




ラマ3、Mixtral、GPT-4oを使用中
RAGのGジェネレーション・パートを実行するには、実に様々な方法がある! 今日は、この分野で最もホットな候補のいくつかを実行する方法をいくつか紹介しよう:MetaのLlama 3、MistralのMixtral、そして最近発表されたOpenAIのGPT-4oだ。
下のLMSYS Leaderboardからわかるように、今週、OpenAIの新しい発表によって、クローズドソースモデルとオープンソースモデルの間の差(水色)は、ますます広がっています。
クローズドソース vs オープン](https://assets.zilliz.com/closed_source_vs_open_0f3e484a2d.png)
画像ソース https://chat.lmsys.org/?leaderboardを基にhttps://twitter.com/maximelabonne。
このブログの概要
オープンソースのLlama 3やMixtralを最速で動かす方法
Ollamaでローカルに
Anyscaleエンドポイント
OctoAIエンドポイント
Groqエンドポイント
OpenAIから最新のgpt-4oを実行する
答えを評価するGPT-4o, Llama 3, Mixtral
始めよう!
Ollamaを使ってLlama 3をローカルで動かす
まず、RAGのGパートである答えを生成する最後のステップまで、通常の方法でRAGを実行する。 PythonでRAGを始めるためのチュートリアルがたくさんあります。
Ollamaを使ってLlama 3をローカルで実行する。
1.instructions](https://github.com/ollama/ollama)に従ってollamaをインストールし、モデルをプルします。
2.そのページによると、ollama run llama3はデフォルトで最新の "instruct "モデルを引っ張ってくる。 そのコマンドを実行してください。
3.Pythonの場合は、pip install ollama。
4.RAGのPythonコードで、プロンプトと質問を定義し、ローカルにインストールしたLlama 3モデルへのAPIコールを呼び出します。
私の場合、M2 16GBのラップトップを持っているので、ダウンロードしたOllamaモデルは、Llama3-8Bの最高量子化ggufコンパイルバージョンです。つまり、Llama 3の非常に小さなバージョンが私のラップトップにインストールされているのです!
# すべてのコンテキストをスペースで区切り、逆順に並べる。
# Lost in the middle" arxiv.org論文を参照。
contexts_combined = ' '.join(reversed(contexts))
source_combined = ' '.join(reversed(sources))
# プロンプトを定義する。
SYSTEM_PROMPT = f"""提供されたコンテキストが与えられている場合、あなたのタスクは次のとおりです。
内容を理解し
に正確に答えることです。
完全で、明確で、簡潔で、適切な回答を4文以内で述べてください。
また、独自の情報源を引用すること。
答え質問に対する答え。
ソースソース:{source_combined}
コンテキストコンテキスト: {contexts_combined}
"""
# 質問とプロンプトをローカルに送る!
import ollama
start_time = time.time()
response = ollama.chat(
messages=[
{"role":"system", "content":system_prompt,}、
{"role":"user", "content": f "質問:{sample_question}",}.
],
model='llama3'、
stream=False、
options={"temperature":TEMPERATURE, "seed":RANDOM_SEED、
"top_p":TOP_P、
# "max_tokens":MAX_TOKENS, # 認識されない
"frequency_penalty":frequency_penalty}.
)
ollama_llama3_time = time.time() - start_time
pprint.pprint(response['message']['content'].replace('\n', ' '))
print(f "ollama_llama3_time:{format(ollama_llama3_time, '.2f')} seconds")

答えはかなり良さそうだ。3つのパラメーターが見えるが、引用だけが文字化けしているように見える。ローカルモデルは私のラップトップで推論を実行するのに13秒かかったが、コストは無料だった。
AnyscaleのエンドポイントからLlama 3を実行する。
AnyscaleのエンドポイントからLlama 3の推論を実行する:
1.Anyscale endpoints](https://github.com/simonw/llm-anyscale-endpoints) githubページの指示に従ってコマンドラインをインストールし、プラグインをインストールします。
2.AnysclaeエンドポイントAPIトークンを取得し、環境変数を更新する。
3.Pythonの場合は pip install openai.
