




Vector Lakebase: End the AI Data Silo
Every AI Team Hits the Same Wall — Data Gravity
Every modern data team has built some version of the same architecture. A lakehouse — Iceberg tables on S3, a Spark pipeline, and Delta Lake for governance — sits at the center. It works well. Then the AI requirements arrive.
Your RAG pipeline needs to answer questions over 10 years of enterprise documents, so you copy everything into a vector database. Your AI agents need low-latency access to product catalog embeddings — another pipeline, another sync job. Your multimodal model training requires daily deduplication across a billion image embeddings — a Spark job that can't see the index.
Six months later, you have five systems instead of two. Your data engineering team spends more time maintaining synchronization pipelines than building AI features. You have three copies of the same dataset with no guarantee that they agree. Every schema change cascades into four different places.
This isn't a failure of execution. It's a failure of architecture — specifically, an architecture that keeps fighting a fundamental property of data: gravity. Every system that requires you to copy data first is levying a gravity tax on you. The more AI workloads you add — RAG pipelines, agent memory, model training, real-time recommendations — the higher that tax becomes.
The right solution isn't a better pipeline. It should be a new architectural paradigm: Vector Lakebase.
Three Generations of Architectural Solutions, Two Dead Ends
Before we dive into the details of Vector Lakebase, it is worth looking at how vector search architecture has evolved to address the data gravity problem. Broadly, there have been three generations of solutions.
Generation 1: Dedicated Vector Databases
Dedicated vector databases like Milvus solved a real problem for production AI systems: millisecond-latency semantic search with recall and performance that general-purpose databases could not match. As the creators of the open-source Milvus vector database, Zilliz has long focused on building a reliable, high-performance system for storing embeddings, constructing indexes, and serving low-latency retrieval for RAG, agents, recommendation systems, semantic search, and multimodal applications. That foundation still matters. Production AI systems still need database-speed retrieval, and vector databases remain the right serving layer for many latency-sensitive workloads.
However, as AI workloads mature, the challenge increasingly extends beyond online serving. Much of an organization’s source data already lives in object storage, data lakes, lakehouses, and downstream analytical systems. To use that data in a dedicated vector database, teams typically copy it into a separate serving system, build ingestion pipelines, maintain synchronization jobs, and manage consistency between the source data and the vector index. When embedding models change, as they inevitably do, teams need to regenerate embeddings, rebuild indexes, and keep multiple systems aligned.
This is not a limitation of vector database performance. It is an architectural boundary created by data movement. As more teams want to use the same data for production retrieval, embedding experiments, offline evaluation, governance, lineage, and analytics, the operational surface area grows. Dedicated vector databases solved the online retrieval problem extremely well, but by themselves, they do not eliminate the data gravity problem.
Generation 2: Vector Lake
The next natural response was to bring vector search closer to the lake: query vectors directly from Iceberg, Delta Lake, or Parquet files without first moving them into a dedicated serving system. The motivation was correct. If the data already lives in object storage or a lakehouse, why duplicate it somewhere else just to make it searchable?
But in practice, vector lake architectures remain incomplete for production AI workloads for three reasons.
First, they are not designed for low-latency serving. Most vector lake approaches load data or indexes from object storage on demand and are optimized more for flexibility than for concurrent, latency-sensitive request handling. That may be acceptable for offline exploration, but it is not enough for user-facing RAG, agents, recommendation, or search applications. When a retrieval pipeline sits in the critical path of an LLM call, teams need predictable sub-100ms latency at high concurrency. If p99 latency regularly drifts into the seconds range, the system may still be useful for analysis, but it cannot serve as the production retrieval layer.
Second, vector lake systems typically stop at the search stage. They let teams query vector data in the lake, but they do not provide a broader execution environment for AI data workflows. Modern AI systems need more than nearest-neighbor search. They need to regenerate embeddings, evaluate retrieval quality, compress agent memory, extract frames from video, process multimodal data, manage metadata, and prepare data for fine-tuning or downstream pipelines. A system that only adds search on top of lake files does not address the full lifecycle of vector and multimodal data.
