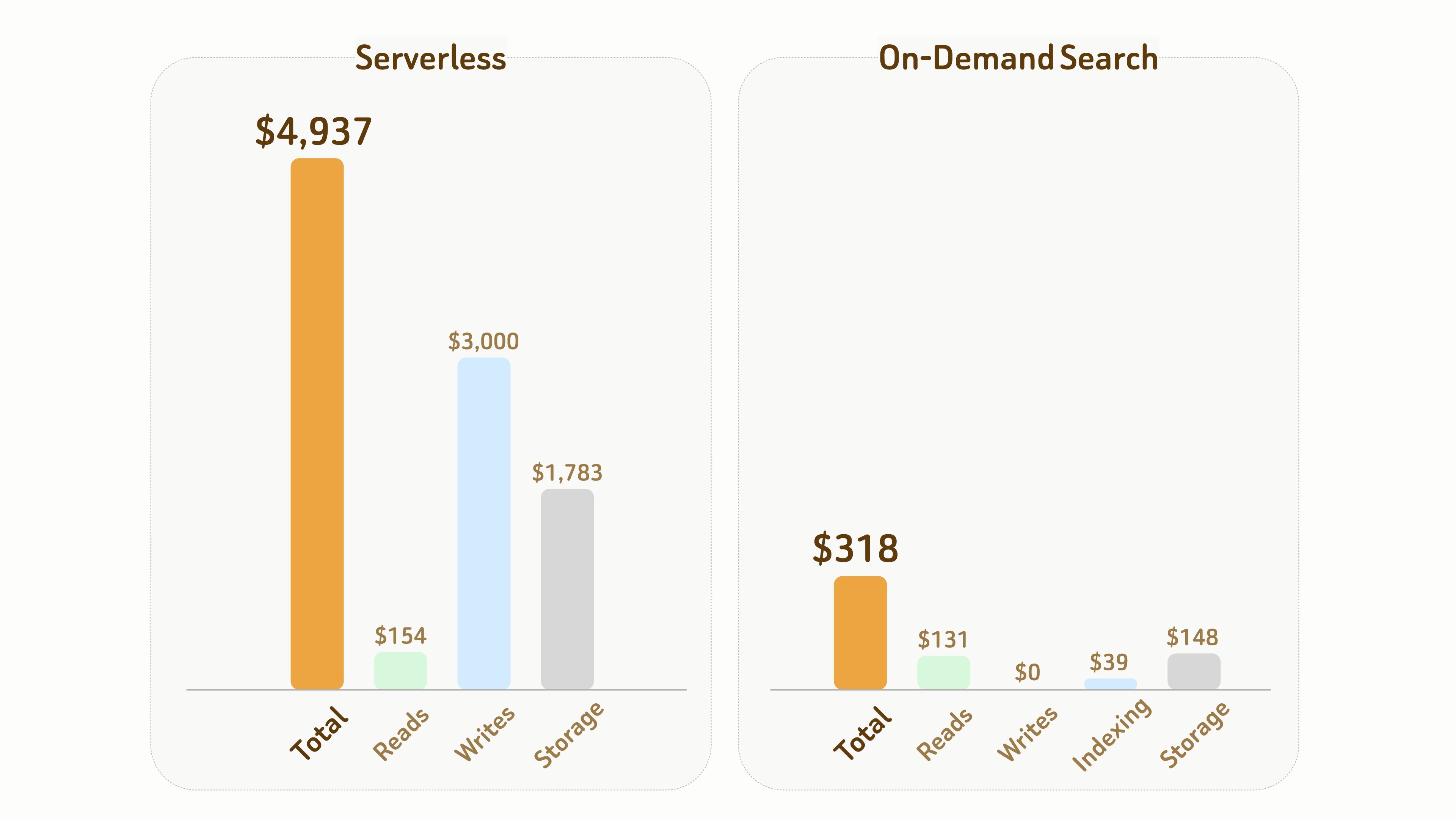
The following comparison illustrates the cost difference between Serverless and On-Demand Search.
Setup:
- 1B vectors with 768 dimensions, requiring approximately 6 TB of storage including data and index files,
- 1 month duration with 10 hours of accumulated active compute time.
Overall, in this experiment, the total cost of On-Demand Search is only about 1/15 ($318 vs $4,937) that of Serverless.
External Data Lake Search
Zilliz Vector Lakebase provides fully managed storage and query compute, allowing users to store and operate their data directly in Zilliz Cloud. However, some customers already have mature data lake infrastructure and governance pipelines in place.