4.4.HuggingFaceからダウンロードしたLlama 3モデルについて読み、OpenAI APIを使って呼び出す。 私は、Anyscale playgroundのデフォルトのラマ3(70B-Instructモデル)を使った。
インポート openai
LLM_NAME = "meta-llama/Llama-3-70b-chat-hf"
anyscale_client = openai.OpenAI(
base_url = "https://api.endpoints.anyscale.com/v1"、
api_key=os.environ.get("ANYSCALE_ENPOINT_KEY")、
)
開始時間 = time.time()
response = anyscale_client.chat.completions.create(
messages=[
{"role":"system", "content":system_prompt,}、
{"role":"user", "content": f "質問:{sample_question}",}.
],
model=LLM_NAME、
temperature=TEMPERATURE、
seed=RANDOM_SEED、
frequency_penalty=FREQUENCY_PENALTY、
top_p=TOP_P、
max_tokens=MAX_TOKENS、
)
llama3_anyscale_endpoints_time = time.time() - start_time
# 応答をプリントする
pprint.pprint(response.choices[0].message.content.replace('\n', ' '))
print(f "llama3_anyscale_endpoints_time:{format(llama3_anyscale_endpoints_time、'.2f')}秒")
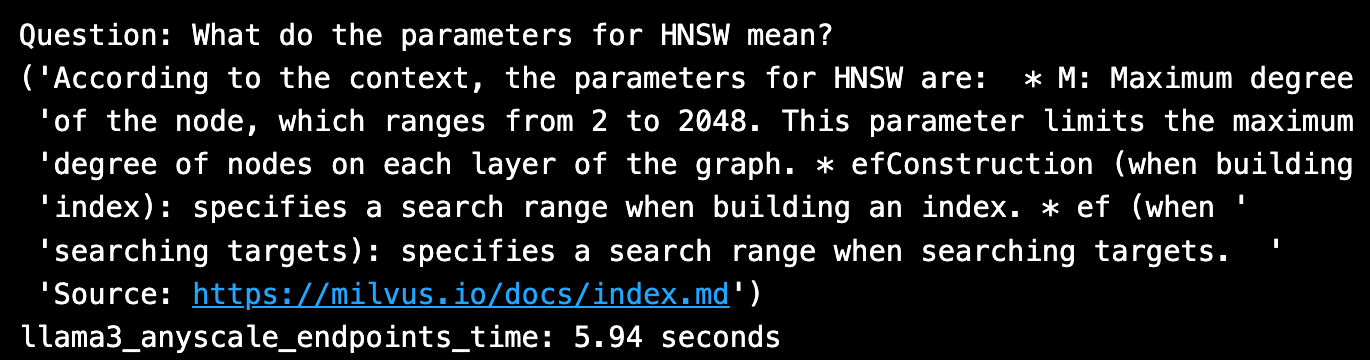
完璧な引用を含め、答えは良さそうだ。HuggingFace Llama 3 70Bは、Anyscaleエンドポイントからの呼び出しに〜6秒かかりました。
OctoAI エンドポイントからのラマ3の実行
OctoAIのエンドポイントからLlama 3の推論を実行する:
1.https://octoai.cloud/textにアクセスし、Llama 3 8Bモデルを選択し、モデルのリンクをクリックするとサンプルコードが表示されます。
2.OctoAIのエンドポイントAPIトークンを取得し、環境変数を更新してください。
3.Pythonの場合は、pip install octoai。
4.MetaからダウンロードしたLlama 3 8Bモデルを読み、起動する。
from octoai.text_gen import ChatMessage
from octoai.client import OctoAI
LLM_NAME = "メタ-ラマ-3-70b-インストラクト"
Octoai_client = OctoAI(
api_key=os.environ.get("OCTOAI_TOKEN")、
)
開始時間 = time.time()
response = octoai_client.text_gen.create_chat_completion(
メッセージ=[
チャットメッセージ(
content=SYSTEM_PROMPT、
role="system"
),
チャットメッセージ(
content=SAMPLE_QUESTION、
role="user"
)
],
model=LLM_NAME、
temperature=TEMPERATURE、
# seed=RANDOM_SEED, # 認識されない
frequency_penalty=FREQUENCY_PENALTY、
top_p=TOP_P、
max_tokens=MAX_TOKENS、
)
llama3_octai_endpoints_time = time.time() - start_time
