




Zilliz Cloud On-Demand Compute: Pay Only for What You Use
Last quarter we worked through a billing case with an autonomous-driving customer. Their analytics team needed vector search on a 1B-row collection. We sized it on a Dedicated cluster: $7,000/month. We tried Serverless: $10,800. The actual analytics work was a few hours a month.
Both bills were correct. Both products were doing exactly what they're designed to do. The problem was that this customer's workload — sparse analytics sharing a dataset with two other production workloads — didn't match what either product was designed for.
That case is what we built Zilliz Cloud On-Demand Search for — one of the new capabilities we shipped with the Zilliz Vector Lakebase launch. Same workload, under $500/month. Below is what didn't fit, what we changed, where On-Demand is the wrong tool, and how it fits back into Vector Lakebase at the end.
The customer case
The collection — about 1 billion records — was already in use by two production workloads:
- An online retrieval service serving real-time traffic.
- A model-training pipeline that pulls scenario data for regression jobs (run by a separate team).
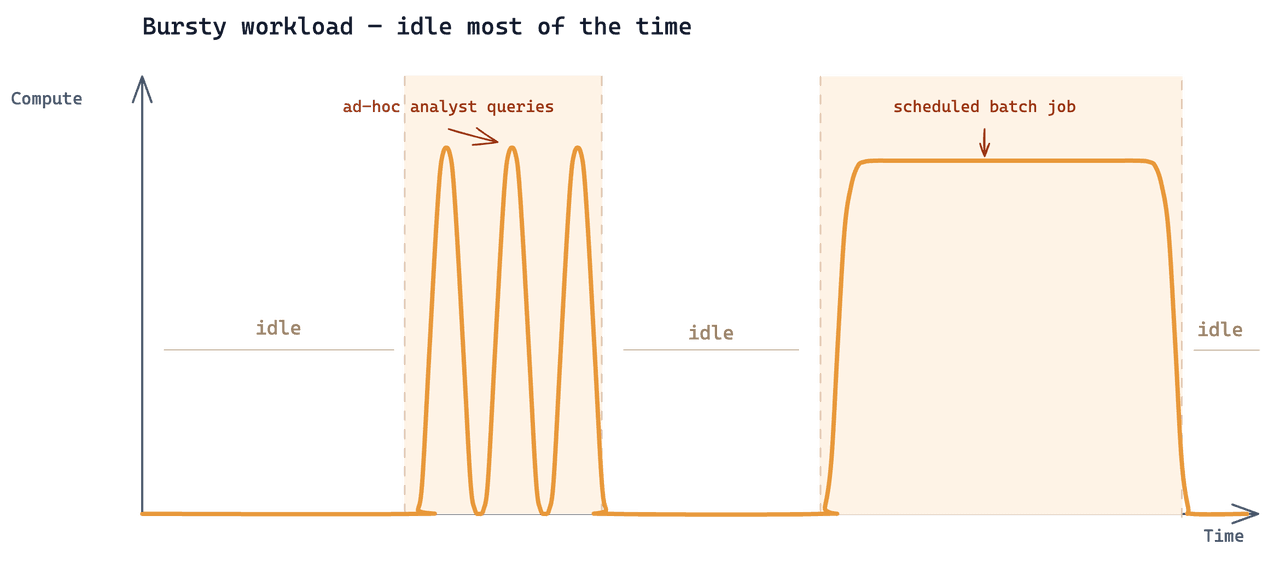
Analytics was a third workload being added on top of the same data. The access pattern: analysts only ran searches when they had a specific question, in short iterative bursts driven by the current investigation. The rest of the time, no analytical queries hit the cluster.
This is a fairly common Zilliz use case at a fairly common data scale. What made it hard was that all three workloads needed to read from the same underlying collection, and each one had a very different cadence.
Why the Dedicated Cluster didn't fit
The existing setup was a Zilliz Cloud Tiered cluster at 24 CU. Adding the analytics workload to it priced at ~$7,000/month. The cluster bills for every hour it exists: 24 × 30 = 720 hours/month. Real analytics work consumed 2–3 hours. The remaining 717 hours billed for sitting idle — 99.6% of total spend went to capacity that nobody used.
