




Self-Hosted Milvus から Zilliz Cloud へ移行する理由と方法
Milvus は最も人気のあるオープンソースのベクトルデータベースであり、その高いパフォーマンスと水平スケーラビリティで信頼されています。Milvus を使用しているなら、類似性検索や大規模な埋め込みワークロードをいかに効率的に処理できるかをすでにご存じでしょう。
しかし、データセットが拡大し、アプリケーションがより複雑になるにつれて、独自の Milvus デプロイメントを維持することはますます困難になります — インフラストラクチャの管理やクラスターのスケーリングから、一貫したパフォーマンスの確保まで。
そこで Zilliz Cloud の出番です。Milvus 向けの完全マネージドクラウドサービスとして、最大 10 倍高速なパフォーマンスを提供し、ホスティング、スケーリング、最適化を手間なく処理する本番環境対応の環境を提供します — そのため、チームはインフラストラクチャの管理ではなく、AI アプリケーションの構築に集中できます。
この記事では、Milvus と Zilliz Cloud を比較し、Milvus から Zilliz Cloud へスムーズに移行し、運用上のオーバーヘッドなしでベクトルデータを最大限に活用し始める方法を順を追って説明します。
Milvus vs. Zilliz Cloud
Milvus と Zilliz Cloud は同じ基盤を共有していますが、異なる目標に最適化されています。
オープンソースのベクトルデータベースである Milvus は、開発者に完全な制御と柔軟性を提供します。ベクトル実行エンジンである Knowhere によって駆動される Milvus は、Faiss、Hnswlib、Annoy などの高性能ライブラリを統合し、SIMD アクセラレーション、CPU/GPU ハイブリッド実行、バイナリベクトルサポートによってそれらを強化します。最適な命令セット(SSE、AVX2、AVX512)を自動的に選択し、Euclidean、Inner Product、Cosine、Jaccard、Hamming、BM25 など複数の類似度メトリクスをサポートします。