# 応答をプリントする
pprint.pprint(response.choices[0].message.content.replace('\n', ' '))
print(f "llama3_octai_endpoints_time:{format(llama3_octai_endpoints_time、'.2f')}秒")

答えは良さそうだし、引用も完璧だ。Llama 3 70BはOctoAIのエンドポイントから呼び出すのに~4秒かかりました。
Groq LPUエンドポイントからLlama 3を実行する
GroqエンドポイントからLlama 3推論を実行する:
1.console.groq.com](http://console.groq.com)にアクセスし、指示に従ってください。
2.Groqエンドポイント APIトークンを取得し、環境変数を更新します。
3.Pythonの場合は、pip install groq。
4.HuggingFaceからダウンロードしたLlama 3 8B modelを読み、起動する。
from groq import Groq
LLM_NAME = "llama3-70b-8192"
groq_client = Groq(
api_key=os.environ.get("GROQ_API_KEY")、
)
開始時間 = time.time()
response = groq_client.chat.completions.create(
messages=[
{"role":"system", "content":system_prompt,}、
{"role":"user", "content": f "質問:{sample_question}",}.
],
model=LLM_NAME、
temperature=TEMPERATURE、
seed=RANDOM_SEED、
frequency_penalty=FREQUENCY_PENALTY、
top_p=TOP_P、
max_tokens=MAX_TOKENS、
)
llama3_groq_endpoints_time = time.time() - start_time
# 応答をプリントする
pprint.pprint(response.choices[0].message.content.replace('\n', ' '))
print(f "llama3_groq_endpoints_time:{format(llama3_groq_endpoints_time、'.2f')}秒")

答えは少し簡潔になり、引用も完璧です。Llama 3 20Bは、Groq LPUエンドポイントからの呼び出しに~1秒かかり、これはこれまでの最速推論である!
LLM_NAMEを各エンドポイントプラットフォームがMixtralモデルに使用する名前に変更するだけです。
OpenAIからGPT-4oを実行する
OpenAIから最新のGPT-4o推論を実行します:
5.OpenAIのAPIトークンを取得し、環境変数を更新する。
6.新しいモデルの呼び出し方は、説明書 に従ってください。
7.Pythonの場合は、pip install --upgrade openai --quiet。
8.新しいGPT-4oモデルについて読み、それを起動する。
import openai, pprint
from openai import OpenAI
LLM_NAME = "gpt-4o" # "gpt-3.5-turbo"
openai_client = OpenAI(
# これはデフォルトであり、省略可能である。
api_key=os.environ.get("OPENAI_API_KEY")、
)
start_time = time.time()
response = openai_client.chat.completions.create(
メッセージ=[
{"role":"system", "content":system_prompt,}、
{"role":"user", "content": f "質問:{sample_question}",}.