You can stop a Dedicated cluster between sessions to avoid the idle hours. We considered it. It doesn't work, for two reasons.
First, cold start on Dedicated takes 10+ minutes for analytical cold queries on a dataset this size. Dedicated's mental model is that all required data has to be in local memory before queries run, so it preloads the entire working set — typically tens to hundreds of times the data a single cold query actually touches. The same load also has to bring up state for non-query work the cluster supports, like DDL and deletes. That overhead exists whether or not the next query needs it.
Second, billing rounds to the hour. So even if the analyst was willing to wait 10+ minutes for the cluster to warm up, the bill for a single query is still one hour plus the load. With analysts running in short iterative bursts, the cost-per-useful-query stays high no matter how diligent the start/stop discipline.
Why the Serverless Cluster didn't fit
Serverless was the next option we tried. On paper it's the right shape for this access pattern: stateless, pay-per-query, no idle compute. For the analytics workload by itself, it could have worked.
The catch is that Serverless on this dataset doesn't price the analytics workload in isolation. It prices everything that touches the collection. Once we included the existing workloads, three line items broke the math:
- Queries: ~$6,000/month. Most of it from the model-training team's bi-weekly regression jobs — 100 QPS for 3 hours, every two weeks. Serverless unit prices fold in a cold-query premium that gets paid on every query, even when the query is hot. Once query volume isn't trivially low, it stops penciling out.
- Storage: $1,700/month. Metered separately because Serverless has no compute-hour fee to fold storage into.
- Writes: $3,000/month. Same reason — no compute-hour to fold into.
Total: $10,784/month, higher than the Dedicated cluster we were trying to escape from.
Each of those premiums has a structural reason behind it.
Queries carry a cold-query premium. From the user's side, Serverless is stateless. From the platform's side, data still has to be loaded onto specific machines to execute. Queries split into hot (data already on the machine) and cold (object-storage fetch first). Hot queries are cheap; cold queries are expensive. The platform can't predict which queries will be cold for any given user, so it spreads the cold-query cost across every query's unit price. Workloads with mostly-hot queries end up paying for everyone's cold ones.
Storage is priced above marginal cost. In Dedicated, storage and write costs ride on the compute-hour fee invisibly. Serverless has no compute-hour fee for those costs to hide behind, so storage is charged explicitly. That explicit price has to cover data that's stored but never queried — the platform can't drop it to deeply cold storage because data has to stay query-ready at any moment. Maintaining that readiness requires extra state, and its cost ends up amortized onto storage size, which doesn't actually correspond to real consumption.
Writes are also priced above marginal cost. Writes are metered separately to keep users from issuing high-frequency updates that produce a lot of write cost without growing the dataset (which would otherwise leave the platform absorbing the cost). Same dynamic as storage: the readiness state's cost rolls into the per-write unit price.
The deeper issue is that Serverless hides the "compute resource" abstraction from the user. The user sees a stateless interface; the platform still has to pay for unpredictable access patterns behind it — hot/cold data, bursty traffic, idle storage that has to stay query-ready. Those costs can't be precisely attributed to specific users, so they get amortized into the unit prices of queries, storage, and writes. Every billable action ends up a notch above its real marginal cost.
This is a "shared risk" model: every line item carries a surcharge to cover someone else's cold queries, bursts, or idle storage. The workloads least responsible for that variance — stable, high-frequency, predictable hot queries — pay the largest premium share. The more stable your workload, the more you end up subsidizing.
What the customer actually needed
Stepping back, the customer's ask wasn't exotic. One dataset, multiple access cadences, with the bill following only the compute each cadence actually used.
- Online retrieval: continuous, low-latency, predictable. Dedicated is right for this.
- Model training: bursty but predictable — 3 hours every two weeks.
- Analytics: sparse and unpredictable — a few minutes at a time, with long gaps.
Dedicated couldn't deliver that. It bills for provisioned capacity, not consumption. Serverless couldn't either: its per-query unit price has to subsidize cold queries, idle storage, and burst headroom across all users on the platform, so stable workloads end up paying for variance they don't generate.
What we needed was a third compute model — one that could attach to the same data as Dedicated, spin up fast enough to make per-query billing realistic, and bill only when actually running.