これにより Milvus は、ベクトルインデックス作成をきめ細かく制御したいチーム、構成を試したいチーム、そしてクラスター、スケーリング、アップグレードを管理する DevOps リソースを持つチームにとって優れた選択肢となります。
対照的に、Zilliz Cloud は Milvus を次のレベルへ引き上げます。Milvus の上に構築された Zilliz Cloud は、運用の複雑さを排除しながら、より高いパフォーマンスとスケーラビリティを引き出すように設計された、完全マネージドの本番環境向けベクトルデータベースサービスです。
その中核で、Zilliz Cloud は Cardinal 上で動作します。これは商用グレードの自己最適化ベクトル検索エンジンで、Milvus より最大 10 倍高速なパフォーマンスを提供します。AutoIndex により、HNSW、IVF、DiskANN などのインデックス作成アルゴリズムを自動的に選択・調整し、手動設定なしで 96% を超えるリコールを実現します。
しかし速度だけでなく、Zilliz Cloud は AI アプリケーションの構築とスケーリングのための包括的なプラットフォームを提供します。
Elastic Scaling とコスト効率: 需要に基づいてコンピュートおよびストレージリソースを容易にスケールできます。サーバーレスのオートスケーリング、ワンクリックデプロイ、ワークロードに適応する従量課金制を利用できます。
高度な AI 検索機能: メタデータフィルタリングと動的スキーマを備えたベクトル検索、全文検索、ハイブリッド(dense + sparse)検索を実行し、複雑なマルチモーダル検索を可能にします。
自然言語クエリ: 組み込みの MCP server サポートにより、開発者は API 呼び出しを手動で作成する代わりに、自然言語を使用してデータをクエリできます。
エンタープライズグレードの信頼性とセキュリティ: Zilliz Cloud は 99.95% の稼働率 SLA、マルチ AZ 冗長性、SOC 2 Type II、ISO 27001、GDPR compliance などの認証を提供します。また、エンタープライズデータ保護のために RBAC、BYOC、監査ログ、暗号化もサポートします。