],
model=LLM_NAME、
temperature=TEMPERATURE、
seed=RANDOM_SEED、
frequency_penalty=FREQUENCY_PENALTY、
top_p=TOP_P、
max_tokens=MAX_TOKENS、
)
chatgpt_4o_turbo_time = time.time() - start_time
# 質問と答えを、根拠となるソースと引用とともに表示する。
print(f "Question: {SAMPLE_QUESTION}")
for i, choice in enumerate(response.choices, 1):
message = choice.message.content.replace('\n', '')
pprint.pprint(f "Answer: {message}")
print(f "chatgpt_4o_turbo_time:{format(chatgpt_4o_turbo_time, '.5f')}")
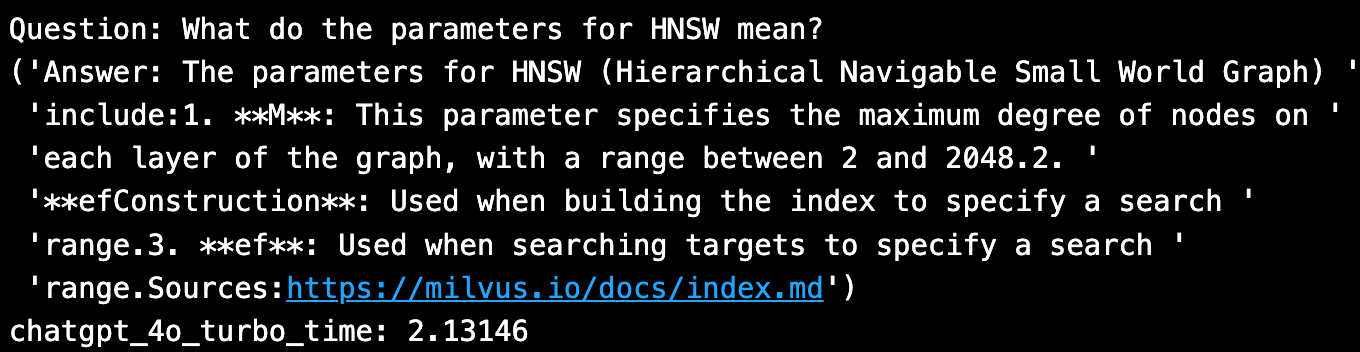
新しいGPT-4oモデルは、接地ソースの引用が含まれており、良さそうだ。推論の実行には2秒かかった。
Ragas を使ったクイックアンサー評価
オープンソースのRagasを使ってRAGシステムを評価する方法についてはこのブログで説明しました。 以下では1つのQ&Aしか使っていない。 より現実的な評価では、~20の質問を使用します。
import os, sys
import pandas as pd
np として numpy をインポート
import ragas, datasets
from langchain_community.embeddings import HuggingFaceEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
from ragas.metrics import (
# context_recall、
# コンテキスト精度
# 忠実度
answer_relevancy、
answer_similarity、
答えの正しさ
)
# グラウンドトゥルースの回答をファイルから読み込む
eval_df = pd.read_csv(file_path, header=0, skip_blank_lines=True)
# 評価するLLMモデルの選択肢:
# openai gpt-4o = 'Custom_RAG_answer'。
LLM_TO_EVALUATE = 'Custom_RAG_answer'.
# LLM_TO_EVALUATE = 'llama3_ollama_answer'
# LLM_TO_EVALUATE = 'llama3_anyscale_answer'
# LLM_TO_EVALUATE = 'llama3_octoai_answer'
# LLM_TO_EVALUATE = 'llama3_groq_answer'
# LLM_TO_EVALUATE = 'mixtral_8x7b_anyscale_answer'
CONTEXT_TO_EVALUATE='Custom_RAG_context'
eval_metrics=[
answer_relevancy、
answer_similarity、
answer_correctness,].
メトリクス=['answer_relevancy', 'answer_similarity', 'answer_correctness'].