What we changed
On-Demand is a separate compute model on Zilliz Cloud that lives alongside Dedicated and Serverless. It changes three things compared to either:
- Cold start. Load only the chunks the current query touches, not the full working set. Drops from 10+ minutes to seconds.
- Billing. Per minute of actual compute uptime. Writes too. No minimum hour, no per-query cold/hot premium.
- Isolation. Each workload attaches to a collection through its own compute resource group. Same data, no contention.
The next three sections walk through each one.
Loading less data, faster
The 10-minute cold start on Dedicated exists because the cluster has to pull the full working set into local memory before serving queries. On a 1B-row collection, that's tens to hundreds of times more data than any single query actually needs. Compressing cold start to seconds means dropping that assumption: load only what the current query touches.
That sounds like one sentence; in practice it required redesigning three layers — what to read, where to put it, and how to bring it up.
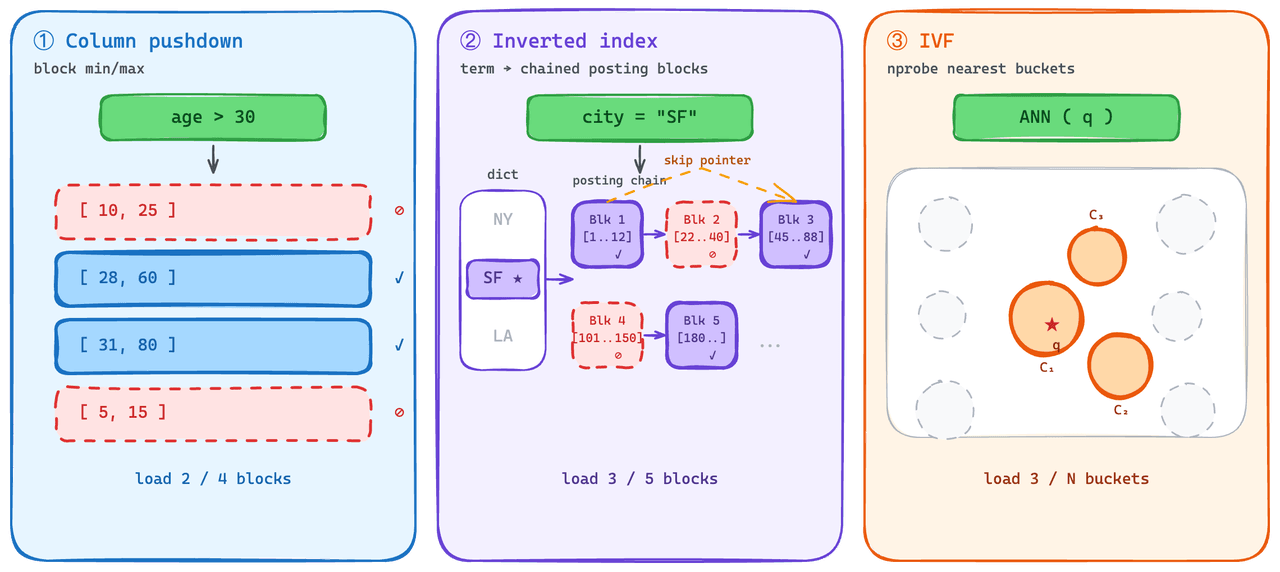
Indexes that load partially.
On the scalar side, predicate pushdown is standard practice. The engine eliminates blocks that can't match the predicate and skips fetching them. We use this on inverted indexes: each posting list loads as a block, and each list carries min/max statistics that the engine can check before fetching.
The harder part was giving the vector side a comparable "read a subset" capability. Graph indexes — the higher-performance option for steady-state QPS — don't degrade gracefully under partial loading: the structure has to be loaded in full to be useful, so the cold-load cost is high.
On-Demand uses the IVF family instead. IVF clusters vectors into buckets at index time, and at query time only the closest buckets to the query are fetched. That gives the vector side something close to predicate-pushdown semantics: cold queries pull a small fraction of the index, not the whole thing.
This is a deliberate trade-off. We lose the steady-state performance of graph indexes, which is the main reason On-Demand isn't a fit for high-QPS serving (more on that below). For sparse and bursty workloads, the trade is worth it.
A three-tier data path.