グローバルリーチ: AWS、GCP、Azure 全体にデプロイし、世界中で 100ms 未満のレイテンシと分散チーム向けのシームレスなアクセスを確保します。
容易な移行: 組み込みの移行ツールを使用して、Milvus、Pinecone、Qdrant、Weaviate、Elasticsearch、PostgreSQL から移行できます — スキーマの書き換えやダウンタイムは不要です。
要するに、Milvus は柔軟性と制御性を提供します。Zilliz Cloud は、メンテナンスの負担なしに、パフォーマンス、シンプルさ、グローバルなスケーラビリティを提供します。
移行の準備
Zilliz Cloud に移行する前に、すべてがスムーズに進むよう、いくつかの手順を実施する必要があります。
現在の Milvus セットアップを確認する: Milvus のバージョン(移行をサポートするには 2.3.6 以降である必要があります)、デプロイメントタイプ(Docker や Kubernetes など)、および設定済みのカスタム設定を確認してください。
データをバックアップする: 移行前には必ず Milvus データの完全なバックアップを作成してください。この手順は、データ損失を避けるために非常に重要です。
移行方法を選択する: データベースのサイズとニーズに応じて、エンドポイント経由(小規模な単一データベースの移行に最適)またはバックアップファイルを使用(大規模な移行に推奨)して移行できます。
このガイドでは、ソースとして スタンドアロンの Milvus インスタンスを使用しました。デフォルトデータベースには migration_test という名前のコレクションが 1 つ含まれており、1,000 件のレコードが含まれています。
Milvus を Zilliz Cloud に移行する方法
Milvus から Zilliz Cloud へ移行する方法は 2 つあります。
方法 1: エンドポイント