Third, the underlying storage layer was not built for this workload. Iceberg and Delta Lake were designed for structured analytical data — no native vector types, no index structures, every query is a full scan. AI workloads need fast point lookups (not Parquet's sequential row-group scans — formats like Vortex and Lance exist for this reason), built-in indexes co-managed with data, and reference-based unstructured data management where images, audio, and video are linked by reference rather than inlined as blobs. None of this exists in the lake today. A Vector Lake built on Iceberg is fighting the storage layer at every level.
Generation 3: Vector Lakebase
Vector Lakebase is what you get when you stop treating the lake and the vector database as separate systems that need to be synchronized and start building them as two operating modes of a single unified layer. To be more specific:
A vector lakebase is a new AI-native and lake-native architecture evolved from vector database systems. It combines the high-QPS, low-latency serving capabilities of vector databases with the openness, scalability, and cost efficiency of multimodal data lakes, while keeping all workloads on the same source of truth without data migration. By separating compute from storage, a vector lakebase stores multimodal data, vectors, attributes, indexes, and metadata directly in low-cost object storage using open formats. Serving, discovery, and analytics workloads can then run independently on top of the same data.
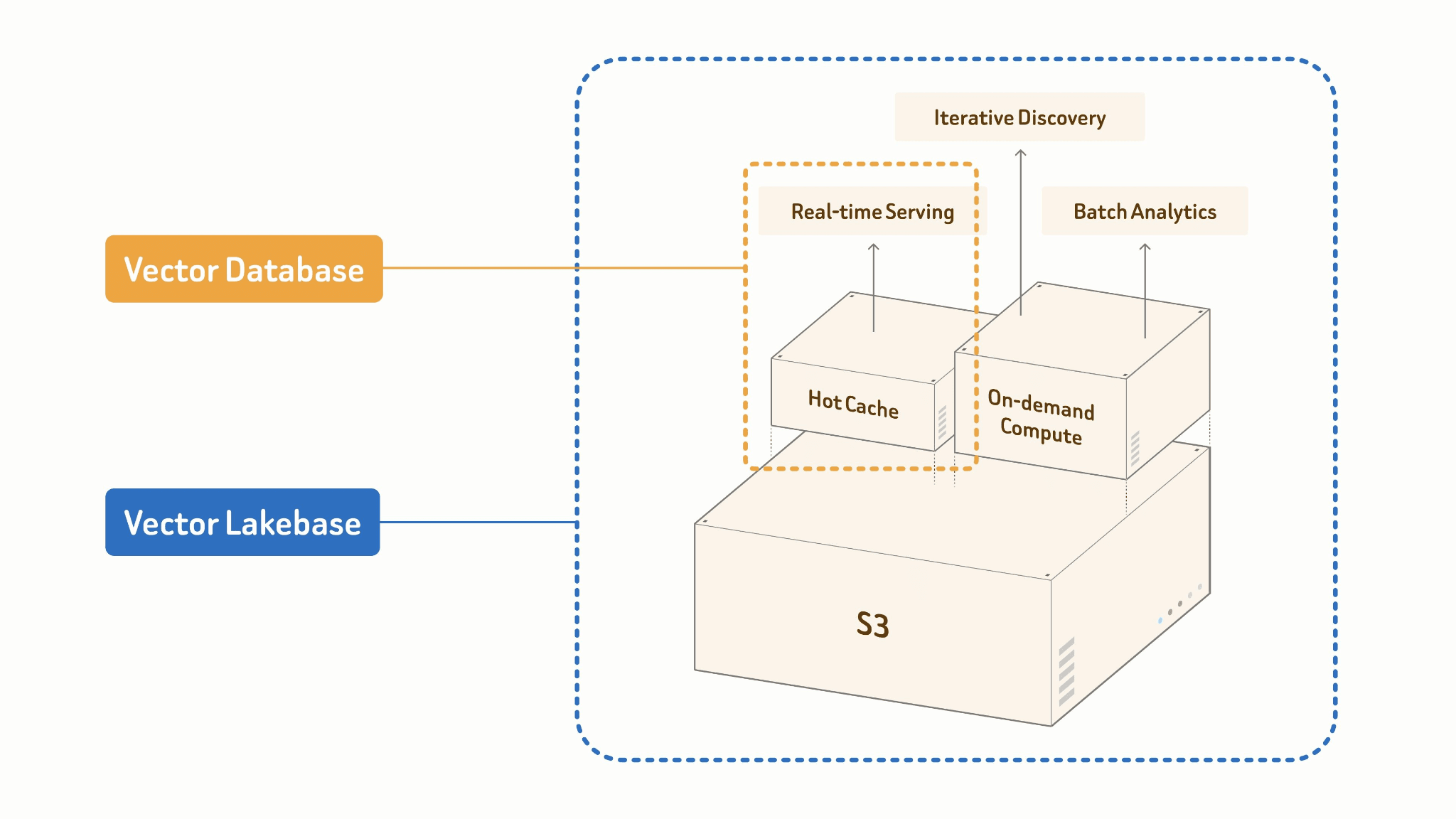
The core principle: One Source of Truth.