Once we know what to read, the next question is where to keep it. Chunks flow freely between S3, local disk, and memory, and the cache lifecycle is managed per chunk between queries: chunks the current query needs are pulled up; chunks that stay idle long enough get evicted. The same dataset can be queried at very different cadences, and none of them pays the cost of loading data they don't touch.
Each tier has its own data layout and granularity, adapted to the IO characteristics of the medium — the alignment that works for object storage isn't the alignment that works for local disk, and neither matches what the engine executes against in memory.
Async IO end to end.
The IO chain is fully asynchronous. Compute and IO are pipelined the whole way through, so CPU doesn't sit waiting on a fetch and IO bandwidth doesn't sit waiting on compute.
In aggregate, chunked + tiered + async drops the cold-query payload to under 1–2% of the full dataset and the end-to-end cold path to seconds.
Per-minute billing
With cold start at the second level, "spin up compute when a query arrives, release it when it ends" works as an actual product mechanism — not just a design aspiration. Two pieces of the control plane do the heavy lifting.
A standby node pool. Image pulls add latency to bringing up a fresh node. We keep a small pool of pre-pulled nodes ready, so spin-up draws from the pool instead of starting from scratch.
TTL-based release. Each session has a configurable idle timeout. Compute releases automatically when the timeout fires, the query workload ends, or the session is closed. The whole lifecycle is platform-scheduled — no "forgot to stop my cluster" mode, no manual ops.
Because the lifecycle is fine-grained, billing granularity drops to match. Compute is billed per minute of actual uptime — no minimum hour, no minimum charge per query. Writes are metered the same way: actual resource use, per minute.
The cost-attribution precision is what lets On-Demand avoid the storage premium Serverless has to charge. Serverless prices storage above marginal cost because its compute layer has no way to absorb unattributed cost — every dollar the platform spends has to land somewhere on the bill, so storage and writes become the dumping ground for what can't be attributed elsewhere. When On-Demand bills every minute of compute to a specific session, there's no unattributed pool. Storage on On-Demand follows Zilliz Cloud pricing at Dedicated rates — about 1/10 of typical Serverless storage.
Workload isolation on shared data
The third change is making the compute layer explicit. On Dedicated, the compute layer is the cluster — invisible to the user except as a single sizing parameter. On Serverless, the compute layer is hidden entirely. On-Demand exposes it.