前提条件:
Milvus:
バージョン: Milvus 2.3.6 以上
ネットワーク: パブリックインターネット経由でアクセス可能である必要があります
認証: 有効になっている場合は、ユーザー名とパスワードを用意してください
Zilliz Cloud:
ユーザーロール: 組織オーナーまたはプロジェクト管理者である必要があります
クラスターリソース: Zilliz Cloud クラスターに十分なストレージ容量とコンピューティング容量があることを確認してください。これは CU Calculator を使用して見積もることができます。
ネットワークアクセス: Zilliz Cloud の IP アドレスを許可リストに追加してください(完全なリストはこちらを参照)
移行手順:
- Zilliz Cloud Console を開き、新しい移行を開始します。
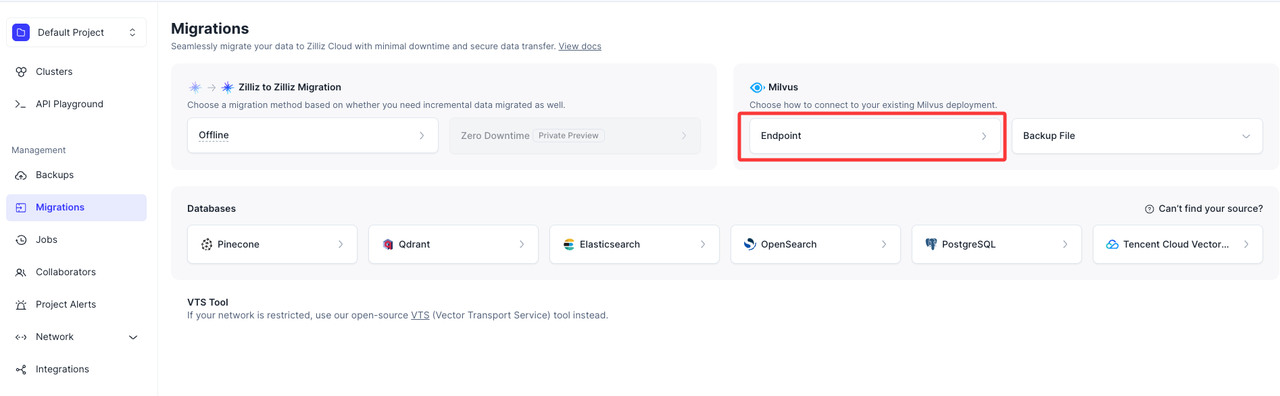
- 移行方法として Endpoint を選択します。
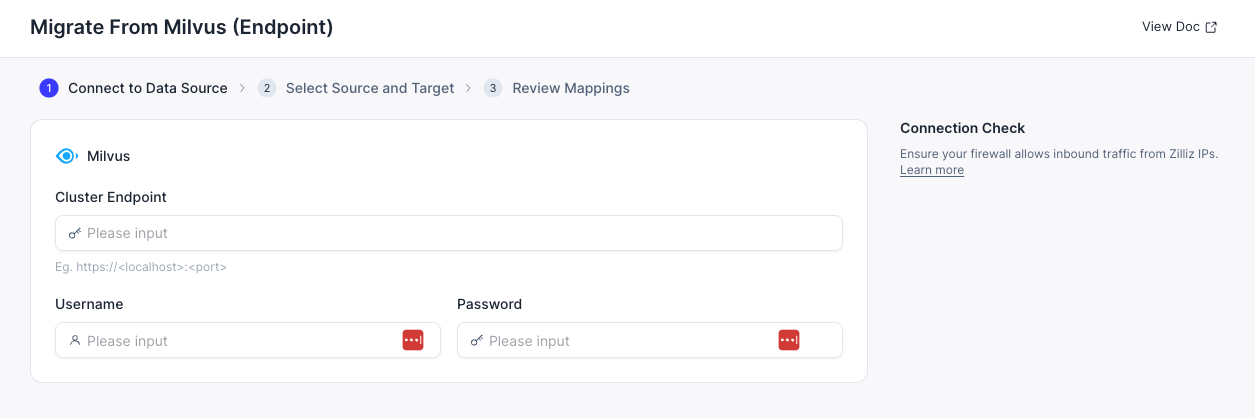
- Milvus エンドポイント URL を、ユーザー名とパスワード(認証が有効な場合)とともに入力します。
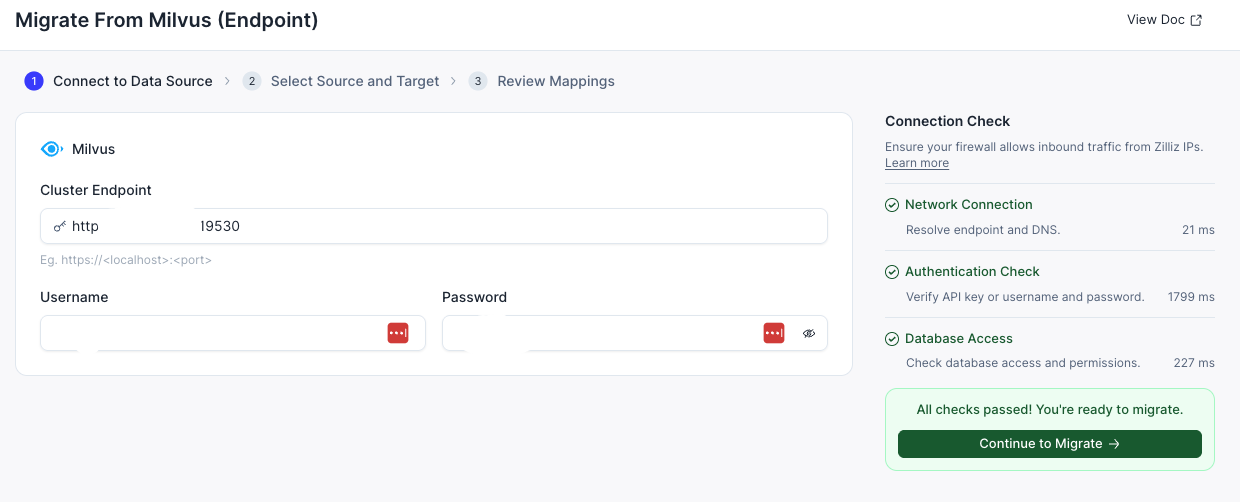
- 接続テストが成功することを確認します。
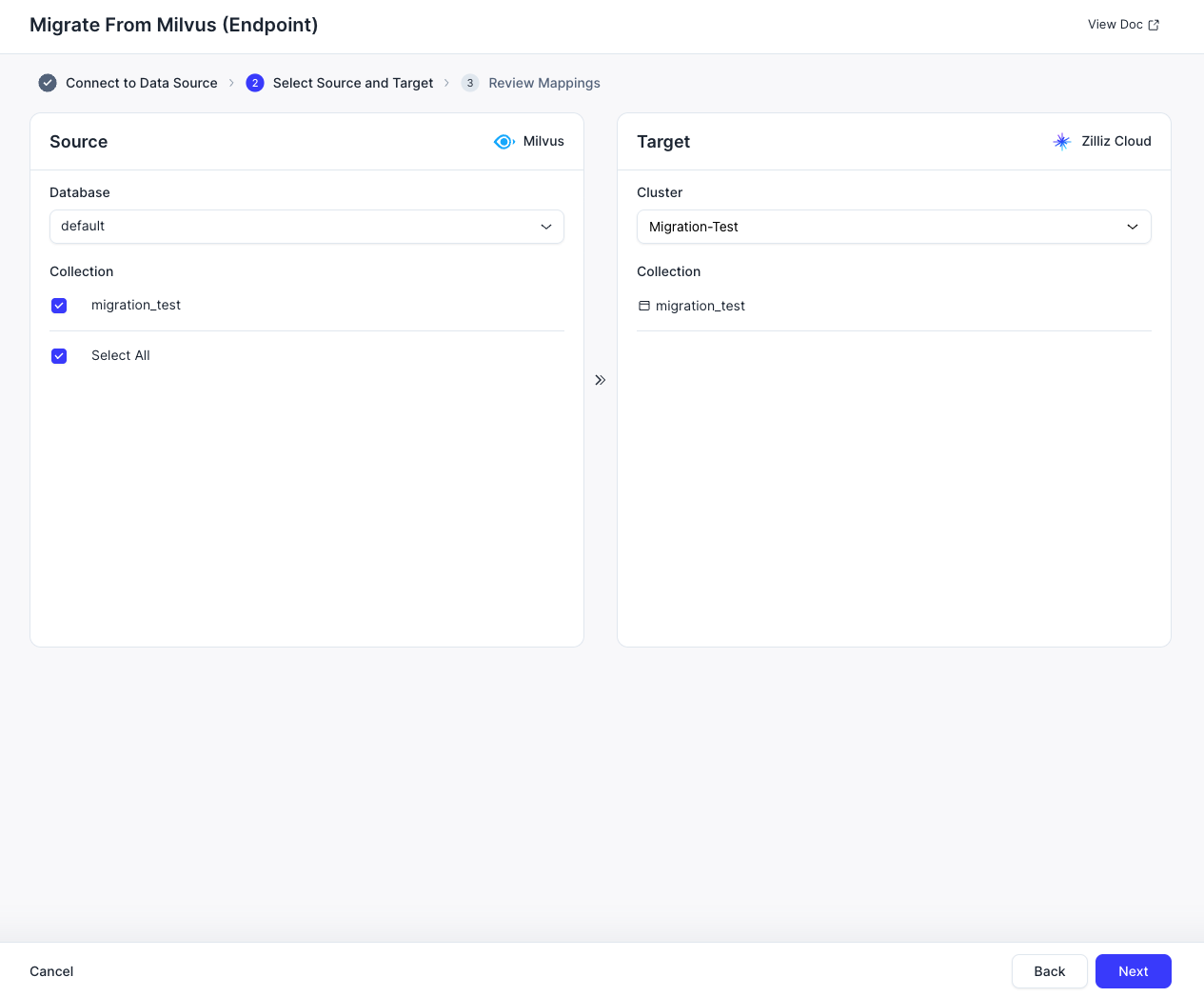
- 移行したいソース Milvus データベース内のコレクションを、Zilliz Cloud のターゲットデータベースインスタンスおよび対応するコレクションとともに選択します。
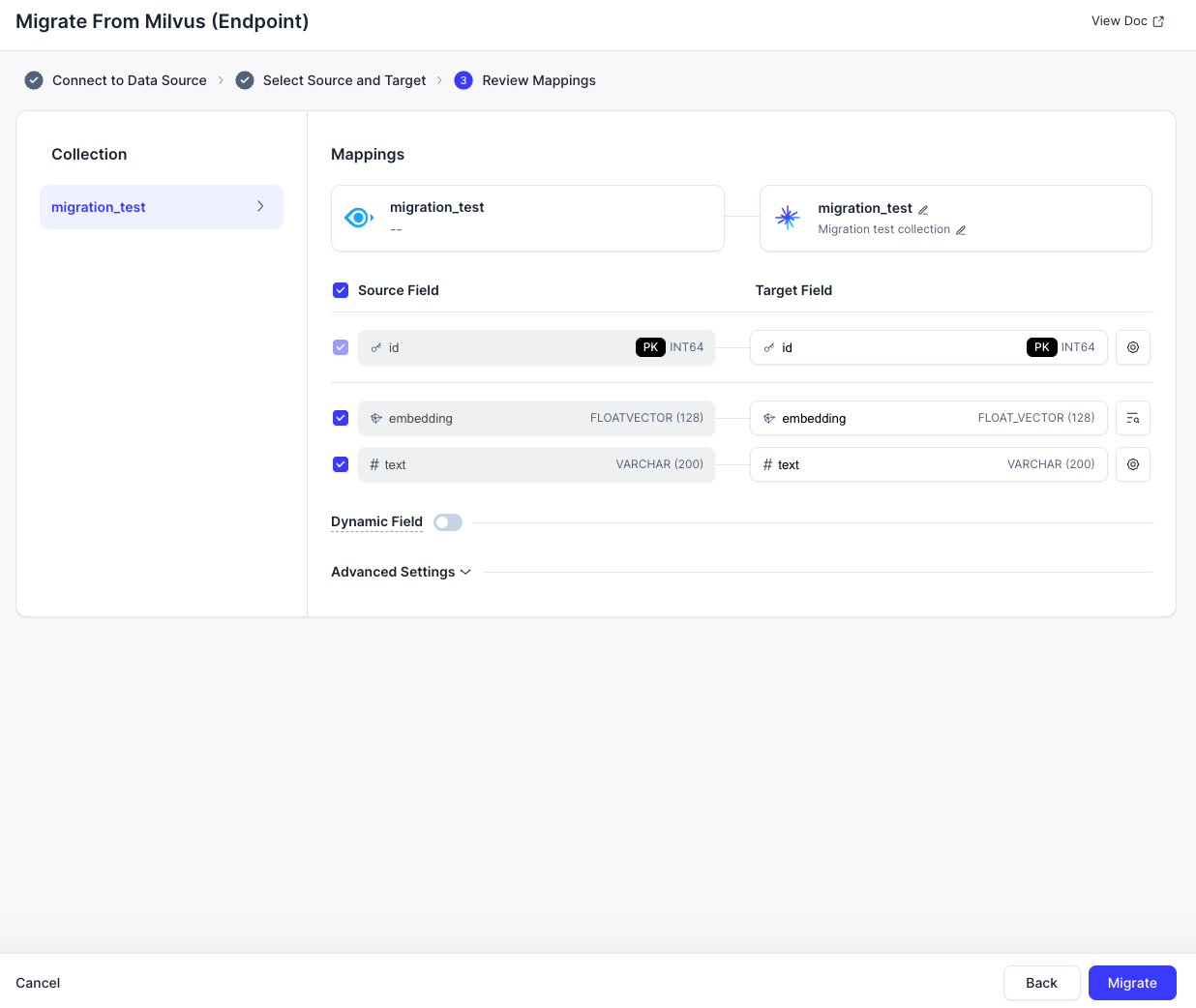
- すべてのフィールドマッピングが正しく一致していることを確認します。Migrate をクリックして移行ジョブを開始します。
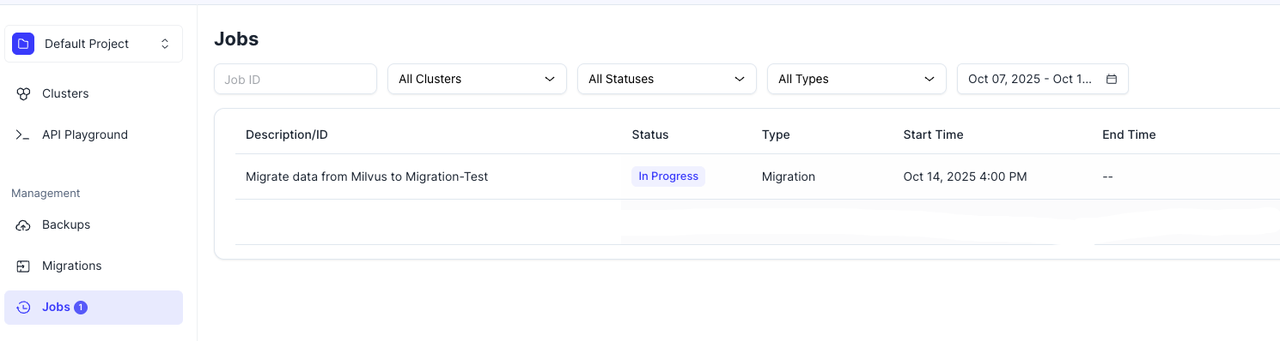
- Job Center に移動して進行状況を追跡します。ジョブステータスが “In Progress” から “Successful” に変わると、移行は完了です。