Your lake table is the single source of truth. Online serving and offline batch processing share the same data, index, and schema. There is no pipeline between them because there is no boundary between them.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplication + staleness
Vector Lake: [Lake + Index] ◀── batch query only # no serving, no processing
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + High-performance Index
│ → ANN query, <100ms p99 serving
└── Offline: Batch Processing + Cost-efficient Index Build
→ embed, cluster, dedup, feature engineering
The two modes are designed differently by necessity. Online serving runs against a hot cache and a high-performance in-memory index — optimized for concurrency and tail latency. Offline batch jobs build indexes cost-efficiently at scale: columnar scans, GPU-accelerated construction, staged writes back to the lake. Same data, same index format, radically different compute profiles.
What does this look like in practice? On a 1-billion-vector Iceberg table:
| Mode | Latency | Context |
|---|---|---|
| Spark brute-force scan (no index) | Hours | Today's default for lake-based vector search |
| Vector Lakebase — cold (index just built) | ~30 seconds | Index builds from Iceberg in ~20 minutes |
| Vector Lakebase — warm (disk cache) | Double-digit ms | Index cached on local SSD |
| Vector Lakebase — hot (in-memory) | Single-digit ms | Production RAG and agent serving |
| Vector Lakebase — clustering / dedup | Hours | 1B-vector KMeans or near-duplicate detection, fully distributed |
You go from hours to single-digit milliseconds — and you never copy the data out of the lake.
This isn't a product choice. It's the direction AI data architecture is converging toward. Any system that requires data to exist in two places charges you a permanent tax — in storage, in engineering hours, in staleness. Systems that separate storage from AI operations will look transitional in hindsight.
What a Vector Lakebase Actually Enables
At least three classes of workloads that previously required separate systems can now be handled with a vector lakebase.
External Collections: Make Your Lake Searchable Without Moving Anything
You have petabytes of embeddings in Parquet files on S3. Making them searchable for a new RAG application today means loading into a vector database — a migration measured in days or weeks, plus an ongoing sync obligation.
Vector Lakebase's external collections work with data gravity instead of against it. You point at the bucket, define a schema mapping over your existing columns, and build a vector index in place. Data stays in S3. The index persists back to S3. When source data updates, you refresh incrementally — only changed files are reprocessed.
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
No migration, no pipeline, no new storage cost. Your RAG system queries the same data your analytics team already governs — through Spark, Ray, LangChain, PyMilvus, or a REST API. The index becomes a first-class property of the table, not a foreign system bolted alongside it.
ETL, Feature Engineering, and Context Engineering
This is the workload that Vector Database and Vector Lake both ignore — and it's becoming the most important part of the AI data stack.
AI-native data operations don't just move data between systems — they enrich it with semantic meaning, in place, at scale:
- Add an embedding column to an existing table: batch-infer across 100M rows, write results back to the same table.
- Chunk a document corpus for RAG, keeping raw documents and chunks versioned together.
- Upgrade from text-embedding-3-small to a newer model — backfill all 500M vectors in place, with old and new embeddings coexisting until you cut over.
- Build and version the context packages your AI agents retrieve at runtime — what gets retrieved, how it's structured, how it's compressed for a context window.
As models commoditize, the quality of what you feed them matters more than which model you pick. This emerging discipline — Context Engineering — belongs in the lake: close to the data, versioned alongside it, reproducible end-to-end. Vector Lakebase makes it a first-class operation, not ad-hoc scripts glued together with cron jobs.