Each workload attaches to a collection through a compute resource group. New groups are spun up — or existing ones reused — via sessions. Different groups are isolated from each other, and each group's bill reflects only its own consumption.
For the autonomous-driving case, that's how the analytics workload gets its own attachment to the data: an On-Demand resource group that spins up for ad-hoc queries and releases on idle, running on the same Milvus collection, the same indexes, and the same metadata as the existing online retrieval and model-training workloads. Storage-compute separation means none of them has to copy or sync data to use it. No cross-subsidization, no scheduling contention, no operational coordination between teams about cluster shape.
This is the same architectural pattern as a data lake, applied to vector search: storage is the shared substrate, and compute attaches in whatever shape each workload needs.
The bill, after
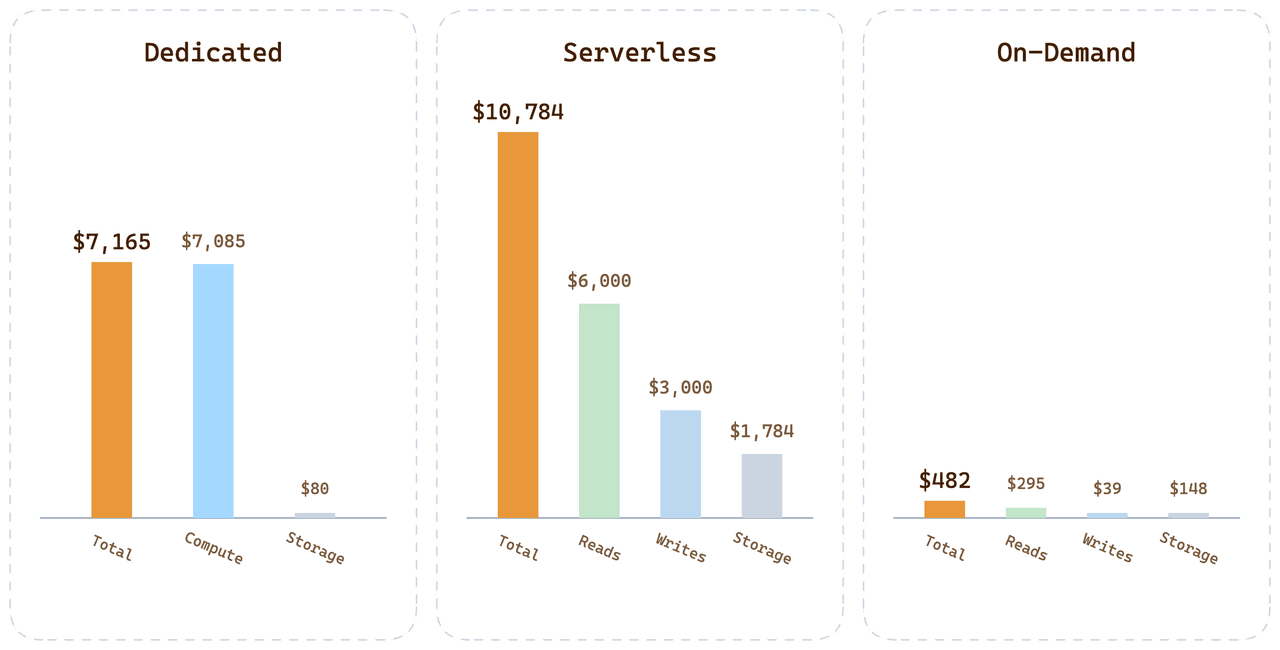
For the same customer workload across all three options:
| Option | Monthly bill | Where the money goes |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 99.6% of compute paid for but idle |
| Serverless | $10,784 | Query premium + $1,700 storage + $3,000 writes |
| On-Demand | < $500 | Per-minute compute + Dedicated-rate storage |
On-Demand for this workload comes in at under 1/20 of the Serverless bill. The delta isn't a pricing trick; it's the direct consequence of attributing cost to real consumption instead of amortizing other users' variance into every unit price.
Where On-Demand is the wrong tool
On-Demand isn't a universal replacement for Dedicated or Serverless. The same design choices that make it cheap for sparse, bursty workloads make it the wrong fit for others. The chart below plots monthly cost against query pressure for this customer's workload across all three options.
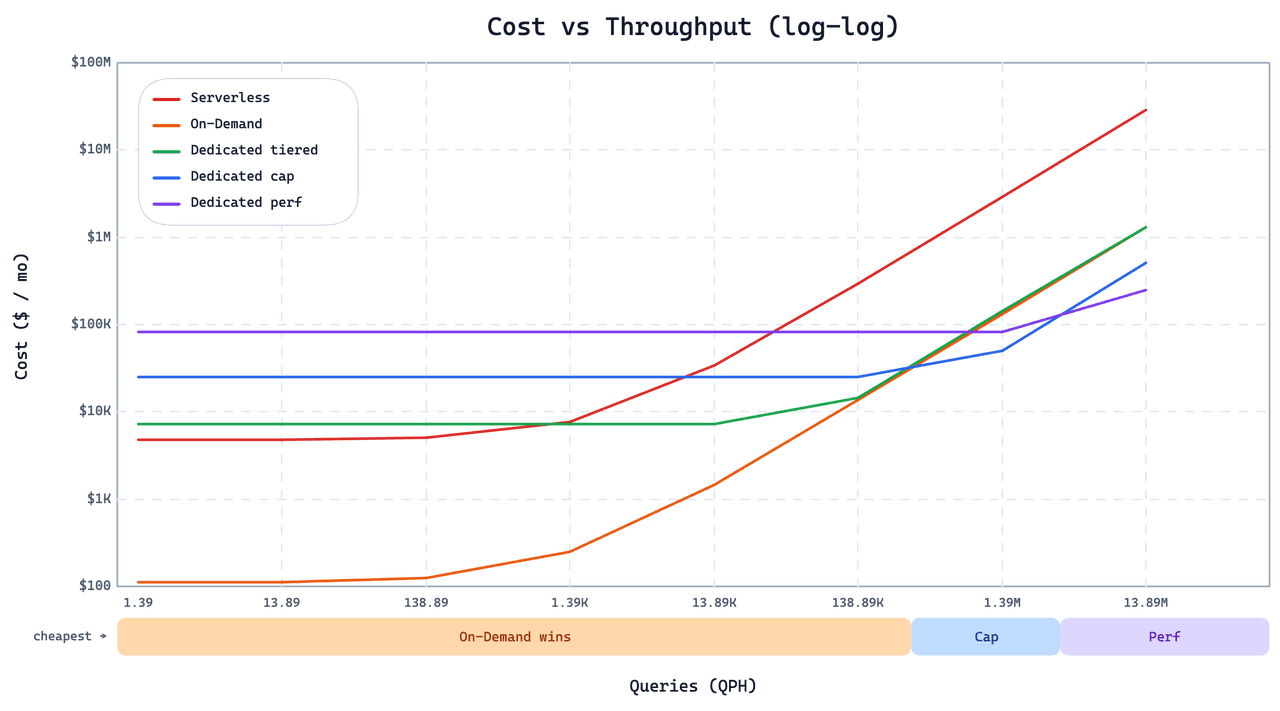
Below the crossover, On-Demand is significantly cheaper. Once QPS crosses into the tens, Dedicated Cap or Perf instances become both cheaper and faster. Two design decisions explain the crossover:
No graph index. To keep cold-query loading cheap, On-Demand uses IVF instead of graph indexes. Graph indexes deliver higher steady-state QPS at scale, but their cold-load cost is high. Above a few dozen QPS, the steady-state advantage wins decisively. For high-QPS serving, use Dedicated.
Higher tail latency on cold queries. On-Demand doesn't preload data, so a cold query pays an extra fetch before it can run. Warm queries are fast; cold ones are noticeably slower, and the tail latency distribution is wider than on Dedicated or Serverless. If your application can't tolerate occasional second-level (or worse, minute-level) responses, On-Demand isn't right. For those workloads, Smart Autoscaling on Dedicated trims idle capacity without sacrificing warm-state latency.