# デフォルトのllm-as-criticを変更し、$を節約する。
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = ragas.llms.llm_factory(model=LLM_NAME)
# デフォルトのエンベッディングをHuggingFaceモデルに変更する。
EMB_NAME = "BAAI/bge-large-en-v1.5"
lc_embeddings = HuggingFaceEmbeddings(model_name=EMB_NAME)
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# 各メトリックを変更する。
for metric in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# 評価を実行します。
ragas_result, score = _eval_ragas.evaluate_ragas_model(
eval_df, eval_metrics, LLM_TO_EVALUATE、
コンテキスト_to_evaluate, evaluate_what)
# 結果を表示する。
print(f "Using {eval_df.shape[0]} eval questions, Mean Score = {score}")
表示(ragas_result.head())

以下は結果をまとめた表である。
| ---------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------- | -------------------------- | ---------------------- |
| モデル・エンドポイント** | アンサー | レイテンシ(秒) | コスト | ラガス・アンサースコア |
| Ollama Llama 3 | 提供されたコンテキストとソース[1, 65535]によると、HNSW(Hierarchical Navigable Small World Graph)には2つの主要なパラメータがある: * `M`:M`:グラフの各層のノードの最大次数。M`:グラフの各層におけるノードの最大次数。* ef`または `efConstruction`:このパラメータは検索範囲を指定し、インデックス構築時やターゲット検索時に使用することができる。 これらのパラメータはパフォーマンスを向上させることを目的としており、想起率(efを大きくすることで改善)と検索時間(M値を大きくすることで増加)のトレードオフをコントロールする。 | HNSWのパラメータは以下の通りである: * M: ノードの最大次数で、2~2048の範囲である。このパラメータは、グラフの各レイヤーのノードの最大次数を制限する。* efConstruction (インデックス構築時): インデックス構築時の検索範囲を指定する。* ef (ターゲット検索時): ターゲットを検索する際の検索範囲を指定する。 出典:`[` https://milvus.io/docs/index.md`](https://milvus.io/docs/index.md)`'` | `5.94` | `フリープレイグラウンド` | `0.80` | | HNSW のパラメータ M はノードの最大次数を意味する。その範囲は2~2048である。さらに、efConstruction と ef は、それぞれインデックス構築時とターゲット検索時の検索範囲を指定するためのパラメータである。 ソースは以下の通り:1.`[`https://milvus.io/docs/index.md`](https://milvus.io/docs/index.md)` 2. `[`https://milvus.io/docs/index.md`](https://milvus.io/docs/index.md)`'` | `3.57` | `自由な遊び場` | `0.79` | | HNSW (Hierarchical Navigable Small World Graph)のパラメータは以下の通りである: * M: ノードの最大次数で、2~2048の範囲。このパラメータは、グラフの各層におけるノードの最大次数を制限する。* efConstruction:インデックスを構築する際に使用するパラメータで、検索範囲を指定する。* ef:ef: ターゲットを検索する際に使用するパラメータで、検索範囲を指定する。 出典:`[` https://milvus.io/docs/index.md`](https://milvus.io/docs/index.md)` | `4.43` | `100万トークンあたり0.15ドル` | `0.73` | `Groq Llama 3` | `提供されたコンテキストによると、HNSWのパラメータは以下の通りである: * M: ノードの最大次数、2~2048の範囲。* efConstruction:インデックスを構築する際に使用するパラメータで、検索範囲を指定する。* ef:ef: 検索範囲を指定するためにターゲットを検索する際に使用するパラメータ。 出典: `[`https://milvus.io/docs/index.md`](https://milvus.io/docs/index.md) | `1.21` | `Free beta` | `0.79` | HNSW のパラメータは以下の通りである:- M: ノードの最大次数、各ノードがグラフ内で持つことができる接続を制限する。範囲は[2, 2048].``- efConstruction:インデックス構築時に使用するパラメータで、検索範囲を指定する:ターゲット検索時に使用するパラメータで検索範囲を指定する:[https://milvus.io/docs/index.md](https://milvus.io/docs/index.md) | 2.13 | $5/Mインプット $15/M output | 0.803 | `$5/M input
ソース著者のコードとhttps://console.anyscale.com/v2/playground, https://console.groq.com/playground?model=llama3-70b-8192, https://octoai.cloud/text?selectedTags=Chat, https://openai.com/api/pricing/。
結論
今日、RAGのG-Generationパートで選択できるモデルや推論エンドポイントには多くの選択肢がある! このブログで試したすべてのエンドポイントは、(GPTクリティックによって評価された)回答品質、待ち時間、および考慮すべきコストが異なります。

読み続けて

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.