移行後の最終確認:
- コレクションを手動でロードする: 検索およびクエリ操作を有効にするには、Zilliz Cloud で移行済みコレクションを手動で ロードする必要があります。
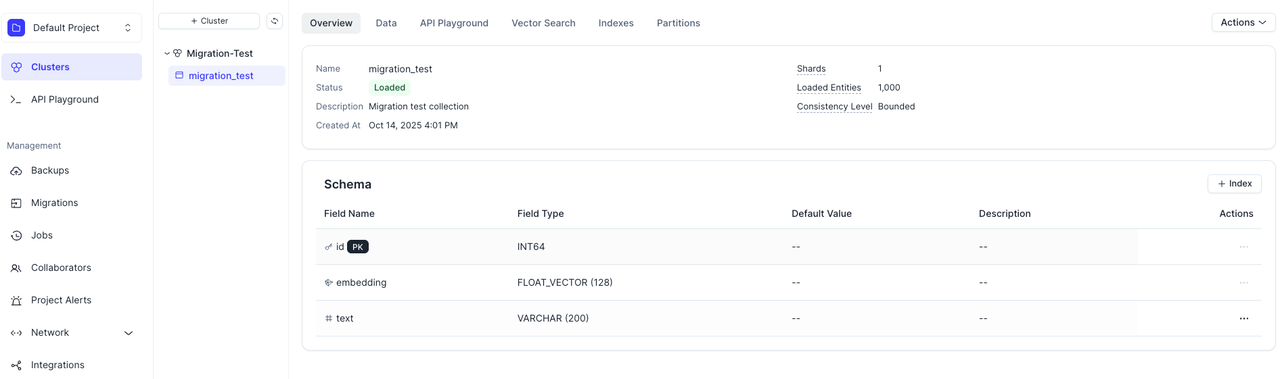
データの一貫性を確認する: Zilliz Cloud のコレクション数とエンティティ数が元の Milvus インスタンスと一致していることを確認します。差異が見つかった場合は、移行を再実行できます。
失敗した移行に対処する: 移行ジョブが失敗した場合は、Zilliz Cloud Console の Job Center に移動し、ジョブをキャンセルして、View Details をクリックしてエラーログを確認します。
方法 2: バックアップファイル
前提条件:
Zilliz Cloud:
ユーザーロール: 組織オーナーまたはプロジェクト管理者である必要があります
クラスターリソース: クラスターにデータを保存するための十分な Compute Units (CUs) があることを確認してください。これは CU Calculator を使用して見積もることができます。
ネットワークアクセス: Zilliz Cloud の IP アドレスを許可リストに追加してください(完全なリストはこちらを参照)
Milvus:
- バックアップファイル: Milvus のバックアップファイルを準備する必要があります。バックアップはローカル、または AWS S3 や MinIO などのオブジェクトストレージに保存できます。
バックアップファイルの作成とアップロード方法:
milvus-backup をダウンロード: milvus-backup の最新バージョンを取得します
configs フォルダーを作成し、backup.yaml を追加します
wget https://raw.githubusercontent.com/zilliztech/milvus-backup/main/configs/backup.yaml