Where On-Demand is the right tool: sparse access, analytical iteration, and batch mining on large datasets — workloads where high concurrency and tight latency consistency aren't the primary requirements.
Where this fits in Zilliz Vector Lakebase
The customer case in this post is one slice of a larger pattern: the same dataset, accessed at different cadences by different workloads, sized correctly only when each workload gets the compute shape it actually needs. On-Demand is one of the compute shapes. Zilliz Vector Lakebase is the architecture that makes the rest possible.
A Vector Lakebase is a lake-native data platform for AI workloads. Data sits on S3, indexes are decoupled from compute, and different compute shapes attach to the same collection through zero-copy access. It handles three workload modes as first-class capabilities — real-time retrieval, iterative discovery, and batch analytics — each served by the compute shape that fits its access pattern. Vector retrieval has always been a first-class workload on Zilliz Cloud; with the Vector Lakebase launch, iterative-discovery and batch-analytics compute shapes join it on the same data foundation.
On-Demand is the compute shape built for analytical and bursty workloads. The other four capabilities cover the rest of the modes:
- Tiered Serving Solutions for real-time retrieval — Performance-Optimized (1000+ QPS, single-digit ms latency, all in memory), Capacity-Optimized (100–500 QPS at sub-100 ms latency on memory + local NVMe), and Tiered-Storage (10–50 QPS at ~100 ms latency across memory, NVMe, and object store). Different points on the performance/cost curve, same serving mode.
- External Data Lake Search for indexing and searching data already sitting in Lance, Iceberg, or other lake formats — without copying it into a separate store.
- Full-Spectrum Search for vectors, text, JSON, and geospatial on one query plane, with hybrid retrieval, filtering, and reranking on a wide-table data model.
- Unified Lake-Native Storage built on Vortex, a next-generation open columnar format with faster random reads than Lance or Parquet, plus per-column format flexibility.
Zilliz Vector Lakebase is now in public preview on Zilliz Cloud. For the full architecture and the rest of the capabilities, the Vector Lakebase deep-dive is the canonical read.
To try On-Demand on your own workload, sign up on Zilliz Cloud and spin up an On-Demand cluster from the console or CLI. If the numbers in this post mapped onto something you're running, the Zilliz team is happy to walk through your workload before you build.

Keep Reading

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.