




引用による検索拡張生成
大規模言語モデル(LLM)アプリから応答を得たとき、その応答がどこから来たのか知りたいと思いますか?それが引用や帰属の力です。このチュートリアルでは、なぜ引用を含めることが重要なのか、どのようにして高いレベルから引用を得ることができるのかを見て、コードの例に飛び込みます!
なぜRAG(Retrieval Augmented Generation)ソースを引用するのか?
Retrieval Augmented Generationは、LLMアプリで知識を補うために使われるテクニックです。一般的なLLMの主な弱点の1つは、最新またはドメイン固有の知識が不足していることです。これには主に2つの解決策があります:微調整と検索拡張生成です。
ここZillizやOpenAIのような他の企業では、ファクトベースの検索におけるファインチューニングの優れた選択肢としてRAGを提案している。ファインチューニングはより高価で、より多くのデータを必要としますが、スタイルトランスファーには良い選択肢です。RAGは、Milvusのようなベクトルデータベースを使用して、アプリに知識を注入する。
あなたの製品やドキュメントについてLLMに尋ねる代わりに、ベクターデータベースをあなたの真実のストアとして使うことができます。これにより、アプリが正しい知識を返すことが保証され、データ不足を補おうとして幻覚を見ることもなくなる。ドキュメントやユースケースを増やし始めると、その情報がどこにあるのかを知ることがますます重要になってくる。
そこで、引用と帰属の出番となる。LLMアプリからレスポンスを受け取ったとき、あなたはそのアプリがどうやってその情報を入手したかを知りたいと思うでしょう。引用や属性の付いた回答を得ることで、その回答がどのテキストのどの部分から得たものなのかがわかります。データが増えれば増えるほど、これは信頼できる回答を決定するために不可欠になります。
RAGの出典はどのように引用するのですか?
LLMは、Milvusのようなベクターデータベースのような隣接ツールの人気を押し上げた。また、LangChainやLlamaIndexのようなフレームワークも生まれた。このような人気の高まりの一環として、検索拡張世代は、特に内部データの情報検索に関しては必須のアプリとなっている。
データを検索するだけでなく、検索したデータに引用を加えることで、アプリがより強固になり、より説明しやすくなり、より多くの文脈を提供することに多くの人が気づいている。では、どうすればいいのか?多くの方法がある。ベクターデータベースがMilvusのようにメタデータをサポートしていれば、その中にテキストのチャンクを格納することもできますし、LlamaIndexのようなフレームワークを使うこともできます。このチュートリアルでは、LlamaIndexとMilvusを使って引用文献をRAGする方法を説明します。
ソースによる検索拡張生成の例
コードに飛び込みましょう。このチュートリアルを行うには、pip install milvus llama-index python-dotenv が必要です。milvusとllama-indexライブラリはコア機能を提供し、python-dotenv` は OpenAI API キーなどの環境変数をロードします。この例では、ウィキペディアから様々な都市に関するデータをスクレイピングし、引用を含むクエリを実行します。
必要なライブラリをインポートし、OpenAI APIキーをロードします。LlamaIndexから7つのサブモジュールが必要です。順不同:LLMにアクセスするための OpenAI、引用クエリーエンジンを作成するための CitationQueryEngine、ベクターストアとしてMilvusを使用するための MilvusVectorStore である。さらに、Milvus を使用するために VectorStoreIndex、ローカルデータを読み込むために SimpleDirectoryReader、Milvus にベクターインデックスをアクセスするために StorageContext と ServiceContext をインポートする。最後に、 load_dotenv を使用して OpenAI API キーをロードする。
from llama_index.llms import OpenAI
from llama_index.query_engine import CitationQueryEngine
from llama_index import (
VectorStoreIndex、
SimpleDirectoryReader、
StorageContext、
ServiceContext、
)
from llama_index.vector_stores import MilvusVectorStore
from milvus import default_server
from dotenv import load_dotenv
import os
load_dotenv()
open_api_key = os.getenv("OPENAI_API_KEY")
テストデータのスクレイピング
プロジェクトを始めるにあたって、まず扱うべきデータを用意しよう。この例では、Wikipediaからデータをスクレイピングする。実際には、multi-documentクエリエンジンを構築するために行ったのと同じデータをスクレイピングしている。以下のコードはウィキペディアのAPIから wiki_titles リストで言及されているページに対してpingを打っている。その結果をテキストファイルに保存する。