For AI applications, one of the key challenges is enabling efficient retrieval and semantic exploration directly on top of existing lake data. Traditional big data systems such as Spark and Ray are not optimized for these workloads, because they are fundamentally designed around full-data scan and map-reduce computation rather than index-accelerated query and semantic retrieval.
To solve this, Zilliz provides an External Collection mode. It creates a zero-copy logical mapping from the Zilliz data plane to customer-owned lake tables, while enabling high-performance indexes and full-spectrum search on top of that mapping.
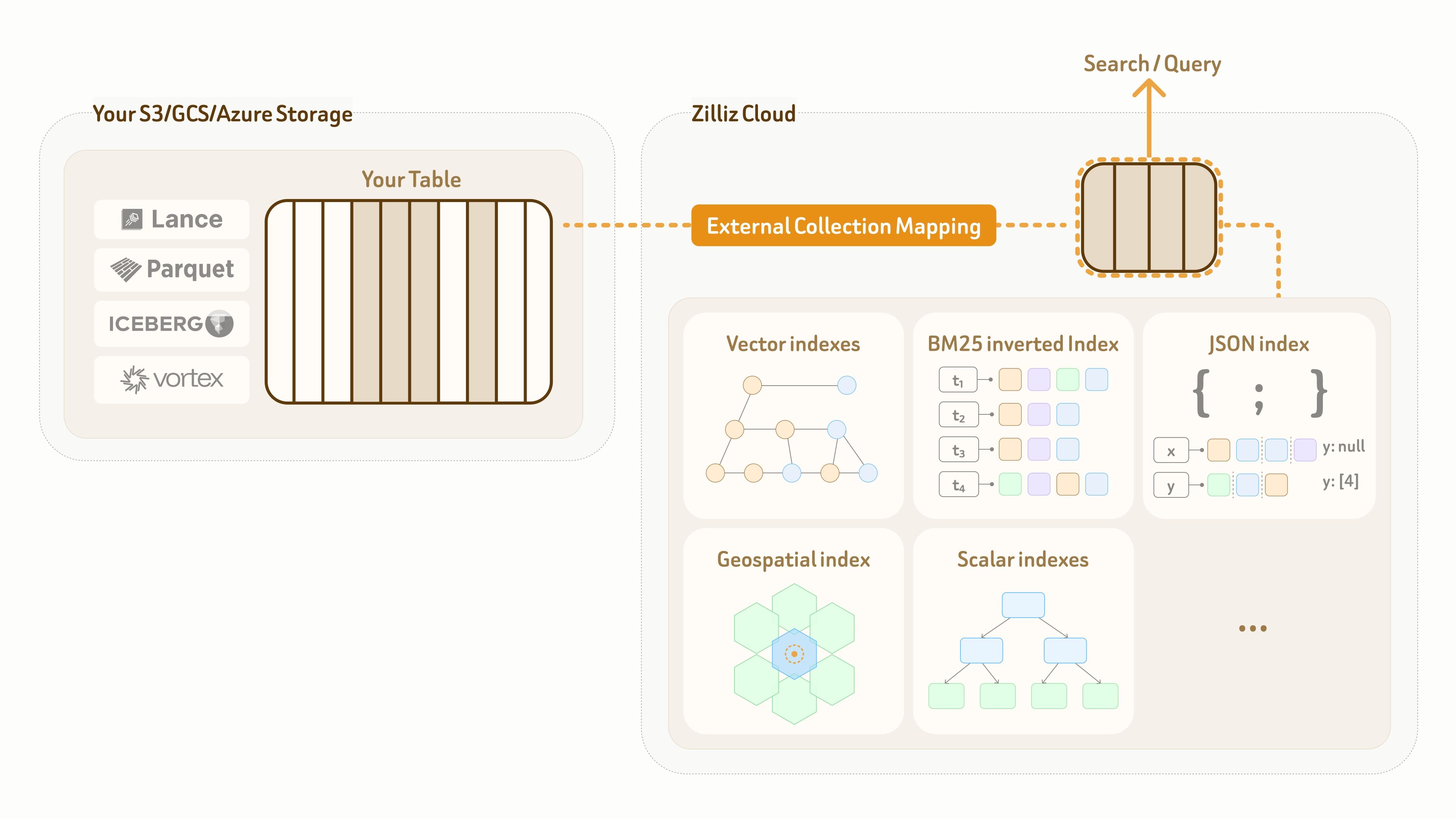
Currently, External Collection supports two data lake table formats — Lance and Iceberg, as well as two open data formats — Parquet and Vortex.
For data lake updates, Zilliz External Collection provides incremental synchronization capabilities. Based on the data lake update pattern and query visibility requirements, users can sync data anytime with a refresh call.