milvus-backup バイナリがある同じディレクトリに、configs という名前のフォルダーを作成します。backup.yaml 設定ファイルをダウンロードし、このフォルダーに保存します。
ディレクトリ構造は次のようになります。
workspace
├── milvus-backup
└── configs
└── backup.yaml
backup.yaml をカスタマイズ: backup.yaml ファイルを開き、その設定を確認します。環境に応じて、milvus.address、milvus.port、minio.address などのフィールドを更新します。
バックアップを作成します:
./milvus-backup --config backup.yaml create -n my_backup
バックアップファイルを取得します:
./milvus-backup --config backup.yaml get -n my_backup
バックアップファイルの保存場所を確認します: 設定によって、バックアップファイルは異なる場所に保存される場合があります。
OSS (Object Storage Service) を使用している場合: バックアップファイルは、
minio.addressとminio.portで定義された OSS バケットにすでに保存されています。MinIO を使用している場合: MinIO Console または
mc(MinIO Client) ツールのいずれかを使用してバックアップファイルをダウンロードできます。
MinIO Console からダウンロードするには:
MinIO ダッシュボードにログインします。
minio.addressで指定されたバケットを見つけます。バケット内のファイルを選択し、ダウンロードを開始します。
mc クライアントを使用してダウンロードするには:
# MinIO ホストを設定
mc alias set my_minio https://<minio_endpoint> <accessKey> <secretKey>
# 利用可能なすべてのバケットを一覧表示
mc ls my_minio