wiki_titles = ["トロント", "シアトル", "サンフランシスコ", "シカゴ", "ボストン", "ワシントンD.C.", "マサチューセッツ州ケンブリッジ", "ヒューストン"].
from pathlib import Path
import requests
for title in wiki_titles:
response = requests.get(
'https://en.wikipedia.org/w/api.php'、
params={
'action': 'query'、
'format': 'json'、
'titles': タイトル、
'prop':'extracts'、
'explaintext':真、
}
).json()
page = next(iter(response['query']['pages'].values()))
wiki_text = page['extract'].
data_path = Path('data')
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", 'w') as fp:
fp.write(wiki_text)
LlamaIndexでベクターストアをセットアップする
これですべてのデータが揃ったので、citationアプリでRAGのアプリロジックをセットアップできます。まず、ベクターデータベースを作成します。この例では、Milvus Liteを使用して、ノートブックで直接実行します。次に、LlamaIndexのMilvusVectorStoreモジュールを使って、Milvusをベクターストアとして接続します。
default_server.start()
vector_store = MilvusVectorStore(
コレクション名="citation"、
host="127.0.0.1"、
port=default_server.listen_port
)
次に、インデックス用のコンテキストを作成しましょう。サービスコンテキストはインデックスとリトリーバーにどのサービスを使うかを指示する。この場合、目的のLLMとしてGPT 3.5 Turboを渡す。また、インデックスがどこにデータを保存し、クエリするかを知るために、ストレージコンテキストも作成します。この場合、上で作成したMilvusベクトル・ストア・オブジェクトを渡します。
service_context = ServiceContext.from_defaults()
llm=OpenAI(model="gpt-3.5-turbo", temperature=0)
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
これで、先ほどスクレイピングしたデータをロードし、それらのドキュメントからベクトルストア・インデックスを作成することができる。
documents = SimpleDirectoryReader("./data/").load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
引用によるクエリ
これで引用クエリエンジンを作成できます。先ほど構築したベクトルインデックスと、返す結果の数、引用のチャンクサイズのパラメータを与えます。これで引用の設定は完了で、次のステップはエンジンへのクエリです。
query_engine = CitationQueryEngine.from_args(
インデックス
similarity_top_k=3、
# デフォルトは512です。
citation_chunk_size=512です、
)
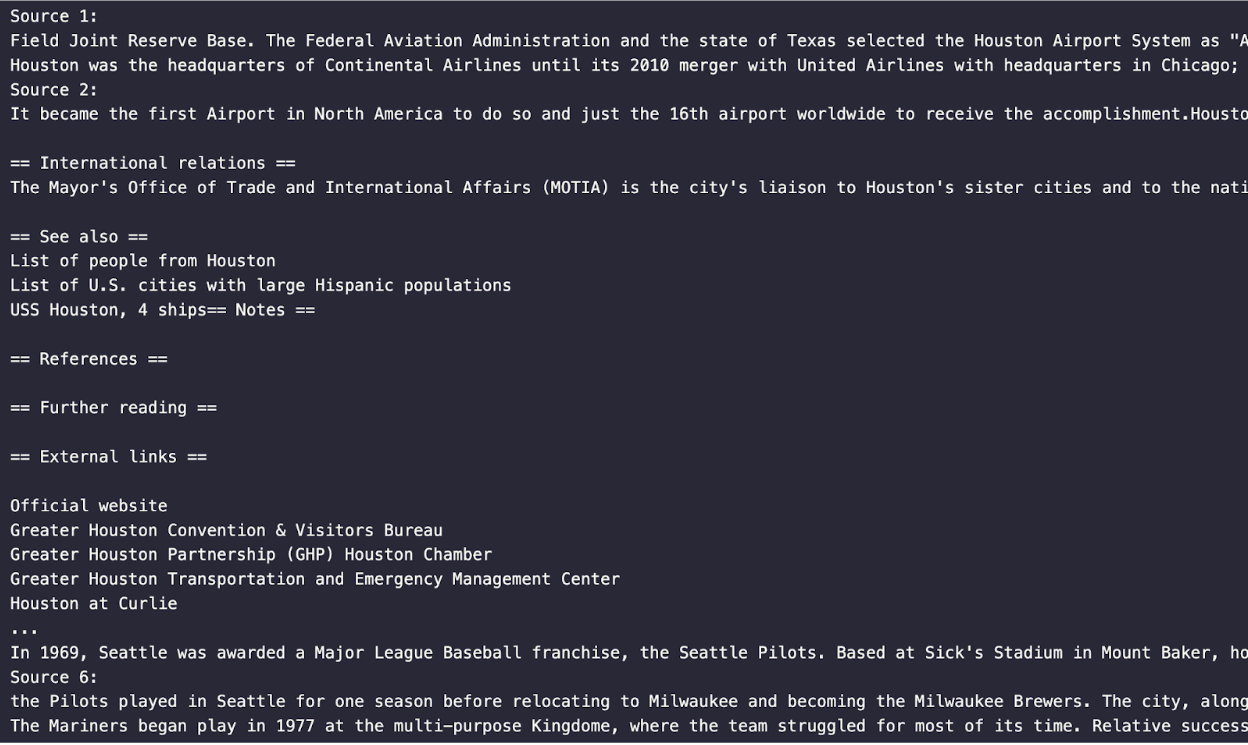
response = query_engine.query("Does Seattle or Houston have a larger airport?")
print(response)
for source in response.source_nodes:
print(source.node.get_text())
クエリを実行すると、レスポンスは次のようになる。
 引用によるクエリ
引用によるクエリ
要約
このチュートリアルでは、引用(attributions)を使ってretrieval augmented generationを行う方法を学んだ。検索機能拡張生成は、多くの企業が構築したいと考えているLLMアプリケーションの一種です。情報を検索し、消化しやすいフォーマットにフォーマットするだけでなく、その情報がどこから来たのかも知りたいものです。
LlamaIndexをデータルーターとして、Milvusをベクターストアとして使用することで、このタイプのRAGアプリケーションを構築することができます。まず、ウィキペディアからいくつかのデータをスクレイピングして、これがどのように機能するかを示す。次に、Milvusのインスタンスを立ち上げ、LlamaIndexにベクターストアのインスタンスを作る。そこからMilvusにデータを入れ、LlamaIndexを使って引用クエリーエンジンを使って帰属と引用を追跡する。そして、そのクエリー・エンジンにクエリーを行い、テキストのどの部分か、どのテキストから答えを引き出しているのか、といった回答を得ることができる。

読み続けて

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.