Full-Spectrum Search
AI applications increasingly need to retrieve and analyze data across different sources and modalities — both to combine complementary information and to extract multiple perspectives from the same raw content for better retrieval and analysis quality.
Zilliz Vector Lakebase supports wide-table modeling with rich data types including dense and sparse vectors, text, JSON, geospatial data, and primitive types, along with complex structures such as Struct and Array — enabling efficient nested semantic modeling directly within a unified table layout.

This enables unified context modeling by mapping each application-level entity directly to a single row. For example, instead of splitting a document into hundreds of rows for text chunks, images, and tables, Zilliz Vector Lakebase can model the entire document as a single row. This improves multi-modal retrieval and analytics while avoiding the performance and operational overhead of JOINs and aggregations.
Beyond data modeling, Vector Lakebase also provides state-of-the-art indexing and search capabilities across all supported data types. Detailed capabilities are listed below:
| Vector Search | Advanced indexing algorithms outperforming HNSW, IVF, and RaBitQ, with 10 levels of recall-latency tuning. |
|---|---|
| Full-Text Search | Full-text search with BM25, phrase, prefix, fuzzy matching, and a wide range of analyzers. |
| Grep | Built-in regex support covering most grep-style matching patterns. |
| Hybrid Search | Hybrid dense and sparse vector search for improved recall and relevance. |
| Query on JSON | Built-in JSON shredding and indexing for fast filtering and querying on nested JSON fields. |
| Geospatial Search | Fast geospatial search with radius, nearest-neighbor, and area filtering. |
| Multi-Vector Search | Search over multiple embeddings generated from one or more modalities, with unified reranking. |
| Vector Search with Filtering | Vector search with attribute filtering, optimized across low to high filter selectivity. |
| Range Search | Return all vectors within a specified distance threshold of the query vector. |
| Iterative Search | Iterative search with step-by-step query refinement based on intermediate results. |
| Multi-Path Retrieval | Multi-path retrieval with multiple strategies, where each path can use any of the above search methods. |