Clustering, Deduplication, and Anomaly Discovery
Essential for every team training or fine-tuning their own models — and entirely absent from the vector database paradigm:
- Deduplication: Near-duplicate examples in your LLM fine-tuning dataset inflate the training loss and bias the model's behavior. Identify near-duplicates, emit a canonical set, write dedup labels back as a column.
- Clustering: Understand what your dataset actually contains before training. Cluster your embedding space — you'll often find that 40% of a "diverse" dataset is minor variations on the same few topics.
- Anomaly discovery: For autonomous vehicles, robotics, or any safety-critical model — find the 0.1% of samples that look nothing like the rest. Flag them, prioritize for labeling, and include them in training. You can't find them without an index; you can't act on them without writing results back to the lake.
Vector Lakebase treats these as first-class distributed operations: index-aware, parallelized across data where it lives, writing results in open formats. The output of a deduplication run becomes a column in the same table.
Who's Already Building on This
Vector Lakebase's earliest design partners span two of the hardest AI data problems at scale.
Leading autonomous driving and EV companies use it to mine corner cases from billions of driving scene embeddings — the rare road scenarios that determine whether a self-driving system is safe. A top foundation model company uses it for near-duplicate detection across pre-training corpora — deduplicating billions of examples to improve model quality before a single GPU hour is spent on training.
We Already Have Databricks Lakebase. Do We Need Another One?
It's a fair question, and the answer requires understanding what Databricks Lakebase actually is.
Databricks Lakebase — built on their acquisition of Neon — integrates a serverless PostgreSQL engine into the Databricks platform. The problem it solves: OLTP and OLAP have always been separate systems. Databricks is collapsing that boundary. That's a real problem worth solving. But it's a fundamentally different problem.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| Primary user | Backend engineers, data engineers | ML engineers, AI platform teams |
| Primary data | Rows, accounts, transactions | Embeddings, documents, multimodal |
| Storage model | Postgres storage + Delta Lake (separate) | Single lake table, unified |
| Batch embedding / dedup | Not in scope | First-class operation |
| Context Engineering | Not in scope | Core capability |
| Builds on the existing lake | Partial | Yes — zero migration |
| Format optimization | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, native unstructured data |
| OLTP (transactions) | ✓ | N/A |
Databricks Lakebase collapses the OLTP/OLAP boundary. Vector Lakebase collapses the boundary between where your AI data lives and where your AI operations run. These are complementary, not competitive. Many teams will use both.
The Architectural Bet
In 2013, Databricks asked: What if SQL analytics lived in the lake? That question was worth $40 billion.
The next question is: What if AI-native data operations — RAG retrieval, agent memory, batch embedding, model training data curation, context engineering — lived in the lake too?
That's the bet behind Vector Lakebase. Not a new database to migrate to. Not a query layer bolted onto your existing lake. A unified foundation where your data lives once, is indexed once, and serves every AI workload — without duplication, without ETL overhead, without fighting gravity.
The AI race rewards speed. Every week your team spends building sync pipelines, debugging stale data, or migrating between systems is a week your competitors spend shipping AI features. Infrastructure should be an accelerator, not a bottleneck. The teams that win aren't the ones with the best models — they're the ones who removed the friction between their data and their AI.
Build on your existing Iceberg tables or data lake. No migration. No duplication. Move fast — your data stays where it is, and becomes searchable, processable, and AI-ready in minutes.
That's Vector Lakebase.
Zilliz Vector Lakebase is available in public preview
We've launched the public preview of Zilliz Vector Lakebase — a major evolution of Zilliz Cloud from a managed vector database to a unified semantic data platform, combining low-latency vector serving with the openness, scalability, and economics of a data lake.
Zilliz Vector Lakebase core capabilities:
- Tiered serving optimized for different real-time performance-cost trade-offs
- On-demand search for large-scale or exploratory workloads without always-on compute
- External data lake search — index and search directly over your existing lake data
- Full-spectrum search across vectors, text, JSON, and geospatial data with hybrid retrieval and reranking
- Unified lake-native storage built on Vortex, an open format with faster and cheaper random reads than Lance or Parquet
If your current stack splits serving and discovery into separate systems, Vector Lakebase might be worth a look. Try it on Zilliz Cloud — new work email signups get $100 free credits — or talk to us about your use case.

Keep Reading

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.