# 特定のバケットからファイルをダウンロード
mc cp --recursive my_minio/<your-bucket-path> <local_dir_path>
バックアップファイルを Zilliz Cloud にアップロード: バックアップファイルを取得したら、Zilliz Cloud Console を使用して、バックアップディレクトリ内のサブフォルダーを Zilliz Cloud にアップロードします。
backup
└── my_backup <= このフォルダーをアップロード
ステップバイステップの移行:
- Zilliz Cloud で移行を開始します。

バックアップファイルの保存場所に基づいて、バックアップファイルの場所を選択します。
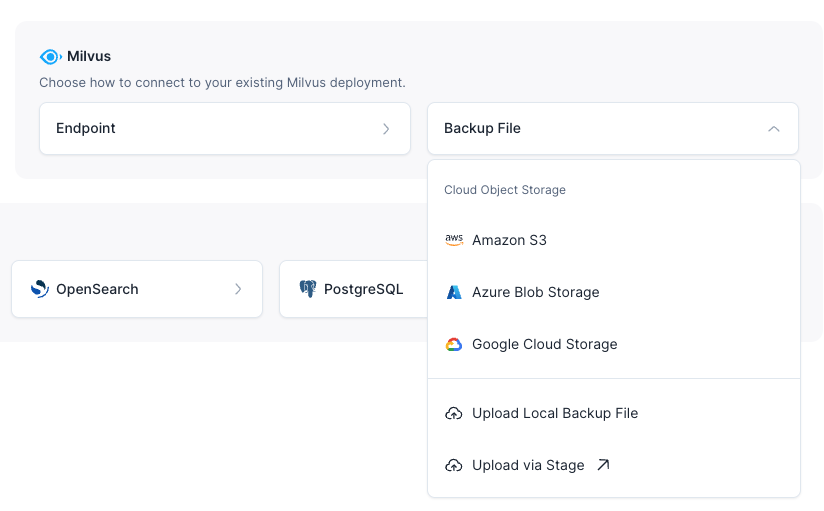
バックアップフォルダーを選択します。
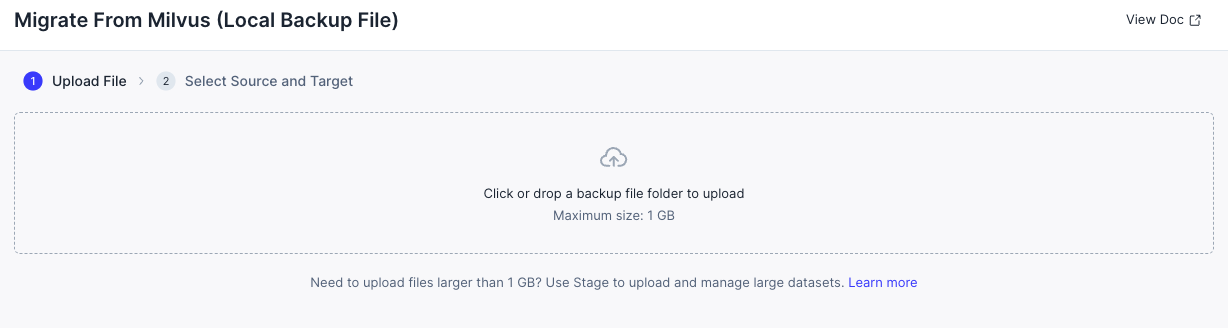
データを復元する Zilliz Cloud 内のターゲットデータベースとコレクションを選択します。
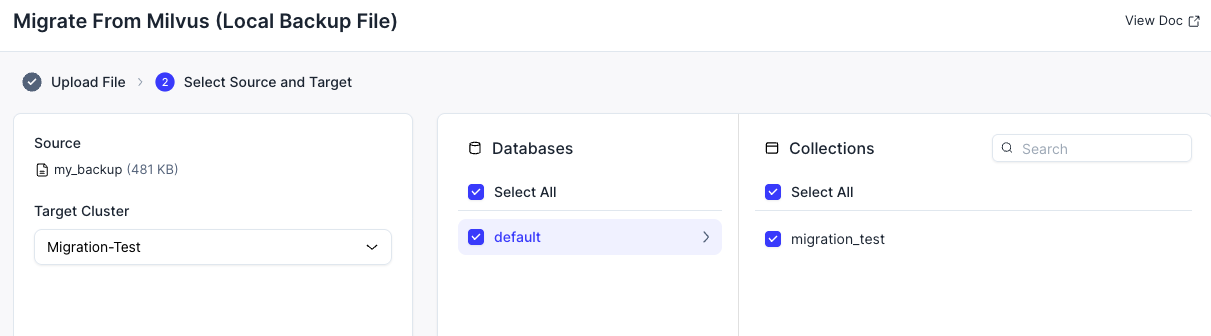
- 進行状況を追跡するには、Job Center に移動します。
移行後の最終確認:
コレクションを手動でロード: 検索およびクエリ操作を有効にするには、Zilliz Cloud で移行済みコレクションを手動で load する必要があります。
データの一貫性を確認: Zilliz Cloud のコレクション数とエンティティ数が元の Milvus インスタンスと一致していることを確認します。差異が見つかった場合は、移行を再実行できます。
失敗した移行への対応: 移行ジョブが失敗した場合は、Zilliz Cloud Console の Job Center に移動し、ジョブをキャンセルして、View Details をクリックしてエラーログを確認します。
スムーズな移行のためのベストプラクティス
移行をスムーズに実行し、データの整合性を維持するために、次のベストプラクティスを念頭に置いてください。