as well as reranking capabilities used together with multi-path retrieval.
| Cohere Reranker | A cross-encoder reranking model that scores query–document pairs with high semantic precision to reorder retrieval results for maximum relevance. |
|---|---|
| Voyage AI Reranker | A lightweight, high-throughput reranking model optimized for fast, cost-efficient relevance scoring in large-scale retrieval pipelines. |
| Boost Reranker | Applies conditional filters to matched results and adjusts their scores with a specified weight to promote or demote rankings. |
| Decay Reranker | Adjusts result scores by applying a decay function based on factors like distance or time, gradually lowering relevance as values diverge from a target. |
| RRF Reranker | Fuses multiple result lists by combining each item’s rank positions across lists into a single ranking. |
| Weighted Reranker | Combines scores from multiple result lists using configurable weights to produce a unified ranking. |
Unified Lake-Native Storage
Zilliz Cloud is built on a fully decoupled storage–compute architecture, with everything persisted on cloud object storage.
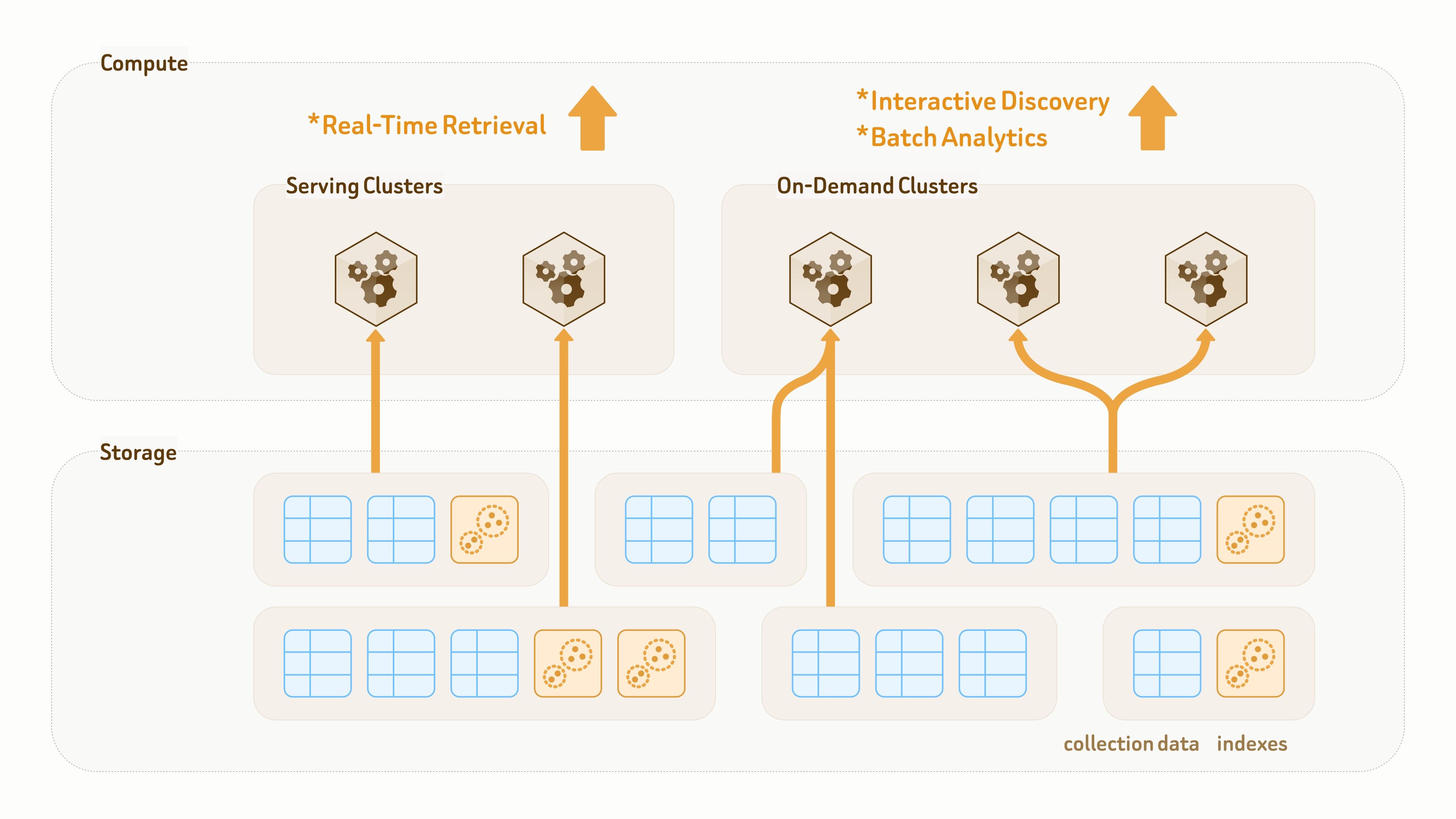
Unlike traditional data lakes designed mainly for storage, the data layer of Zilliz Vector Lakebase is designed for both persistence and query execution. Collections and indexes are decoupled from compute clusters, allowing the same data and indexes to be mounted through zero-copy access by different clusters for different query and analytics workloads.
For AI and agent applications with continuously evolving data models — such as frequently adding new labels and features or switching embedding models — Zilliz provides a seamless and high-speed schema evolution and data backfill mechanism.
New fields are backfilled and aligned by pooled platform compute resources, then exposed to query clusters through metadata updates. A 100M-row backfill can typically be completed in single-digit minutes.
Because most of the work is handled by platform-side compute resources, existing user clusters remain unaffected and can continue serving read and write traffic throughout the process.
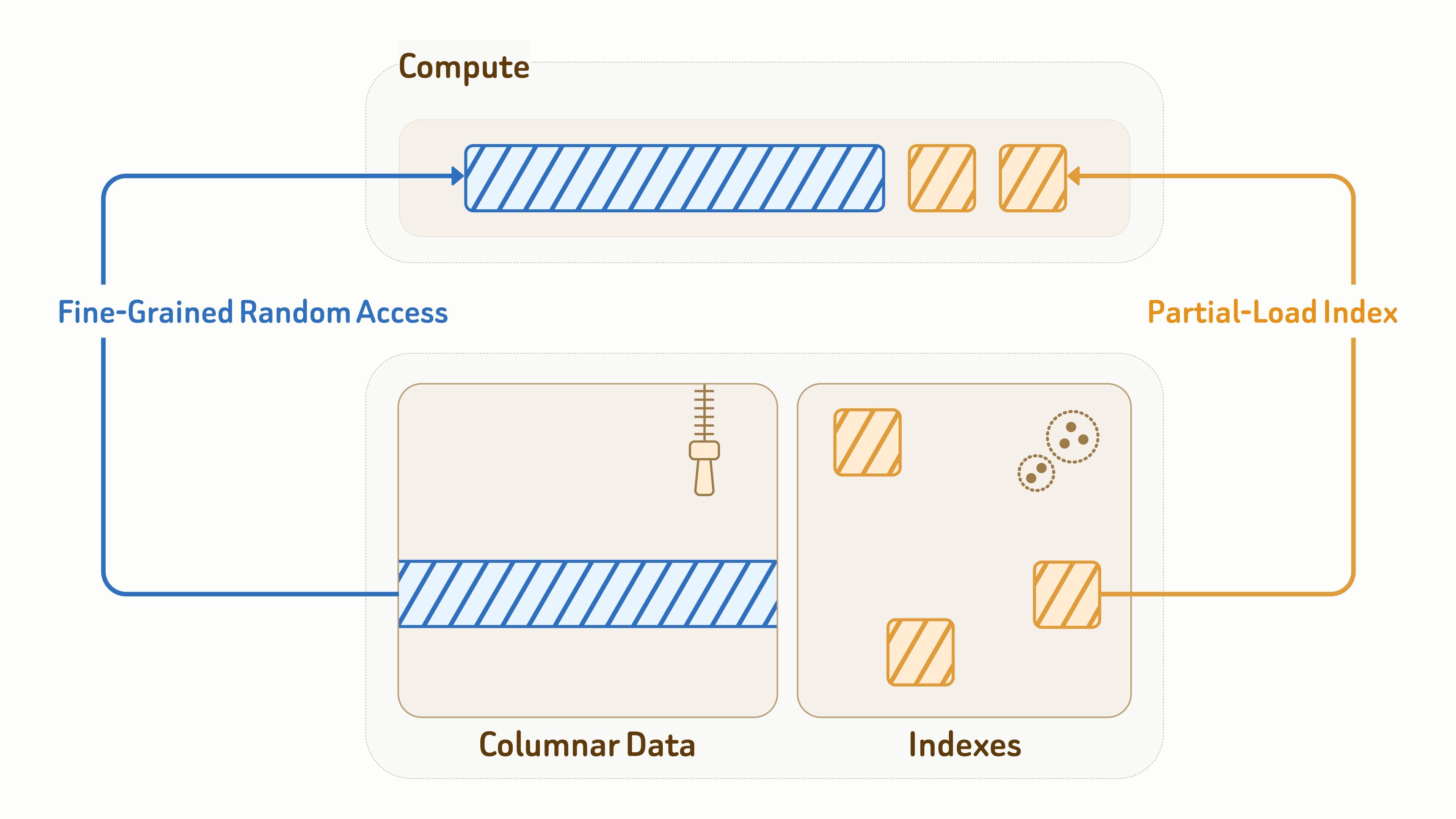
Because the data layer also directly serves query workloads, efficient I/O is critical for both latency and throughput.