データの整合性を確認: 移行前に、バックアップファイルが完全で一貫していることを確認します。
進行状況を監視: 移行中は Job Center を監視し、問題を早期に発見して解決できるようにします。
アプリケーションをテスト: 移行後、アプリケーションを十分にテストして、Zilliz Cloud ですべてが正しく動作することを確認します。
以下の表は、両方の移行方法を比較したものです。ニーズに最も適した方法を選択できます。
| 移行方法 | 最適な用途 | 利点 | 制限事項 |
|---|---|---|---|
| エンドポイント経由 | 個々のデータベースまたは小規模デプロイメントの移行 | シンプルでわかりやすい;きめ細かな移行を管理しやすい | 一度に1つのデータベースしか移行できない;効率が低い |
| バックアップファイル経由 | 大規模な移行、または複数のデータベースの同時移行 | 高効率;大規模データセットの処理に最適 | 追加のツールとストレージ設定が必要;操作がやや複雑 |
Zilliz Cloudを自分で体験する
セルフホスト型MilvusからZilliz Cloudへの移行は、単なるインフラのアップグレードにとどまりません。AIアプリケーションのより高速で、よりシンプルで、よりスケーラブルな未来へ向けた一歩です。無料でサインアップして、100ドル分のクレジットを受け取り、世界をリードするマネージドベクトルデータベースを直接お試しください。
Milvusに加えて、Zilliz Cloudは、Weaviate、Pinecone、Elasticsearch、OpenSearch、Amazon S3 Vectors、Qdrant、PostgreSQLなど、幅広いソースからのシームレスな移行にも対応しています。さらに多くの統合が近日中に追加される予定です。
移行について = ご質問がある場合は、ドキュメントをご確認いただくか、お問い合わせください。Zilliz Cloudを最大限に活用できるよう、私たちがサポートします。

読み続けて

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.