For collection data, Zilliz uses the Vortex open format for columnar storage layout, combining efficient encoding with fine-grained random access to data fragments — significantly faster than Lance and Parquet for random reads.
For indexes, Zilliz provides object-storage-aware index algorithm designs with deeply optimized layouts and access patterns for efficient I/O, including vector indexes, BM25 inverted indexes, and JSON indexes.
During query execution, compute nodes only partially load the index pages and data entities touched by the query. Combined with caching and data pruning, this significantly reduces read amplification by over 90%.
Primary Use Cases of Vector Lakebase
Typical application scenarios for Vector Lakebase include, but are not limited to:
Real-Time Serving Workloads:
- Latency-critical agent memory and strategy retrieval.
- Vertical domain knowledge bases for legal, healthcare, finance, and other specialized industries.
- Web-scale AI search engines.
- Ultra-high-throughput recommendation systems.
- Second-level dynamic hot/cold data scheduling across storage tiers.
- Differentiated service tiers for both premium enterprise users and large-scale free-user pools.
Iterative Discovery Workloads:
- AI service quality analysis and issue discovery across feedback data, agent-generated notes, logs, and other multi-source data.
- Efficient exploration of large-scale datasets.
- Multi-step iterative deep research.
Batch Analytics Workloads:
- Ultra-large-scale corpus deduplication and clustering.
- Adding full-spectrum search capabilities to Spark and Ray for efficient filtering, retrieval, and two-stage coarse-to-rerank query pipelines.
- Training and fine-tuning dataset preparation.
Hybrid Cases:
- Accelerated indexing and retrieval on existing data lake tables such as Lance and Iceberg.
- Continuously evolving data models with frequent large-scale backfills.
- Multi-modal semantic wide-table modeling, unifying vectors, metadata, LLM-generated summaries, and structured fields into entity-centric tables with consistent versioning and lineage management.
Try Zilliz Vector Lakebase
For more information about Vector Lakebase and the latest updates, visit the Zilliz website or explore the Zilliz Cloud documentation. If the architecture or use cases in this article are relevant to your work, contact the Zilliz team for a deeper technical discussion.

Keep Reading

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.